
 起点课堂会员权益
起点课堂会员权益
机器学习时代的体验设计(上):对创造人类行为学习系统的设计师和数据学家的启示
 B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
许多数字服务的设计不仅依赖于数据操作和信息设计,还依赖于用户学习系统。
一般来讲,数字服务的体验遵循预定义的用户旅程,具有明确的状态和动作。一直以来,设计师的工作一直是创建线性工作流,并将其转化为可以理解和不引人注目的体验。但是这种情况可能会成为过去时。
过去6个月,我一直在BBVA Data&Analytics(D&A)任职一个相当独特的职位,这是一家卓越的财务数据分析中心。我的工作是利用新兴的机器学习技术,使用户体验设计得到提升平。
除此之外,我的职责是为数据科学团队带来整体的体验设计,并使其成为算法解决方案的生命周期(例如预测模型、推荐系统)的重要组成部分。同时,我会对设计团队的体验设计进行创造性和战略性的优化(例如网上银行、网上购物、智能决策),引导它们发展演变为“人工智能”的未来。
事实上,我通过促进设计师和数据科学团队之间的交流合作,来达到设计出由数据和算法驱动的理想的和可行的用户体验的目的。
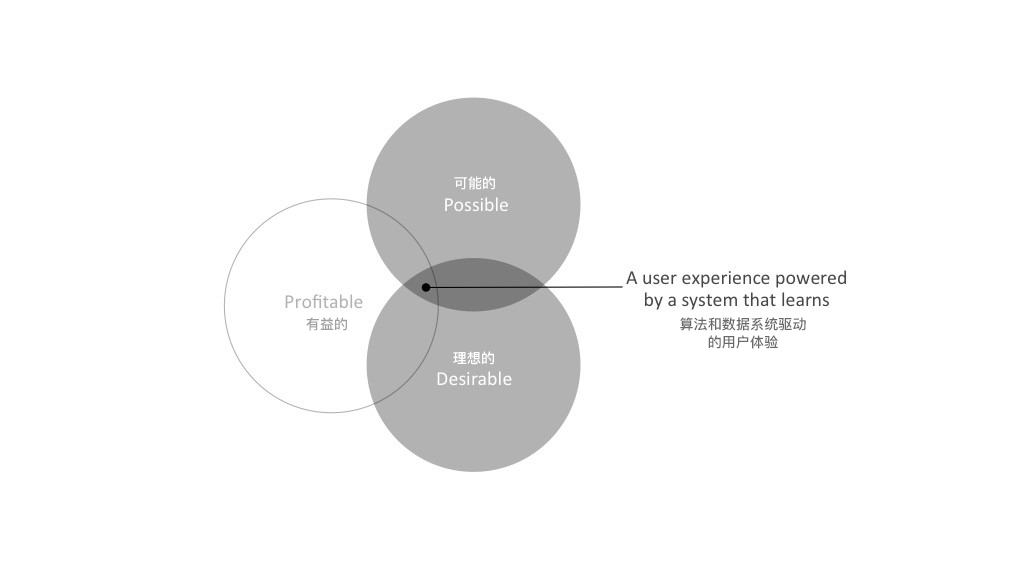
我们定义了一种不同的体验设计,即人类行为学习系统用户体验。这是一个新的尝试,因为:
- 它创造了新的用户体验类型。
- 它重新定义了人与机器之间的关系。
- 它要求设计师和数据科学家之间紧密合作。
接下来将会具体阐述这些内容的含义。
新型用户体验
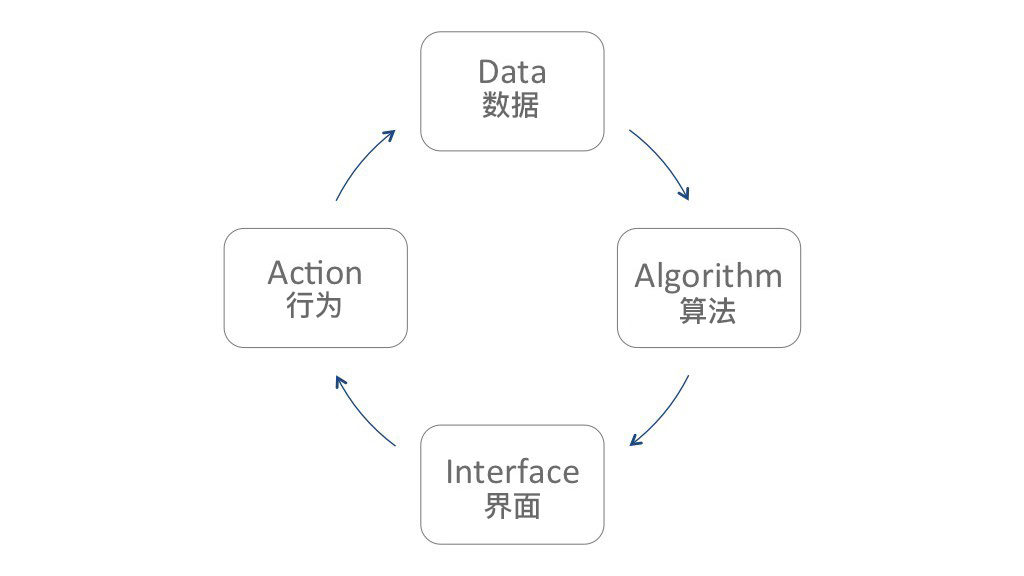
如今,许多数字服务的设计不仅依赖于数据操作和信息设计,还依赖于用户学习系统。如果深入剖析这些系统,我们会发现行为数据(例如人的交互,系统交互)被作为内容提供给生成知识的算法。传播知识的界面则使得体验更加丰富。理想情况下,这种体验会寻求明确的用户操作或后台关键事件数据来创建一个反馈循环,该循环将为算法提供学习材料。
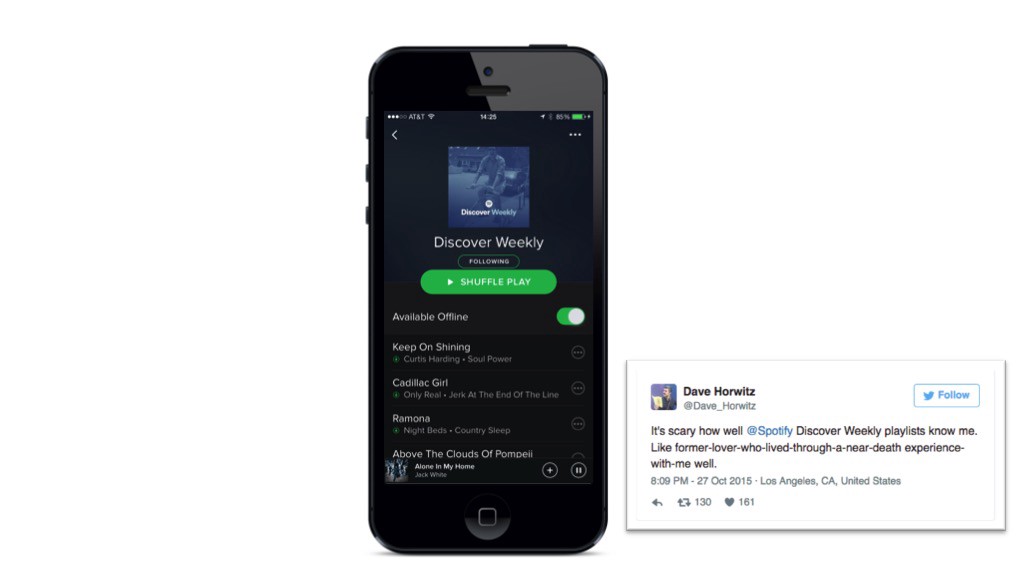
举个实际的例子。你知道Spotify “发现每周”是如何工作的吗?
“发现每周”是Spotify的自动音乐推荐“数据引擎”,每星期专门为每个Spotify用户量身定制两小时的定制音乐推荐。
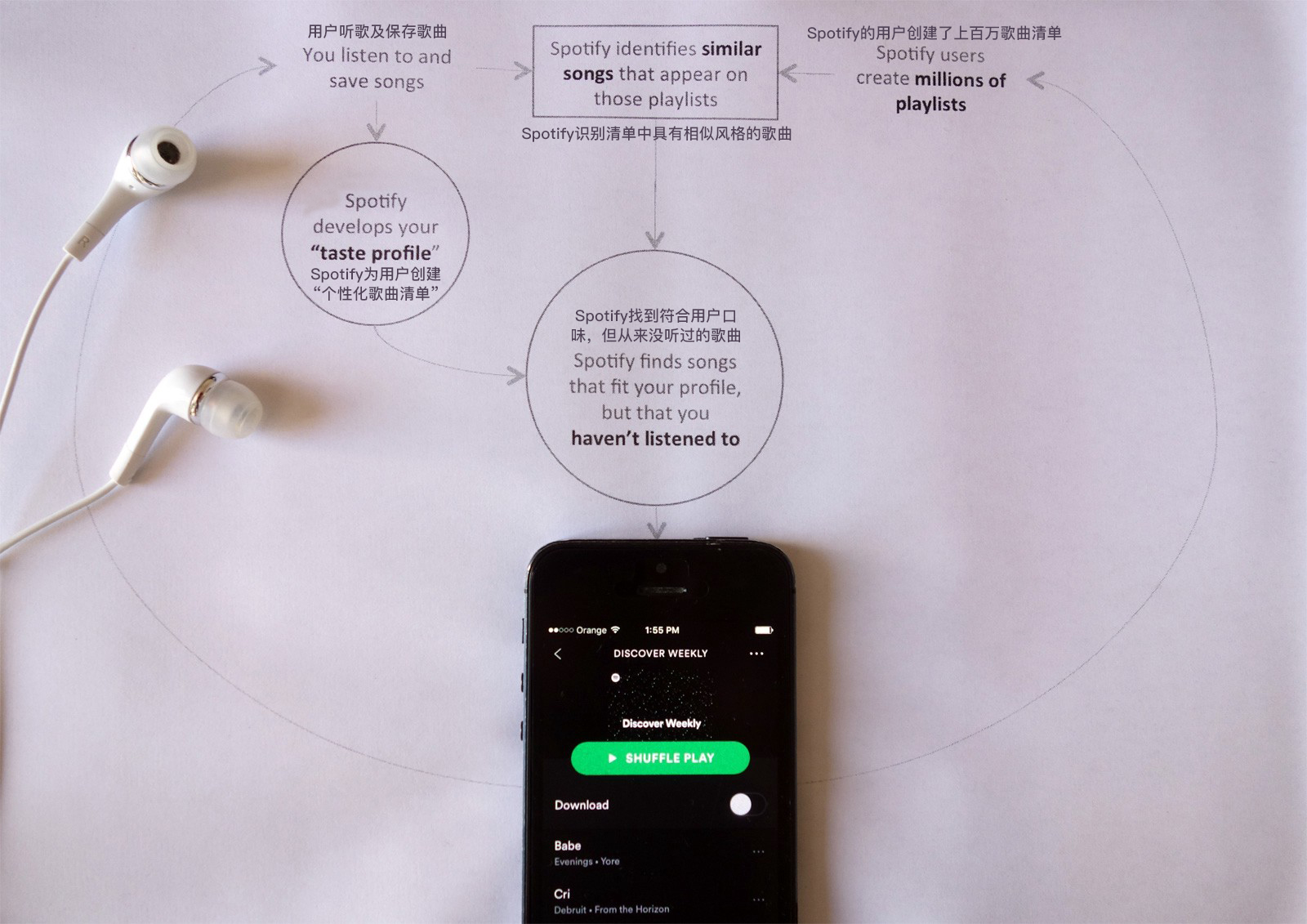
架构改编使得Spotify的“发现每周”的播放列表具有强大吸引力
“发现每周”的推荐系统利用Spotify用户创建的数百万个播放列表,为公司的专业播放列表和那些拥有广大粉丝群的播放列表带来额外的权重。该算法试图强化那些具有相似品味的用户的听歌习惯。它有三个主要任务:
- 一方面,Spotify为每个用户创建了个性化音乐品味的简介,将其划分为艺术家和少数流派;
- 另一方面,Spotify使用上亿级的播放列表,根据播放列表中歌曲的风格特点,去建立具有相似音乐风格的播放列表
- 每周它都会根据每个用户的个人口味去创建推荐列表。基本上,如果一首最喜欢的歌曲与一首未曾听过的歌曲一起出现在播放列表中,那么它就会推荐那首新歌。
一般来说,“发现周刊”播放列表会推荐30首歌曲,这个歌曲列表的内容已经足够多了,可以较好地去发现与个人品味相匹配的音乐。这样做的好处是可以生成数千个新的播放列表,这些新的播放列表在一周后会反馈到算法中以产生新的推荐。
这种反馈循环机制通常可以使现有的体验实现个性化、优化或自动化的目的。同时,它们还会根据建议、预测或情景来创造机会去设计新的体验。在D&A,我首次提出了一套不太全面的设计方法。
以下是其具体步骤:
为探索而设计
如你所见,推荐系统可以帮助发现已知的未知甚至未知的未知。例如,Spotify通过对用户听音乐的行为与数十万其他用户的听音乐行为之间的匹配来定义个性化体验,从而帮助发现音乐。这种体验至少面临三个主要的设计挑战。
首先,推荐系统倾向于创建一个“过滤器”,将建议(如产品、餐厅、新闻项目、人员连接)限制在一个与过往行为紧密联系的世界。为了避免这种问题,数据学家有时必须调整一些不太准确的算法,并增加一些随机性的建议。
其次,让用户可以自主选择推荐的各个部分也是一个很好的设计实践。例如,亚马逊允许用户删除可能对建议产生不利影响的项目。想象一下,顾客为他人购买礼物,这些礼物不一定是未来个性化推荐的数据参考。
最后,像Spotify这样,依靠主观推荐的系统可以使用户对被推荐的内容拥有更多的主观性和多样性的选择。这种人为清理数据集或减小机器学习算法局限性的方法通常被称为“人类计算”或“交互式机器学习”或“相关反馈”。
为决策而设计
数据和算法也提供了个性化决策的手段。例如在D&A,我们开发了一套优秀的算法为BBVA客户提供财务建议。
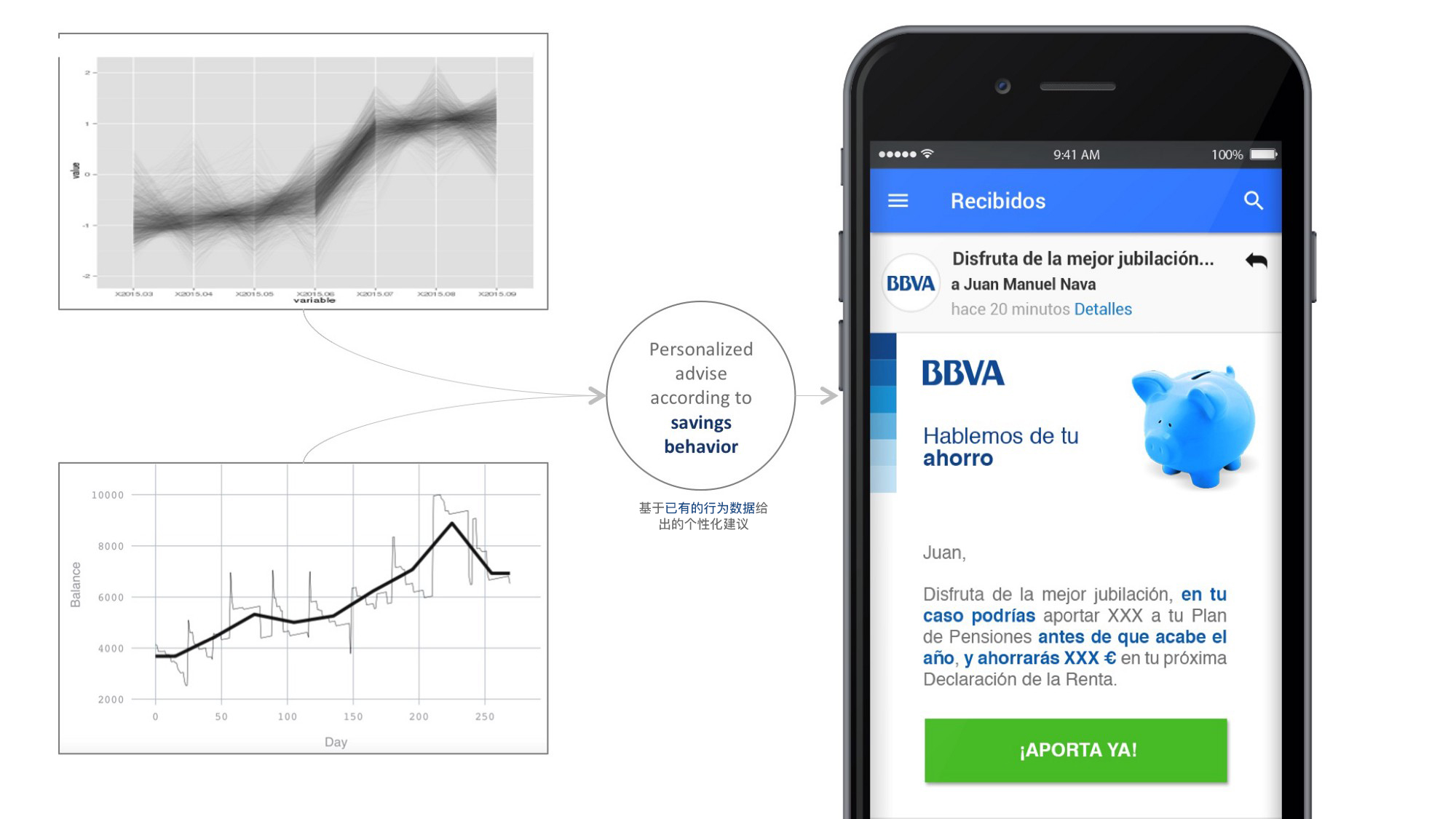
例如,我们根据账户余额的时间演变来划分储蓄行为。通过这种技术,我们可以根据每个客户节省资金的能力来设计个性化投资机会。
这种决策性的算法对准确度有更高的要求,因为它们往往依赖于只能提供真实情况的数据集。在财务咨询的案例中,客户可以在不同银行操作多个账户,从而避免对储蓄行为的泄漏。目前来看这是一个比较好的设计实践,因为它可以让用户隐晦或明确地提供不良信息。数据学家的责任是明确反馈类型,从而丰富他们的模型,而设计师的工作是找到构成体验组成部分的方法。
为不确定性而设计
传统上讲,计算机程序的设计遵循的是二进制的逻辑,即通过将具有明确的、有限集合的、具体的和可预测的状态转换成工作流程来实现 。机器学习算法使用一种模糊逻辑来改变这种情况。它们的目的是寻找一组大概率接近样本行为规则的模式(参见Patrick Hebron的《为设计者的机器学习》一文中关于此定义的更加具体的介绍)。这种方法包含一定程度的不精确和不可预知的行为。它们经常会反馈一些关于已有信息精确度的提示。

例如,预订平台Kayak通过分析历史价格变化来预测价格的演变。它的“预测”算法旨在让用户对是否在一个合适的时间购买一张票产生信心(参见Neal Lathia 《在票价背后的机器学习》)。数据学家自然倾向于给出算法预测值的精确度:“我们预测这个票价是x”。这个“预测”实际上是一个基于历史趋势的结果呈现。然而,预测与告知并不相同,设计师必须考虑这样的预测能够支撑用户的行为:“买!这个票价可能会增加”。“可能”与“价格走势的预测”是用户体验中的“完美衔接”,这个概念是由 Mark Weiser在施乐帕洛阿尔托研究中心工作期间首次提出,然后由 Chalmers and MacColl进一步将其发展为一个新的概念——seamful design(有缝设计):
“Seamful design故意向用户展示“接缝”,并利用通常被认为是消极或有问题的特征”。
Seamful design 利用失败和局限来改善体验。它通过收集用户对于不良设计细节的建议来改善系统。DJ Patil描述了Data Jujitsu中的巧妙设计。
其他类型的机器学习算法运用精确度和召回率来处理接缝。
- 精确度评分体现了提供完全符合需求的结果的能力。(精确度指的是算法推送的内容与用户喜好的匹配程度)
- 召回率评分体现了提供大量可能的好建议的能力。(召回率指的是算法推送的内容与用户喜好匹配的内容的占比)
算法的理想之处在于提供高精确度和高召回率。不幸的是,精确度和召回率往往相互矛盾。在许多数据分析系统中,设计决策经常需要在精度与召回率之间进行折中选择。例如,在Spotify 的发现周刊中,必须根据推荐系统的性能来决定播放列表的大小。提供30首歌曲推荐的大播放列表可以凸显Spotify的信心,足够多的推荐歌曲增加了用户获取完美推荐的几率。
为参与而设计
今天,我们在网上阅读信息是基于自身行为和其他用户的行为产生的。算法通常会评估社交和新闻内容的相关性。这些算法的目的是通过推送内容获取更高的参与度或通过发送通知来建立用户阅读习惯。显然这些为我们所采取的行动并不一定是从我们自身利益出发。

在注意力经济中,设计师和数据学家都应该从用户的焦虑、强迫、恐惧、压力和其他精神负担中学习。资料来源:《地球村及其不适》。照片来源:Nicolas Nova
可以说,我们进入了注意力经济时代,主要的在线服务正在努力吸引人们,尽可能长时间吸引他们的注意力。他们的业务是让用户在其平台上尽可能长时间的频繁操作。但是这也带来了差的体验,这些体验经常伴随着诸如惧怕错过信息(FoMO)或其他困扰情绪,以此来麻痹用户的参与。
注意力经济的“演员”也使用麻痹用户的方法,例如根据使用时长给予奖励。这与老虎机中使用的机制完全相同。由此产生的体验会促使服务(赌场)吸引用户不断地寻找下一个奖励。我们的手机已经成为通知、警告、消息、转发、喜欢的“老虎机”,有些用户每天平均检查150次,或者更多。今天,设计师可以使用数据和算法来挖掘人们日常生活中的认知漏洞。这种新的能力对机器学习时代的设计原则提出了新要求(参见Aaron Weyenberg 的《优良设计的道德规范:连接时代的伦理原则)。
然而,用机器学习算法设计的体验并不一定会成为一种“赌场”体验。
为时间高效利用而设计
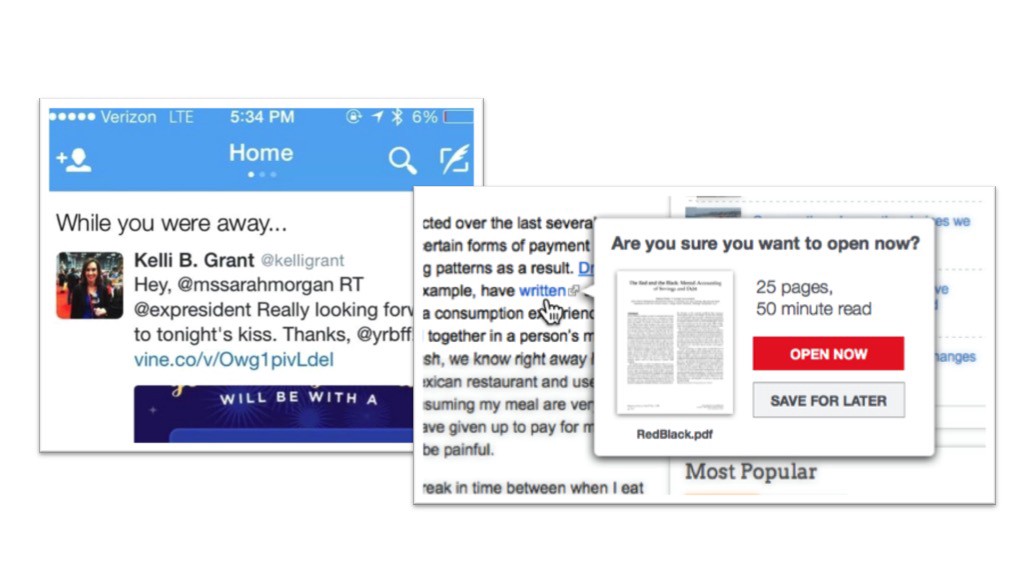
设计一个与众不同的而不是约定俗成的体验有很多方式。事实上,像银行这样的组织有一定的优势:它是一个以数据为基础的行业,且不需要客户花费大量的时间在他们的服务上。Tristan Harris的“时间高效利用运动”在这个层面上具有重要意义。他提倡使用数据紧密相关或完全不相关的体验类型。这种技术可以保护用户注意力和尊重人们的时间。twitter的“当你离开时……”是这种做法的一个很有说服力的案例。其它服务则善于提示与其互动的时间。这种体验不是关注用户留存量,而是关注交互的相关程度。
为内心平和而设计
数据学家擅长检测正常行为和异常情况。在D&A,我们正在努力促进BBVA客户内心平和,这种机制在情况良好的情况下能够提供一种通用意识,并触发更多关于异常情况的详细反馈。
我们认为目前这一代机器学习给社会带来了新的力量,同时也增加了创造者的责任。算法存在偏差并且可能是数据源固有的特征。因此,尤其需要注意使算法对于人们来说更清楚易懂,并且监管者可以对其进行审查,以了解其影响。实际上,这意味着算法产生的内容应该保护用户的兴趣,并且应该解释其评估的结果和使用的标准。
体验设计其他相关的方面如下:
- 为公平而设计
- 为沟通而设计
- 为自动化而设计
可能还有更多方面的内容,期待更多人去发掘。
原文链接:https://medium.com/@girardin/experience-design-in-the-machine-learning-era-e16c87f4f2e2
本文由@百度UXC翻译发布于人人都是产品经理,未经许可,禁止转载。
题图来自PEXELS,基于CC0协议

















系统而深刻