
 起点课堂会员权益
起点课堂会员权益智能对话机器人如何设计产品主流程框架?
智能对话机器人是一种极度类人的人与物的沟通媒介,它可以帮助个体通过类人的沟通方式达到自己的目的。你知道智能对话机器人产品主流程框架是如何设计的吗?本文作者对此进行了详细介绍,与大家分享。

开篇(《智能对话机器人产品设计——开篇》)里我们已经简单介绍了智能对话机器人的产生背景以及当下的现状(并非理想中的智能),AI产品经理应该如何做好充足的准备以便于设计出一款在当下技术边界内有较好用户体验的对话机器人产品。
从功能实现层面对智能对话机器人的做了五个类别区分,如果从对话机器人实际解决的问题范围来看,也可以将其分为两个大类:封闭域对话机器人和开放域对话机器人。不难从字面上就很容易理解,封闭域即为在限定的领域内完成对话,而这些领域是由设计产品的人进行人为限定的;而开放域则没有限制,一般支持的会话是广泛领域内的公共范畴。
但就目前的最终效果来看,开放域对话机器人很难做好用户体验,一旦给用户设定什么问题都可以问什么话都可以聊,那用户就一定会问出bug…实际大多数的产品设计目前都聚焦于一个或几个特定领域内(开放域仅作为分支补充功能),便于为目标用户提供更好的产品体验。
智能对话机器人的主体框架:
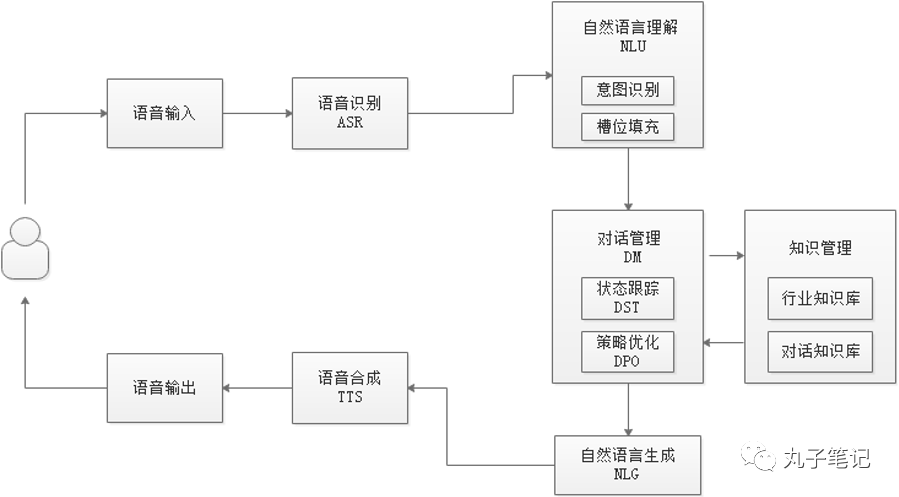
通常来说如上图所示,智能对话机器人整个框架分为7个模块,但也可根据实际设计的产品功能进行增减,增减的部分主要聚焦在输入/输出的部分,后面会进行具体解释。
01 输入/输出
对话机器人,那对话就是一个核心的交互方式,那么基于具体的产品是软件or硬件,硬件里面是有屏or无屏,其实都会在输入输出的交互方面产生细微的差异。
语音输入当然是便捷的,它突破了用手打字的部分局限,从而扩展了智能化产品的使用场景,比如开车时的语音地图导航,比如临睡前的语音关灯等等。
另一方面,我们必须意识到,语音输入自身存在的局限性:
- 语音输入因为有后面一步语音识别的技术瓶颈(一方面是远场语音识别的准确率,一方面是各类方言的识别准确率),会有一定的识别错误导致最终结果翻车,影响用户体验,给用户造成“智障机器人”的感觉;
- 语音输入需要一定的使用条件,并不是所有用户在何时何地都可以进行语音这种交互方式的输入,用户有需要保护隐私的使用场景;
而语音输出的局限性也显而易见,一旦机器人的回答话术比较长,那么对于用户来说等待机器人输出完整的语音所花费的时间绝对比通过视觉获取同等信息高出很多倍,所谓“一目十行”即是这个道理。毕竟人类已经掌握了通过视觉快速从大量文字图片信息中获取关键信息的技巧。
因此,如果你的产品有让用户可以进行操作的屏幕,那么在输入/输出端,最好支持多模态,比如语音、文字、以及触觉(通过屏幕点击、完成部分对话场景的信息交互)等适应用户复杂的使用场景,提升用户使用效率。
当然,在信息输出的部分,目前也有多款纯软件类产品仅支持文字图片等结果输出,不支持语音输出,究其原因大概有以下3个方面:
- 信息输出效率低;
- 基于第一点,部分产品场景不适合使用语音输出,比如任务型对话机器人结果较为复杂时;
- 产品实现复杂度增加,进行语音输出过程中是否支持打断,打断后是否需要重新唤醒,上次对话结果是否保留等等;
综上:在输入输出方面,可依据自己的产品场景进行合适的选择。
02 语音识别(ASR)/ 语音合成(TTS)
一般的智能对话机器人产品目前直接使用主流厂商提供的功能即可,包括:讯飞、百度、腾讯等。业内总体语音识别准确率在量级上相差不是很大,一般分免费和付费两种,用户体量小一般免费即可够用,稍大点的产品需要对比各家不同的资费进行选择即可。
在语音识别方面目前可能存在的问题是:大厂的语音识别语料基于更广泛的场景,而一旦你的产品属于垂直领域,即有一些特殊行业的词汇时,就会出现通用识别能力识别不准的情况,从而造成整个流程识别错误最终反馈给用户错误的结果。
当然,大厂也是可以做定制的,目前也支持用户进行词库的导入,从而在一定程度上解决这个问题。同时,多数厂商也有语音识别纠错的功能,总体体验都还可以。此处不再赘述,相关信息可自行查询。
03 自然语言理解(NLU)
这个模块即为机器人理解用户输入信息的核心模块,即让机器人“理解”用户。主要分为2个部分:意图识别(intent)和槽位填充(slot filling)。
意图识别需要由产品所需要支持的功能进行圈定,可以识别单个意图也可以识别多个。比如,你是一个单纯的查天气的机器人,那么你的意图识别领域就是需要界定出用户输入的信息是否是“查天气”,又比如你是一个出行领域的机器人,那么你的意图识别就需要确定是“订机票”还是“订火车票”“订汽车票”等等。
意图识别目前涉及到的技术主要分两大类:基于规则、基于算法。而意图识别的难点就在于每一种意图都有多种多样的表达,比如用户要“订机票”,可能存在的表达如下:
- 我要订机票
- 帮我查一下从北京飞上海多少钱
- 我下周要出差,查下航班
- 查一下五一飞厦门的头等舱
仅仅基于规则很难准确识别用户的多种表达方式,所以目前主流做法是【少量规则+算法模型】,而比较主流的算法模型包括:CNN、LSTM等。
槽位填充即是想要达成目标意图所需要的必备或者识别等关键内容。比如意图识别为“查天气”那么所需要填充的槽位就是“地点”,机器人需要回答天气,必须是指定城市或区县的天气,这个“地点”即为必填的【槽位】。而如果是“订机票”的场景,那么需要的槽位就包括“出发地”“到达地”“出行日期”,而用户如果说了机票业务场景内的“公务舱”则可以作为非必填但需要识别的实体信息。
04 对话管理(DM)
一般多轮对话机器人均需要做对话管理,因为对话是持续进行的,所以每次机器人进行答复时需要针对当前的会话状态给出合适的回复。对话管理分为两个模块:状态跟踪(DST)、策略优化(DPO)。
状态跟踪就是表示:t+1 时刻的对话状态,依赖于之前时刻 t 的状态,和之前时刻 t 的系统行为,以及当前时刻 t+1 对应的用户行为。因此确认当前意图和槽位信息是状态跟踪的核心,需要明确当下的对话状态进展到哪一步。
策略优化则是根据状态跟踪的结果给出机器人应该在当前对话状态下需要给出的正确回复。
举例来说在“订机票”这个对话过程中,需要根据用户当前不同的对话状态节点给出不同的回复,如下两种状态:
场景一:
- 用户:订机票
- 机器人:请问您要订去哪里的机票呀?
- 用户:去北京
- 机器人:请问您从哪个城市出发?
- 用户:上海
- 机器人:请问您打算什么时候出发?
- 用户:下周一
- 机器人:给出具体的机票信息结果
场景二:
- 用户:我要订从上海飞北京的机票
- 机器人:请问您打算什么时候出发?
- 用户:下周一
- 机器人:给出具体的机票信息结果
从以上两种场景可以看出,机器人给出的回复需要判断用户之前信息给出的状态,如果设定的必填【槽位】全部满足则给出最终结果,否则需要根据设定的顺序依次进行询问。当然,这里面还有一种情况是,用户在对话过程中跳出了当前的意图,比如订机票的过程中询问目的地的天气,那么机器人需要根据已有的设定给出新的意图所需要回答的话术。
05 自然语言生成(NLG)
自然语言生成即是通过对话管理之后确认需要给用户的答复内容的过程。目前,多数产品的NLG模块仍是采用传统的基于规则的方法加上新的基于模型算法的生成式对话。
基于传统规则,如上文举例的“订机票”的场景,即可简单的通过规则的方式实现。但是,如果在开放域进行对话聊天,那就很难基于规则去完成会话设计,同时基于规则的回复会让用户感觉机器人死板,无趣。而通过模型生成的语言回复,则更加多样,也会在产品层面体现出机器人的情感态度等等。
当然,自然语言生成在其他应用场景有更为广泛的应用,比如写诗词、写春联、写文章、生成文本摘要等等,此处就不再展开讲了。
以上为智能对话机器人产品主流程框架设计的详细介绍,希望对你有所帮助~
本文作者:丸子妹,微信公众号:丸子笔记
本文由 @丸子笔记 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









目前的打断机制,你也是跟根据关键词来设置的吗?
如果是指对话过程被打断,那么打断机制其实包含两个方面问题:
1.如何判定打断;
2.如何恢复对话;
针对问题1,需要通过主导者制定规则给到机器人,比如重新唤醒、接打电话等;
针对问题2,则是包含2个层面的机制:a.记录用户的对话历史;b.主动(指定中断时间)/被动(等用户重新对话)重新启动对话;
对话过程中,对话被主动打断,打断后,机器人是恢复对话是重复前面说的那句话,还是执行下个流程;
结论:任务型对话机器人如没有走到流程结束,那么采用的是恢复之前的对话,依照保存的会话的最新对话状态节点告知用户,进行显性确认。否则,可执行下一个流程。
原因:产品设计的核心是满足用户当前情景下的需求,对话被打断且流程未到最终结果,那我们认为用户需求并没有被满足,基于产品效率(快速进入之前流程)和用户体验(因对话中断导致用户不知道机器人已经收集到哪些信息,需要重新确认),应在会话恢复时将保存的最新对话节点状态告知用户,并需要用户进行显性确认,确认是否继续,如用户给予肯定确认则按照当前意图继续进行,否则进入下一个流程。
明白,怎么联系,加你好友,交流一下
自然语言生成是靠什么实现的呀?会有对应的语料库吗?
NLG也是需要根据机器人所覆盖的领域储备相应的语料库,否则生成的内容就不可控了~
但目前因NLG在实际对话生成过程中的应用瓶颈:采用神经网络的高级NLG(更贴合人类自然语言)会出现不可控的风险,因此多数采用的仍然是模板化的NLG,除非是开放域的闲聊机器人~
写的真好,通俗易懂~
感谢认同~ 😉