
 起点课堂会员权益
起点课堂会员权益《长安十二时辰》大案牍术,并非“穿越版”的大数据!
如果你有关注《长安十二时辰》,那你一定会知道“大案牍术”。不过,你知道“大案牍术”和我们常提到的大数据有什么区别吗?

现在《长安十二时辰》正在优酷热播,发现这个连续剧跟大数据还有点关系,好多文章就以大数据为题进行了诠释,比如《<长安十二时辰>中的IT技术》、《<长安十二时辰>,穿越版的大数据泄露事件》、《刘雨欣:唐代查案用“大数据”,<长安十二时辰>里的大案牍术可行吗?》等等,而且不止一次提到了一个概念——大案牍术。

那么“大案牍术”是什么呢?
答案很简单,就是我们天天挂在嘴边的“大数据”,剧中靖安司徐宾的“大案牍术”其实就是以超强记忆力对长安各部门办事文书进行记忆、归纳、整理,形成“大唐数据库”,进而形成预判和解决方案。无论是破案调查找人,甚至预言未来。
案牍是中国古时候官府的公文案卷,大案牍更是凸显重要的国家纪要,术则是代表方法能力。堪比当今的大数据分析应用能力。

开篇剧中易洋千玺扮演的李必牺牲了一名暗桩崔六郎,又从大牢中提出死囚张小敬,为解决此次长安大劫,答应如果能破获此案,便免去他的死罪,两人都是“大案牍术”选出的最佳人选。

怎么选的?
在庞大的数据库中,添加目标的行为与特征等标签,分析出其喜好与习惯。“熟知当地黑白道规矩”,三教九流皆有交集”,多种语言能力,“且有好胜心、有牵挂”、不想死”。这不就是大数据标签体系吗?
现代意义上的大数据,跟连续剧里的大数据有密切的联系,比如都需要基于收集的数据进行客户的洞察和未来的预测,但无论是从采集的数据规模、实现分析的方法、使用的算法及使用的工具上都具有天壤之别,这些往往决定了现代大数据的本质。
笔者就用类比的方式,讲讲这部剧里的唐代原始大数据与现代大数据的区别,毕竟有比较就有鉴别,看看热文牵强附会大数据一把无可非议,但如果能借此机会学习下什么才是现代意义上的大数据,可能更有意义。
一、什么是大数据
1. 现代大数据
指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
2. 唐代大数据
以档案登记为基础,无论是百姓家添丁新丧、婚配嫁娶之事,还是各个衙门机构间的人员往来和调动,甚至连钱粮货物流水,都会由录入吏进行登记。
两者的区别就在于现代意义上的大数据,更多依靠的是海量的机器和传感器无时不刻的自动记录数据,而唐代大数据仅靠官吏进行手工录入,其不仅受限于人员数量,而且受限于有限的时间,这决定了其数据量的上限。
二、大数据的特点
1. 现代大数据
一般讲有4个特点。
一是数据体量巨大。
比如百度资料表明,其新首页导航每天需要提供的数据超过1.5PB(1PB=1024TB),这些数据如果打印出来将超过5千亿张A4纸。
二是数据类型多样。
现在的数据类型不仅是文本形式,更多的是图片、视频、音频、地理位置信息等多类型的数据,个性化数据占绝对多数。
三是处理速度快。
数据处理遵循“1秒定律”,可从各种类型的数据中快速获得高价值的信息。比如在用户浏览购物的时候进行商品的个性化实时推荐。
四是价值密度低。
以视频为例,一小时的视频,在不间断的监控过程中,可能有用的数据仅仅只有一两秒。
2. 唐代大数据
完全走向了反面。
一是数据体量极其有限。
有资料证实,到目前为止,人类生产的所有印刷材料的数据量仅为200PB,唐代作为全世界一个国家中的一个朝代一个时期能记录的数据量更是微乎其微。
二是数据类型非常单一。
大案牍术仅仅以档案登记为基础,也就类似于现代的户口登记数据。
三是处理速度很慢。
你看靖安司那么多人忙这忙那,因为卷宗到处都是,需要某个数据得靠人工一个个去找,要推理某个事情,还要靠人员超级的记忆力和逻辑推断力,脱口而出的数字虽然代表敬业,但显然跟现代的机器处理速度不可同日而语。

四是价值密度相对高。
由于处理能力有限,靖安司只能记录最重要的数据,户口登记数据即使在现代也是重要的数据类型之一,因此唐代大数据的价值密度肯定是很高的,否则就没有断案的可能了。
三、大数据的分析
大数据已经不简简单单是数据大的事实了,而最重要的现实是对大数据进行分析,只有通过分析才能获取很多智能的,深入的,有价值的信息。
1. 现代大数据
大数据的属性,包括数量,速度,多样性等等都是呈现了大数据不断增长的复杂性,因此不大可能靠人去直接面对大数据进行分析,大数据的分析方法在大数据领域就显得尤为重要,可以说是决定最终信息是否有价值的决定性因素。
先说说可视化分析。
大数据分析的使用者有大数据分析专家,同时还有普通用户,但是他们二者对于大数据分析最基本的一个要求就是可视化分析,因为可视化分析能够直观的呈现大数据特点,非常容易被读者所接受,就如同看图说话一样简单明了,就是你平时接触的PPT软件,也可看成一种可视化分析软件,更别提专业的商业智能(BI)软件了。
再说说算法。
大数据分析极度依赖数据挖掘算法,各种数据挖掘的算法基于不同的数据类型和格式能更加科学的呈现出数据本身具备的特点,也正是因为这些被全世界统计学家所公认的各种统计方法才能深入数据内部,挖掘出公认的价值,包括贝叶斯,SVM,回归,决策树,神经网络,深度学习等等。
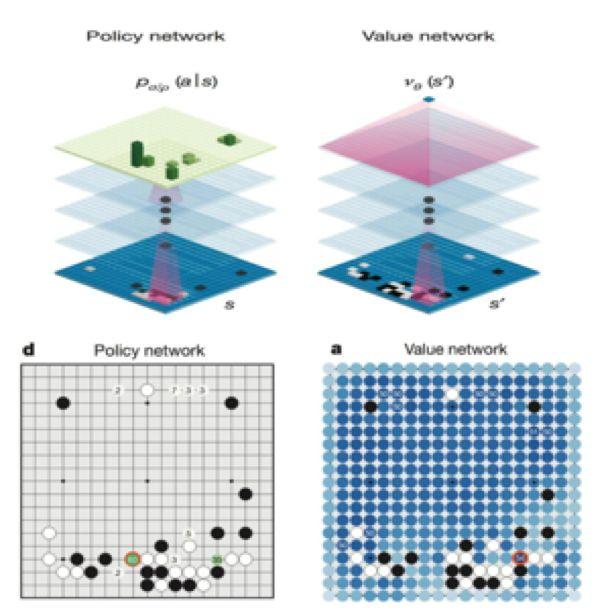
比如阿尔法狗基于深度学习算法来实现价值网络(value network),可以预测棋盘上不同的分布会带来什么不同的结果,因此,现在机器在围棋上战胜人类已经不是事了。
2. 唐代大数据
《长安十二时辰》大案牍术这么描述办案分析方法:
“等到办案时,靖安司只需调阅相关卷宗进行预判和推测,便可以从数据与信息间发现诸多关联,进而找到破案的线索“,这里提到的预判、推测、关联都是靠人,徐宾似乎成了分析之神。
但徐宾在分析上其实是个光杆司令,没啥辅助工具。
唐代既没有电脑,更不可能有可视化软件,徐宾的分析推测首先要让李必理解听懂,但人对于听的接受能力远没有看强,而同样是看,人对于图像的理解力比文字好太多了。
徐宾缺乏很好的洞察数据的手段和解释数据的方法,因此如果要用图形示意,估计就只能这么靠手工画吧,效率之低可想而知。

徐宾不可能用到现代的算法,做预测或判断靠的只能是自己的逻辑推理能力,但里面的可疑人物之所以能被推理出来是因为徐宾面临的只是小数据,涉及的要素不够多,关系不够复杂而已。
人对于二三维变量的关系还是能做些判断,但一旦数据维度非常多,比如要你基于十维的数据找相互之间的关系,人的脑子估计就不够用了,这个时候就要靠机器算法。

比如Palantir是美国著名的独角兽反恐公司,Palantir的主要牛逼之处是在于可以多维度将不同来源的数据进行关联,特别是对非结构化数据的关联分析。
比如邮件、社交网络信息、网络日志信息,从而挖掘和展现出未知的相关关系,为决策提供依据。
唐代第一围棋国手王积薪在那个时候可是所向披靡,但如果穿越到现代跟柯洁下,不知道要被让多少个子,而柯杰对阿尔法狗的胜率可是0,具有强大算法能力的阿尔法狗在围棋界是神一样的存在。
当然,现代大数据和人工智能算法目前的“通识”能力还是有限的,其对于环境的复杂性非常敏感,只能专一的做某件事,能够把某件事做到极致,比如纯粹的下棋,人脸识别,商品推荐等等。
假如涉及到复杂的决策环境,比如在无边界,数据完整性不够的情况下的断案,那福尔摩斯、徐宾依靠人类进化而来的的逻辑大脑可以做出更为明智的判断。
但一旦判断方向准确,算法就可以起到强大的辅助作用,比如DNA检测等等,遗憾的是,徐宾在那个时候只能孤身作战,如果徐宾穿越到现代,一定可以依靠算法的协助让其决策水平更上一层楼,两者是相辅相成的。
四、大数据的技术
从数据采集看,现代大数据的数据采集依托专业的ETL工具,将分布在各处的异构数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为数据挖掘的基础,而且实时性越来越高。
而唐代大数据的采集是这么记录的:“各县配备录入吏,该县百姓的添丁新丧、婚配嫁娶、买卖奴婢,衙门之间的人员往来、人事变动、车马粮草、征收赋税等一切事务,将被录入吏一一查证,悉数记录到案牍中。”
最大特征就是靠人工纸质记录,效率之低可想而知,比如每个人记录的标准可能不统一,因此无法保证数据质量,比如在录入的时候无法快速的判断重复,无法方便的实现纸质的案牍修改功能,又比如写错了怎么办等等。
从数据处理看,现代大数据用分布式架构来解决海量数据的计算瓶颈,也就是能够自动把一个针对海量数据的计算任务拆成多个子数据任务,然后多个子任务并行计算,最后再自动汇总,这样就可以实现处理速度的飞跃。
而唐代大数据的数据处理估计还是以人工集中式的为主,比如徐宾要统计某天进入长安城的人数,肯定得安排一个下属找到对应的册子去一个个数吧,而这个数的过程是无法交给不同人处理的,如果要分布式处理,则也是非常麻烦。

首先,要有人负责把本子平均拆成多份,其次,根据份数安排对应的人分别去统计,最后,还要有人汇总记录各人统计的结果,如果某个人能力差点统计的慢一点,所有人都要等那个人的结果,总体耗费的时间可能更长,这个管理成本是非常高的,而现在大数据分布式处理能基于算法自动高效的完成这种资源分配及协调问题。
从数据存储看,现代大数据不仅能基于关系型数据库存储类似名字,籍贯等结构化数据,也能用NOSQL等数据库存储图像,视频等非结构化数据,这些数据存储于数据库中非常方便检索,而唐代大数据则只能存储于纸质书中,存储的数量还受限于纸张印刷量。
大家也看到了,因为大案牍术记录卷宗需要大量的纸张,但唐朝的藤纸相当匮乏,所以徐宾将每月的俸银都用来买书做造纸坊了,可见唐代要存储数据是多么不容易的事情啊。

五、大数据的应用
唐代大数据展示给我们最大的应用就是“大案牍术”,也就是在司法、安全、民生领域基于大数据做决策判断,为社会稳定做出贡献,但现代大数据的应用领域可远远超越了这个范畴,而且重点集中在互联网、金融等新兴领域,下面举一些例子:
在互联网领域,我们每天接受到的广告就是最大的一类大数据应用。
在金融领域,风控大数据始终是应用的焦点,比如大家接触到的芝麻信用分算是其中很小的一个应用。
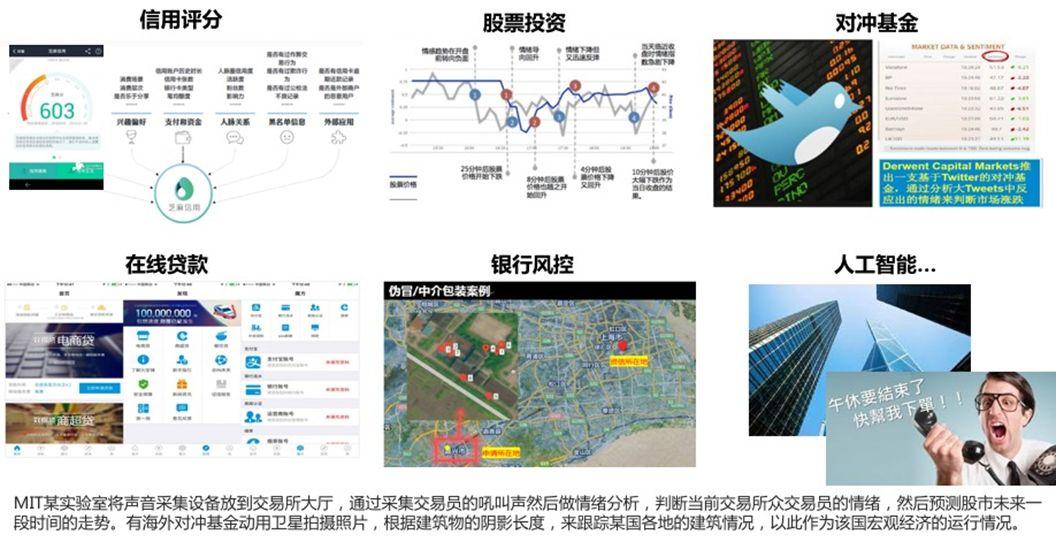
当然还有医疗行业的电脑医生、交通行业的自动驾驶、工业上的个性制造、体育行业的运动员大数据分析、能源行业的用电预测、通信行业的客户挽留等等,大数据已经渗透进每个人的生活。
以上笔者以《长安十二时辰》为例子,简单的对比了下现代大数据与唐代大数据的区别,涵盖了大数据概念、分析、技术、应用等各个方面,但现代大数据与唐代大数据其实是没有可比性的,因为基础完全不一样。
现代大数据是建构在近现代科技基础上,特别是信息时代的新数学和新方法论、电子计算机、互联网、通信网等等,笔者所以这么比较,只是为了更方便的说清楚大数据的一些概念。
当然如果换个角度,脱离“术”的范畴,那《长安十二时辰》中有两点大数据的做法是发人深省的,也是当前大数据发展中的难点:
第一,唐代建立了靖安司这个集中化的数据管理组织。
靖安司为唐玄宗设定的统摄整个西都贼事策防的机构,凌驾于诸署之上,负责收集来自全国各地的信息收集和传递。靖安司内有个庞大的库房,堆积着从三省六部、一台九寺五监的机密要件 。这不就是一个全国性的数据仓库吗?

孤立的一个数据的价值是极其有限的,大数据必须打破孤岛,集中起来才能办大事,所谓1+1>2,比如徐宾做推测是要综合多个要素相互验证才能使得做出的结论合情合理,因此,打破数据边界是现代数据管理者的一个使命!
第二,人员档案、用户行为数据搜集的完整性令人瞠目。
靖安司建设了相关应用,例如人员档案。徐宾在被怀疑后,就被用大案牍术推演了个人户籍、轨迹、行为信息。他的出身、房产变动、妻子的劳动关系、异常行为等等都记录详尽,被李必查了个底儿掉。
其中记录的信息之详尽,包括你去哪个酒吧喝的什么酒、与谁喝酒、谁付的钱这些,恐怕放在今日,都难有人能做到这么详实的记录,堪称人口管理工作模板。

显然上述描述过于夸张了,但这似乎是现代大数据所希望能达到的境界,我们也许迟早会处于一个现代天网之下,这到底是好事还是坏事呢,就看管理者的智慧了吧!
《长安十二时辰》在提供给大家赏心悦目的剧情和华丽的画面之余,如果能普及点大数据知识,也算是很有意义的事情,欢迎大家阅读评论!
作者:傅一平,微信:fuyipingmnb,公众号:与数据同行
来源:https://mp.weixin.qq.com/s/0Z7UvZfW4O6gWCAvgtL_1g
本文由 @傅一平 授权发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议









在那个时代,也是很牛逼了