
 起点课堂会员权益
起点课堂会员权益Amazon SageMaker Canvas 初探
编辑导语:作为一款0代码机器学习智能工具,Amazon SageMaker Canvas 在使用上会给用户带来什么不一样的感受?本篇文章里,作者从“新手模式”、“上帝模式”等角度切入对该款产品进行了体验测评,一起来看。

Amazon SageMaker Canvas 是本次测评的产品,主要用于提供“无代码”构建人工智能模型的能力。为了明确当前的产品优势并提出改进建议,这个评测从“新手模式”和“上帝模式”来描述整体的使用体验。
Amazon SageMaker Canvas 是来自亚马逊云科技公有云的一款 SaaS 化的产品。而国内的朋友可能使用国内的公有云上的 SaaS 软件更多。
虽然从产品的基本使用逻辑上看,不管来自哪家的产品都是差不多的。但是,由于是国外厂商的产品,在具体设计上与国内公有云的产品还是多少有点差异的。这可能是国内的朋友们使用这块产品遇到的一个“小门槛”。
接下来就开始正式的使用体验。因为初始化的部分与 SageMaker 关系不大,先开启“上帝模式”。
一、开始“云上之旅”
大赛的测评要求是从产品、运营、交互等角度给出使用体验评测或者优化意见。但是作为一款云上的产品,在开始阶段都要经历一段“开始云上之旅”的过程。这段过程与具体公有云平台和具体产品关系不大,是在云上使用产品的必经之旅。
当然,我自己在这个环节也遇到了一些小插曲,会在下面分享。
1. 注册与支付方式
从注册和开通的方式上看, Amazon SageMaker Canvas 与国内公有云的交互逻辑大体相同。但国外的公有云基本都是依赖信用卡支付的,并且有些是不支持银联的,仅支持 Visa 和 MasterCard ,比如微软的 Azure 。
这可能是国内的朋友们体验国外产品的一个门槛。而好在 Amazon SageMaker Canvas 可以直接用银联卡,我自己绑定的就是银联的信用卡。当然相比之下,还是咱们国内公有云的支付手段更便捷。
页面交互的布局与国内公有云基本相同,一路跟着引导走,倒也不太需要太专业的知识。这部分采用“新手模式”完全可以搞定。完成注册后登陆控制台,顶部是整个平台的顶级菜单。到这里,注册这个步骤就算顺利结束了。
2. 登录控制台并开通产品
控制台(Console)是云平台比较常见的一个概念。一方面是监控所有已经购买的资源,另一方面是给其他子产品提供了入口。
正规的入口是通过 亚马逊云科技控制台,依次选择 服务 → Machine Learning → Amazon SageMaker 来访问 Amazon SageMaker 。这个路径对于明确知道自己要使用的是一个机器学习的产品的朋友,还是比较好找的。
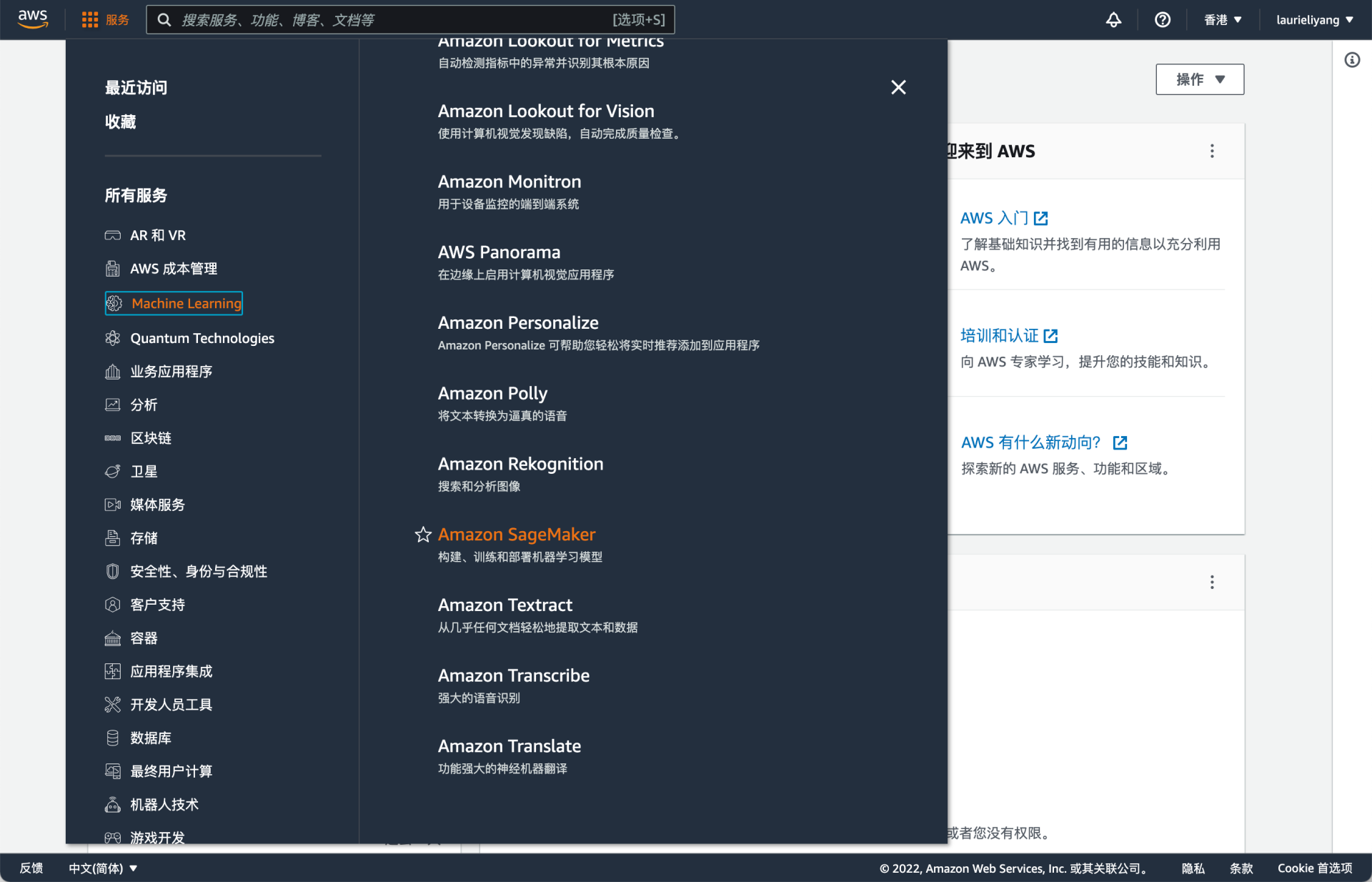
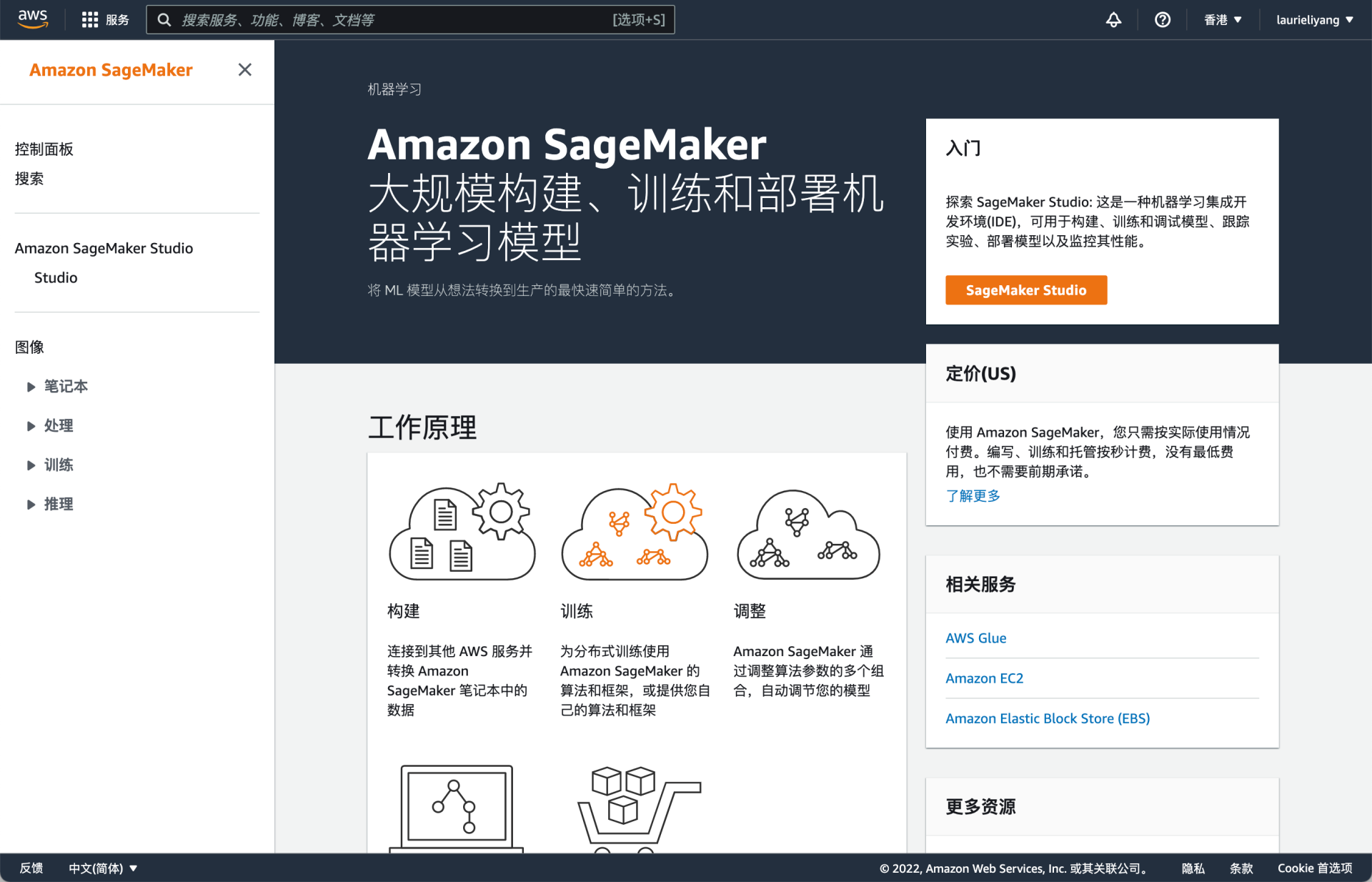
这里出现了一个小插曲。我一开始通过 Amazon SageMaker 这个关键词直接进入了 Amazon SageMaker 这个产品。后来发现没有 Canvas 选项,才意识到可能是某些操作出了问题。
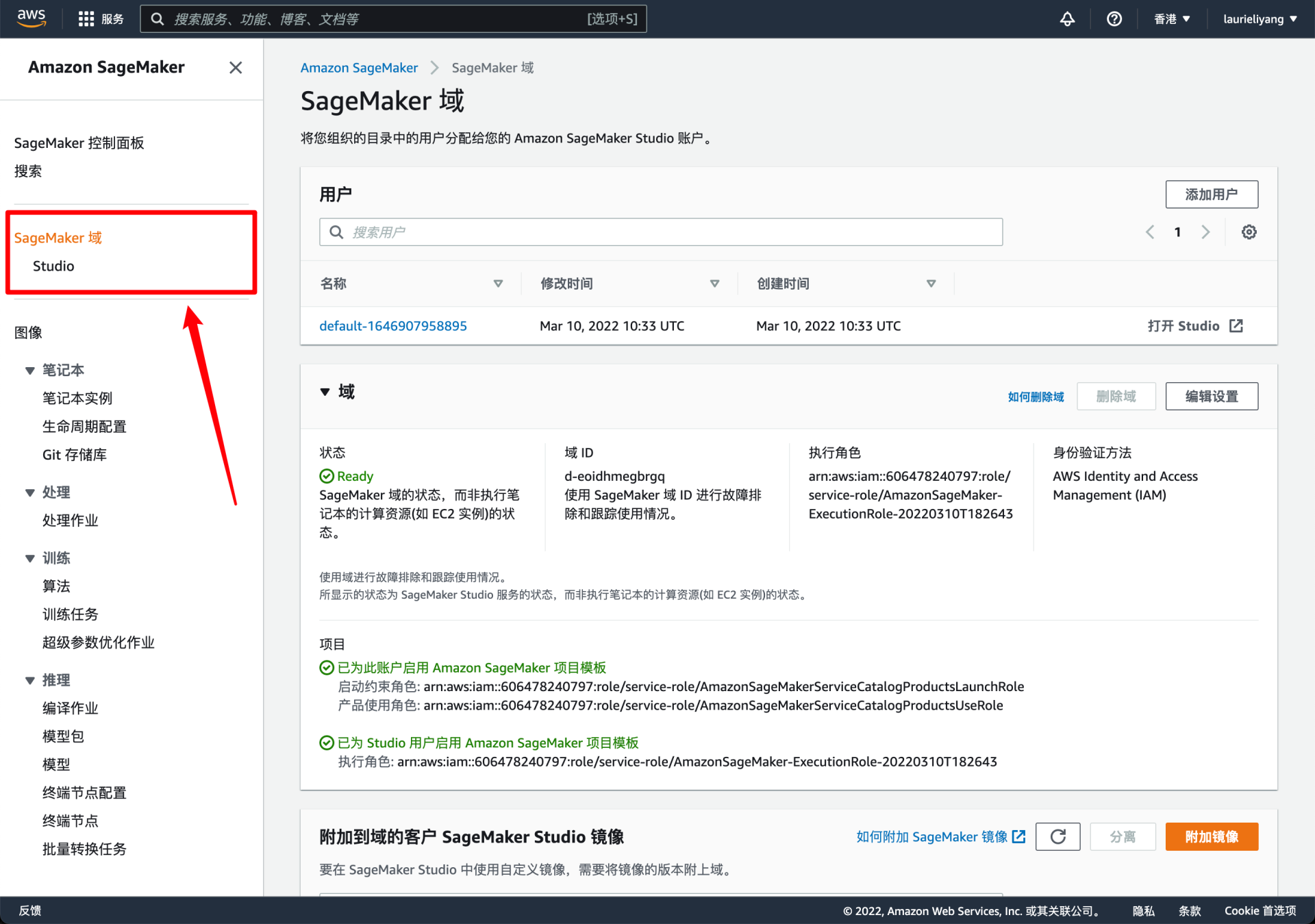
看了主办方提供的文档之后,才发现是选错了区。可能有不少小伙伴跟我一样,在第一次注册时候自动分配到了国内的香港区。后来切换到了美国的 us-east-1 区,然后就能看到关于 Amazon SageMaker Canvas 了。另外有一个小问题,就是切换到美东区后偶尔会遇到网络会不稳定,多刷新几次就行了。
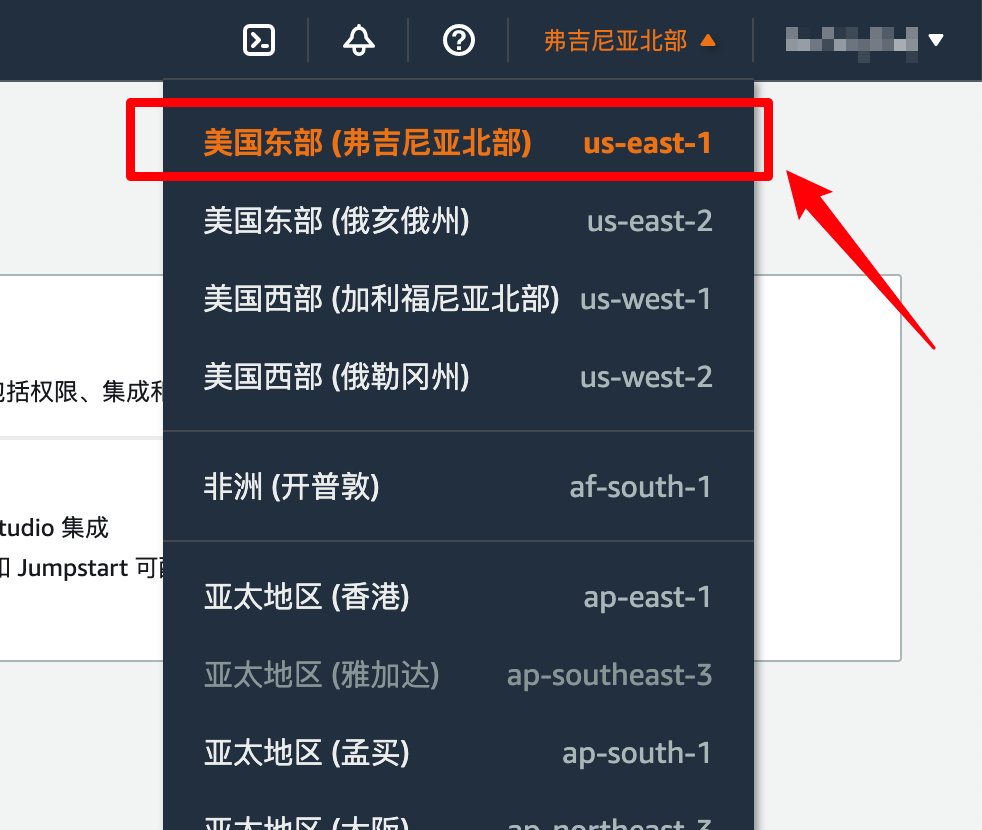
在切换区之后,语言可能就变成了“English(US)”。还要继续用中文的话,可以通过顶部菜单右上角的“设置”中切换语言。
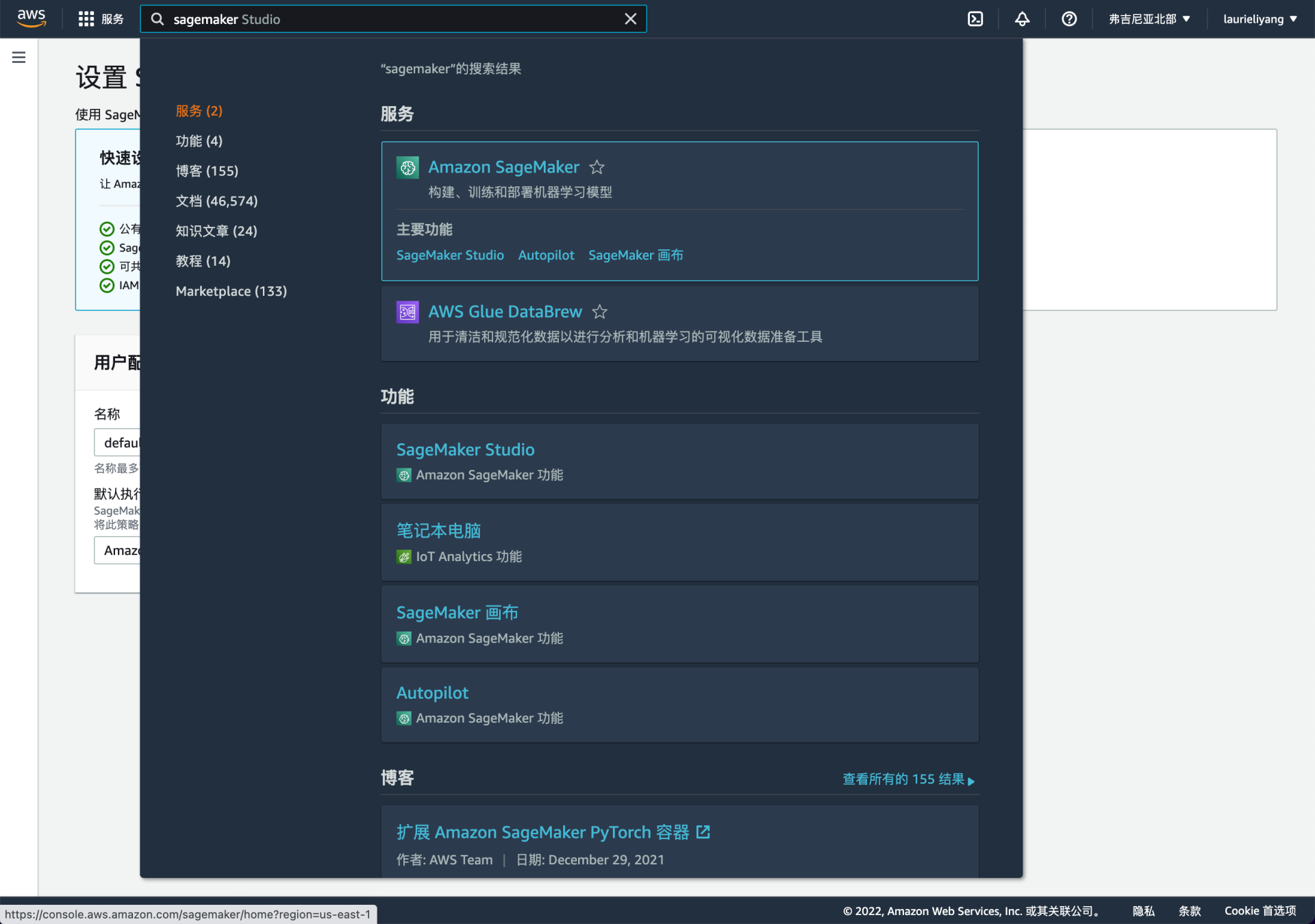
切换区域之后,懒得再从菜单进了,直接通过控制台顶部的搜索框输入关键词来进入 SageMaker 。这也是控制台通常都会提供的功能。
顺带一提,如果你跟我一样首选语言用的是“中文(简体)”,那么 SageMaker Canvas 的中文名叫 “SageMaker 画布” 。这个名字倒是很符合“无代码”的意思。
3. 创建 Amazon SageMaker 域
接下来,又是一个对于非技术用户比较有难点的事情,就是为使用 SageMaker 这个产品初始化一些配置。主要是为这个产品配置子账号和角色,用来分配数据读写等权限,并配置相应的计算、存储、网络等资源。在国内的公有云平台也会有类似的操作,只不过体验做的比较好的话,会提供一套默认的初始化配置。
简单理解,创建了一个 SageMaker 域,就相当于与给你的 SageMaker 分配了一台“微型电脑”,用来进行所有后续的模型设计和训练等操作。
亚马逊云科技的设计对于小白用户稍微有些门槛,因为你可能并不能理解这一步是要做什么。当然,直接点击“提交”对于小白用户来说也并没有带来什么困扰。
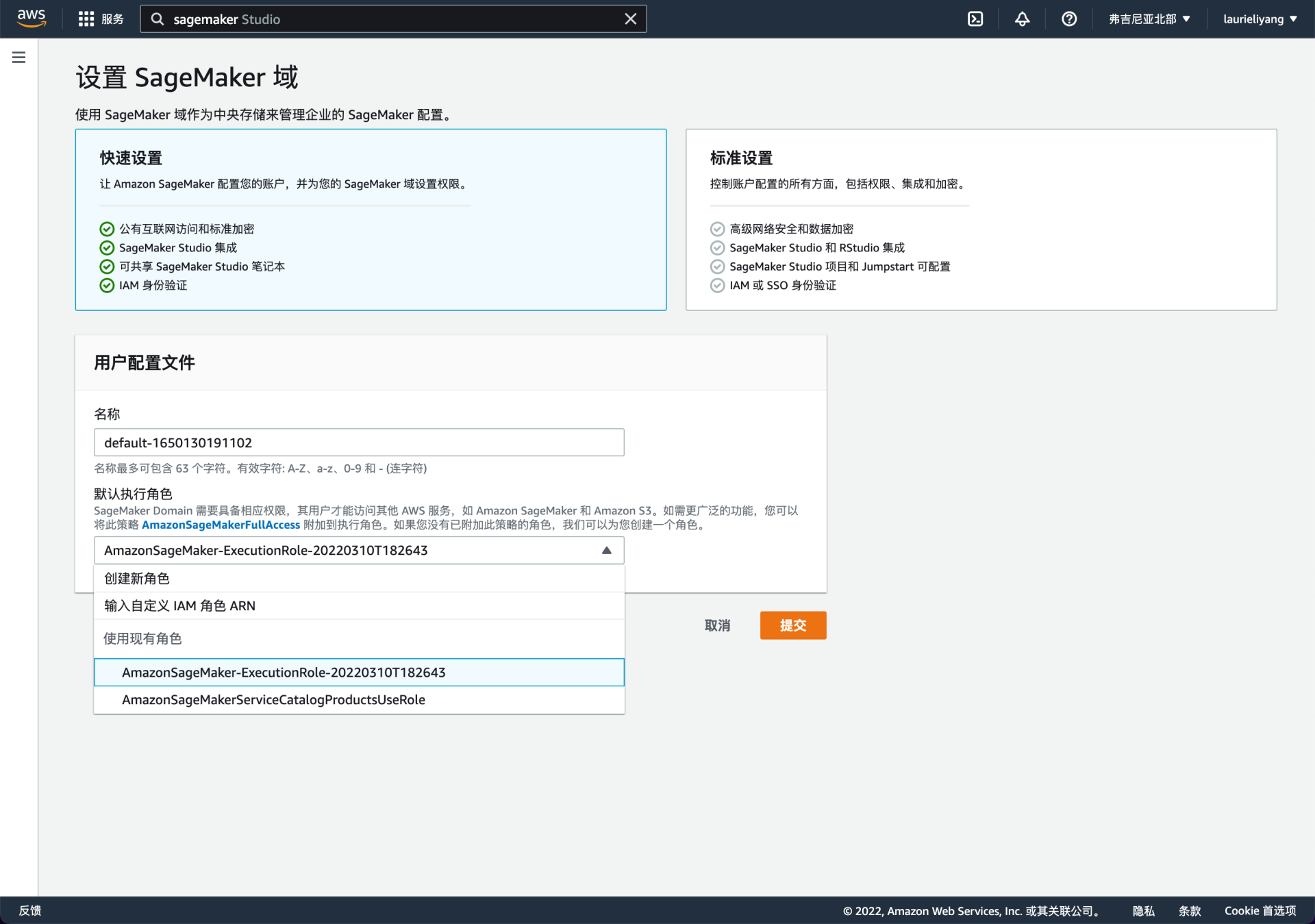
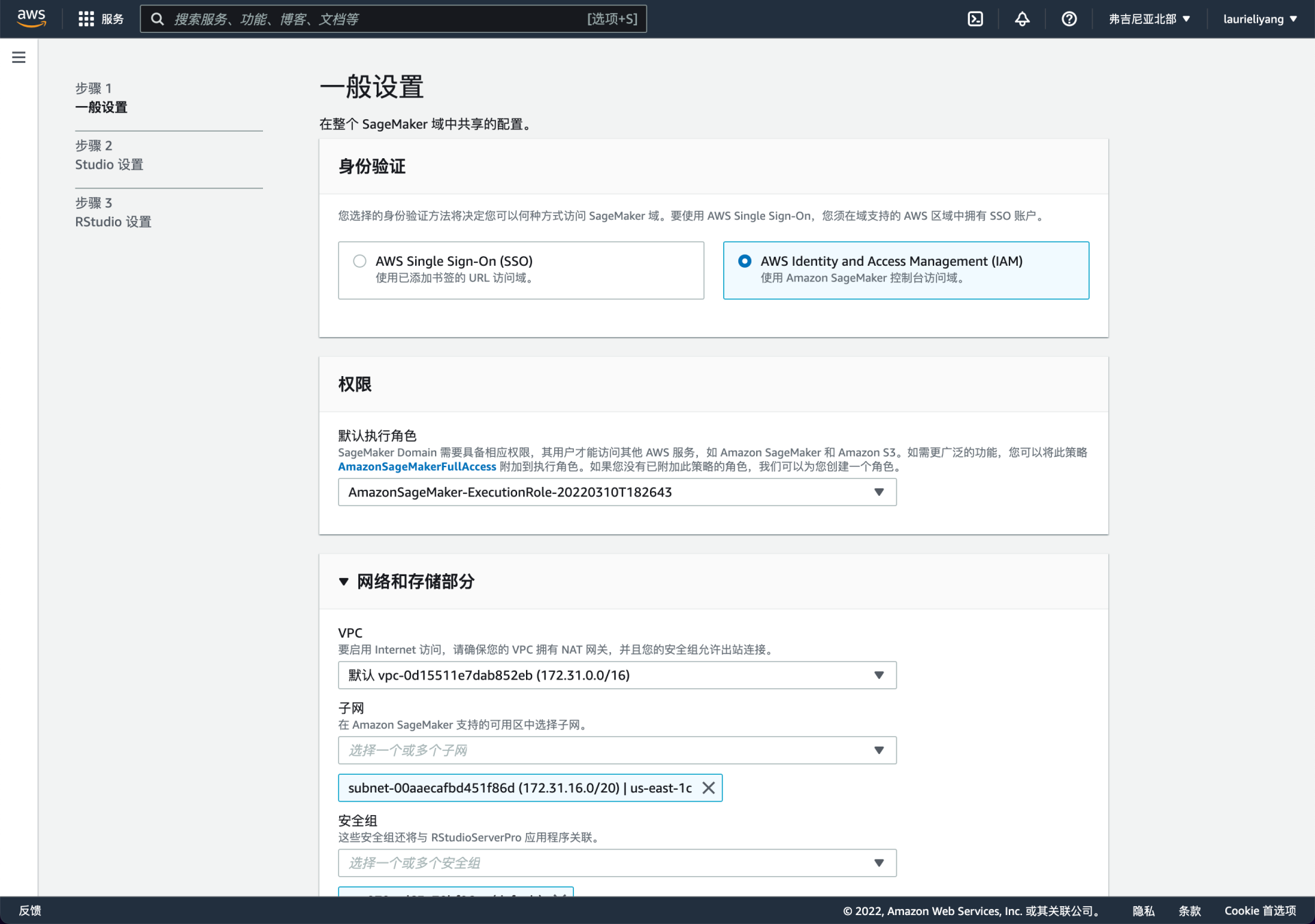
但是如果你是具有技术背景的专业型用户,同时还有很明确的配置诉求,那么“标准配置”的模式可能更适合你。因为你可以在这里修改成自己想要的配置,从权限到网络存储等基本配置都能掌控。
当然如果你像我一样是个强迫症,改掉 default 换一个更有意义的名字可能才是头等大事。
到这一步结束了吗?还没。
看到页面上方的蓝色条幅了吗?根据刚才的配置, 亚马逊云科技正在为你创建相关的用户、角色,分配权限和资源等。同时域的状态一栏也显示为“Pending”。这个过程中我们做不了什么,等着吧。
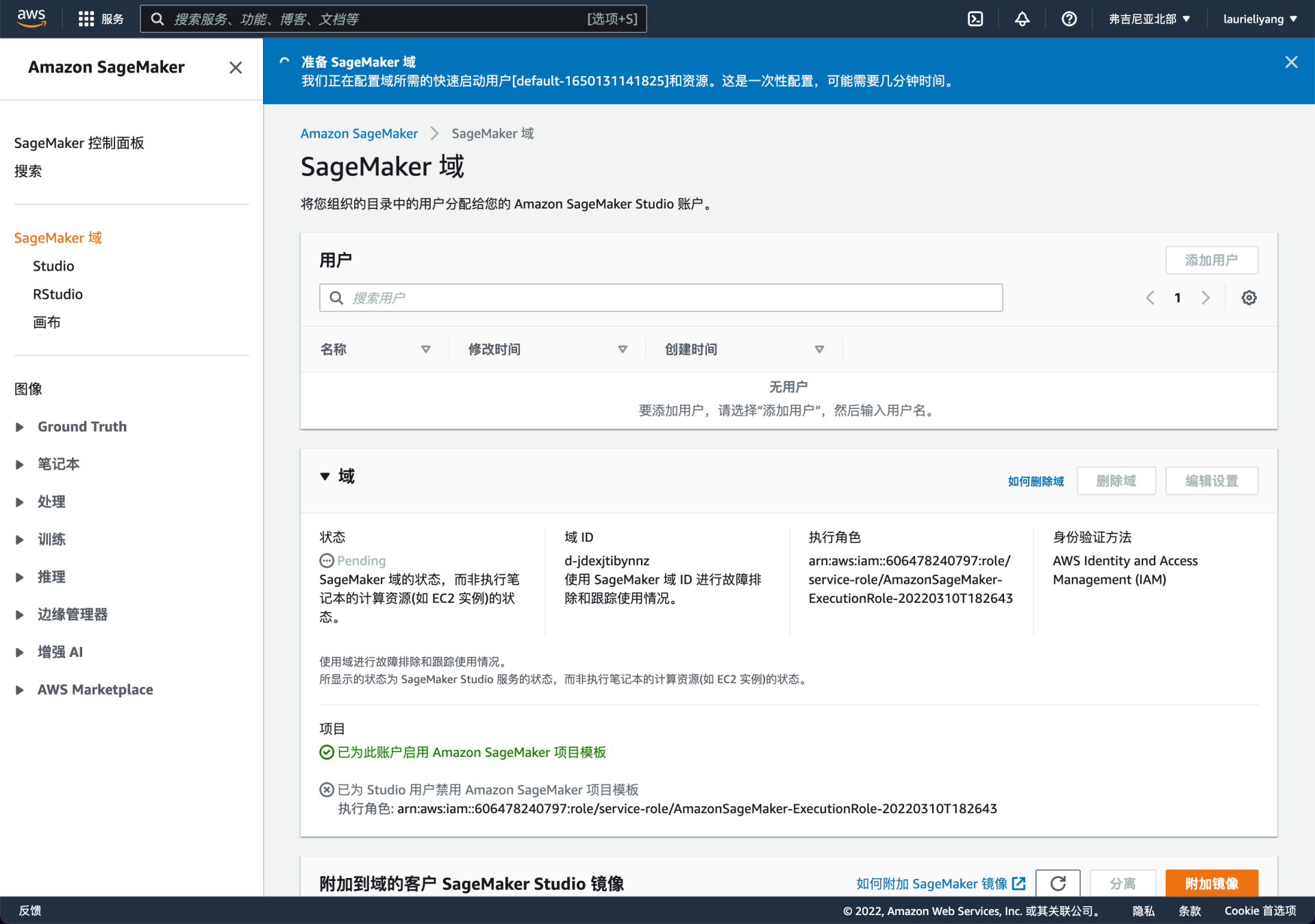
到这一步,看到绿色条幅提示,并且下面域的状态也变成了 Ready ,才算真正可以使用了。
总结起来,整个注册过程的流程图如下:
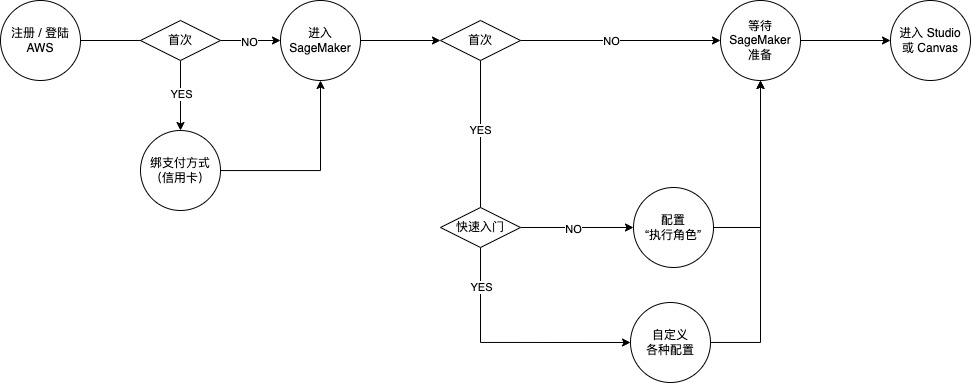
整个初始化过程对于小白用户可能有些云里雾里,但是无可厚非,因为其他公有云产品基本也是这样的。好在这些配置都是一次性的,如果没有修改配置的诉求,那么以后再也不会经历这个过程了。不过,如果能通过沙盒环境或者 Demo ,让小白用户更快上手,可能就更好了。
二、开始使用 SageMaker Canvas
从左面的菜单看, SageMaker 提供了多种开发工具环境:
- “Studio”对应的是做算法的朋友比较熟悉的 Jupyter Notebook (版本 1.2.21) 。由于不是本次评测的重点就简单看了下,开发语言用的是 Python 3.7.10 ,环境是 Anaconda 4.6.14;
- “RStudio”对应的应该是数据分析师朋友可能更熟悉一点的 R 语言环境。但是不知道问什么,我没打开;
- “画布”就是我们本次要评测的 Canvas 了。
顺带一提,下面的“图像”,英文原词是“Images”。按国内的用词习惯,可能翻译成“镜像”更合适一些。
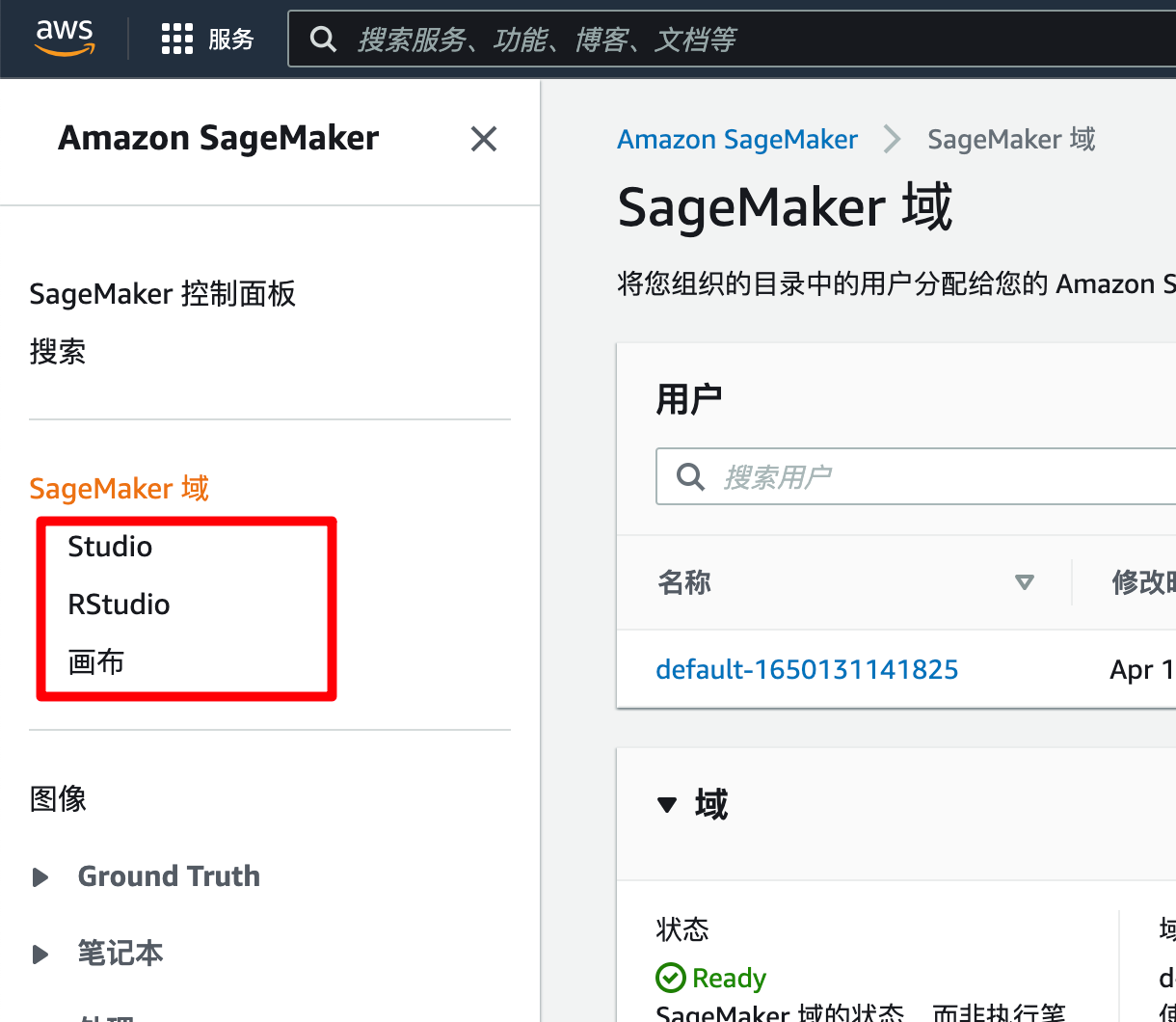
1. 启动 Canvas
Canvas 的入口在“用户”列表中的操作列中,从下拉框里选择“画布”即可。如果你也想我一样创建了多了个用户,选择自己需要用的那个用户。
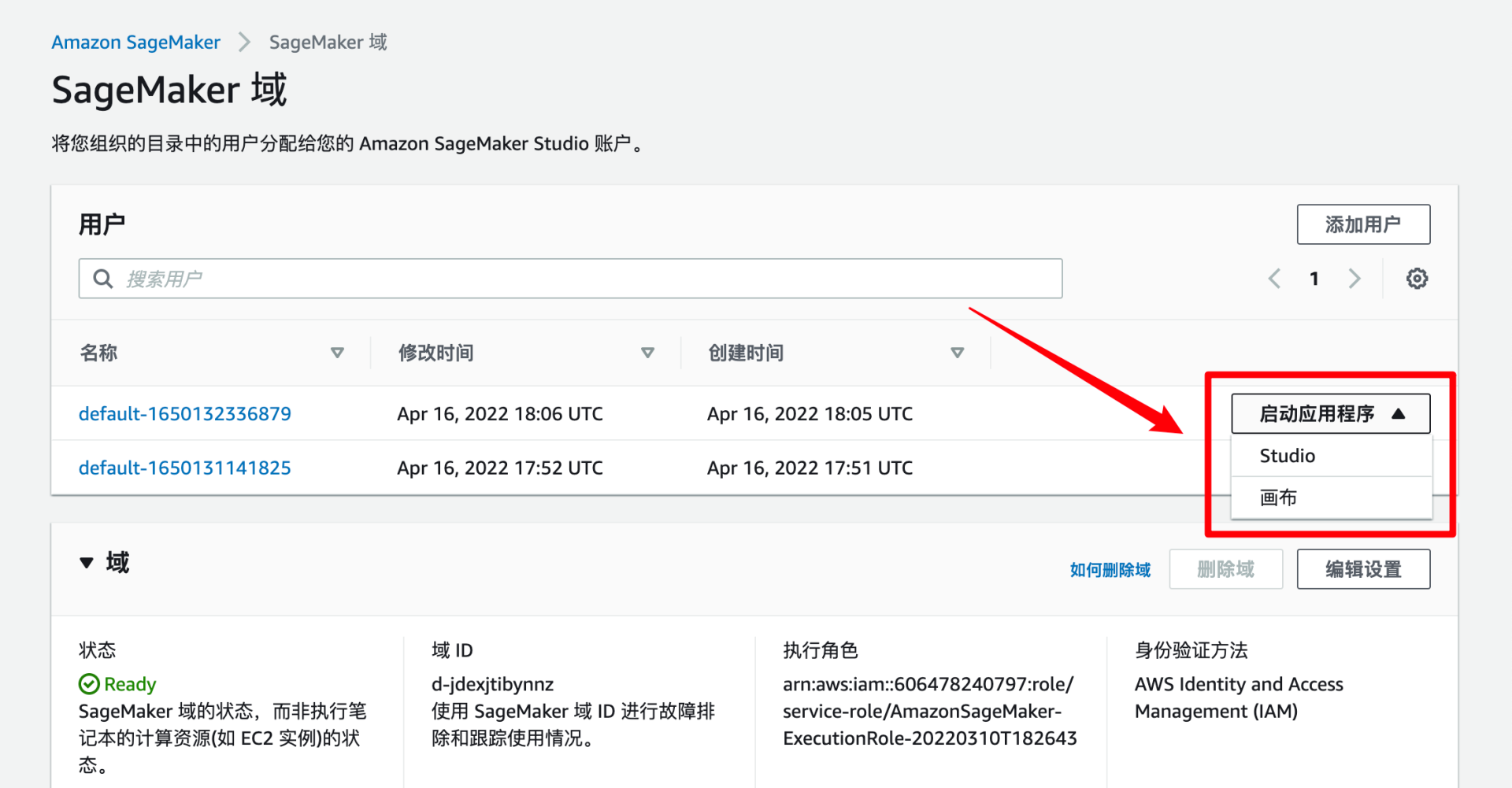
之后是一段过场动画。这个过长我还是等了一些时间的,大概几分钟的样子。这部分应该包括了创建和启动应用实例,另外就是网络稳定性可能导致一些延迟。不行就多等等,或者刷新一下。

进入到下面这页面,我们就正式开始使用 Canvas 了。有点意外的是,视觉设计风格与亚马逊云科技完全不同,似乎更 Flat 了一些。
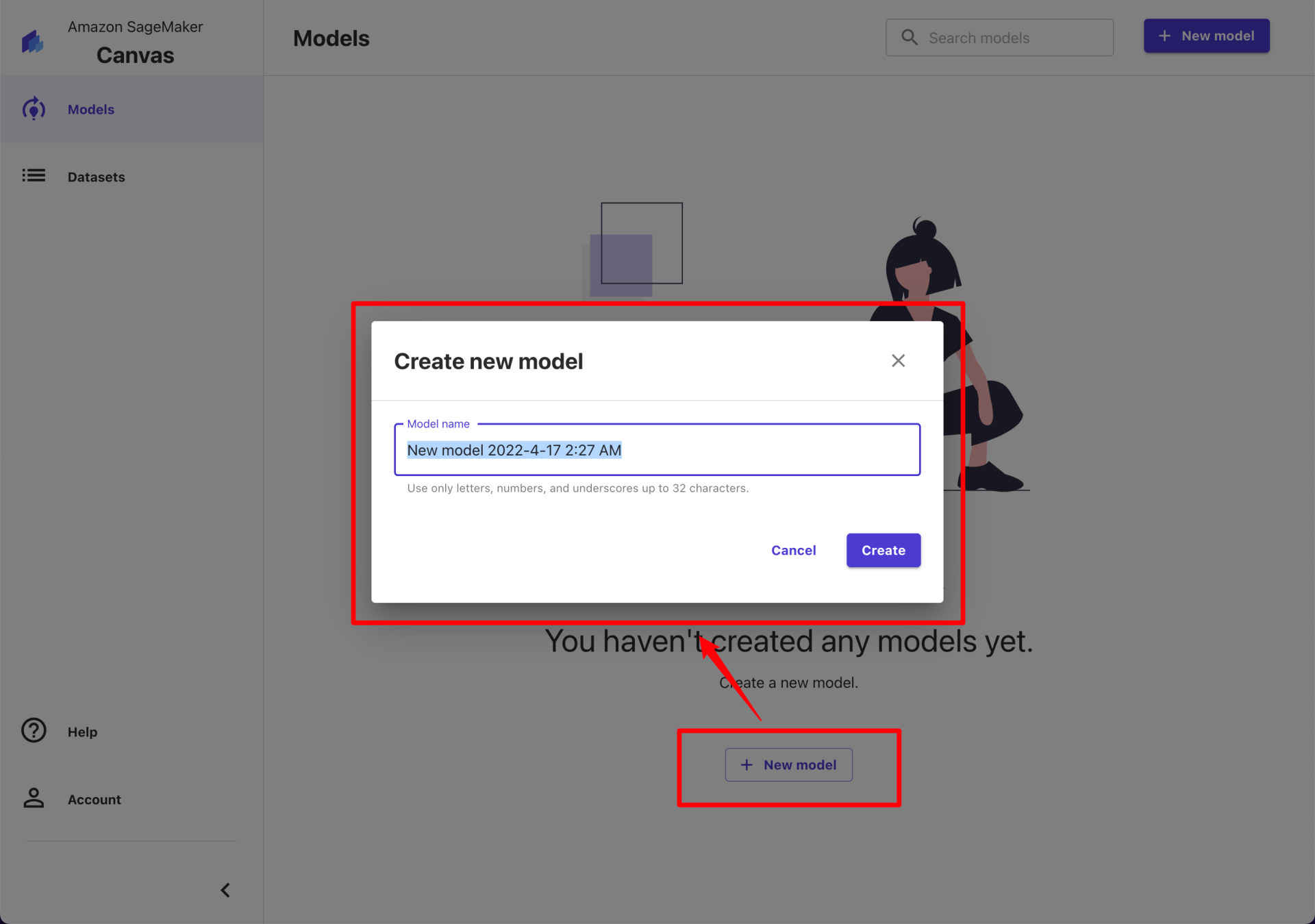
到这里我们继续开启“新手模式”,完全按照页面提示来操作。点击页面主区域的“+ New Model”,开始创建我们的第一个模型。
不过看看左面菜单,提供了两个主要功能,一个是模型(Models),一个是数据集(Datasets)。做算法的同学在实际工作中大量精力需要铺在数据处理上,因此直接新建模型隐隐感觉可能会遇到数据的问题,而且对于非算法背景的同学,与数据的互动可能也是比较吃力的一点。
接下来就看 Canvas 是如何解决这个问题的。
新建模型后, Canvas 按照常规操作提供了新手引导(intro)。看了下,虽然只是静态的截图,但是确实把使用 Canvas 进行建模的全过程介绍清楚了。其中第一步就提到了前面担心的问题,也就是数据的问题如何解决。
如果关闭了操作引导之后还想再看一次,可以从左边菜单中选择“Help”,就又能看到这个弹窗了。
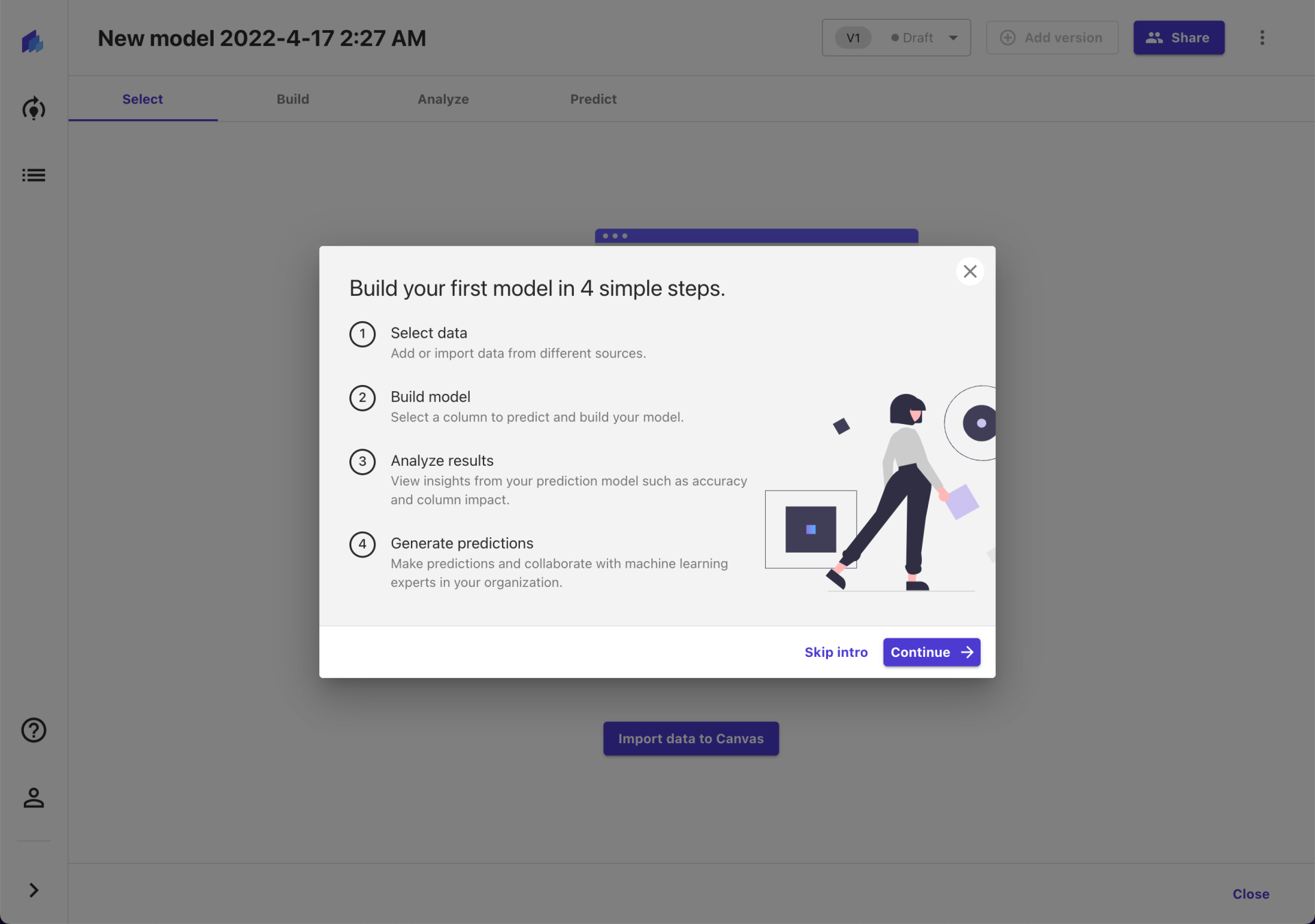
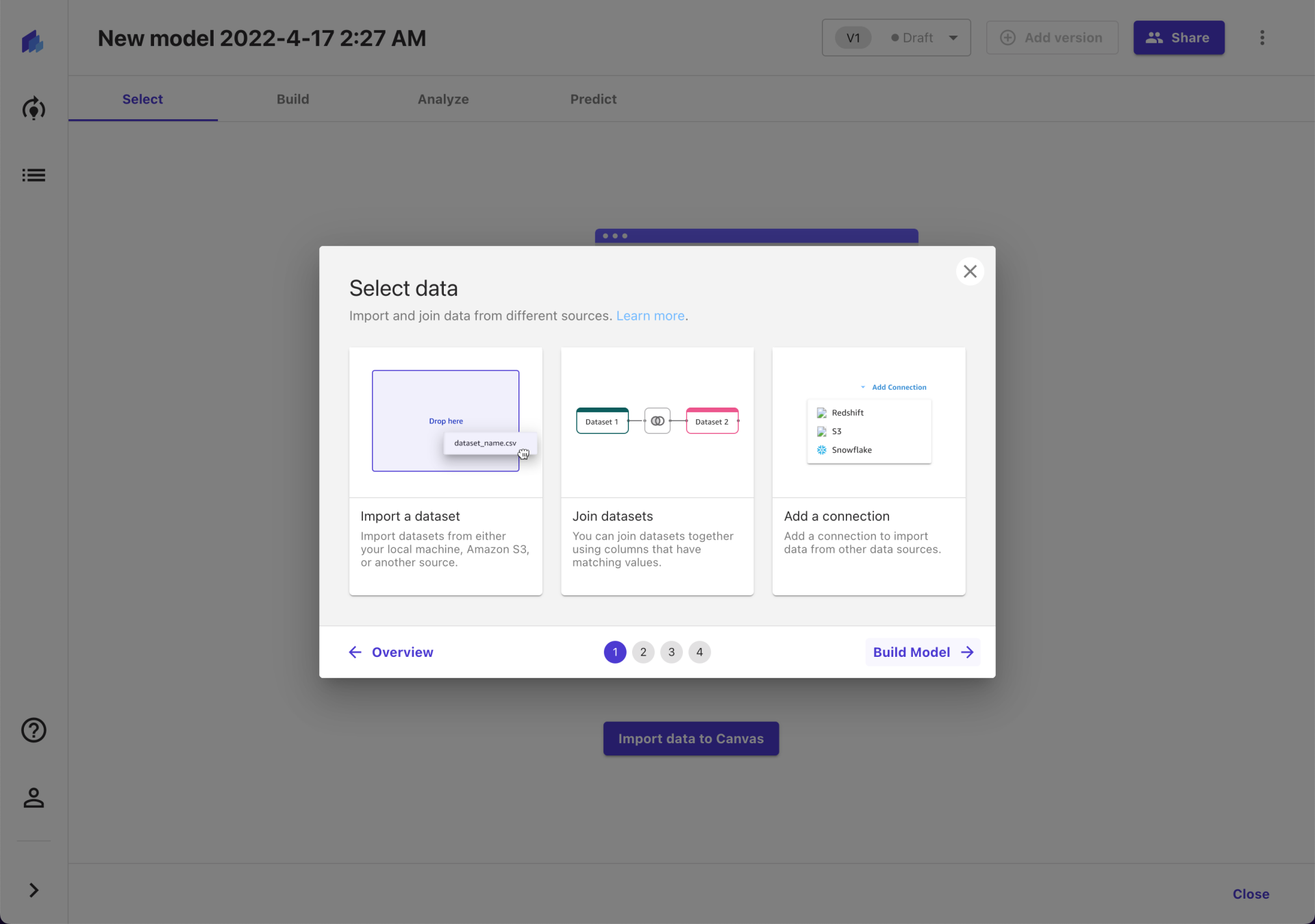
不过咱就是说,这个截图里的图标裂了,官方修复一下呀 ~

2. 开始建立模型
关闭引导之后,就正式开始建模了。通过页面可以看到一个 Model 包括 4 个部分:
① Select 代表导入和管理训练数据集
② Build 代表建模的过程,主要用于确定算法模型中的预测目标
③ Analyze 代表对模型的分析和评价,包括准确率和贡献度等
④ Predict 代表模型部署后对真实数据集做预测
1)准备数据集
这里我们采用一个公开数据集,是关于共享单车的需求量的:https://www.kaggle.com/competitions/bike-sharing-demand 。
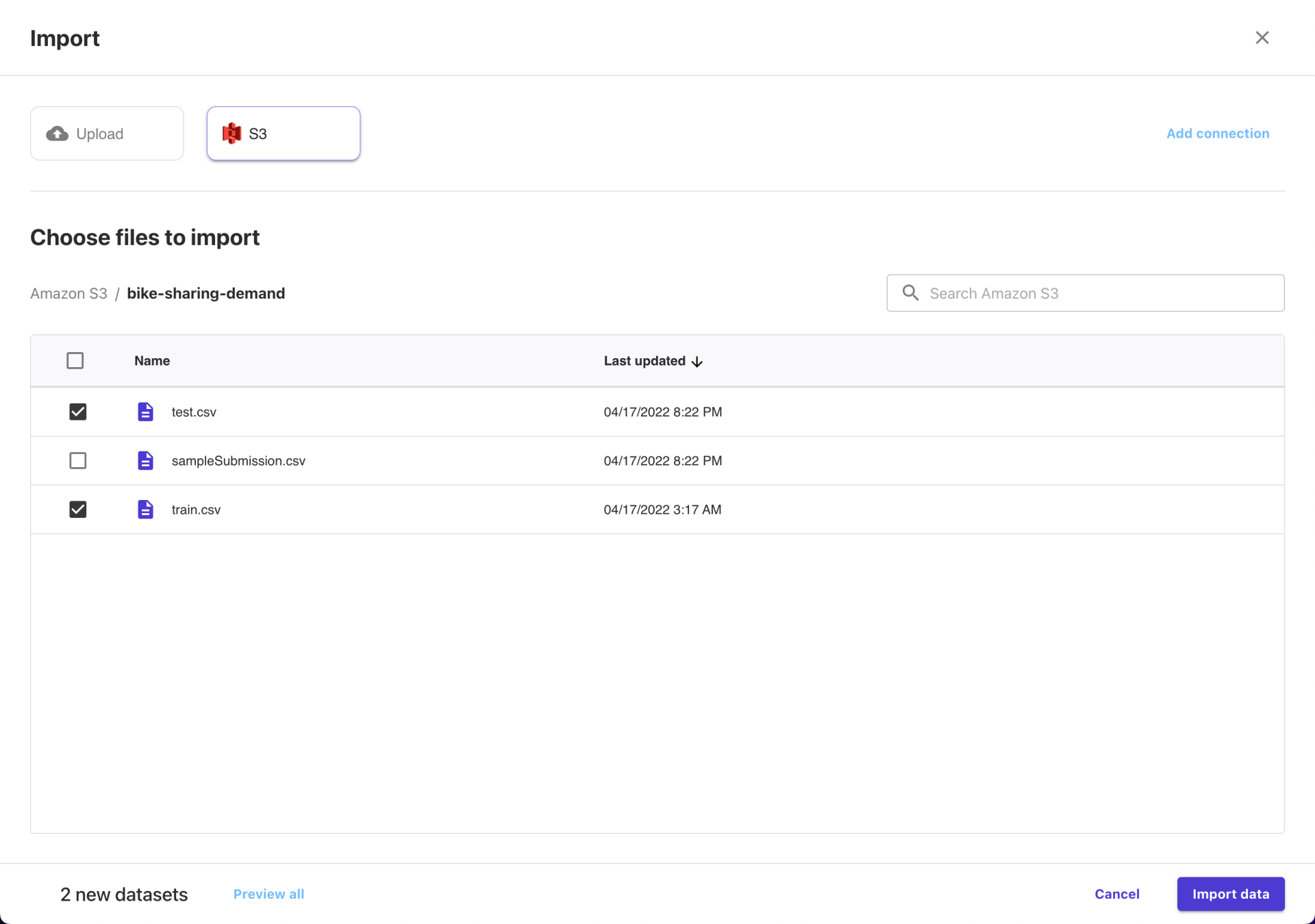
选择其中的训练集 train.csv 和测试集 test.csv ,通过 Amazon S3 将数据文件上传到一个 Bucket (这一段具体步骤略过)。切换到“Select”页签下,点击“Import Data to Canvas”,就能看到导入数据的指引了。这里直接选择 Amazon S3 方式,选择上传的数据文件。
这一步怎么评价呢?也算是使用云产品的基本操作吧。不过可能会让不少小白用户再次遇到一个坎。如果能在 Canvas 内部提供与 S3 之间的数据同步功能,可能体验会更好。虽然 Canvas 这里也确实提供了 Upload 方式,但是需要先配置与其他存储介质的链接参数。实话实说,这对于小白来说就有些“硬核”了。
2)Build 阶段
导入并选择数据集之后就进入了 Build 阶段了。模型数据集中的字段包括:
- datetime – hourly date + timestamp
- season – 1 = spring, 2 = summer, 3 = fall, 4 = winter
- holiday – whether the day is considered a holiday
- workingday – whether the day is neither a weekend nor holiday
- weather – 1: Clear, Few clouds, Partly cloudy, Partly cloudy, 2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist, 3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds, 4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
- temp – temperature in Celsius
- atemp – “feels like” temperature in Celsius
- humidity – relative humidity
- windspeed – wind speed
- casual – number of non-registered user rentals initiated
- registered – number of registered user rentals initiated
- count – number of total rentals
这里我们选择预测的目标字段是 count 。在模型类型(Model Type)中选择数值预测(Numeric prediction)(暂时忽略那个小三角警告)。
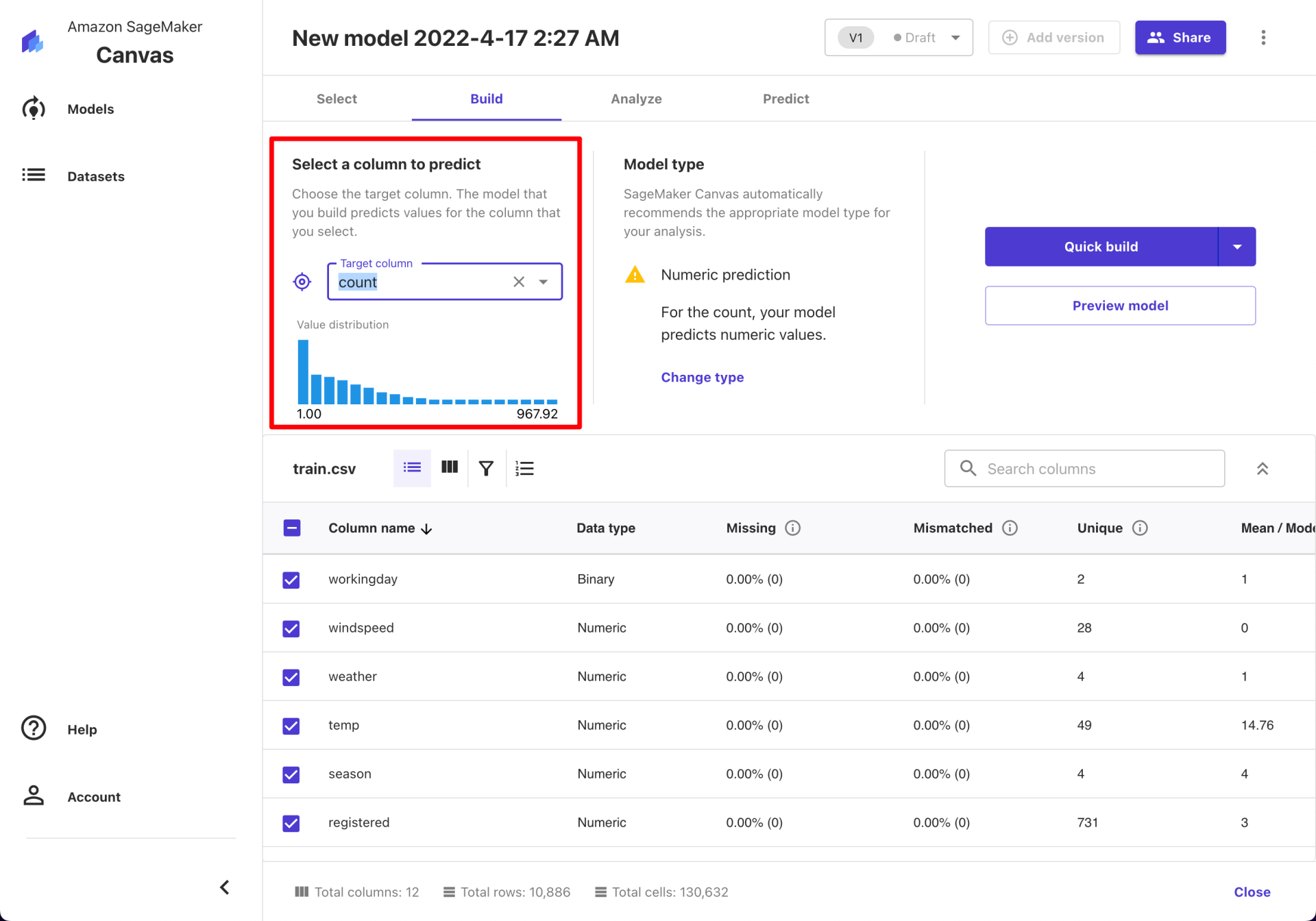
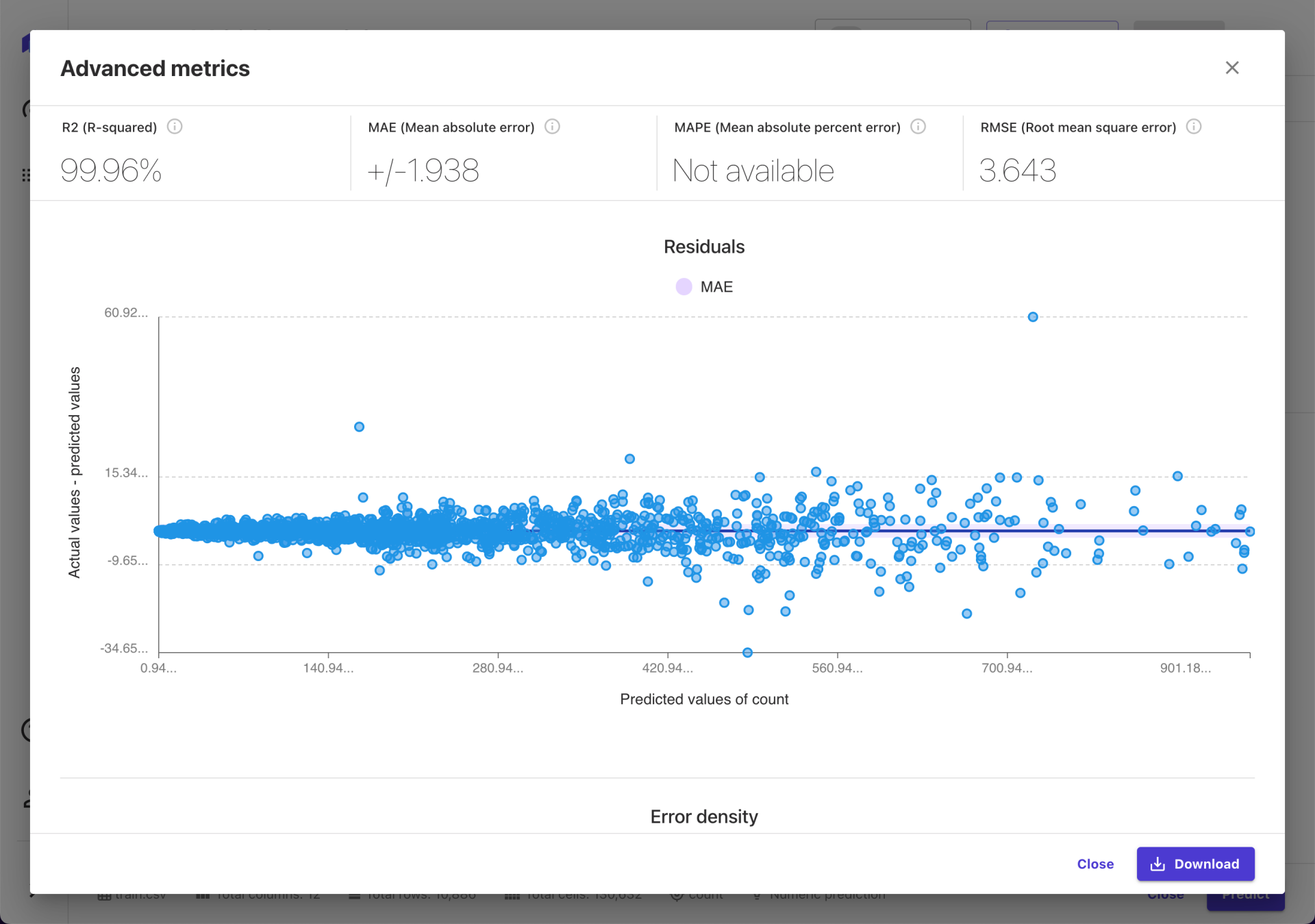
在实际创建模型之前, Canvas 提供了预览模型效果的功能。点击“Preview model”,下方会展示均方根误差(RMSE)和特征贡献度(Column Impact)。
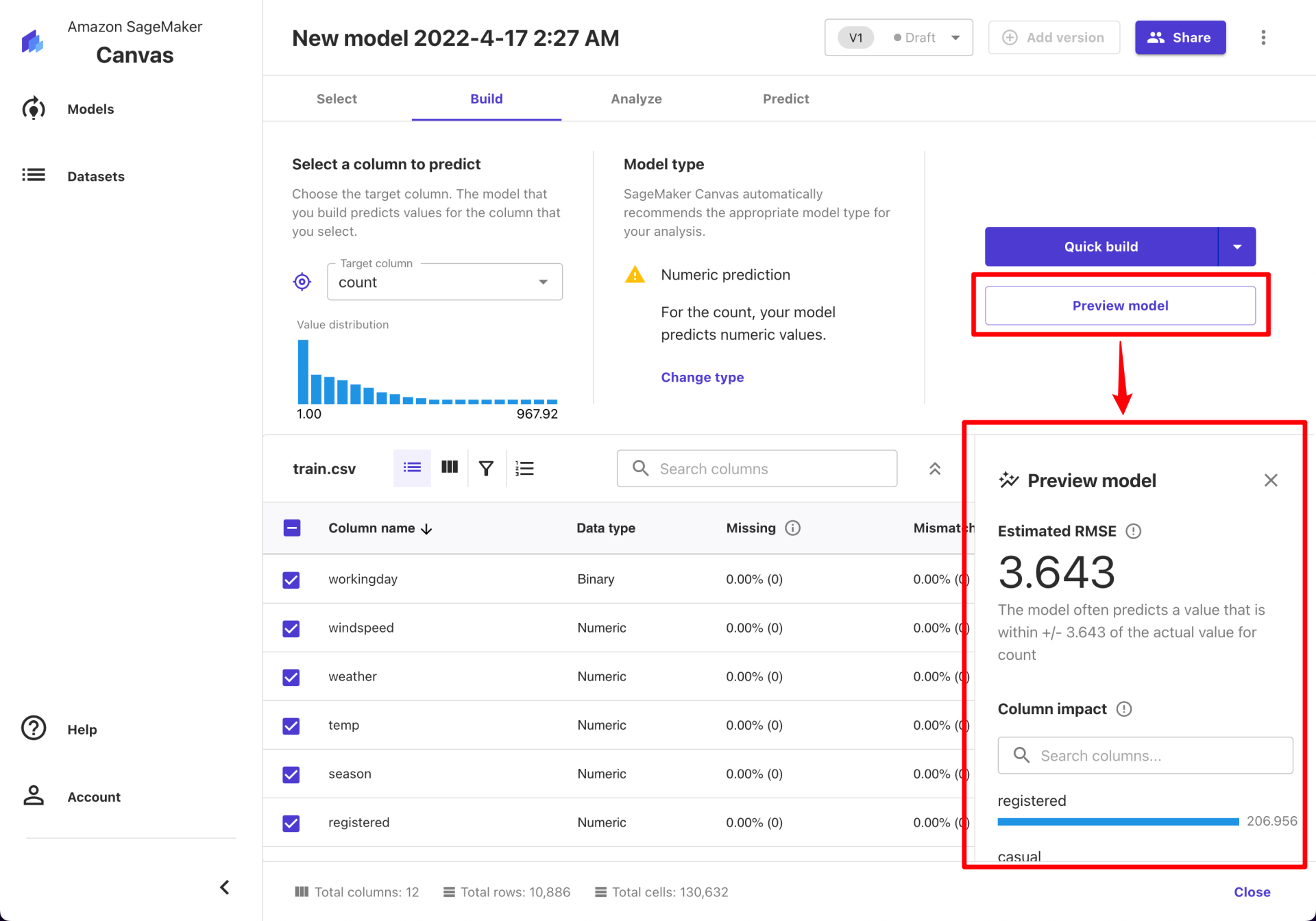
接下来我们正式构建模型,点击“Quick build”。之后还是要等一下。
3)模型分析
完成模型构建后,我们就能在 Analyze 菜单中看到模型的各方面情况了。主要包括整体情况(Overview)和评分(Scoring)两部分。实话实说,这块我就不是很专业了哈哈哈,所以也就不瞎解读了。
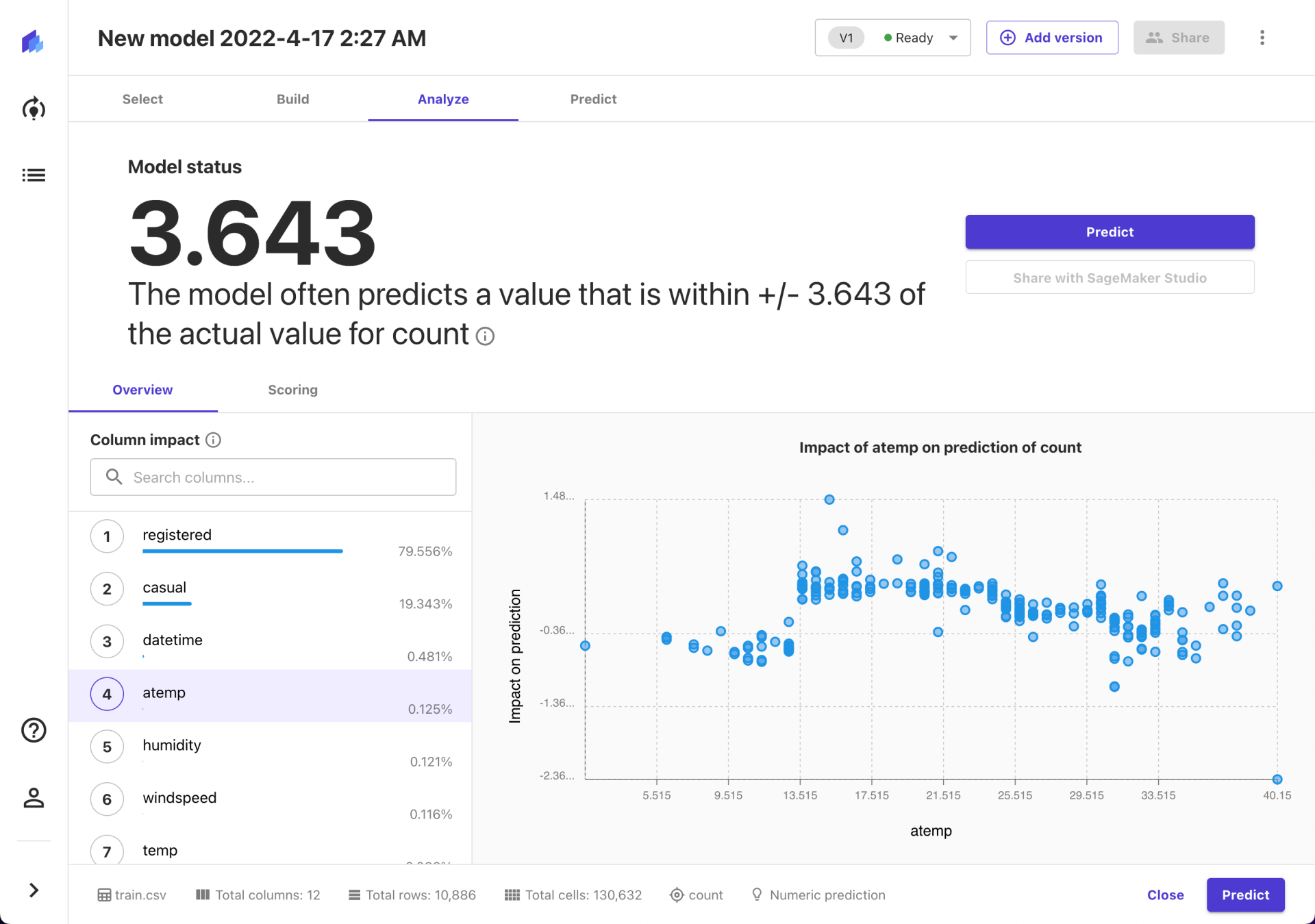
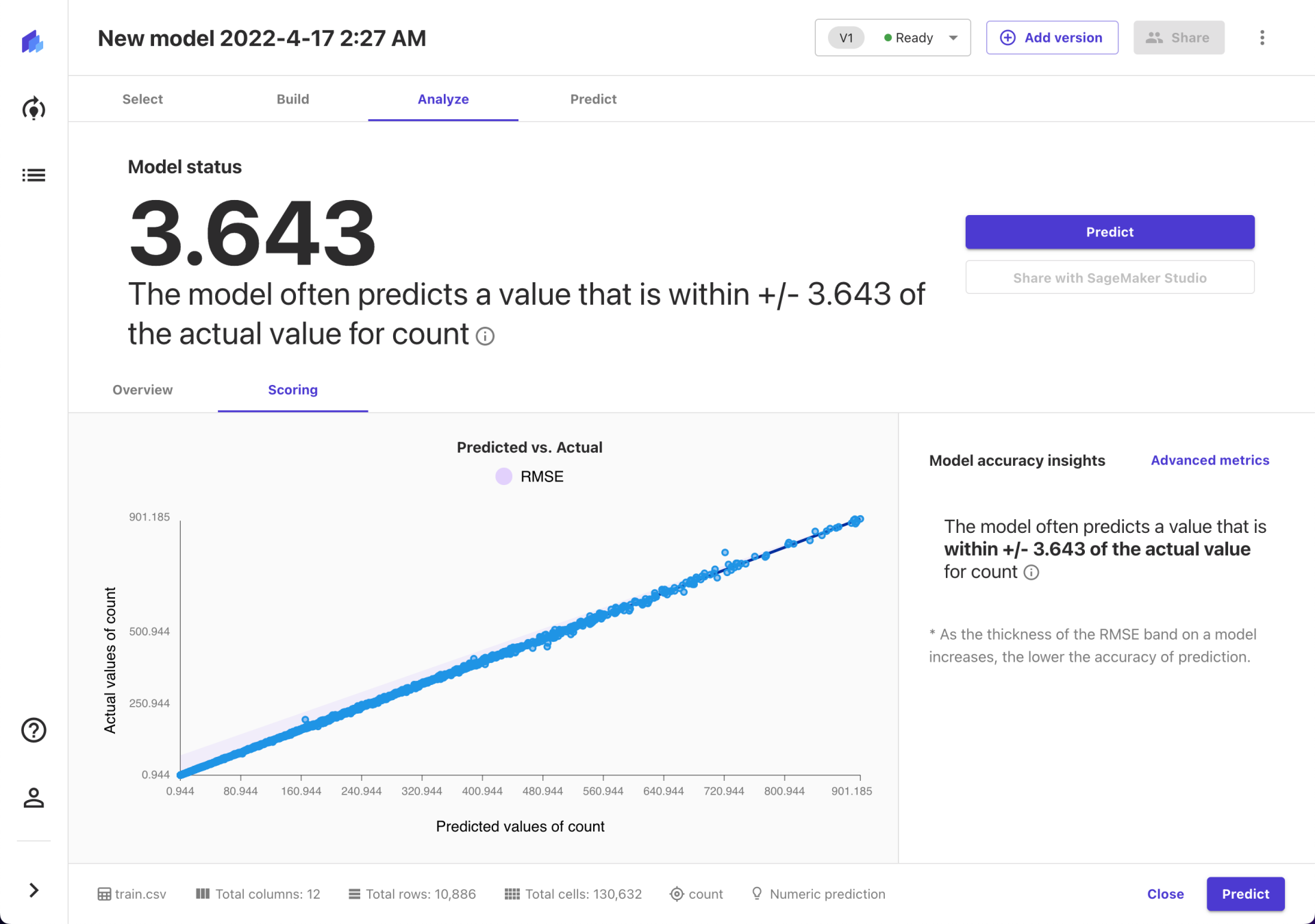
最后再说一点,就是在 Scoring 页签下还有一个 Advanced metrics 入口。如果你没有找到自己想看的指标,可以在这里再找一下。
4)模型预测
我们假设模型的训练结果看起来一切良好,那么接下来就是实际使用这个模型做预测了。
切换到 Predict 页签,在选择数据集中点击 Select dataset ,选中前面已经准备好的 test.csv 。
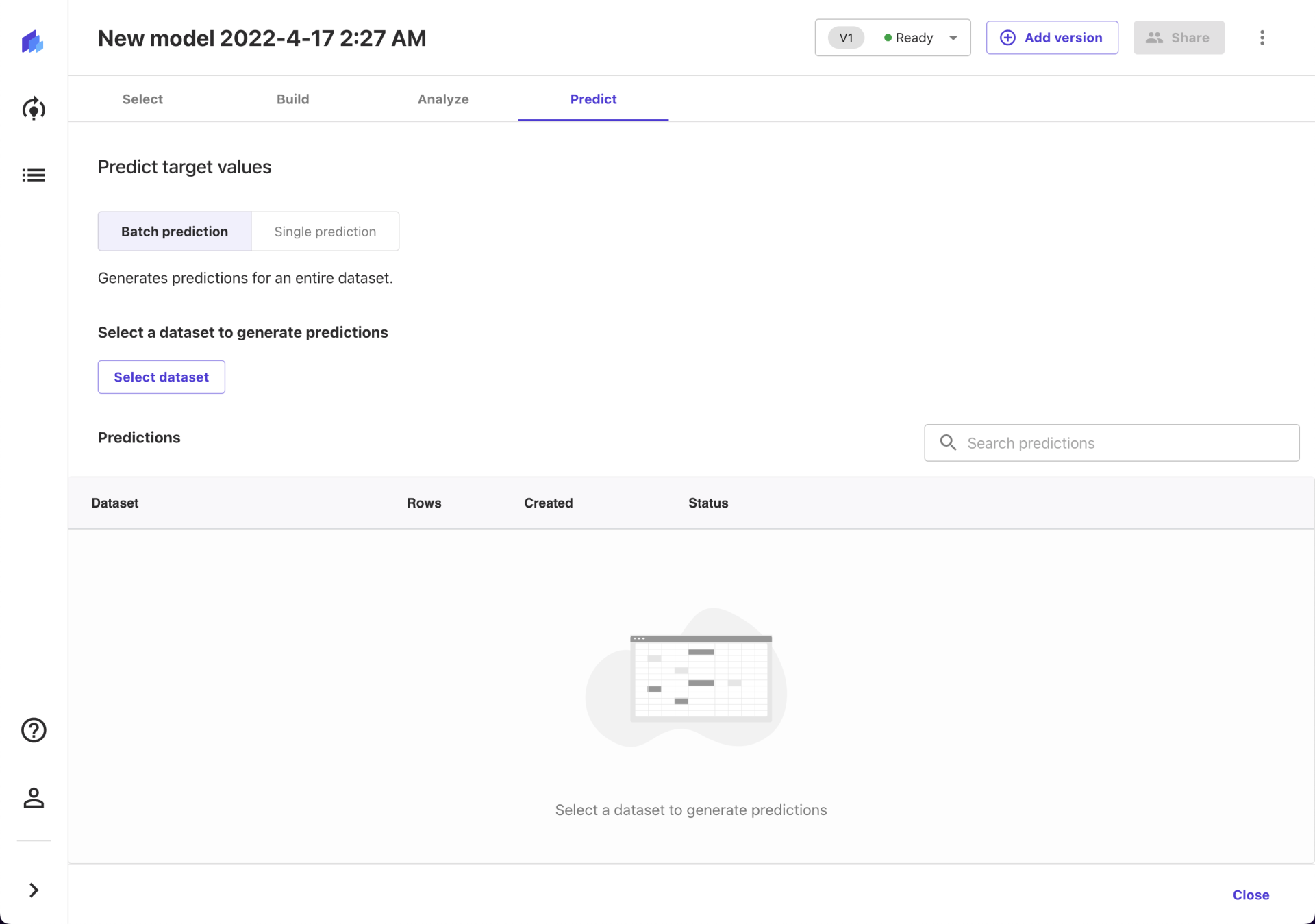
这时出现了第二个小插曲:test.csv 中没有 casual 和 registered 两个字段,导致这个数据集不能用。
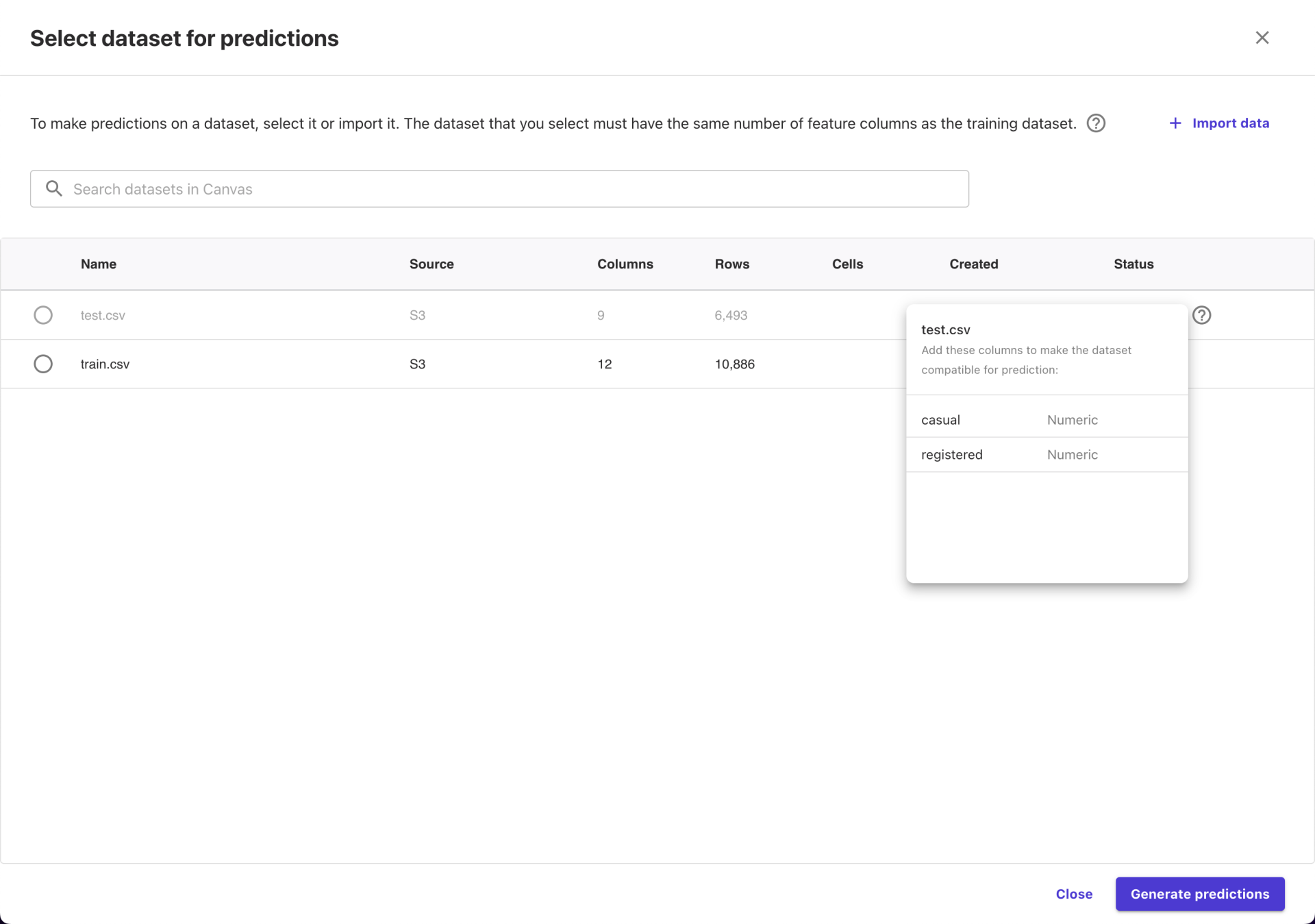
只好在自己电脑上处理了一下 test.csv ,“伪造”了两列并重新上传,这样就可以用了。
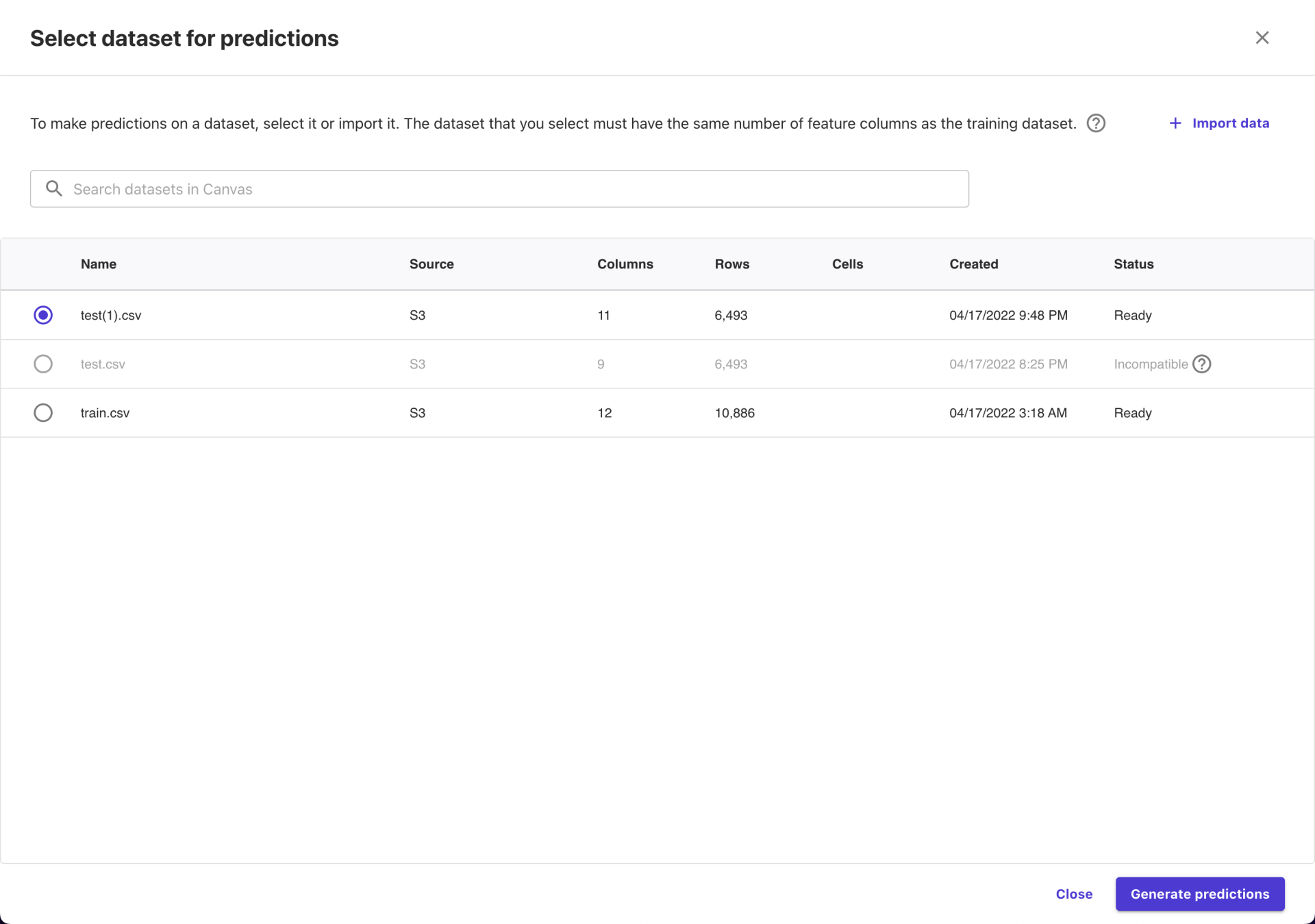
点了 Generate predictions 之后,模型就开始做预测了。预测的过程还是挺快的,但是到这里,交互逻辑与前面几个步骤稍微有点不一样了。我以为预测的详细结果会直接出现在页面的下方,结果收到了一条通知,说预测结果已经完事了。好在这个通知是不会自动关闭的,不然可能不少小白会停留在这里不知所措了。
当然,从预测这件事本身出发,我是可以理解这个设计的。毕竟可能需要用一个模型对多个数据集做预测。以列表的形式确实更容易管理所有的预测动作和结果。
点击通知中的 View 之后,我们就看到预测结果了。
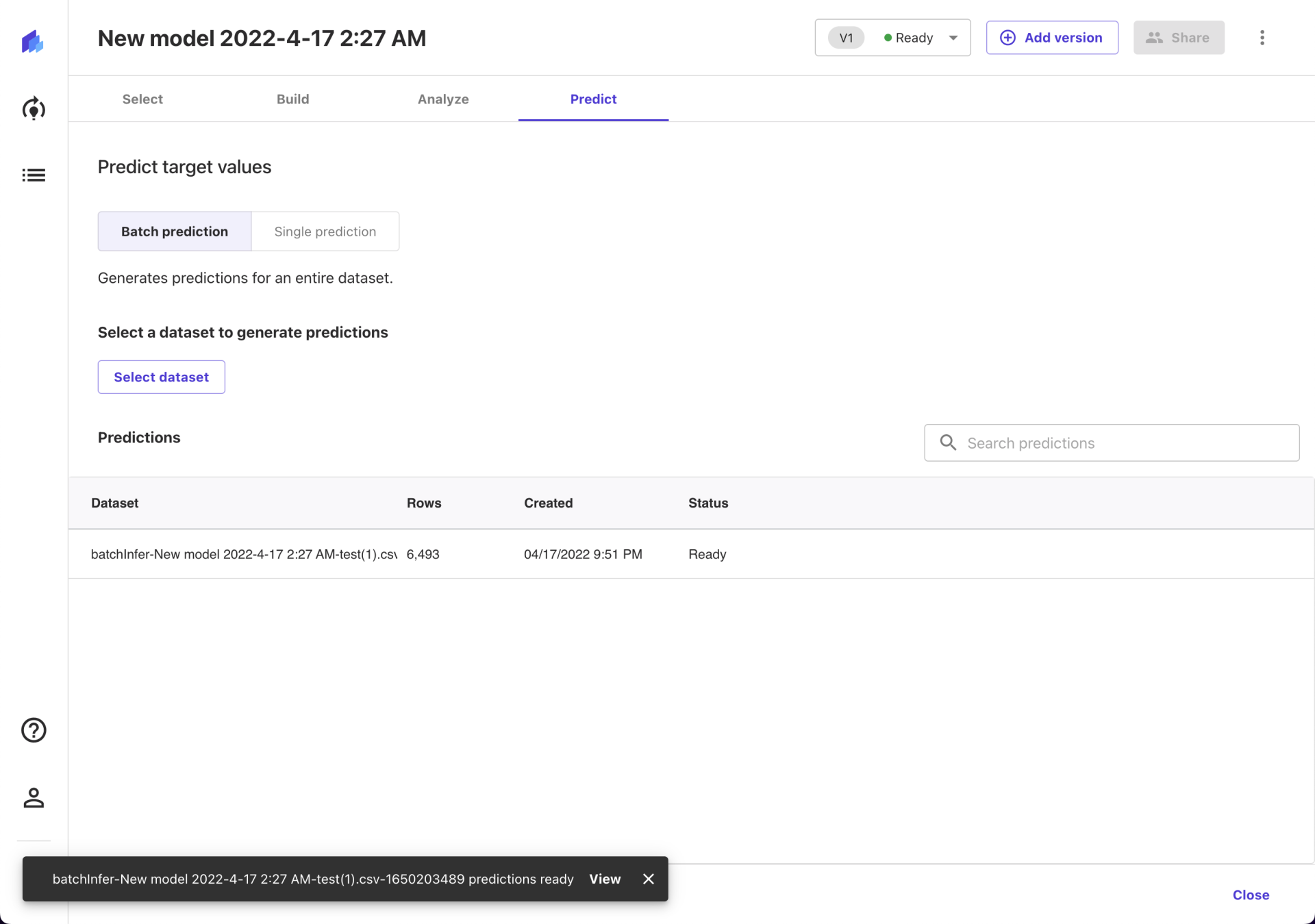
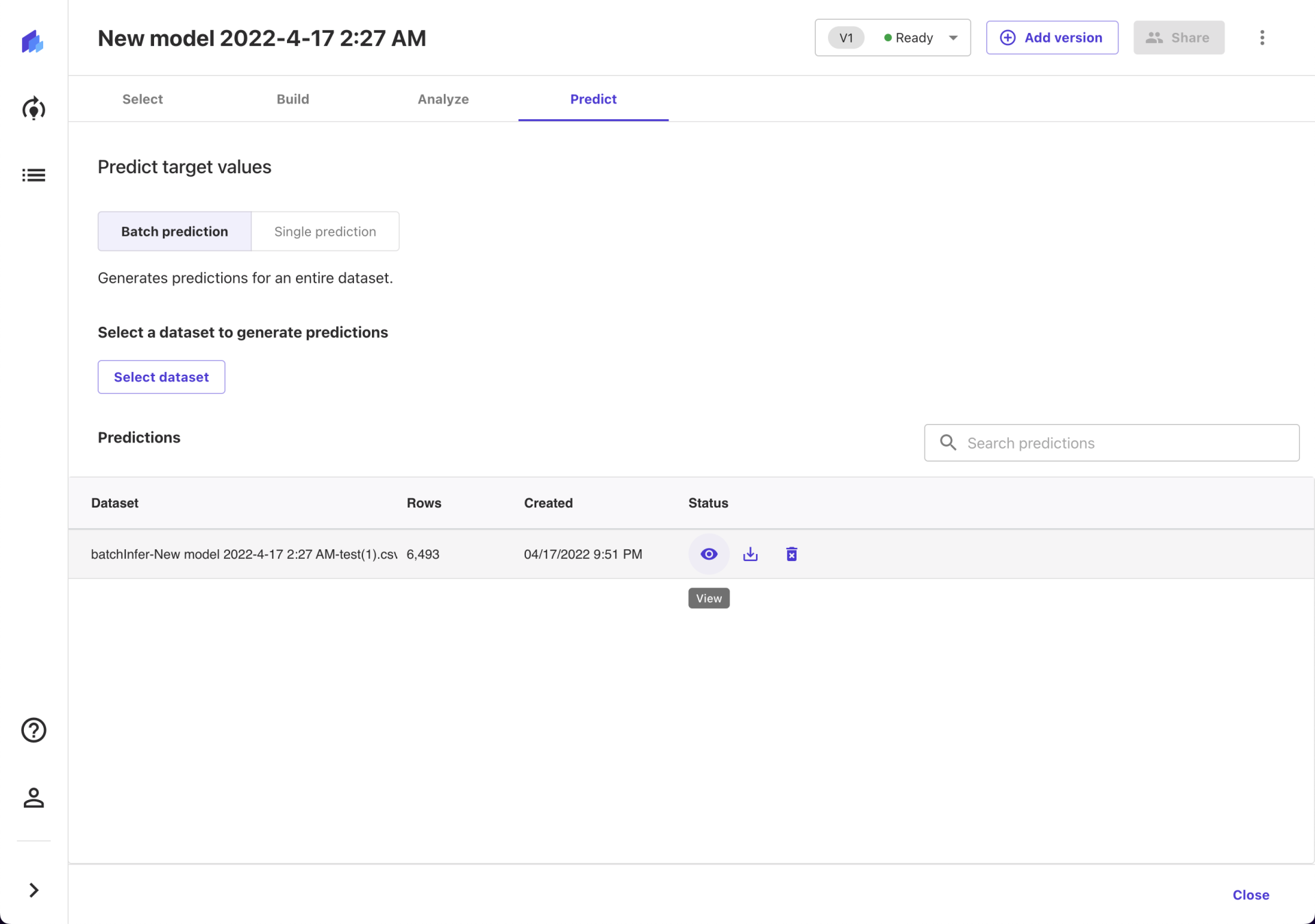
当然,更正式的方式是从页面下方的列表中,点击 View 按钮。
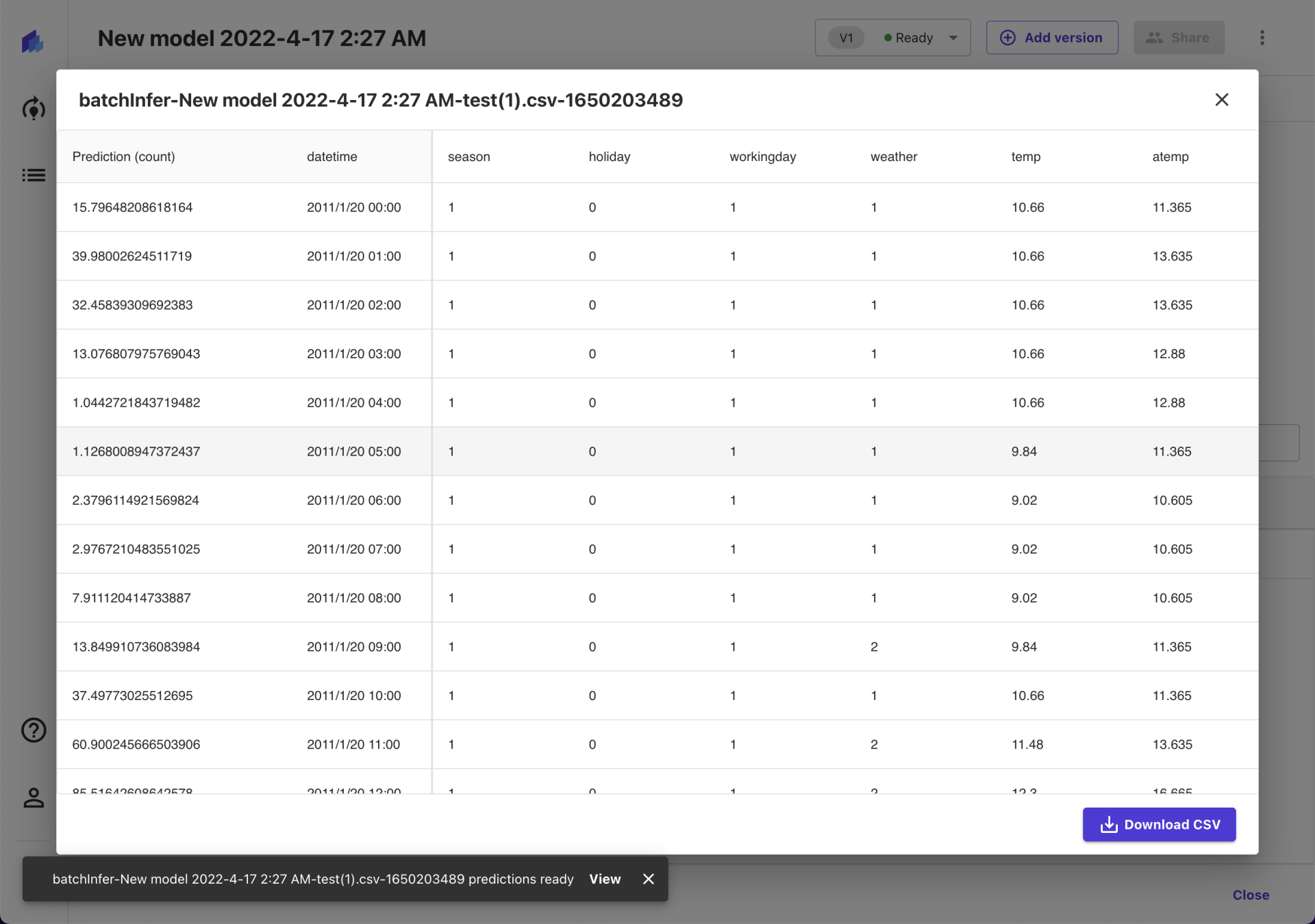
至此,一个基本的机器学习模型的全过程就结束了。其实,在页面的最上方,模型名称的右边,还提供了对于模型的版本管理和分享等功能。我们可以不断搜集新数据对模型进行训练,并通过版本保留之前训练的模型。
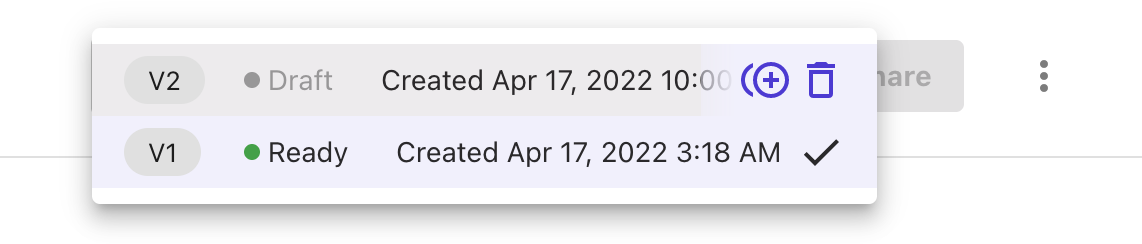
三、总结
1. 上手门槛
从整体看使用难度并不高,Canvas 确实做到了“无代码”。所有的数据、训练和预测工作可以通过交互界面完成。当然,前提是你需要了解机器学习建模的基本步骤和含义。
不过,在前面的评测中也提到了,作为一款公有云上的 SaaS 产品,对公有云上的存储、计算、权限管控等相关子系统、子产品也是有依赖的。这意味着,在必要的时候,你需要了解并使用其他子系统、子产品,才能完成一个使用流程。我们在评测开头区分了“新手模式”和“上帝模型”。下面我就列举一下在整个评测过程中,分别涉及到哪些环节:
- 【新手模式】账号注册;
- 【新手模式】绑定支付方式;
- 【上帝模式】初始化 SageMaker ,创建必要的用户、角色;
- 【上帝模式】如果处在没有提供 Canvas 的区,需要手动切区;
- 【上帝模式】通过 Amazon S3 上传需要的数据到某个 Bucket ;也可以选择通过链接参数连接到 Snowflake 或者 Redshift ;
- 【新手模式】选择已经上传的数据集;
- 【新手模式】选择要预测的数据字段;
- 【新手模式】切换模型类型,或者预览模型的效果;
- 【新手模式】启动模型训练,等待训练完成;
- 【新手模式】查看训练结果;
- 【新手模式】进行模型预测。
从比例上看,也印证了整体使用难度不高的结论。希望亚马逊云科技能在与 S3 等系统的联动方面进一步降低使用难度,这样对非技术背景的产品、运营朋友们可能更容易上手使用。
2. 功能建议
作为一款主打“无代码”建模的机器学习平台, Canvas 确实覆盖了一个机器学习模型从数据到应用的全主干流程。但也不可否认,Canvas 中的每个环节其实可以做得更“宽”一些,通过默认值的方式兼顾纯粹的新手用户和稍微有一点“探索精神”的入门级用户。
就比如,上传到 S3 的数据文件由于遇到了字段不一致的小插曲,需要进行修改。但是我却没有找到能在线上直接处理数据集的地方。不管是修改数据集文件,还是在模型训练的时候指定数据集中的字段,这两个功能都没找到。如果确实还没有加的话,我建议 Canvas 考虑下加上这个功能。
如果你觉得它相比 Jupyter Notebook 这种平台功能不够丰富强大,确实,不过可以看出这两个平台本来的定位就是面向不同人群的。
我觉得 Canvas 在尝试做的,是向“非算法专业”的用户屏蔽底层的复杂性,只把真正需要“人”来决定的事情暴露出来。
当然这种尝试在专业用户眼中可能是“不完美”的,甚至是“漏洞百出”的。从我自身的工作经历中也能体会到,当我们想把几行代码就能搞定的事情变成交互功能提供给不懂代码的人时,可能反而把简单的事情复杂化了。但也正是这种不完美的现状,给我们继续去探索问题本质和了解用户诉求增添了一份动力。
作者:李阳
本文由 @御豪同学 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!

