
 起点课堂会员权益
起点课堂会员权益案例分析:基于RFM的客户价值分析模型

本文用具体实例的方式,在RFM的基础上构建客户价值分析模型,探讨如何对客户群体进行细分,以及细分后如何进行客户价值分析。最终得到LRFMC模型,并将客户群体细分为重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户五类。
本文原始数据与分析思路来自《Python数据分析与挖掘实战》第七章,感谢这本书提供的数据集与分析框架。(这本书很不错,推荐)
一、背景与目标
1.1 背景
在面向客户制定运营策略、营销策略时,我们希望能够针对不同的客户推行不同的策略,实现精准化运营,以期获取最大的转化率。精准化运营的前提是客户关系管理,而客户关系管理的核心是客户分类。
通过客户分类,对客户群体进行细分,区别出低价值客户、高价值客户,对不同的客户群体开展不同的个性化服务,将有限的资源合理地分配给不同价值的客户,实现效益最大化。
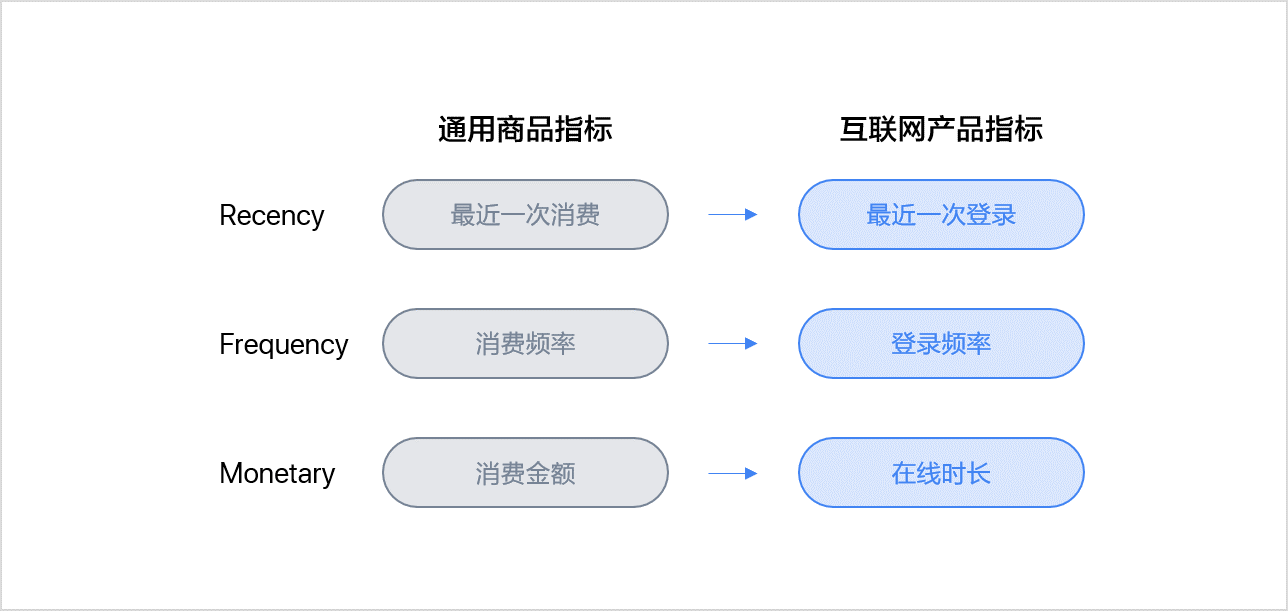
在客户分类中,RFM模型是一个经典的分类模型,模型利用通用交易环节中最核心的三个维度——最近消费(Recency)、消费频率(Frequency)、消费金额(Monetary)细分客户群体,从而分析不同群体的客户价值。
在某些商业形态中,客户与企业产生连接的核心指标会因产品特性而改变。如互联网产品中,以上三项指标可以相应地变为下图中的三项:最近一次登录、登录频率、在线时长。
1.2 目标
本实例借助某航空公司客户数据,探讨如何利用KMeans算法对客户群体进行细分,以及细分后如何利用RFM模型对客户价值进行分析,并识别出高价值客户。
在本实例中,主要希望实现以下三个目标:
- 借助航空公司客户数据,对客户进行群体分类
- 对不同的客户群体进行特征分析,比较各细分群体的客户价值
- 对不同价值的客户制定相应的运营策略
二、分析过程
2.1 分析思路
本实例的数据包含了2012年4月1日至2014年3月31日期间的客户数据,共有6万余条记录。分析中需要用到KMeans算法,且需要将数据分析的结果可视化,便于后期的结论分析,于是采用以下两种工具进行分析:
- jupyter notebook(Python 3.6 )
- Excel 2016
同时数据的属性定义见下表所示,可见维度非常丰富。

考虑到商用航空行业与一般商业形态的不同,决定在RFM模型的基础上,增加2个指标用于客户分群与价值分析,得到航空行业的LRFMC模型:
- L:客户关系长度。客户加入会员的日期至观测窗口结束日期的间隔。(单位:天)
- R:最近一次乘机时间。最近一次乘机日期至观测窗口结束日期的间隔。(单位:天)
- F:乘机频率。客户在观测窗口期内乘坐飞机的次数。(单位:次)
- M:飞行总里程。客户在观测窗口期内的飞行总里程。(单位:公里)
- C:平均折扣率。客户在观测窗口期内的平均折扣率。(单位:无)
首先对原始数据进行探索,清洗异常记录,再根据上述公式将原始数据表变换得到LRFMC模型建模需要的新数据表,接着对新数据表的数据进行属性规约、数据变换、Python建模、结果分析,便能得到最终的结果。
总体思路与流程见下图:
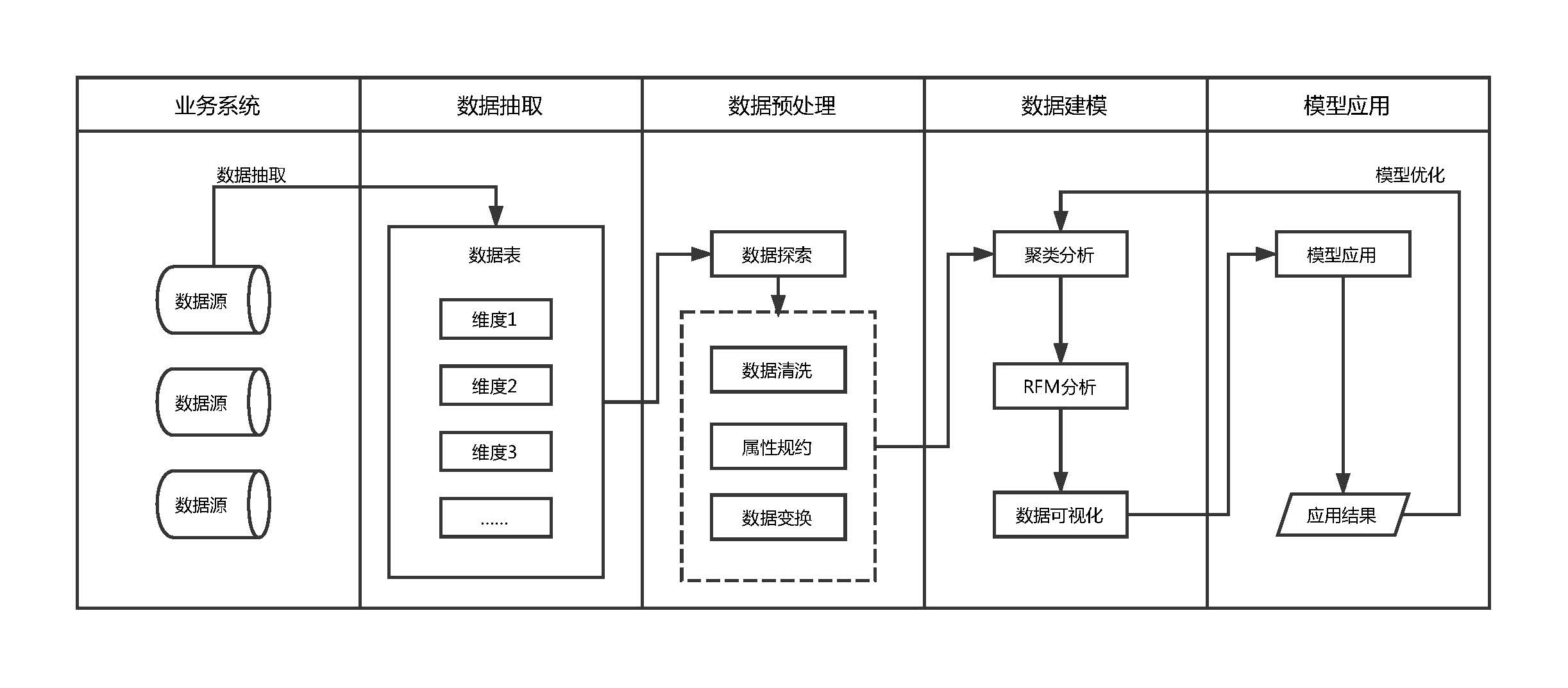
由于本实例中的数据已经得到,便不需要在业务系统中抽取数据,直接开始对数据进行预处理即可。
2.2 数据预处理
2.2.1 数据探索

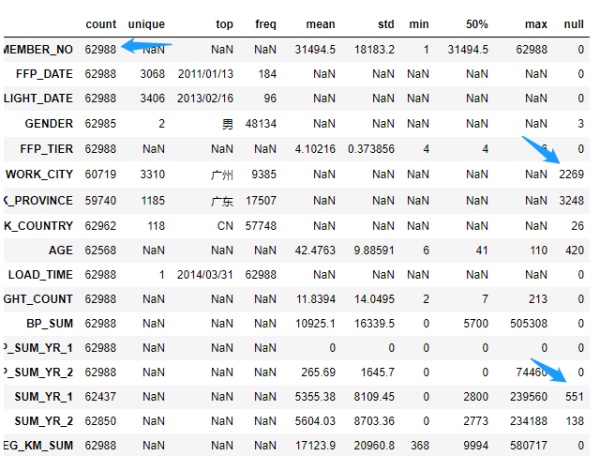
经过初步的数据探索,发现数据有几点特征:
- 共62988条记录
- 部分维度存在缺失值,WORK_CITY缺失2269条,SUM_YR_1缺失551条,SUM_YR_2缺失138条
2.2.2 数据清洗
此处主要清洗两类异常数据:
- 缺失值:票价为null的数据(注意不是票价为零)
- 异常值:票价为0、平均折扣率不为0、总飞行公里数大于0的数据(折扣不为0,仍有飞行里程,说明客户必然是花钱买票飞行的,如果此时票价也为0,说明是错误数据)
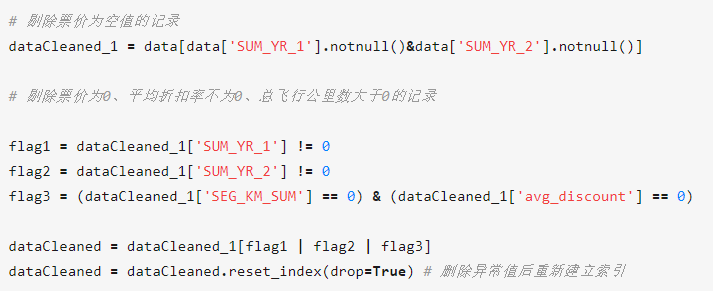
共清洗944条异常数据,得到62044条有效记录。
2.2.3 属性规约
根据LRFMC模型,选取与模型强相关的6个属性:LOAD_TIME、FFP_DATE、LAST_TO_END、LIGHT_COUNT、SEG_KM_SUM、avg_discount。删除其他冗余的、弱相关的属性,得到属性选择后的数据集。

2.2.4 数据变换
构建包含L、R、F、M、C五项指标的新数据表,并对应属性定义表,得到LRFMC模型中五项指标的计算公式:
- L = LOAD_TIME – FFP_DATE. (观测窗口结束日期 – 入会日期)
- R = LAST_TO_END. (最后一次乘机时间至观测窗口结束时长)
- F = FLIGHT_COUNT. (观测窗口内的飞行次数)
- M = SEG_KM_SUM. (观测窗口的总飞行公里数)
- C = AVG_DISCOUNT. (平均折扣率)
利用2.2.3中的数据表计算得到变换后的数据表:
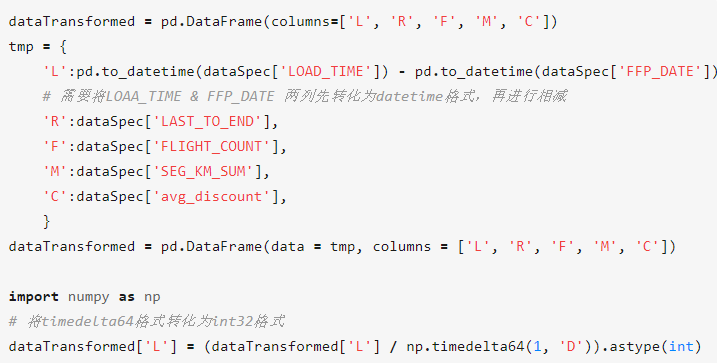
结果如下图所示:
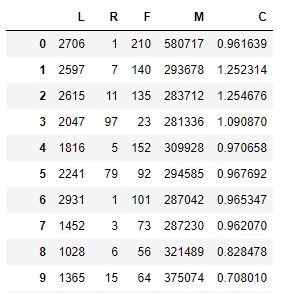
从表中可以发现:每个指标的数据取值范围分布较广,为提高后续聚类分析的准确性,还需要将L、R、F、M、C五类数据进行标准化处理。标准化方法有极大极小标准化、标准差标准化等方法,此处采用标准差标准化的方法对数据进行处理。
结果如下图所示:
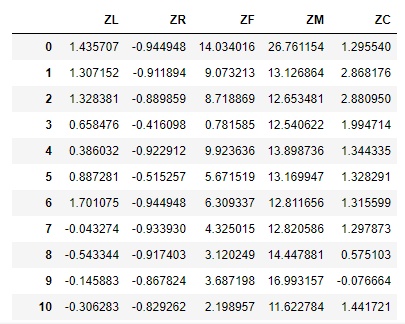
标准差标准化后,得到包含ZL、ZR、ZF、ZM、ZC五项指标的数据集。
2.3 数据建模
客户价值分析模型构建主要分为两个部分:
- 利用K-Means算法对客户进行聚类分析,得到细分的客户群
- 对细分的客户群进行特征分析,得到客户价值分析模型
2.3.1 聚类分析
采用K-Means聚类算法对客户数据进行分群,共分为5类:

得到结果后,将结果转化为DataFrame对象:
以及对62044位客户贴上群体标签,记为1、2、3、4、5五类,并输出带有标签的Excel文件。结果如下图所示:
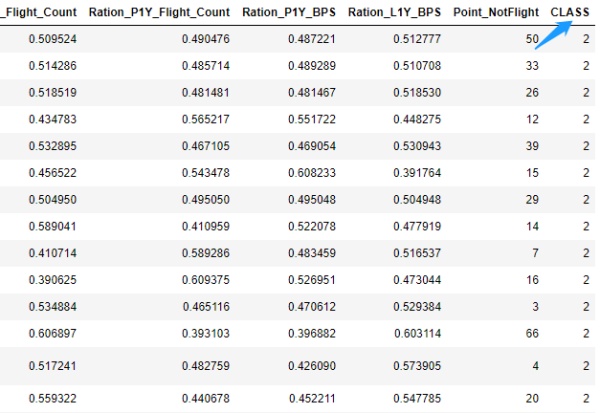
2.3.2 特征分析
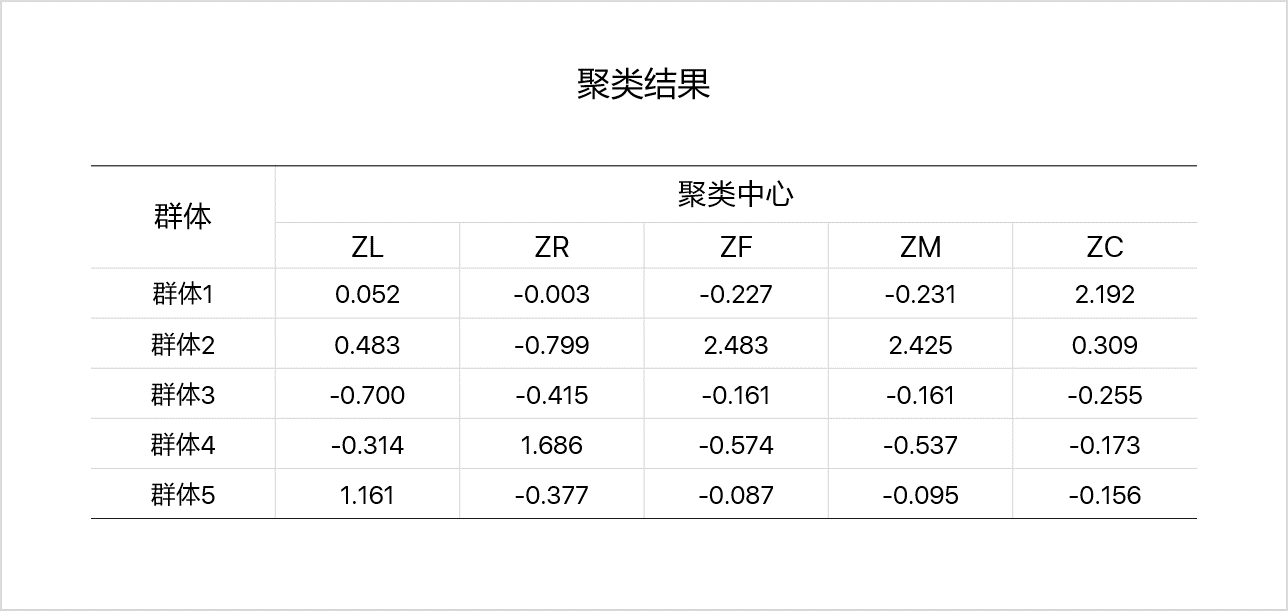
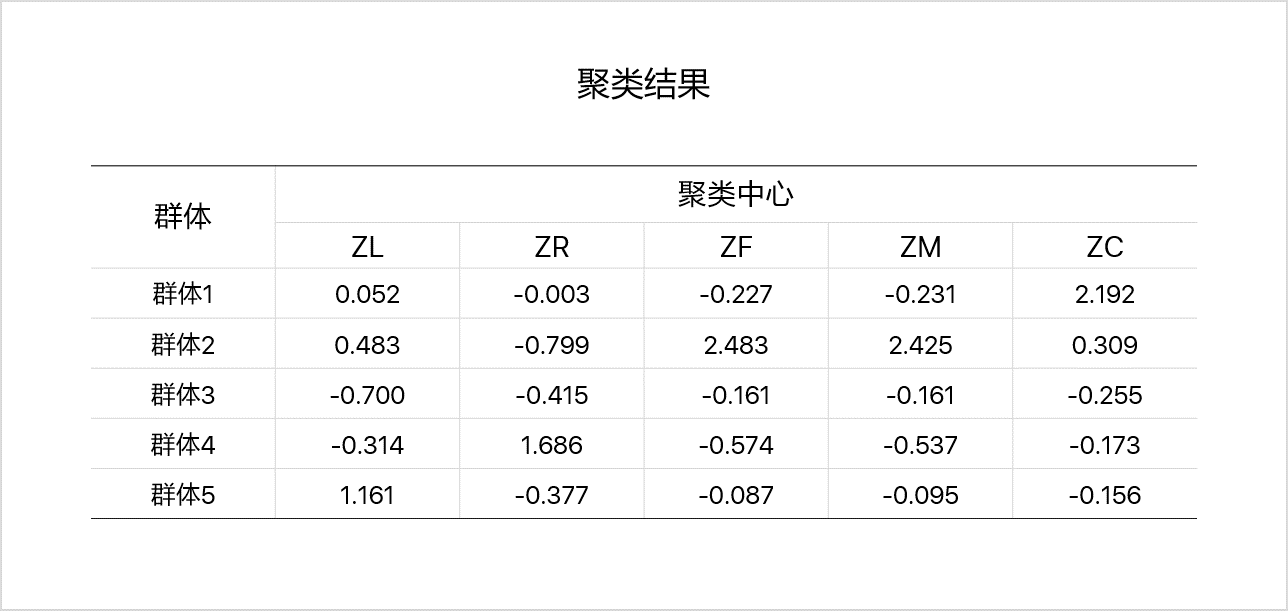
对2.3.2中的聚类结果进行特征分析,如下图所示:
分析:
- 群体1的C属性上最大
- 群体2的M、F属性属性最大,R属性最小
- 群体3的L、C属性最小
- 群体4的R属性最大,F、M属性最小
- 群体5的L属性最大
其中每项指标的实际业务意义为:
- L:加入会员的时长。越大代表会员资历越久
- R:最近一次乘机时间。越大代表越久没乘机
- F:乘机次数。越大代表乘机次数越多
- M:飞行总里程。越大代表总里程越多
- C:平均折扣率。越大代表折扣越弱,0表示0折免费机票,10代表无折机票
对应实际业务对聚类结果进行分值离散转化,对应1-5分,其中属性值越大,分数越高:

同时针对业务需要,及参考RFM模型对客户类别的分类,定义五个等级的客户类别:
(1)重要保持客户
- 平均折扣率高(C↑),最近有乘机记录(R↓),乘机次数高(F↑)或里程高(M↑)
- 这类客户机票票价高,不在意机票折扣,经常乘机,是最理想的客户类型
- 公司应优先将资源投放到他们身上,维持这类客户的忠诚度
(2)重要发展客户
- 平均折扣率高(C↑),最近有乘机记录(R↓),乘机次数高(F↓)或里程高(M↓)
- 这类客户机票票价高,不在意机票折扣,最近有乘机记录,但总里程低,具有很大的发展潜力
- 公司应加强这类客户的满意度,使他们逐渐成为忠诚客户
(3)重要挽留客户
- 平均折扣率高(C↑),乘机次数高(F↑)或里程高(M↑),最近无乘机记录(R↑)
- 这类客户总里程高,但较长时间没有乘机,可能处于流失状态
- 公司应加强与这类客户的互动,召回用户,延长客户的生命周期
(4)一般客户
- 平均折扣率低(C↓),最近无乘机记录(R↑),乘机次数高(F↓)或里程高(M↓),入会时间短(L↓)
- 这类客户机票票价低,经常买折扣机票,最近无乘机记录,可能是趁着折扣而选择购买,对品牌无忠诚度
- 公司需要在资源支持的情况下强化对这类客户的联系
(5)低价值客户
- 平均折扣率低(C ↓ ),最近无乘机记录(R ↑ ),乘机次数高(F ↓ )或里程高(M ↓ ),入会时间短(L ↓ )
- 这类客户与一般客户类似,机票票价低,经常买折扣机票,最近无乘机记录,可能是趁着折扣而选择购买,对品牌无忠诚度
根据聚类结果,对应上述五类客户类型,进行匹配,得到客户群体的价值排名:
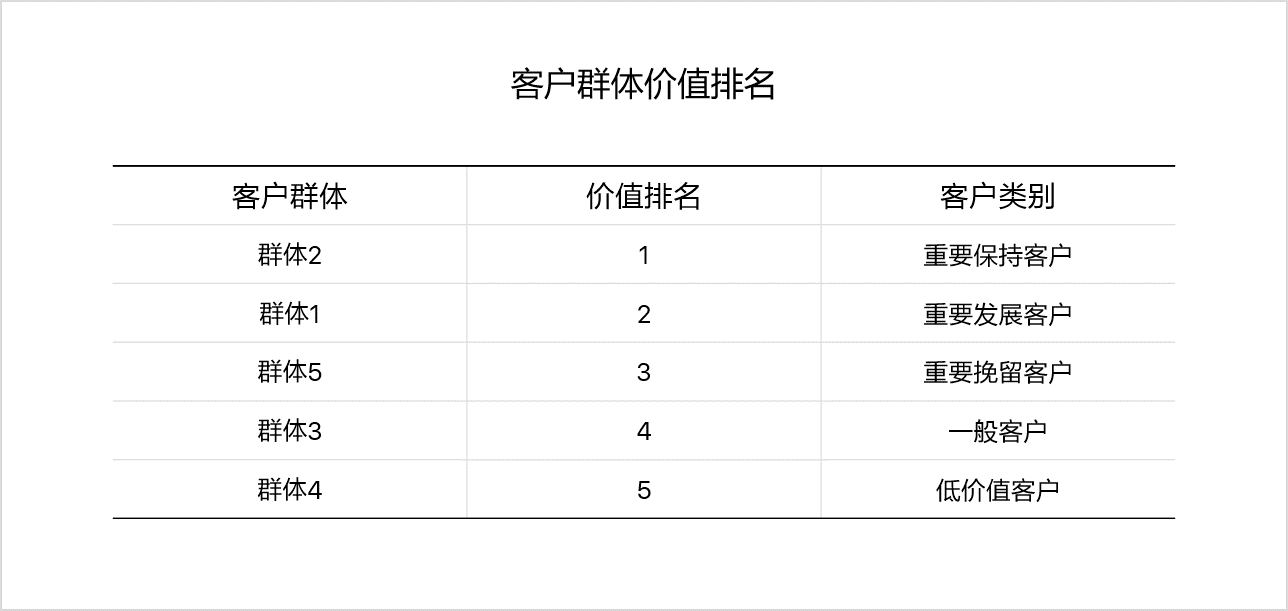
在数据与处理时,我们已经将62044位用户与客户群体一一对应,现在每类客户群体也对应了客户价值,至此得到了62044位客户的价值分类结果,建模完成。
三、分析结果
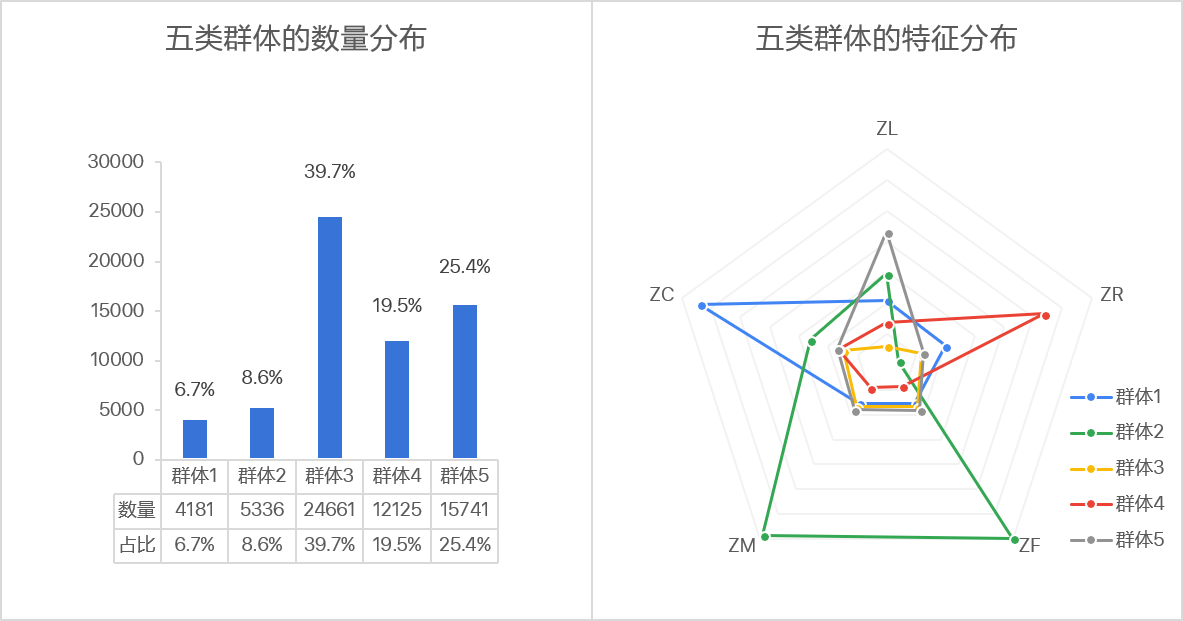
根据建模结果,发现该公司的五类不同价值的客户数量分布如图所示:
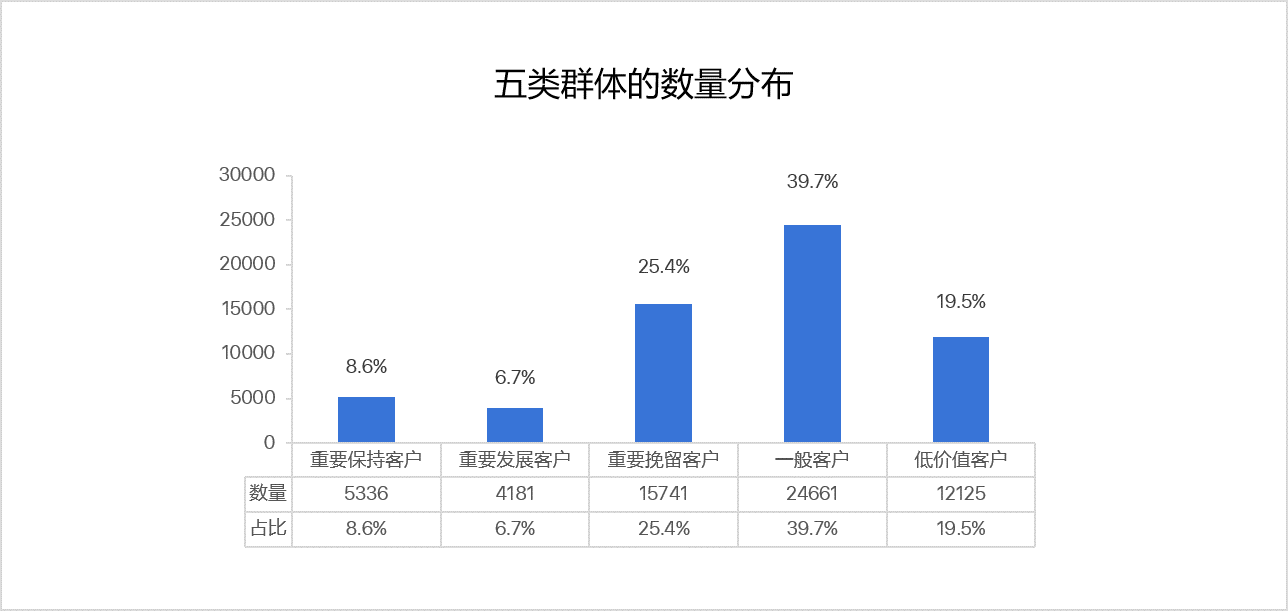
分析:
- 重要保持客户、重要发展客户占比15.3%,不足两成,整体较少
- 一般客户、低价值客户占比59.3%,接近六成,整体偏多
- 重要挽留客户占比25.4%,接近四分之一,整体发挥空间大
按照20/80法则:一般而言企业的80%收入由头部20%的用户贡献。从上图中也能发现:忠诚的重要保留客户、中发展客户必然贡献了企业收入的绝大部分,企业也需要投入资源服务好这部分客户。
同时,重要保持客户、重要发展客户、重要挽留客户这三类客户其实也对应着客户生命周期中的发展期、稳定器、衰退期三个时期。从客户生命周期的角度讲,也应重点投入资源召回衰退期的客户。
一般而言,数据分析最终的目的是针对分析结果提出并开展一系列的运营/营销策略,以期帮助企业发展。在本实例中,运营策略有三个方向:
- 提高活跃度:提高一般客户、低价值客户的活跃度。将其转化为优质客户
- 提高留存率:与重要挽留客户互动,提高这部分用户的留存率
- 提高付费率:维系重要保持客户、重要发展客户的忠诚度,保持企业良好收入
每个方向对应不同的策略,如会员升级、积分兑换、交叉销售、发放折扣券等手段,此处不再展开。
作者:@沈涛,产品运营新人,擅长数据分析。公众号:沈涛先生,欢迎关注
本文由@沈涛 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 unsplash,基于 CC0 协议















这篇文章主要还只是提供了一个RFM的思路,后面关于如何用KMEANS分类,并没有完全详细的说明,没有基础的人可能会看不懂
为什么一定要分成5类呢,4类或6类不行吗
作者大大 有源数据吗 想自己跑一遍
你好,文章最后面写的,每个方向对应不同的策略,如会员升级、积分兑换、交叉销售、发放折扣券等手段,本章不展开在哪里有比较详细开展讲吗 文章很实用真的很棒
您好先生,我是营销小白,现在学客户群体细分,然后看到了这个模型,请问您能跟我说说在不知道细分市场的时候,主要往哪方向进行收集数据吗?
我现在在学营销,但是我还没有一个比较完整的逻辑,不知道学完这个细分之后下一步要做什么,怎么去规划,需要看那些书,您能给我写建议吗?
非常感谢!
为什么每一篇都这么棒,超喜欢!沈哥有没有公众号呀
读了作者写的文章,感觉是醍醐灌顶,从分析思路到整个结果的输出都很清晰明了。自己也在深入学习用户群体细分这一块,可是自己从来没有写过编程,又该如何学好Py呢?
最近一直思考想学习某一款数据分析工具,作者是否能够指点迷津呢?
可以,你说
想学习一款软件,只用于像本文这样的数据分析,您推荐什么软件,本人有一定数学基础;假如学习Py,怎么能快速达到运用软件分析数据的能力,意思是不想学习其他对我来说用不上的编程语言只想学习一块数据处理的功能,该从哪学比较迷茫,想问下您当时是怎么学的
我猜你是希望用以致学地来学习技能,我可以简单推荐一条路线。
Week1:看Python讲述数据分析的教程,重点学习Numpy、Pandas、Matplotlib。推荐《利用Python进行数据分析》,切记要敲下书中的每一行代码。专注一本书,不用广泛地下载Python资料。
Week2:找Python数据分析项目临摹,掌握Week1中学到的几个库。推荐shiyanlou.com,里面有很多数据分析的小项目,切记要完整地跟着提示做,而且要有产出。这时候需要有得到产出后的掌控感,争取一周做3个数据分析项目。
Week3:继续做项目,继续看书。推荐kesci.com & shiyanlou.com,这时候你对Python有基础了,可以自己去Baidu、Zhihu、CSDN找材料看,找项目做。争取做2个项目。
Week4:可以做自己的数据分析了。把之前的项目经验用在这里,边做边在网上、书上查找灵感和方法。
Week5:你自己不是零基础了,可以自己给自己定目标了。
Note:Python是工具,做的时候需要时不时地在网上查找指令代码,推荐yiibai.com,记得在项目中一遍一遍地熟悉它的功能。
感恩,感谢!
谢谢你的分享,干货满满
厉害