
 起点课堂会员权益
起点课堂会员权益互联网金融中可做的17个模型
编辑导语:模型的使用有助于帮助获得相应数据,进而推动业务目标的实现。与此同时,模型的使用需要依据业务核心目标来确定。本篇文章里,作者介绍、总结了互联网金融可做的17个模型,并对模型的应用注意事项做了相应总结,一起来看一下。

模型的存在是基于一个事实,基于概率的决策是最优的。概率转化为评分,方便对齐风险。评分就是用统计的方法来识别潜在客户,判断客户是否合意。
合意由我们事先定义,可以是诸如风险、收益率、响应率、续借意愿、违约后的偿还意愿等等。
那么,业务中一系列环节都可以采用模型方案,我们要说风控中哪些模型可做,就变相地在讨论业务上有哪些环节可以做精细化策略。
01
1)申请评分卡模型
预测是否该通过客户的借款申请。借款行为的发生就像泼出去的水,一旦发生,就无法被撤回。所以要尽可能准确地判断客户会否偿还该笔借款。贷前如果一个客户的评分过低可以直接拒绝,而通过的客户也可以根据评分高低制定差异化初始额度。
2)行为评分卡模型
基于客户发生的行为,重新评估客户的风险。授信通过后的用户产生一系列行为数据,例如借了几笔贷款、间隔多久、还款习惯怎么样等等,这些数据进一步刻画了用户的可信任度。
贷中管理,在不同时间点对客户基于更新的数据情况重新评估风险,是精细化用户管理必须做的事情。
3)提额模型、息费敏感模型
前者预测可以增加额度的客户,以及必须减少额度或者取消额度的客户;后者是预测哪些用户对息费敏感,这部分人升息就可能导致其利用率急剧下降。
这也是精细化运营的工作,也可以说属于行为评分的范畴。因为贷款机构的目标正在从降低借款人在贷款产品中的违约率变成提高客户带来的利润率。
4)催收评分卡模型
预测无须采取措施或者必须采取措施进行催收的客户。一些逾期行为能自行修正,一些只需要适当的提醒,剩下的那部分借款人才需要采取严厉的措施。
不仅是要不要催的问题,还可以建模预测什么时候催、以什么方式催,从而智能分配话务员在最优的催收时间下选用最优的催收话术和客户对话。
另外,要和客户对话得先联系上客户,于是还有失联修复的问题。
5)多头风险模型
从多头共债的角度预测客户的违约风险。多头借贷变量涉及到共债信息,与还款能力和还款意愿挂钩,多头严重就存在借新还旧的可能,一旦有平台拒借,客户就丧失了还款能力,一旦还不起,也可能就不愿意还了。用多头变量来预测逾期风险,效果通常较好。
多头模型还可以采用另一个方案,以多头程度为目标变量,就变成了多头借贷预测模型。多头和信用风险一样,是动态变化的,预测用户通过之后的多头严重程度,也是有意义的。并且其优势是可以利用申贷样本建模,因为不需要有滞后的风险表现。
02
以逾期为目标变量的模型,正如上面我们提到的大多数,都是风险模型。但也有很多非风险模型,这些非风险模型,广泛地应用于量化增长的场景,例如如拉新、促活等。AARRR。
6)用户现金贷需求预测
预测客户有无现金贷款的需求。面向支付的花呗显然用户规模远远多于面向借款的借呗,因为更多的人是为了支付便利而使用支付宝,而不是借款提前消费。对有现金贷需求的客群去营销,才能对症下药。
7)营销响应模型
预测不同触达方式下客户的响应率。不同的人对同一个触达方式的反应是不一样的,有些人看到短信就愿意来,甚至有些人会自然找上门来,有些人则需要优惠券需要福利才愿意尝试你的产品。差异化触达是更有效率的做法。
8)借款可能性预测模型
预测客户未来一段时间内发生借款行为的概率。客户借还一次,带来的利润是不够的,实际上,因为获客的成本不断增加,优质客户多次借款才能覆盖成本。对借款可能性的预估,可以帮助你更好地服务这些稀客。如遇到资金储备不足,也可以限制对这些人的营销,防止集中借款导致资金缺乏。
9)客户流失模型
预测客户未来一段时间内会不会流失,和借款可能性大致相反。对于高流失可能的客户,应该尽早地想办法挽留,因为一旦流失,重新唤醒的难度不亚于一个纯新户的获客。
10)甚至是,模型分的有效性预测模型
模型预测的高分段好用户多,低分段坏用户多,但并不都是好用户或坏用户。评分的效用是群体有效,而非个体有效。那预测结果和真实表现差别大的群体,就是模型分有效性不足的群体,这部分客群如果能有效地被识别出来,就不应该采用这个评分工具。
03
量化增长一般较少考虑风险,增长和风险分开能够使得效率最大化。还有一些非风险模型应用场景不限于信贷的。
11)收入模型
预测客户的收入情况。收入模型可能是应用场景最多元化的模型之一了。在风险层,高收人群至少避免了因还款能力不足导致逾期的可能。在非风险层,高收人群尤其是营销获客的香饽饽,甚至很多增长运营团队的核心指标就是此类客户的数量。
12)负债模型
预测客户的负债情况。收入的另一面就是负债,客户显然更愿意支付房贷、车贷等大件物品的每月账单,剩下的才是用户的可用流水。负债收入比过高,贷款逾期风险往往就很高。
13)破产模型
预测具有破产可能性的客户或者企业。相比之下,企业的同质样本比个人的同质样本少得多,而且企业的财务数据容易被高管们操纵,导致企业破产模型的预测效果一般不如个人的模型效果好。
14)职业模型
预测客户的职业。挖掘一个人属于什么工作单位或岗位,可以进一步评估工作稳定性。在风控领域,职业的预测并没有收入负债的预测应用的那么直接,至少可以理解为,职业可以进一步评估个人收入水平和收入稳定性。
15)有孩模型
预测客户是否有子女。有稳定家庭的客户,风险表现一般就更好。甚至你的信贷产品可以为此类客群定制一套借还款策略。其他场景的应用就不用提了,母婴品是一个大类,针对这些人去营销吧。
16)有房模型
预测客户是否有房产。有房的客户除了相对更高收外,也大概率有房贷,存在两面性。有房可以确保的一点是更稳定。一般客群质量是自住>与父母同住>合租。
04
有一个贯彻营销场景、信贷场景、支付场景等几乎所有场景的模型,那就是反欺诈模型。
17)反欺诈模型
识别欺诈用户。欺诈主要可分为一方欺诈和三方欺诈。一方欺诈是指申请人自身的欺诈行为;三方欺诈是第三方盗用、冒用他人身份进行欺诈,申请者本人并不知情,比如团伙利用非法收集的身份证进行欺诈。
其实还有两方欺诈,是内部人员勾结的欺诈,一般不在考虑范围。
营销中,有刷单、套现、黄牛等风险,这些就可以定义为欺诈。信贷中,有撸口子大军摩拳擦掌,他们借到了多少钱就是挣了多少钱,对于骗贷的人来说任何催收劝还都是无效的。支付中,又存在盗刷、洗钱等风险。还有电信诈骗等等。
05
我们额外说一说大家都知道的信用评分,芝麻信用分、微信支付分和小白守约分。
无论是天猫淘宝的消费还是花呗支付的海量交易数据,都可以用来评价个人的还款能力和意愿。结合着马斯洛需求理论,也就是生理、安全、情感、尊重、自我实现依次升级,越能体现高级需求的数据越可以给更高的权重。也就是说重要的不是单次购买行为,而是消费习惯。
而那些店铺商家,平台有他们所有的交易、资金、物流信息,都可以用来作为金融服务的依据。
你掌握了一个人的人际关系,就掌握了这个人。社交关系链,不仅可以用来评估信用,还能直接作为质押物,因为每个人都在乎它,而且很在乎。
而小白守约,与此类似。
06
评分是信贷业务中最有用的一件工具,但不仅仅信贷。许多业务场景都会用到评分。
保险公司使用它来评估参保人的风险偏好,或者汽车事故的风险。
正好借此说明,模型不能滥用,一个人信用评分越高,很可能风险偏好越低,这些人不冒险反而就不会去购置保险。保险公司用信用评分去筛选客户,找到的可能都是这些非目标客群。
医院中使用它去判断哪些病人最需要特殊治疗,也需要判断不同医疗措施下病人的生存时间。
抖音快手这些短视频平台使用它去预测用户直播观看的可能性,好确定是否给你的发现页插入直播推荐。也需要预测用户观看视频的意愿度,好使得推荐的结果是点击率高且观看时长长。
一句话,排序 is all you need!
07
业务的理解能力是可以共通的,任何一个人都可以通过搜集归纳比较容易地了解互联网场景的业务模式,但是其真正的困难在于每个业务背后复杂多变的真实需求,即怎么在具体场景实现以流量或者盈利为目的的最优决策。
业务目标决定了模型目标,模型目标决定了用到的数据。我们可以有很多模型,但业务最核心的目标是唯一的。
当你有这么多模型之后,你要怎么用呢?
多个模型同时通过或者拒绝的,当然好办,它没有改变单个模型的决策结果,给了你更大的决策信心。但是,一个模型说“通过”,另一个模型说“拒绝”,这个问题是不是就费解了。
没那么糟糕,相反,这是改善决策的机会。如果模型都相同,多个就是一个。
我们可以制定两个模型分的交叉效果表,下图是一个示例,如果用定制模型通过8个格子,进一步和通用模型交叉后,置换其中一个格子,往往都能获得更好的风险表现。实际上,通过交叉,通过率也能得到提高。
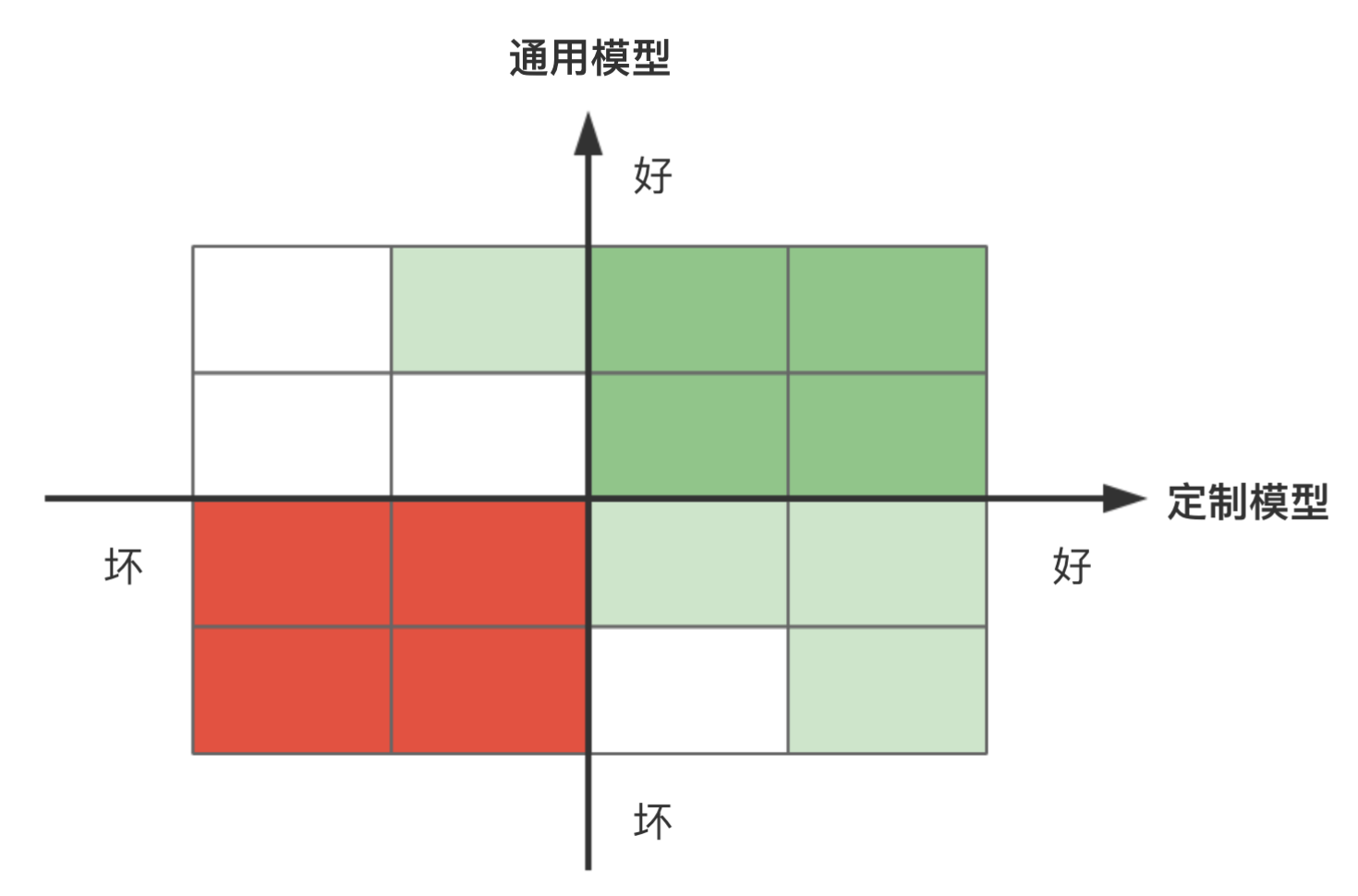
但是请注意,你不能串行地使用模型。除非这真的是你想要的结果。
本文由@雷帅 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









学习了,大佬!
互联网金融的用户要被多少个模型打分,可能多到你想象不到。这么多模型在特定的场景中都有用,那要怎么用?其实模型应用也要分轻重,因为模型太多了。