
 起点课堂会员权益
起点课堂会员权益OCR在资产管理系统的应用
OCR是通过算法识别出图像中的文字内容,算是图像识别的一个分支。那为什么固定资产管理系统中会用到 OCR 呢?

一、从业务说起:为什么需要 OCR?
为什么固定资产管理系统中会用到 OCR 呢?就得从梳理需求时遇到的问题说起。
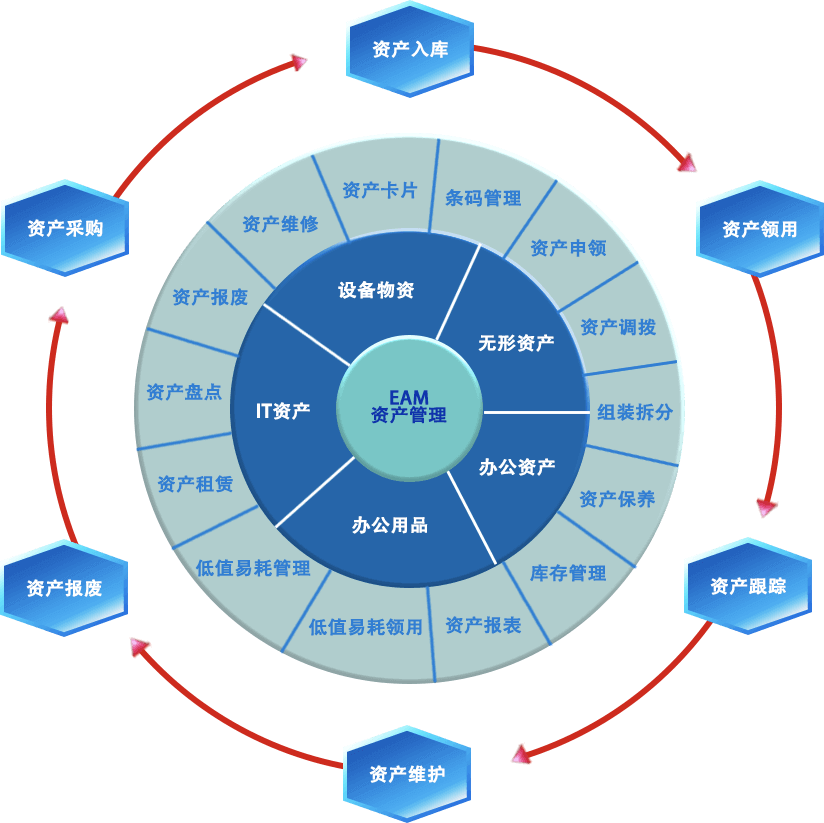
固定资产的全生命周期管理的第一步是“资产入库”,而入库是一个非常繁琐的过程,需要将大量信息录入系统。通过前期调研发现录入过程费时费力,还经常出现录入错误的问题(比如设备型号、序列码是较长的数字、字母序列,人工录入很容易出错)。
有没有办法解决这个痛点呢?受证件识别的启发,我们想到了 OCR 辅助人工录入,那么接下来就是调研这种方案的可行性了。
二、关于 OCR
OCR,也就是 optical character recognation(光学字符识别),是通过算法识别出图像中的文字内容,算是图像识别的一个分支。OCR 对纯文本的识别已经比较成熟,识别率普遍可以达到 90%以上,百度、阿里、腾讯等各大厂都有相应的服务可以直接调用。
1. OCR 分类
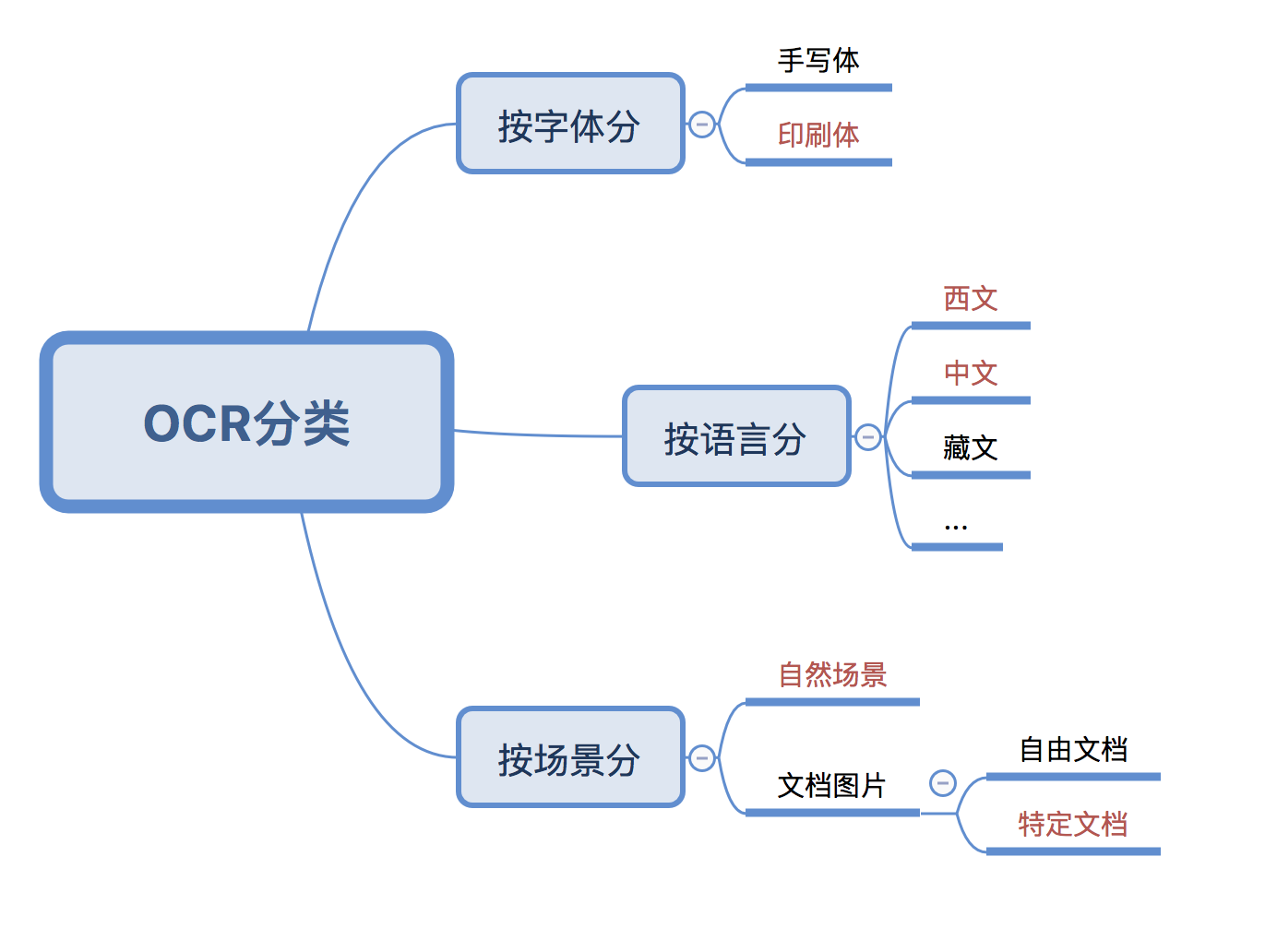
OCR 技术可以按字体类别、识别语言、识别场景进行细分,每个细分的算法有所不同,现在暂时还没有非常通用的算法同时适用于多个分类。
其中:
- 印刷体识别成熟度要高于手写体(原因也比较好理解,印刷体比较规范,手写体五花八门有时候人都难以辨认)。
- 中文和西文的识别成熟度高于小语种,中英文混合识别也能比较好的解决。
- 自然环境中的文字识别难度也要大于文档图片识别,因为自然环境中文字所处环境要更加复杂,文字检测难度要大于文档图片。
- 对特定格式文档(如身份证、发票、成绩单)的识别要好于自由文档(文字、表格、图片、公式混排)。
调研到这里,我们可以发现:OCR 辅助资产入库的需求,属于上述分类里的【自然环境】下的【中英文混合】【印刷体】识别。目前文字识别印刷体识别已经比较成熟,但自然环境下的拍照可能会给识别带来一些难度,初步判断 OCR 辅助人工进行资产入库信息录入是可行的。
2. OCR 算法理解
既然 OCR 是图像识别的一种,那么处理的流程就和大多数图像识别算法是一致的,即预处理-图像检测-图像识别。以自然环境下的文字识别为例,OCR 算法的工作流程大概是这样的:

预处理:文本经过扫描或拍照后会发生形变等问题,会对识别造成干扰,预处理就是通过灰度化、二值化,倾斜校正等方式消除这种干扰,以提高识别准确率。其中倾斜矫正的常见算法有投影法、hough 法等。
文字检测:目的在于找出文字的区域,是文字识别的基础。简单背景(e.g.扫描、截屏)和复杂背景(e.g.广告牌、说明书)下的文字检测方法差异较大,实现算法可以分为传统 CV 算法和 DL 算法两大类。
- 形态学方法:通过膨胀腐蚀等操作找到文字区域,只适用于简单背景。
- MSER:常用的传统文字检测算法,检测速度快,在简单背景和部分复杂背景中适用。但背景特别复杂时,检测效果可能较差。
- CTPN:是 CNN 和 RNN 相结合的算法,适用于简单和复杂背景的文字检测,但文字倾斜时的检测效果较差。
- SegLink:可以用于检测倾斜文字(但文字间隔不能太大)。
- EAST:端到端文本检测方法,也可用于检测倾斜文字,检测的准确性和速度都不错。
文字识别:文字识别又根据文字的长度分为定长(e.g.验证码)和不定长。不定长文字识别现在主要是通过 DL 算法实现,目前两大主流技术是 CRNN OCR 和 attention OCR。由于文字识别的特殊性,虽然其表现形式是图像,但本质是序列化的文本。所以不论是CRNN还是attention,思路其实都是用CNN提取特征,然后用RNN处理序列化,充分运用了文本图像的所有信息。
通过对 OCR 工作流程以及主流算法的了解,我们能对后续技术实现有个大概的认识,和 RD battle 时候也更加有底了。
三、功能设计
1. 核心场景
最近公司采购了一批新的办公电脑,资产管理部门的小方来到仓库打算对这批电脑进行入库登记,他拿出手机打开 app,对着每台电脑上的标签进行拍照,标签上的信息就被识别出来填入相应的输入框,很快小方就完成了入库登记的工作。
2. 业务流程
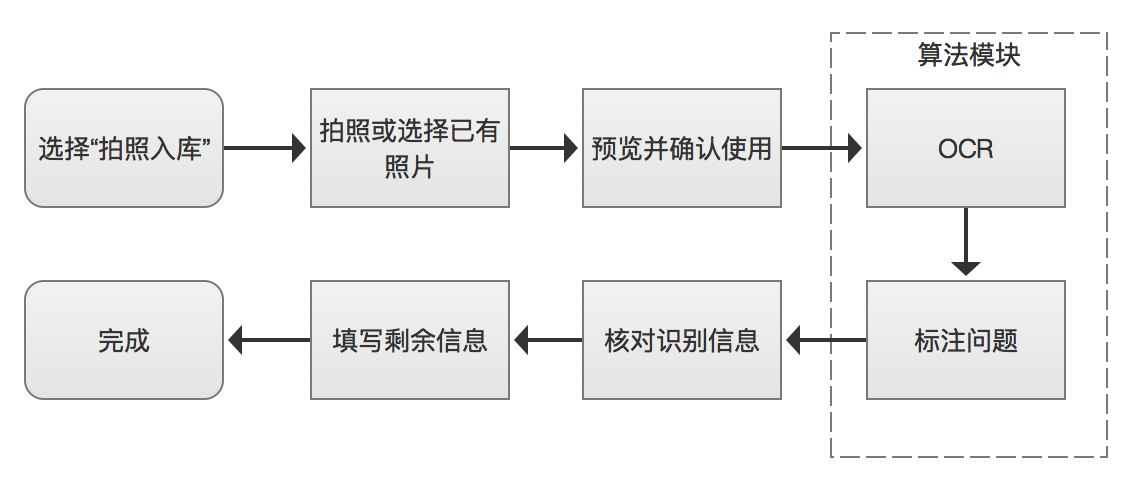
对用户来说 OCR 识别的过程是无感的,操作上只是用拍照代替了手工填写某些字段的步骤。
3. OCR 实现中的几点考虑
1)输入和输出

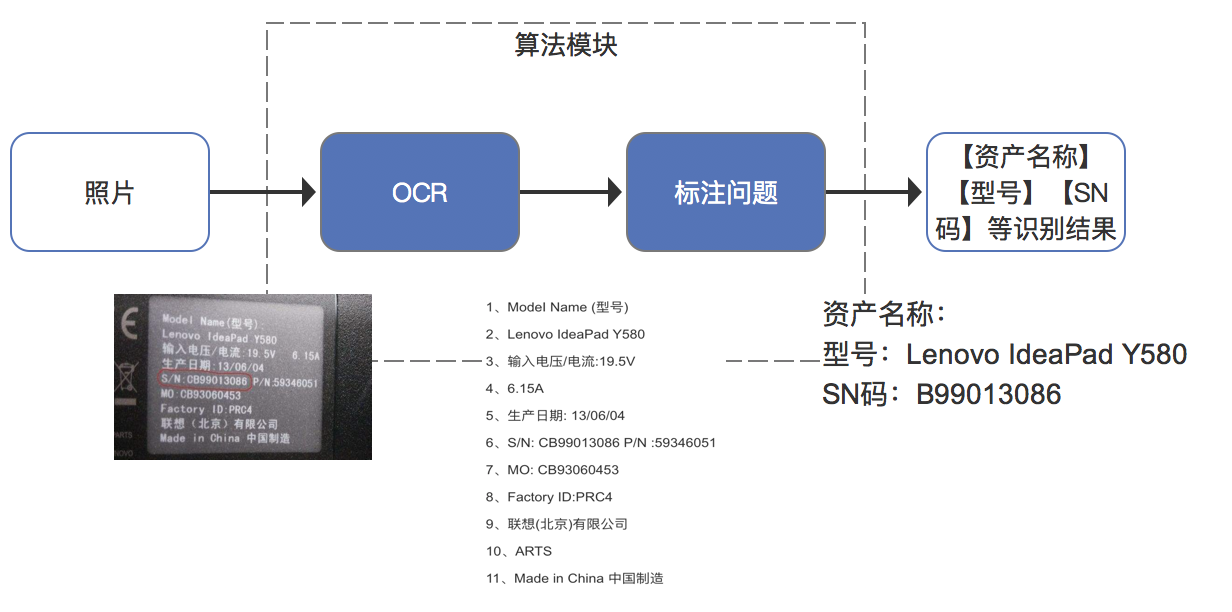
在本需求中,OCR 算法的输入就是用户拍摄的照片,然后需要把算法的识别结果填写到资产登记表单中相应的输入框中,所以需要确定 :a)识别哪些字段;b)每个字段识别出的结果。
a)识别哪些字段:综合考虑了常见的资产标签类型,结合最开始我们遇到的问题“字母数字序列输入容易出错且效率低”,确定了【资产名称】【型号】【SN码】三个需要识别的字段,也就是 OCR 处理完的结果只是中间结果,后边还需要做一个类似标注问题的处理(标注问题的处理方法暂不在这里展开)。
b)文字识别的结果反映到页面上就是把识别出来的字段填到相应的文本框中,所以需要算法部分输出的结果是“型号:Lenovo IdeaPad Y580”这样的 k-v 形式。
细化一下可以得到下图:
2)服务端 or 客户端
模型直接放在客户端的好处是可以离线使用,缺点也十分明显:一是识别准确率会受影响;二是安装包会变大;三是算法迭代必须等软件整体更新。所以除非是特殊的离线要求,还是把识别放在服务端好一点。
3)技术选型
实现途径无非两种:自研或者调用第三方服务。
自研的话,也不太可能从轮子造起,一般是在成熟的开源项目(如 chinese-ocr)或者是团队已有的算法基础上优化,最后得到的模型在特定场景的准确度肯定会比通用服务好。
自研算法主要包括两方面的工作:一是数据集获取、标注;二是模型优化,时间和人力成本都较高。但出于团队发展、算法积累以及后续可能需要私有化部署的考虑,我们最后还是选择了自研的形式。
为了给自研提供支撑和帮助,我对第三方服务也做了一些调研,如果有小伙伴恰好有类似的需求也可以参考。百度、阿里、腾讯三个开发平台都没有针对我们这种需求的特定解决方案,所以只能使用通用 OCR 模型。
以同一张标签图片为例(实际中试验了不同分辨率、不同品牌的资产标签),三个平台通用 OCR 识别结果如下:
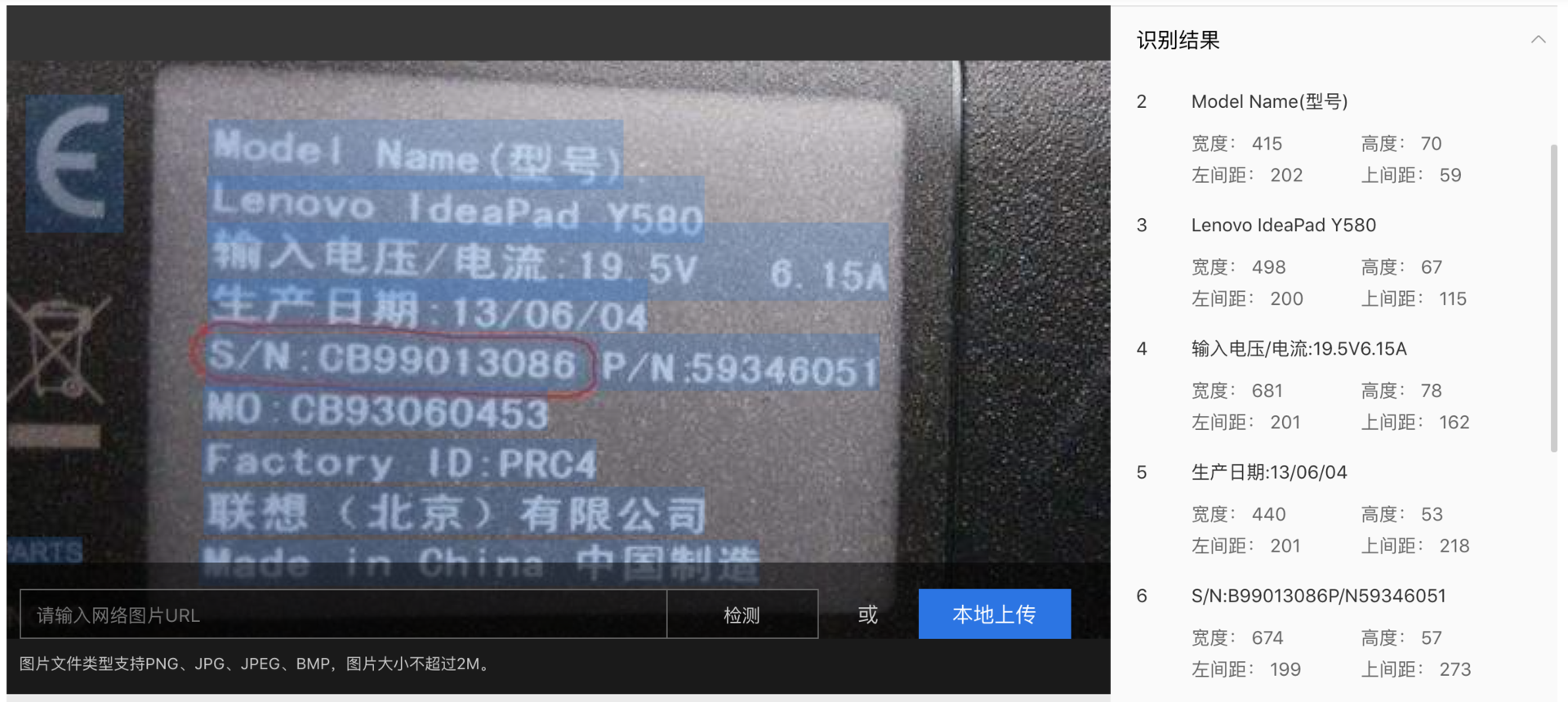
(百度AI开发平台)

(阿里云)

(腾讯AI开放平台)
可见通用 OCR 模型已经能比较好的识别出资产标签信息,所以调用第三方服务的方案也是可行的。
4)性能需求
- 由于用户需要即时获得识别结果,正常网络环境下,处理单张图片请求到返回结果应该在2s以内;
- 由于后续流程中有人工确认、更正信息的步骤,所以在平衡精度和召回率时,可以适当地提高召回率。
4. 优化思路:批量处理
个人认为批量操作是 2B 业务的一个核心思想。设备特别多的情况下每个设备拍照-录入这种流程也会比较慢,而且一批设备很大概率上是同一品牌型号的,所以批量录入的需求是存在且可以实现的(比如输入相同信息,然后批量识别 SN 码)。
实现批量录入的需求,一方面前端业务流程需要调整,另一方面 OCR 算法为适应批量识别在速度上也需要提升。这也是这个功能点后续优化的方向~
参考资料
本文由 @LCC 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。









企业直营的仓库、门店的商品出入库管理有没有类似的案例讲解呢
请求转载
请问哪里能较完整的了解资产管理系统呢 😉
我有 哈哈
求分享_(:з」∠)_
求大佬分享
求分享
求分享
大佬,可以分享下么
可以分享嘛
有道理 楼主可以分享一些市场上目前成熟的OCR开源或者第三方服务吗?
开源项目Chinese OCR,开源引擎tesseract