
 起点课堂会员权益
起点课堂会员权益如何评测语音助手的智能程度(1):意图理解
本文重点定义和讨论第一大模块【意图理解】,即是否能够理解/识别用户表述的意图。笔者以为,这个模块是衡量AI智能与否的核心维度,并将为大家揭晓评测维度与指标。

从事AI-NLP领域已经一年半了,一直潜心学习。
平日里研究各种各样的语音助手,输出各种类型的调研分析报告,以培养自己的业务敏锐度,同时也研究各种框架型知识以丰富自己的知识库。
在仔细、反复研读完了《Google对话式交互规范指南》、《阿里语音交互设计指南》、《亚马逊语音交互设计规范》三大交互规范后,累积过往的工作过程中所遇见的问题,自己努力尝试着提炼出一个知识框架,并期望把这些规范类的东西,内化成为自己的被动技能,继而为自己以后做出更好用的产品做出积累。
一、我心中的超级人工智能
私以为,最理想的人工智能,就像:
- 《Her》里面的萨曼莎;
- 《钢铁侠》里面的贾维斯;
- 《超能陆战队》里面的大白;
- 《多啦A梦》里面的机器猫;
这些超级英雄总能解决我们生活中的各种各样的问题。
虽然我们的世界距离这种超级人工智能还非常遥远,也许永远达不到,但是不妨以一种非常高的标准对AI去做出苛求,继而去倒逼自己做出更好的产品。
文章开始前,请先短暂忘记自己是AI从业者这个身份,让我们变成一个小白用户,尽管提要求吧。
简单而言就是一句话——“我就想要一个聪明且好用的智能助理,能够满足我生活中的各种需求。”
“好用”如何定义?“各种需求”如何满足?难就难在没有边界。
真正意义能符合上面要求的是,可以无限许愿的神灯。
所以我们干脆模块化一些,笔者就智能语音助理这一产品有如下四个大的评判维度,它们依次是【意图理解】、【服务提供】、【交互流畅】、【人格特质】。

亦或者是说,这些指标如果能够得到全部满足,距离我们想要的超级人工智能也就不远了。谁能够提供,谁就可以获得用户的亲睐。
每个评判维度还有对应的细分指标,让我们一步步拆解。
二、【意图理解】维度的5个指标
本文重点定义和讨论第一大模块【意图理解】,即是否能够理解/识别用户表述的意图。
私以为,这个模块是衡量AI智能与否的核心维度。
(1)中控分配意图能力
当前市面上的AI智能助手,往往包含着各种各样的能力。
从业者角度而言,本质是各个技能的集合,而每一项能力都是服务和满足特定领域类的需求,比如听音乐,导航,事项提醒,电影票,机票,火车票什么的。
很多的技能在固定域里面能够表现得非常好,但是集中到一起,表现就未必好了。
核心考量点:准确识别用户需求,并分配到指定技能服务的能力。
用户提出的每个需求,计算机都会做出反馈(文本、语音、图片、功能卡片、多媒体事件等等)。
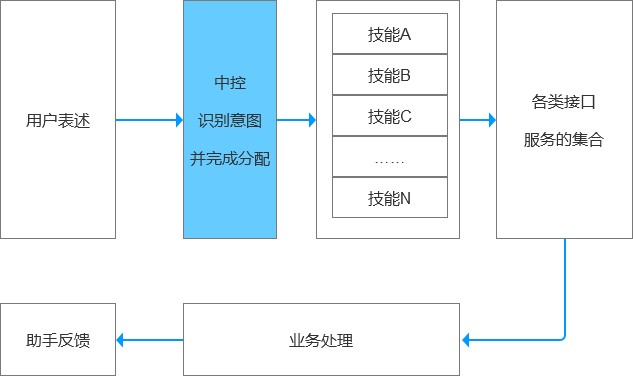
在反馈之前,是先要做到识别并理解,然后成功分配到指定的技能上,最后由指定的技能完成反馈,即服务行为。
而人类的语言表达千奇百怪,我们期望计算机自然能够通过人的自然表达,成功理解人类的意图,并使用对应的回复衔接业务。
例子:
- “我想听我想去拉萨”>>>意图应该分配给音乐,然后由【音乐】完成反馈。
- “我想去拉萨”>>>意图分配导航,然后由【导航】完成反馈。
例子:
- “提醒我一下我明天帮女朋友买一束花花”>>>意图可以分配给【事项提醒】技能
- “我想明天帮女朋友订一张到上海的火车票,你早上8点半提醒我下抢票”>>>意图如果分配给【订火车票】技能就错了
这个就是中控分配意图的能力。也是所有AI智能助手,集合各项能力的一个核心能力。做不好中控的意图识别,智能化无从谈起。
市面上,例如腾讯叮当、小爱同学,小度助手这类大生态的集合的处理方案,属于最大的开放域,相当多的技能只能是采用命令词跳转的方式启动,这种对话行动无疑是要等待,而且对话流程冗长,面对着输入的不确定性,所以用户为什么不用GUI(图形交互界面)去完成目标呢。
而一些细分领域的,比如说出行、餐饮、客服、游戏领域的智能助手,这些相对的封闭固定的领域,还用关键词的方式进入指定技能再寻求服务,就显得非常笨了。
如果做不到全开放域的中控,至少也得在固定域里面做好意图需求识别以及分配的能力,这样方便发挥语音输出便捷直达目标的能力,才不至于像个玩具。
(2)句式/话术/词槽泛化度
用大白话来讲:同一个意思,当用户采用不同的表达的时候,AI是否能够正确理解。
业内的专业说法是“可识别话术/词槽的泛化程度”。解决方案是“增加更多的语义覆盖”。
泛化有两种,一种是句式,另一种是词槽。
先说句式的例子:
笔者经常观察用户的对话日志后台,发现用户在播放音乐的时候,表述各种各样。
“我想听音乐>>>随便放首歌>>>音乐响起来>>>music走起>>>”
有些能够能理解,【音乐】正确回复随机歌单,有些话术的表述无法理解则被【兜底】给接走了,这种反馈就是助手的失误了。
列举词槽例子:
- “我想吃711/想吃七十一”/想吃seven eleven/想吃关东煮/想吃好炖>>>
- 我想吃肯德基/想吃KFC/“想吃开封菜”>>>
笔者的所开发的智能助手有一个【电影票】技能,观察用户对话日志时的一些发现:
- 《速度与激情8》刚刚上映,用户会表述是“我想看速度与激情、速激、速8等等;
- 《魔童哪咤》上映的时候,用户的表述是我想看哪咤的电影;
- 《叶问3》上映的时候,用户的表述会是,叶问。甚至是“甄子丹的那个电影”;
而AI先提取对应的影片名,然后交给接口方去完成查询行为,只有正确填充“指定电影的全称”才能够可查询成功,所以此处就需要做映射关系的特殊处理。
在定电影票例子中,是十分考虑场景和时效性,也就是说,用户在不同的时间点,说我要看《某》系列电影的时候,口语上大概率是绝对不会带上第几部的。
这些要求其实都是生活中的一些例子,既然人类可以做到理解,自然AI也理所应当做得更好。
作为从业者,一定要多看自己的公司业务的对话日志后台,观察用户在对话过程中,究竟是如何去使用我们的产品,这个是我们的迭代产品的重要依据,随时根据用户实际使用情况,做出完善。
就过往的泛化经验而言,结构性的句子变化相对较小,而词语的变化就很多,像分析数据一样经常看用户的对话日志,会有很多的积累。
比如阿里巴巴的天猫精灵是具备线上语音购物的能力的,那么眼下的2020春节,相当多的用户会在我想买口罩这种话术之外,直接表述,我想买3M的口罩甚至会直接问有没有N95卖——毕竟在眼下的这个语境,N95几乎就是口罩的代名词了。
如果这类没有覆盖,那你也只能通过版本迭代去训练,各位AI从业者基于自家产品的版本迭代效率,思考一下差距。
所以“一开始就做好”相比“通过各种渠道反馈发现不好,然后通过迭代去做好”,从产品设计基本功上来看,根本是两种境界。
所以解决方案是,此处应该是有一个动态热词的词库,产品设计和运营方式不展开,不在本篇讨论范围内。
在实际的业务中,很多词汇和句式会被不断地造出来,至于优先级如何选择,如何泛化覆盖词槽和句式,鉴于文章定位,此处不适合展开。
(3)反馈准确度/容错率
考量AI的反馈给用户的内容是否能够准确匹配需求,是否具备显性确认以提升容错性。各个语音交互设计规范都提及了这一点。
例子:
“我想听林志炫的《烟花易冷》”>>>如果AI推送的是周杰伦的就不对。
如果没有资源,也应该处理成,未找到XXX,让我们来听YYY方为合理。
而当接口方真(因为版权)没有资源时,明确没有,是一种我听懂了,但是实在没有,给你提供替代方案的处理,而如果你不明示没有,我可能会再追问一句,然后你还是不明示,到底是我没说明白,还是你没听懂呢?
例子:
- 假设现在是1月1日的晚上23点钟,用户说“帮我订一个明天早上7点的闹钟”
- 假设现在是1月2日的凌晨1点钟,用户说“帮我订一个明天早上7点的闹钟”
第二种情况,如果按照计算机的逻辑去理解,那1月2日的明天早上则是1月3日的早上了,这种定闹钟的方式意味着悲剧。
而基于日常逻辑,两种情况,都应该提供1月2日,早上7点钟的闹钟方为合理。
逻辑处理完毕后,然后就是话术的处理,回复方式有几种选择:
- 回复1:“已经为您设置闹钟。”
- 回复2:“已为您设置明天早上7点钟的闹钟。”
- 回复3:“已经为您设置明天早上7点的闹钟,我将会在6个小时后叫醒你。”
如果没有显性确认,就没有容错性,用户就会心中不安,一旦被【闹钟】服务坑过用户一回,那么就会恶评如潮。本来用户就用的低频,一旦不信任,被打入冷宫再也没什么机会了。
只要你仔细体验观察,相当多的AI语音助手在给于反馈的时候,此类细节处理得不好,容错率实在是太低了。好的容错性设计,其实应该是每个AI从业者体内的基因,成为被动技能,天赋一样的能力。
(4)模糊/歧义表述处理
GUI的交互意味着输入可控,CUI/VUI的交互意味着输入不可控。
这中间相当一部分是人类的表达问题,但是一旦造成的回复不满意,意味着用户将花费巨大的成本去再来一次。最后被用户批评或者被定性为“人工智障”、“就是个能对话的玩具”往往很让人沮丧。
核心考量点:当用户使用模糊歧义表述的时候,AI的处理方式。
例子:“我明天下午4点要去上海出差。”
注意此时至少存在两处模糊歧义表述:
- 用户并没有指定交通工具。
- 明天下午4点,指的是4点出发,还是4点到那里。
例子:(假设现在是周一)“帮我定下周三去上海的机票”。
注意:ASR的转化是无法翻译停顿的,到底是“帮我订,下周三”的,还是,“帮我定下,周三”的呢?
在真实的对话中,人们是能够根据停顿节奏,以及具体的场景猜测到底是如何断句的。
以上两个例子是我们业务中反馈的真实案例。
说说我自己处理这类问题的思路,即提前交付结果,等待用户反馈。
第一个例子,根据用户的GPS坐标出行便捷程度以及商业诉求进行推荐。火车,飞机,或者是打车均是正确的选择。
例如可以做出如下回复,“基于天气情况,建议火车出行,为你找到从XX到上海的火车票,1月3日出发,高铁二等座,价格……
第二个例子,根据用户提出需求的时间,就近选择结果反馈,并给予显性确认。
当面对模糊/歧义意图的时候,一定要有一个处理逻辑,去管理用户的期望值和服务。
面对模糊/歧义表述的处理方式在行业内通通都是大难题。好的处理方案,能够判断用户的歧义表述,并引导纠错。
至于处理逻辑是直接给于结果,还是通过追问的形式二次判断,就是具体业务具体场景的选择了。
不过多举例,但是有无处理方案,应该纳入进评测点。
(5)任务目标达成表现
核心考量点:帮助用户达成目标中间所花费的成本。
当前市面上几乎所有的服务类技能,都是AI通过提取用户表述中的具体信息,填充到指定槽位完成服务的推荐,而当用户没有给予主要槽位的时候,是需要引导用户完成的。
市面上有两种做法,一种是固定路径,不可改变的填槽。
比如说【火车票】技能,正常的对话是这样的。
先问出发地和目的地,然后问出发日期,然后确定车次,中间不能改不能乱,然后方可完成查询行为。
- 用户第一句话:“我想买火车票?”AI回复:“好的,你想从哪里到哪里?”
- 用户第二句话:“从北京到上海。”AI回复:“您想什么时候出发?”
- 用户第三句话:“明天下午出发。”AI回复:“为你找到如下车次,请问你想要第几个。”
- 用户第四句话:“那就第一个吧。“AI回复:“好的,正在为你下单。”
这种我称之为,固定序不可逆填槽,简直笨到了极致。
如果你颠倒顺序填充槽位,AI很可能就智障掉了。
生活中,我们这边一个70岁以上的老人,可以在窗口完成火车票购买,(抛开口音的问题)但是无法通过AI助手完成火车票的购买。
为什么呢?很多比较笨的AI,跟图形界面一样,要求用户适应它的逻辑去完成填充。
这种处理方案,简直违背自然语言处理的这一初衷。
而好的智能助手是可以做到乱序填槽,并且随意改槽位条件的。
例子:
用户第一句话:“我想买一张明天从北京到上海的火车票,我要下午四点出发的,我想要一等座。”
我们可以根据结果,着AI提取槽位,以及反馈的能力。
用户第二句话:“再帮我看看,后天上午十点出发的,二等座也行。”
如果AI能够搞定,那证明可以达到一定的智能化程度了。
以上是应对用户的表述,而在对话服务过程中,还有一个反向管理,完善槽位的引导。
我们可以做一个简单的练习,例如在买电影票的场景,从需求到下单至少需要4个核心槽位。A电影名,B电影院,C场次,D几张票。(选座可以提供默认规则)
想要完成订单的确认,则成功引导用户填充ABCD四个槽位即可。好的完善和引导,则是:
如果用户填充了AB,AI应该追问CD的例子:“我想看《魔童哪咤》,帮我在附近找个最近的电影院。”此时AI需要展示哪几个场次可以选择,然后追问要买几张票
如果填充了ABC,应该追问D的例子:“我想看《魔童哪咤》,附近找个最近的电影院,8点钟左右开场的。”此时AI只需要追问要买几张票即可。
ABCD四个主槽位,无论用户的先后顺序,先填充哪个槽位,后续能够完善填充即可。
人类的表述千奇百怪,无论多少个槽位,人类都可以组织语言联合起来表述。乱序填充槽位才是智能化,自然表述的的基本要求。
三、篇幅所限的阶段性结尾
笔者刚进入AI行业NLP领域工作的时候,梦想着有一天能够做出伟大的产品。
什么算伟大的产品,每个人定义不同。
从业以来,就我们目前技术发展的前提下,能做的真的有限。科幻影视作品里面的超级人工智能,目前来看似乎遥不可及。
遂化为小白用户,提出一个最为直白的需求——“我就想要一个聪明且好用的智能助理,能够满足我生活中的各种需求。”
所以在当前的技术实现下,输出了过往在工作中一些评测产品以及处理问题的具体表现。
实际上,原本在意图理解这个单元模块,有更多评测点去列举,但是受限于篇幅以及能力所限,删掉的一些内容。
用提问的方式,列举一下我删除掉的指标:

上述我提到的种种问题,其实都可以设计考核指标。
笔者可以讲清楚是什么,解决方案以及思考后续会以独立文章的形式分享。
既然是评测指标,自然是有权重之分。
有些是可以努力做好的部分,比如前文中就【意图理解】这个维度提及的5个模块,各个例子的列举,都是基于用户的对话日志后台,是实际业务中非常高频的。
而另外的有些是重点加分项,有些是附加加分项来评定。
【意图理解】越深,越到位,都是让我们极尽所能,在【意图理解】这个维度,无限逼近超级人工智能的种种思考。
而笔者的思路是,用户尽管提要求,余下的尽量去想办法去实现,如此才能够尽量去逼近伟大的产品。
以上,关于本文第一大模块【意图理解】的部分,就此完结。
后续文章会补充余下的部分,并以相同的形式去进行补充解释和完善。
- 【服务提供】——当用户提出需求时,有无高质量的反馈,重点是关于服务价值提供的多样性,反馈表现,价值大小来设计评测指标。
- 【交互流畅】——当用户与AI进行交互的时候,重点就交互反馈过程中的性能指标,体验是否流畅来设计评测指标。
- 【人格特质】——智能助手是否具备足够的魅力/人格化特质,就情绪表现,情商,共情、个性化、拟人化程度来设计评测指标。
作者:饭大官人,不折腾会死星人,微信公众号:fanfan19860403《游戏运营:高手进阶之路》作者。熟悉游戏领域、人工智能-自然语言处理领域。
本文由 @饭大官人 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议









如果能够针对个别指标举例给出具体的指标计算公式就更好了^0^~
写的特别好,最近在做车载语音智能化的课题,思路有重叠,看了您写的感觉更清晰了!
这个不对!机器人是能主动思考的。您这个定义只是一个程序,需要操作的。
你好,认真读了你的这个系列文章,受用很多,能留下联系方式吗?希望可以深入探讨
期待后续
后续已发 💡