
 起点课堂会员权益
起点课堂会员权益每日优鲜如何搭建数据仓库?
编辑导读:生鲜配送已经不是一件新鲜事,只要在手机上下单就能享受到送货到家的服务。这背后不仅要依靠强大的物流,还需要搭建数据仓库,以便决策。本文将以每日优鲜为例,分析它是如何搭建数据仓库的,与你分享。

一、为什么要做数据仓库&数据仓库的结构
1. 市场
国内生鲜销售渠道中农贸市场占73%,而超市渠道渗透率仅为22%,相比与发达国家70%以上的水平,仍有较大差距。
随着新零售的风口刮到了社区生鲜领域,社区生鲜近年来仍密集开店,一是行业巨头降维打击,布局“社区生鲜”市场,二是生鲜传奇、钱大妈之类的小品牌井喷式爆发。
PEST分析:
国家政策:
国家大力发展在线农产品交易,对农产品超市进行补贴。并于2017年出台的《商务部 中国农业发展银行关于共同推进农产品和农村市场体系建设的通知》,其中主要支持方向为:
- 农产品市场及仓储物流设施建设。支持新建、改造各类农产品批发市场、综合加工配送中心、产地集配中心,完善预选分级、包装、仓储、物流等设施。
- 公益性农产品市场体系建设。支持公益性农产品批发市场建设公共加工配送中心、公共信息服务平台、检验检测中心、消防安全监控中心、废弃物处理设施等公益性流通基础设施。支持建设公益性菜市场、平价菜店等公益性农产品零售网点。
- 农产品冷链物流体系建设。支持建设、改造标准化冷库和冷链物流集散中心,提高农产品产地预冷、低温加工、冷链仓储配送能力。推动封闭式交接货通道、月台、货架等设施标准化改造,加快绿色环保冷藏冷冻设施设备与技术应用。
因此为在线生鲜的发展打开了政策渠道。
经济发展:
我国今年来经济快速发展,经济发展带动了人民的消费欲望,在线生鲜电商打开了网上生鲜买卖的渠道。
社会现状:
目前人们的消费水品提高,人们越来越关注农产品的安全问题,因此人们很多希望能够直接从农产品生产地直接拿货,既保证了食品安全,又对价格满意;并且随着人们网上购物的习惯养成和物流运输水平的发展,人们网上采购生鲜类产品的意愿也在加强。
技术现状:
随着AI大数据以及物联网等新技术的诞生,保质期短的生鲜产品能够在特定的时间及时送到用户手中,并对用户反馈的数据进行追踪,既提高了用户的满意度,同时也能够保证食品的安全和新鲜。
综上所述,生鲜网上发展正处于快速成长期,市场份额将越来越大。
二、每日优鲜产品概况
每日优鲜成立于2014年,2018年已完成水果、蔬菜、乳品、零食、酒饮、肉蛋、水产、熟食、轻食、速食、粮油、日百等全品类精选生鲜布局,因此SKU非常丰富,作为配送类产品,每日产生巨大的数据量。
每日优鲜能够做了更多精准的触达。媒体环境变得越来越精准了,这要求我们作为一个零售商或者广告主,也会在算法上越来越精准。因此我们猜测每日优鲜具有自己的OLTP。
伴随着新零售到来的步伐以及社区团购迎来的新风口,电商巨头们亦纷纷布局生鲜电商。阿里有盒马鲜生,京东有7Fresh,苏宁有苏鲜生,步步高有鲜食演义,同一赛道角逐的还有美团的小象生鲜、易果生鲜、天天果园、大润发优鲜等,生鲜电商的抢滩战未来将更加激烈。
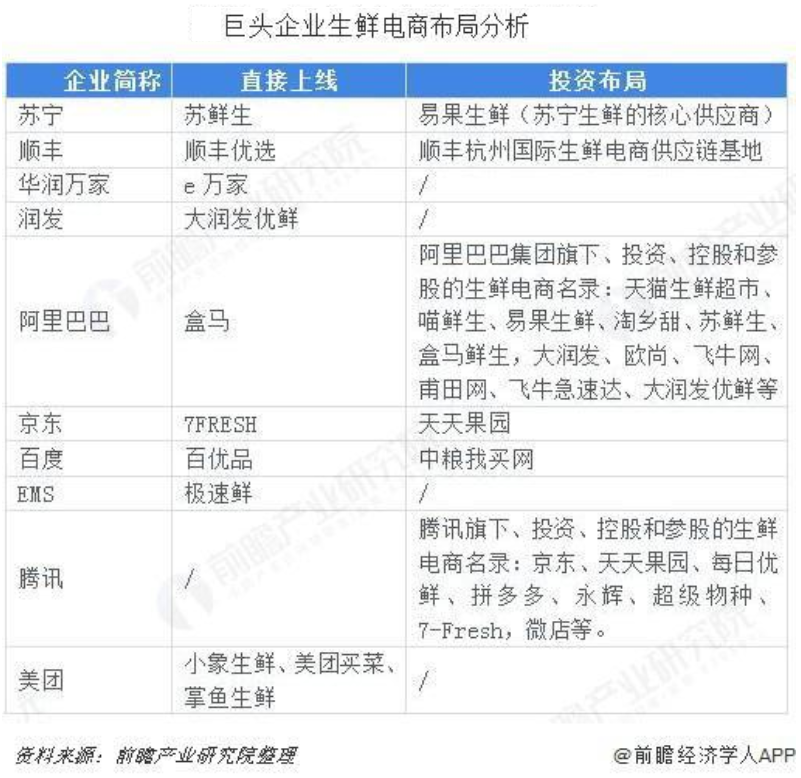
因此,根据以上产品分析,每日优鲜需要搭建自己的数据仓库,用于公司决策,精细化运营。
三、数据仓库的结构
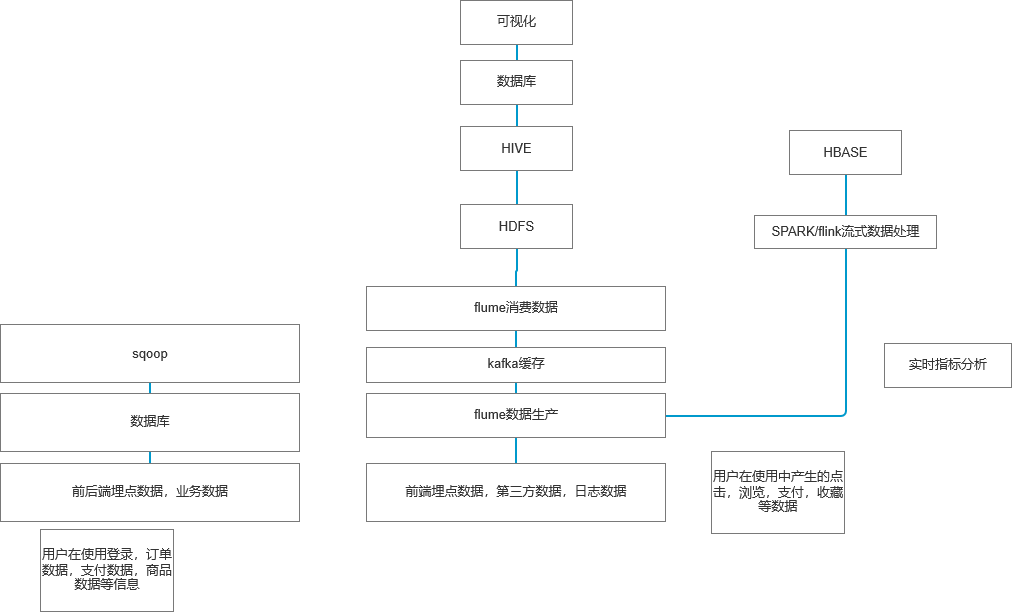
1. 事实与维度
每日优鲜维度分析:

数据集市矩阵表:

2. 数据仓库数据源
数据源分为三种:
- 结构化数据:一般是业务数据库或日志数据库中直接产生的数据,存于关系数据库中,常用的数据库有,MYSQL,ORCAL,SQL SERVER,POSTGRESQL等数据库中,主要以表的形式呈现。
- 半结构化数据:一般我们会将半结构化的数据经过XML转化存于CLOB中,即存在XML的节点中,因此可以对数据进行有效扩展,半结构化数据一般后期会存入结构化数据库中进行调用。
- 非结构化数据:一般是图片,文字,语言类型通常会使用到NLP,图像处理,语音识别等技术手段进行处理之后存在nosql数据库中,常用的有mongo DB 和HBASE或者基于内存运算的列式存储Redis数据库,将数据存在数据库的节点中,优点在于能够有效扩展。
3. 数据仓库的物理生产环境和ETL
在服务器集群规模选择上如下分析(举例):
- 日活100w,每人平均产生100条日志,那么每天总日志可以是100w*100=1亿条;
- 每条日志一般情况5~2k,按照1k进行计算,约需要100万存储空间;
- 如果服务器半年内不尽兴扩容,那么需要的空间就是100万*180天约为18T;
- 保存3套数据副本,为54T;
- 一般情况下还要预留20%~30%的空间,那么需要77T;
- 按照一个磁盘10T的容量,那么我们就可以得出需要10个硬盘的服务器。
数据仓库的物理生产环境一般是在LINUX平台下运行,因为大数据生态体系下的编译好的很多并包都是在LINUX系统中进行编译,因此从技术开发层次在LINUX下开发。
一般服务器可以部署Apache开源的服务,当然在选择框架的过程中需要考虑企业数据的规模,一般情况下大企业使用Apache框架,而对于中小企业可以选择CDH框架。可以使用使用Mysql或其他类型的数据库(根据需求)。使用PHP或者Python、JavaScript进行写入。
ETL可选择Informatica、Beeload、Kettle(开源,有数据安全风险)。
在进行服务器集群管理时,可选择软件Claudira Manager(只支持CDH框架下软件安装)简化框架安装和集群管理。
4. 半结构化数据的预处理
通常会使用XML或JOSN进行半结构化数据的处理存储。
5. 物理化实现数据库物理表
这一步就是设计数据库的表结构,依据上一部中的分析维度和事实情况进行数据库表的设计。常用的维度建模模型有星型模型(结构清晰)和星座模型。根据维度模型建立数据仓库表。
6. ETL
数据仓库设计完成,再对数据库中的数据进行抽取转换加载步骤。进行数据处理。将数据在各个框架中传递。
7. 加载事实表和维度表
对已经制作完成的表结构加载,得出我们希望看到的数据的事实表。
8. OLAP分析
将数据仓库中的数据通过报表的形式和dashboard形式呈现出来。在此常用的工具有:
选择的依据可以遵循两个方面:
1)按照超大数据的查询效率
Druid & Kylin & Presto & Spark SQL
2)从能够处理的数据源多少的种类(从多到少)
Presto & Spark SQL & Kylin& Druid
数据可视化的工具一般可选用:echarts,superset,QuickBI,DataV。后两种可视化工具为阿里提供的付费工具。
四、总结
数据仓库的搭建是企业对数据的充分重视,搭建的过程可以是高层主导直接全域搭建或者由业务主题开始搭建数据集市,然后汇总成数据仓库。
优点:数据仓库使企业数据集成,向上能够帮助高层决策,向下能够满足运营、财务、采购、物流等业务部门需求;随着企业数据量的增大,为后续数据湖和数据平台的搭建提供底层支撑,对企业数据进行数据资产化和数据管理,进一步能够指导企业的业务线发展。
缺点:数据仓库帮助企业数字集成的同时,随着企业发展壮大,缺少对数据的运维,如何能够更好服务企业发展,各部门协作,是下面需要考虑的问题。
后期,数据仓库为更好的为企业节省成本,需要搭建数据平台,集成业务中台和技术中台。
由于本人知识结构尚待优化,有不足之处,请多多指正。感谢。
作者:汪仔2296,QQ:1083368735
本文由@汪仔2296 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议









辛苦了
哪里辛苦,哈哈
讲的太粗了,
100万存储空间具体是怎么计算的呢?
需要10个硬盘的服务器,是怎么计算的?
太笼统
🦉隔壁啊
啥意思
之前我在每日优鲜隔壁公司