
 起点课堂会员权益
起点课堂会员权益数据中台实战(二):基于阿里OneData的数据指标管理体系
本文将通过具体案例来介绍OneData的实施流程,继而介绍阿里OneData数据体系中数据指标的管理和数据模型的设计,最后再为大家讲数据看板的设计。

上一篇文章讲了《数据中台实战(一):以B2B点电商为例谈谈产品经理下的数据埋点》,本文我们先以一个例子实战介绍OneData实施流程。接着再讲阿里OneData数据体系中数据指标的管理、数据模型的设计。最后讲一下数据产品中,数据看板的设计。全是实战干货,看完本文你就会知道数据中台最核心的内容。
阿里OneData实施过程实战
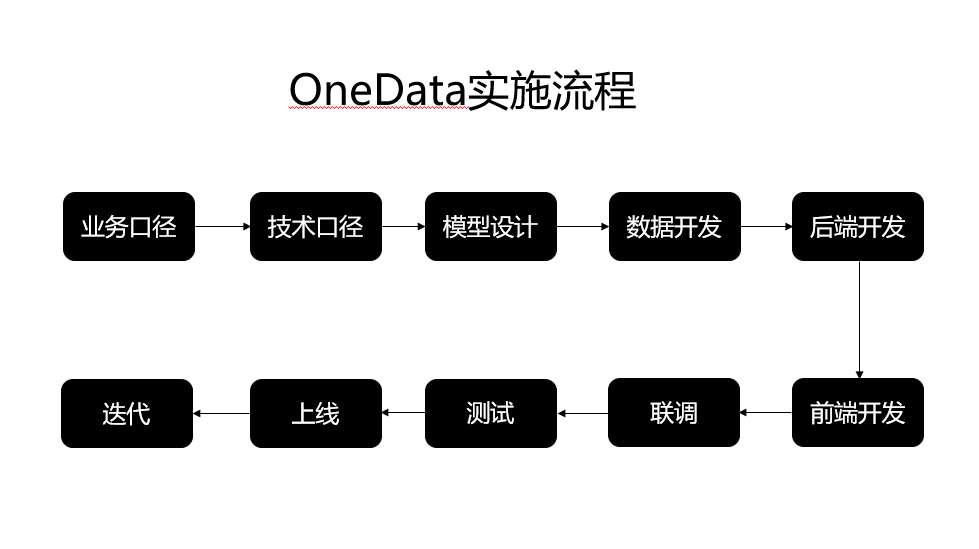
比如当时我们运营提了一个比较有指导意义的数据指标叫爆款率,我们以爆款率为例先说一下OneData每个步骤实施的流程和涉及的角色。
第一步:要确定指标的业务口径
业务口径应该由数据中台的产品经理主导,找到提出该指标的运营负责人沟通。首先要问清楚指标是怎么定义的,比如运营说爆款率的定义分子是是专场中商品销售件数超过20件的商品数,分母是专场内的总商品数(专场如上图所示,商品会放在运营人员组的一个一个专场里面)。
这里面有几个坑:
1. 这个20件可能是运营拍脑袋定义的数据,这时要协调我们的数据数据分析师看下历史专场销售件数的分布找出最合理的值,然后和运营基于数据再一起定义最终的阈值。如果历史数据专场销售件数大部分都远远超过20件那么这个指标就所有的专场都是爆款专场,就没什么意义了。
2. 商品的销售件数超过20件,其中有一个十分有争议的字眼那就是销售,怎么定义销售?是下单就算,还是支付才算?考虑不考虑退款?如果考虑退款是发起退款就算还是退款实际发生后再算?其实是有很多问题要考虑的。最终和运营确定为该专场支付后的商品件数除以专场商品的总件数。
3. 销售的商品件数是按商品销售的件数还是按照商品下SKU的销售件数,这个是要搞清楚的,可能运营不关心这个事,但是影响到模型的设计。
处理完这些坑后关于指标的定义还需要问这几个问题。我们统计的维度是什么?比如爆款率的计算维度是专场内商品的维度,一个是要专场内,一个是商品,原子指标就是销售款数。还有就是统计周期,一般统计周期分为按小时、按天(当天)、按业务周(运营自己定义的统计周期)、按自然周周、按自然月月、按年,还有就是截止到昨天也是比较常用。爆款率的统计周期是统计专场开始到结束时间内的销售件数。
接下来要问清楚这个指标有什么用,给谁用。
不是所有的指标都有开发的意义,因为后面你会发现我们数据中台前期每做一个指标都会花费大量的人力资源,所以一定要考虑这个指标的性价比,我们投入这么多资源,能够给公司带来什么,要么直接和交易额相关,要么就是能节省运营同事大量的工作时间,节省人力成本也是为公司省钱嘛。
比如我们的爆款率是给商品负责人看的,专场的商品是由商品运营人员组的,爆款率就决定这个运营人员的组货能力,组货能力强的商品运营一定是能够给公司带来更多的交易额。这样公司就应该多投入资源给那些爆款率比较高的那些运营人员。这样就很清楚了,我们的爆款率是给运营负责人和商品运营看的。
另外我们的商品运营会长时间在市场选货,那我们团队决定把这个指标做成移动端可看,并且商品运营人员可以实时查看爆款率这个指标。
第二步:要确定指标的技术口径
技术口径是由建模工程师主导,此时数据中台产品经理要和模型设计师沟通整个指标的业务逻辑,另外就是要协调业务方的技术开发人员和我们的建模工程师一起梳理数据库层面需要用到表结构和字段。
一定要精确到字段级别,比如我们的爆款率涉及到专场表、商品表、订单表、涉及的字段有商品的销售款数(需要关联专场和商品表)、专场的总商品件数等字段。
这些字段都确定好后,就能初步定下来这个指标能不能统计,如果不能统计这时产品经理应该主动协调运营告知,并且还要告诉运营同事做了哪些功能才能统计这些指标,接下来就是协调业务方产品经理讨论是不是要做这些功能。
第三步:原型设计和评审
此时由数据中台产品经理主导设计原型,对于爆款率来说我们要一方面要展示他们的实时销售件数,另外一方面要实时展示爆款率的变化趋势,加上专场的转化率(支付人数/UV)就可以综合判断这个专场的质量,当运营人员发现转化率和爆款率比较低时再结合商品的数据及时把一些表现比较差劲的商品下架,让销量好的商品得到更多的曝光机会。
原型的评审分为内部评审和外部评审。
内部评审要拉上我们的架构师、建模工程师、数据开发工程师、后端开发工程师、前端开发工程师、UI,一起说明整个功能的价值和详细的操作流程,确保大家理解的一致。接下来就要和我们的运营根据原型最终确定问题。比较重要的功能要发邮件让我们的运营进一步确认,并同步给所有的运营同事保证大家的口径一致。
第四步:模型设计
此时主导的是我们的模型设计工程师,按照阿里的OneData建模理论的指导,模型设计工程师会采用三层建模的方式把数据更加科学的组织存储。分为 ODS(操作数据层),DWD(明细数据层)、DWS(汇总数据层)、ADS (应用数据层),这是业务对数据分层常用的模型。模型设计工程师要清楚的知道数据来源自那里,要怎么存放。
关于数据建模下一篇文章会更加详细的介绍,在此就不再多说。
第五步:数据开发
此时主导的是大数据开发工程师,首先要和数据建模工程师沟通好技术口径明确好我们计算的指标都来自于那些业务系统,他们通过数据同步的工具如DataX、消息中间TimeTunnel将数据同步到模型工程师设计的ODS层,然后就是一层一层的通过SQL计算到DW*层,一层一层的汇总,最后形成可为应用直接服务的数据填充到ADS层。
另外大数据开发工程另外一个比较重要的工作就是设置调度任务,简单来讲就是什么时候计算提前写好的计算脚本如T-1每天凌晨处理上一天的数据,随着业务的增长,运营会对实时数据的需求越来越大,还有一些实时计算任务的配置也是由大数据开发工程师完成。
第六步:后端开发
此时由后端开发主导,后端开发工程师基于产品经理的功能定义输出相应的接口给前端开发工程师调用,由于ADS层是由数据开发工程师已经将数据注入常规的关系型数据库(如MYSQL等),此时后端开发工程师更多的是和产品经理沟通产品的功能、性能方面的问题,以便给使用者更好的用户体验。
第七步:前端开发
此时主导的是前端开发工程师。原型出来后产品经理会让UI设计师基于产品功能的重点设计UI,UI设计师经过反复的设计,UI最终定型后,会给我们的前端开发工程师提供切图。前端开发工程师基于UI的切图做前端页面的开发。
第八步:联调
此时数据开发工程师、前端开发工程师、后端开发工程师都要参与进来。此时会要求大数据开发工程师基于历史的数据执行计算任务,数据开发工程师承担数据准确性的校验。前后端解决用户操作的相关BUG保证不出现低级的问题完成自测。
第九步:测试
测试工程师在完成原型评审后就要开始写测试用例,那些是开发人员自己要自测通过才能交上来测试的,那些是自己要再次验证的都在测试用例写清楚。此时有经验的产品经理会向运营人员要历史的统计数据来核对数据,不过运营人员的数据不一定准确,只是拿来参考。最终测试没问题产品经理协调运营人员试用,试用中发现的一些问题再回炉重新修改,此时整个研发过程就结束了。
第十步:上线
运维工程师会配合我们的前后端开发工程师更新最新的版本到服务器。此时产品经理要找到该指标的负责人长期跟进指标的准确性。重要的指标还要每过一个周期内部再次验证,从而保证数据的准确性。
经历了以上步骤数据中台的一个指标终于开发完成,可以看得出一个小小的指标需要调动8个角色在一起沟通、确认好久才能完成上线。所以产品经理一定要把握好指标的价值,把有限的资源花费到最有价值的指标上去。下面介绍一下完成这些步骤最核心的数据指标的定义与数据模型的建立。
基于阿里OneData的数据指标管理体系
数据指标的定义
我们在梳理公司的数据指标时发现每个部门对同一个指标定义的不一致,就好比交易额这个指标在电商产品中就是一个模糊的指标,是下单金额、还是支付金额(无包含优惠)、或者有效金额(剔除退款),这样没有一个统一的标准,就很难对部门间做横向的对比。
甚至部门间对同一个指标的口径也存在不一样的情况,更不用说整个指标的开发要涉及运营同事、产品同事、技术同事等,只要一个环节出问题,指标计算就会不准确。我们也是采用阿里的一套针对指标的规范定义,让大家在一个标准下看数据消除歧义。
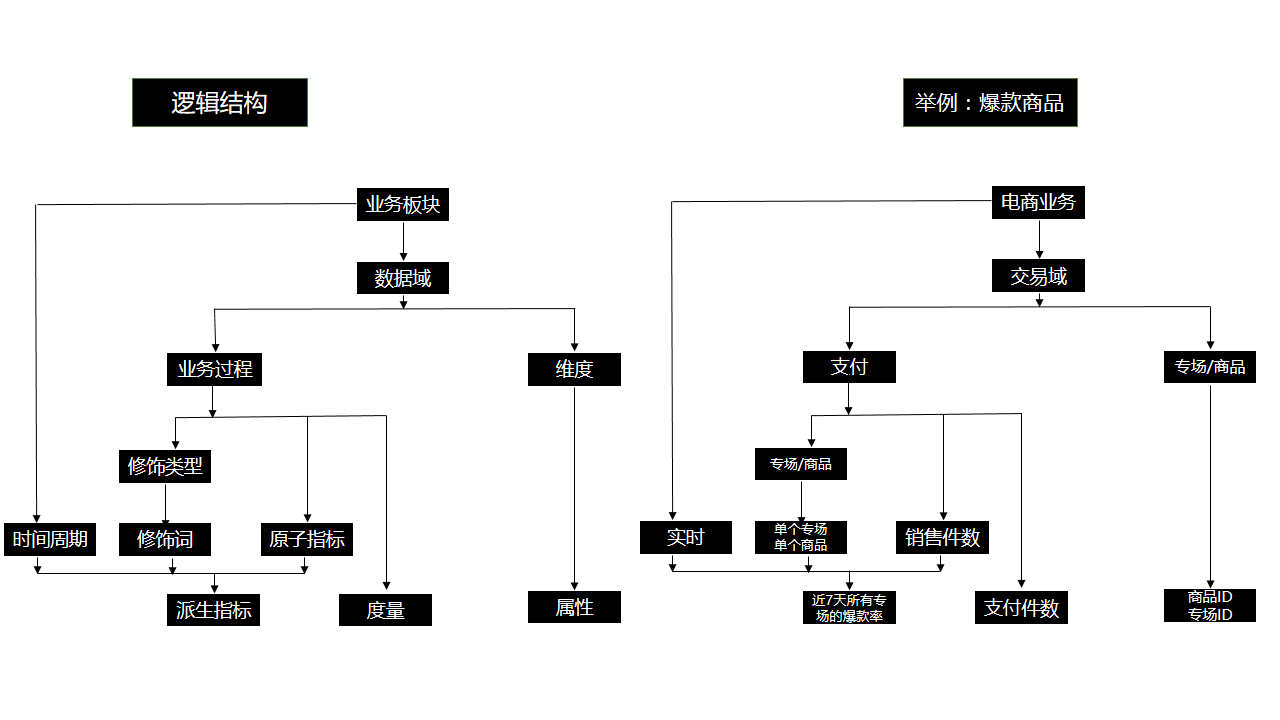
其中的名词定义我们简单过一下:
数据域:面向业务的大模块,不会经常变。比如我们公司有环贸快版打版服务、亿订电商业务、供应链业务等等大的业务模块类似产品线。
业务过程:如电商业务中的下单、支付、退款等都属于业务过程。
时间周期:就是统计范围,如近30天、自然周、截止到当天等。
修饰类型:比较好理解的如电商中支付方式,终端类型等。
修饰词:除了维度意外的限定词,如电商支付中的微信支付、支付宝支付、网银支付等。终端类型为安卓、IOS等
原子指标:不可再拆分的指标如支付金额、支付件数等指标
维度:常见的维度有地理维度(国家、地区等)、时间维度(年、月、周、日等)
维度属性:如地理维度中的国家名称、ID、省份名称等。
派生指标:原子指标+修饰词+时间周期就组成了一个派生指标。
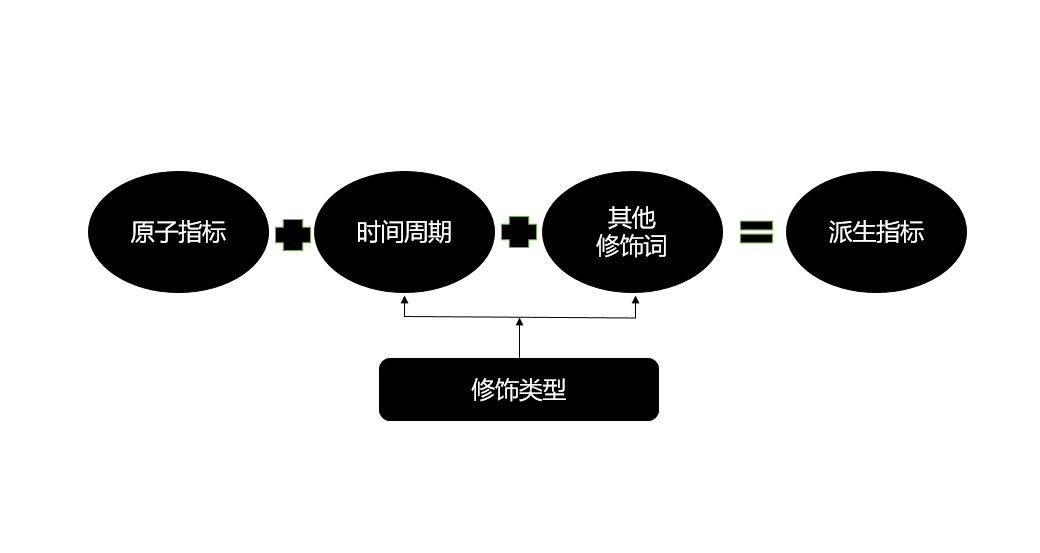
阿里就是用这一套严格的指标拆分体系来管理每个指标。之所以拆这么彻底,就是要消除歧义。条件允许的话可以协调开发同事、测试同事、产品同事口述一下对这个指标的理解看看有什么不同。最大程度的消除指标的歧义。
关于数据指标还有two more thing要谈:
1. 怎么分出指标的重要性。当你不是从0到1跟一个产品,那么此时你可能没你们的运营懂产品的各项数据,当你问你们运营问那些指标是比较重要的,因为他们所处的岗位不同,看事情的角度不同,最后你会发现得到一个结果:一大堆的指标,都重要。此时有个技巧,你可以问人事或者他们的部门负责人要一下部门的绩效考核指标,也许这些就是他们最重要的指标。另外这些指标你可以和部门的负责人沟通,那些是他比较关注的指标,那就应该从这些指标做起。
2. 关于虚荣指标。产品经理需要识别那些是虚荣指标,那些是更有用的指标。比如常见的PV、UV、月活、总用户数、总商品数等等都是虚荣指标,因为他无法直接促进交易额的增长。uv、月活再多有什么用,用户就是不购买。 比如电商行业的主路径的专户率,访问-商品列表、商品列表-商品详情、商品详情-加购、加购-下单转化率这些都是降低流失就能提高交易额的。还有用户的次日留存、7日留存率(新用户7日后是否再次访问)、30日留存率等能直接反应用户的质量和运营做的好坏。商品的动销率(销售款数/上架款数),能直接反映这批商品的好坏。总结一下一般能直接促进交易额、类似转换率这种带分子、分母的指标都是非虚荣指标。
基于阿里OneData的模型设计体系
首先你要知道这些概念。什么是数据仓库、数据仓库和数据库的区别、数据仓库的分层、数据模型的定义。
什么是数据仓库
我用个比喻解释这个概念。
马云:做个报告,我要知道开年到现在还没进入工作状态的有哪些人。
我:好的。
我开始收集:上/下班打卡数据、门口探头统计上厕所频率的数据、手机wifi上网数据、微信群活跃数据、发出零食声音最恐怖的工位数据、有事没事熬电话粥的数据…一周之后,分析报告上我们部门主管的名字占据第一,他让我加了一周的班……
我收集的这些数据我需要把它放在一个地方,我暂且把它放在一个叫“新年好”的文件夹,这些来自不同地方的数据,我需要做维度统一处理、字段命名规范处理、去噪处理(比喻年龄为100这种数据)等等。这是做一份报告,如果做一个平台或者一个项目呢?
比如支付宝的年度账单;网易云音乐的年度报告;那区区一个新年好就应付不过来了,所以,需要一个储藏这些数据的数据库来替代上面的“新年好”,这个用来储存按照我们需要的、对我们有用的、已经清洗过、很规范的东西就是我们的数据仓库。
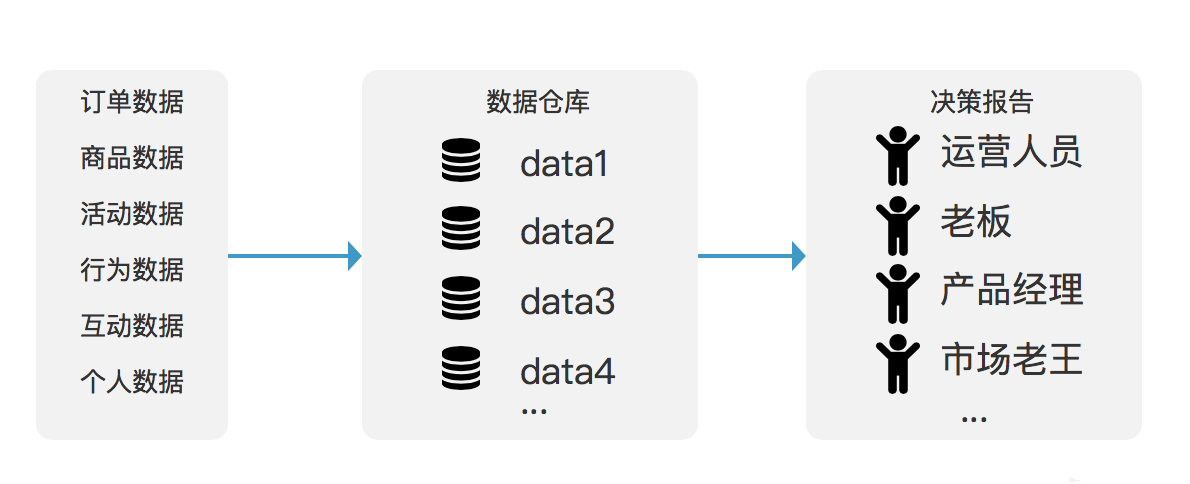
数据仓库与数据库的区别
数据库与数据仓库都用来储存数据,在本质上其实作用是相同的,当从业务出发,两者的区别就很大了。
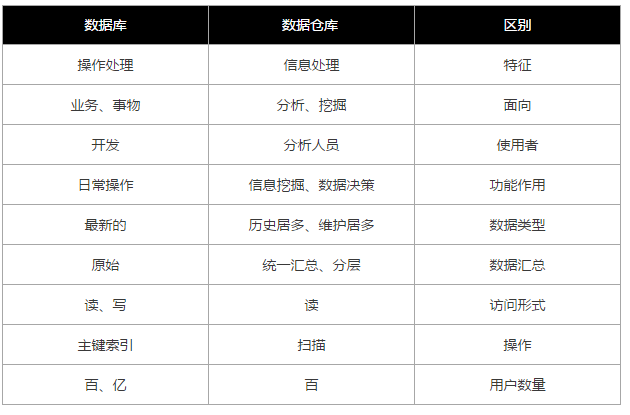
数据仓库是层级分明的
既然要做数据处理,我们数据前后肯定有变化,那么为了保险,我们需要将各个维度的数据分层储存,比如一个订单数据,让我罗列我可以整出二、三十个字段,可是最后我们真正用到的只有:uid、time和goods id,这个过程需要不断的过滤。每过滤一层就需要在新的一层储存一次。业务是分层的参考标准,不同的业务,分层不一样,比如阿里的数据分层分为:ODS、DWD、DWS、ADS。
ODS(操作数据层):是数据仓库第一层数据,直接从原始数据过来的,经过简单地处理,爆款率涉及到的表结构比如订单表、专场表、商品表、用户表等。
DW*(汇总数据层):这个是数据仓库的第二层数据,DWD和DWS很多情况下是并列存在的,这一层储存经过处理后的标准数据。增加了维度形成了统计宽表,比如专场的爆款商品有哪些。
ADS(应用数据层):这个是数据仓库的最后一层数据,为应用层数据,直接可以给业务人员使用。比如某日某个专场爆款率是多少、总的爆款率是什么。
看到这里,你也许会问,为什么要分层?
在这篇文章里,过多解释这个原因,没有意义,这个阶段,你就记住,分层是为了更清晰的掌控、管理数据。了解了数据仓库的基本概念,我们就得实战啦,如基本的数据模型。
数据模型有很多,如:范式模型、维度模型、Data Vault 等等。感兴趣的可以自行查阅资料,今天我们重点讲一下维度模型中的“星型模型”。
星型模型的基本概念
星型模型中有两个重要的概念:事实表和维度表。
事实表:一些主键ID的集合,没有存放任何实际的内容。
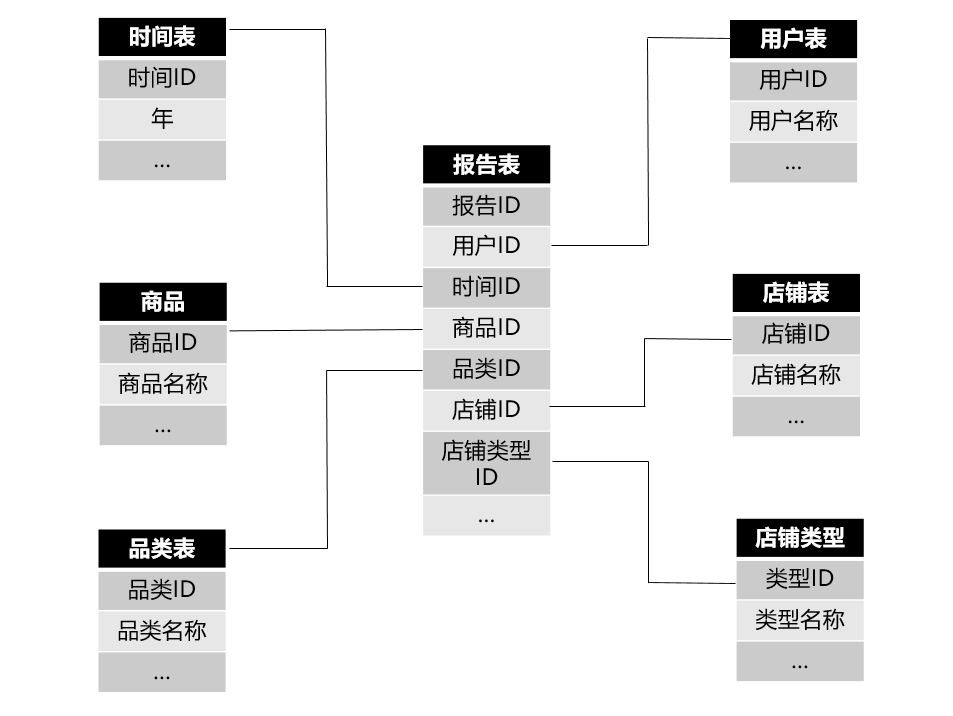
上图是我自己画的一个星型模型表结构(仅辅助说明),如上图中的“报告表”就是一张事实表,这个报告表会随着用户的购买行为不断的优化和更新,每个ID对应维度表中一条记录。
维度表:存放详细的数据信息,有唯一的主键ID。如上面的商品表、用户表等等。
星型模型适用的业务场景:
- 电商网站:某宝、狗东等分析用户的买买买行为。
- 新闻网站:虎嗅*、36kr*、推酷*等分析用户的阅读行为。
- 写作网站:知乎*、简书等用户的创作回顾分析。
- ……
星型模型的特点:
- 数据冗余小(因为很多具体的信息都存在相应的维度表中了,比如用户信息就只有一份)
- 结构清晰(表结构一目了然)
- 便于做OLAP分析(数据分析用起来会很开心)
- 增加使用成本,比如查询时要关联多张表
数据看板的设计
到现在为止指标已经定义好了,也采用三层建模的形式存储了下来。在这里就跳过数据开发这块,太过于偏技术化。指标计算好后最重要的就是指标的展示了,此时有个坑,你会发现每个人关注的数据不太一样,老板关注的和部门领导关注的是有差别的、部门领导关注的和一线的执行人员关注的还是有差别的,我们做了很多看板还是无法满足住全公司每个用户的数据看板需求。
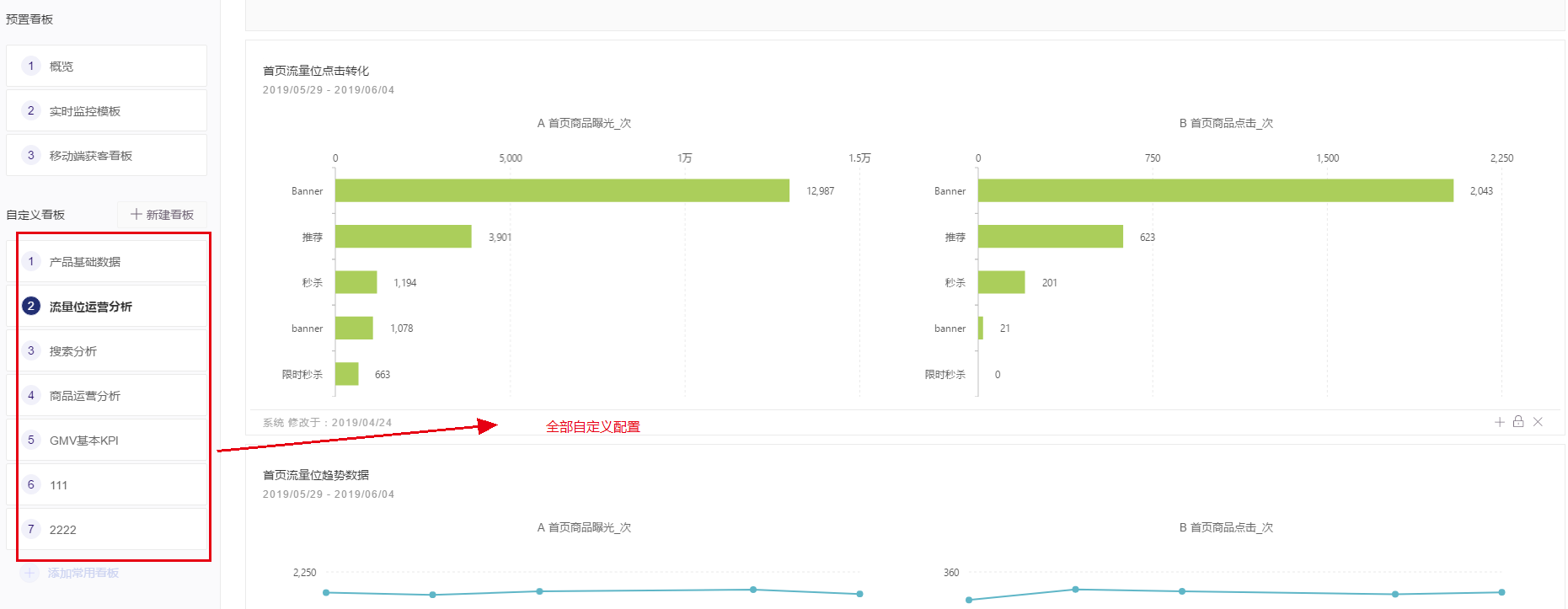
最后决定采用自定义看板的方案,我们数据中台提供的是看板库,所有的指标已经在数据中台分门别类的定义好,计算好。
如果遇到新的数据指标,现在的看板库无法满足,数据中台会进行新一轮的开发,开发完成后将指标计算的结果放到看板库中。看数据的同事可以通过查看、搜素自己想要的指标,通过拖拉拽的方式形成自己的个性化看板,并能通过微信、小程序形成自己的每日看板报告。
这样老板想看的指标数据中台自己定制页面,定制看板的权限交给每个同事,不过要注意权限的设定,有些同事是不能看到特别关键的指标。
看数据人员选择自己想要的指标通过拖拉的方式定制自己的看板,可以选择显示方式如折线图、饼图、柱状图等常规图表,也可以选择统计周期等属性。
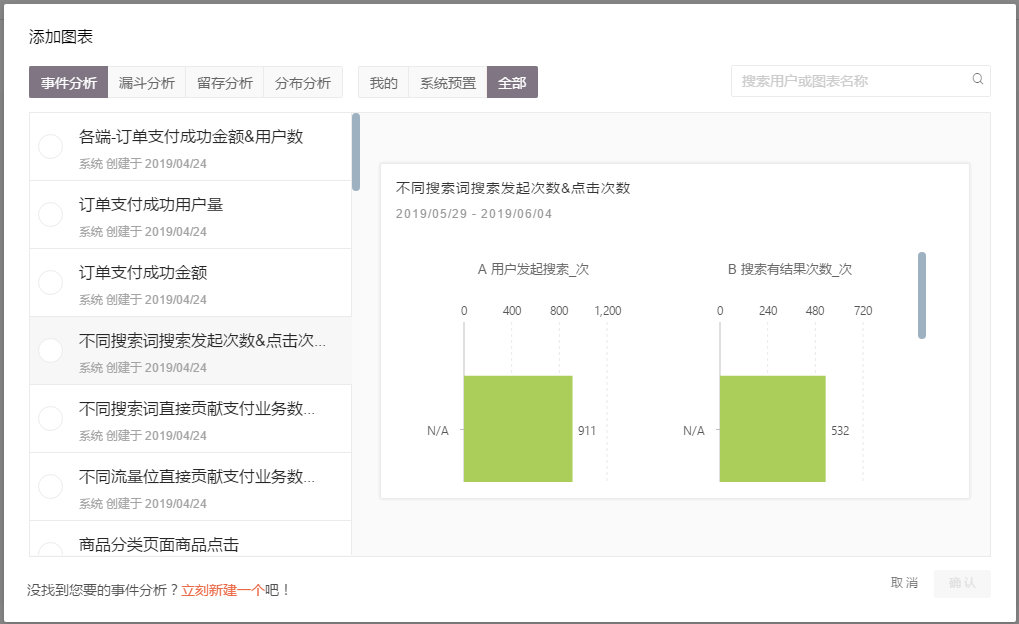
在此放一张配置后的数据看板DEMO, 左侧的看板都是看数据的同事自行配置的。
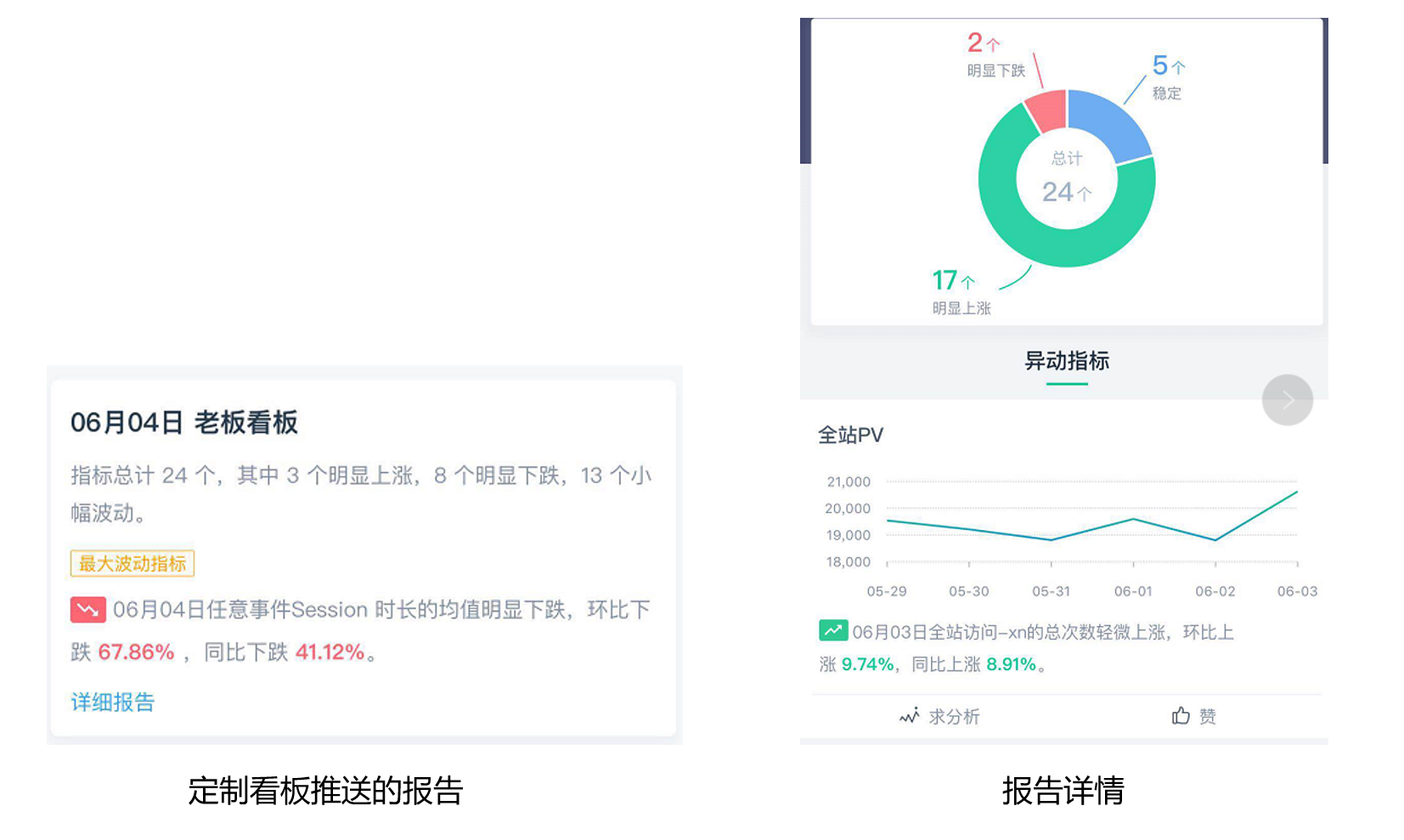
定制完看板后可以对接微信、内部的小程序、APP等。进行数据指标的个性化推送。
接来下会讲数据中台产品设计、用户画像、个性化推荐模块。
相关阅读:
《数据中台实战(一):以B2B点电商为例谈谈产品经理下的数据埋点》
作者:Wilton(董超华),曾任职科大讯飞,现任富力环球商品贸易港大数据产品经理。微信公众号:改变世界的产品经理。简单、简短、有用,坚持原创、坚持做感动你的好文章。
本文由@华仔 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议。









请问这个是阿里的指标平台,还是kdxf的?
写的很棒手动点赞
谢谢分享!请问这里的“数据看板”是用什么技术实现的?谢谢
BI工具 可以看看后面的文章 自助分析 :http://www.woshipm.com/pd/2808653.html
写的非常好,近期在搭建数据平台,帮助很大,期待后续更好的分享
这篇文章是我在互联网上能找到的关于onedata最好的了,比阿里云上的都更容易理解
写的很好,简单易懂,近期刚好再做零售行业数据中台,这篇文章对我帮助很大,感谢
您好,我想请问一下,为什么搞个数据指标还要原型?直接数据开发搞定不就行了
您好!对派生指标里的“时间周期”不是很理解。比如,近30天,这个容易理解,是站在当前角度往前推30天;“自然周”、“自然月”这样的时间周期,该如何理解呢?例如派生指标:“自然月支付金额”,使用的时候,要指定哪个自然月吗?
您好,您觉得数据维度选择的难点在哪里呢
找到真正能指导业务的指标
不错,期待后面的文章
欢迎持续关注gzh 改变世界的产品经理
很棒,简单易懂,期待后面的文章
欢迎持续关注gzh 改变世界的产品经理
通过结合实例变得更好理解了[大拇指]
欢迎持续关注gzh 改变世界的产品经理