
 起点课堂会员权益
起点课堂会员权益抢占AI翻译赛道,搜索平台为何不约而同发力NMT?

不论是国外的谷歌,还是国内的搜索巨头百度、搜狗、360等,均把NMT作为AI翻译的标配,翻译集中的领域在中英互译上,这是一个很有趣的现象。AI翻译真的是块肥肉吗?为什么要发力NMT?
搜索公司在AI翻译这个事上扎堆并不令人意外。
2016年,GNMT技术(谷歌的神经网络机器翻译技术,模仿人脑的神经思考模式)全面布局于谷歌翻译系统中,随后,谷歌声称其AI翻译的译文质量误差降低了55%-85%,并且将此技术广泛应用于网页翻译与手机应用。
国内,百度当时已经研究出了可应用的SMT技术(统计机器翻译),但得知NMT的横空出世之后,便迅速调转方向转而研发NMT技术,于是就有了BNMT应用于百度翻译。尽管初时的百度翻译速度很慢。但是,百度当时反应也佐证NMT的价值性。
搜狗、阿里、腾讯等公司也都有部署NMT领域,推出多款基于神经网络的在线翻译和手机应用,在智能翻译领域持续发力。360搜索也不愿落后,上线了基于NMT的360翻译,以期与去年上线的360英文搜索形成合力,且还拉来了微软旗下的搜索引擎Bing开展技术合作。
但是我们会发现:不论是谷歌还是BAT,其智能翻译从未能声称能替代人工翻译,因为翻译还必须考虑到到使用者的情感及文化背景。从2016年起至今的两年时间里,对海量语料的深度学习逐渐成为AI开发的必修课,也成了巨头们布局AI翻译绕不过的“坎”。
搜索平台不约而同发力NMT,为的是哪般?
前面说到,不论是国外的谷歌,还是国内的搜索巨头百度、搜狗、360等,均把NMT作为AI翻译的标配,翻译集中的领域在中英互译上,这是一个很有趣的现象。AI翻译真的是块肥肉吗?惹得谁也不愿意掉队。
据统计表明:全球一共有73个国家,超10亿人以英语为官方语言,而汉语则是世界使用人数最多的语言。因此,中英互译本身的用户基数市场就能引起巨头们足够的注意力了。
为什么要发力NMT?
这得从AI翻译人类语言的方式说起,包含三种:
- 第一,基于规则的机器翻译方法;
- 第二,基于实例的机器翻译方法;
- 第三,基于统计的翻译方法。
SMT与NMT都属于第三种,从语料自动学习翻译模型,结合大数据通过评分输出翻译结果。但是,SMT与NMT存在着显著的差距。
SMT采用的模式是通过平行语料进行统计分析,翻译的准确性则与语料的丰富度呈明显的正相关,但是存在着翻译结果太过零散,片面生硬,语法语义混乱的劣势。
而模仿人类神经网络构建模型,NMT是以一个句子为基本的处理单元,好处在于翻译过程中有着更好的语感,能降低SMT翻译的关于“形态、句法、词序”等方面出错的概率。
因此,NMT在技术上恰巧可以有效弥补SMT的缺陷。而随着语料不断地加码,AI翻译的准确度也就高得多。
AI翻译引进NMT技术,就能精准识别“语境”吗?
搜狗同传翻译在某次国际性会议上,声称其神经网络机器翻译技术已达临界点,并在进行大规模商用推广。只是,搜狗的同传还是在国际会议上出过争议,结果不尽如人意。
即便在正式的场合能够应对自如的搜狗,在非正式场合会是怎样一种情况呢?
很多时候的中英交流多以口语化形式出现,对“语境”的理解远比“语法和词汇”难得多。下文我们将就几组语句进行讨论,以下从搜狗、360搜索、百度以及谷歌四大平台进行对比。
第一组:献上我的膝盖。
看看,最近这句网络常用语各翻译平台的水平
- 谷歌:Offer my knee。
- 360:express my admiration。
- 百度:Offer my knees。
- 搜狗:Give me my knee。
测试结果是搜狗、百度、谷歌均倾向于单词表面意思的翻译,并未能结合具体的文化背景,360对于该网络用语的解释稍显老练。
第二组:诗词,选自杜甫的《登高》。
因其诗中主要是以诸多意象组成的意境,看翻译能否反馈这种情感。
《登高》原文摘选:风急天高猿啸哀,渚清沙白鸟飞回。
英语译文:

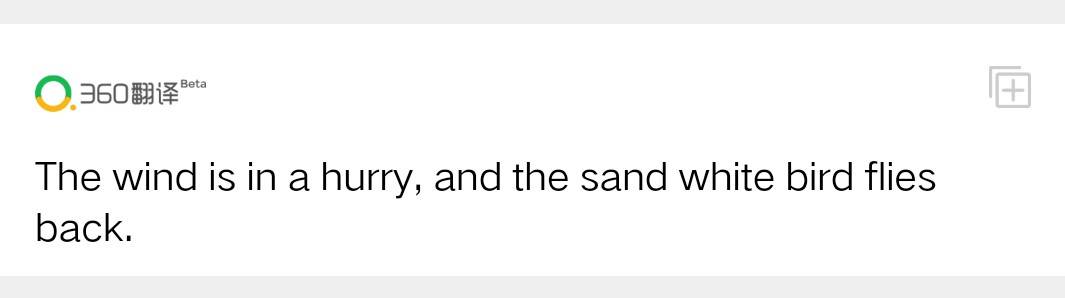
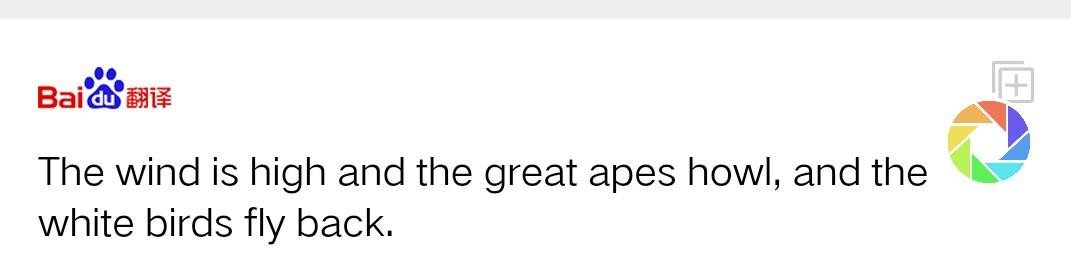

有趣的是将各自翻译的英文译成中文时,没有一个平台能还原。而在诗歌的中译英中360能够结合“语境”处理诗中的意向要素,搜狗翻译表达出了“悲怆”的情感,而百度翻译和谷歌翻译则完全是从字面上进行翻译,破坏了诗的美好。
第三组:新闻,选自红网。
语言简练正式,但涉及的元素较多,对语法的要求性比较高。
原文:据长沙市住房和城乡建设委员会网站显示,2018年5月23日,长沙共计有两个项目获批预售证,均位于雨花区,分别为五矿万境蓝山和创元时代。
译文:




同一段新闻,出现了四种不同的译法。同一语句中各家强调的点不一样,譬如:首句的“长沙市住房和城乡建设委员会”,360的翻译结果更显得专业并符合惯常表述。“长沙市”只是作为补充词出现,而搜狗、百度和谷歌的翻译中,“长沙市”则是作为硬性的地名出现。
尤为值得注意的是:根据语境,“五矿万境蓝山”和“创元时代”都是楼盘名字,应当由汉语拼音直译,只有360识别到这一点,搜狗、百度和谷歌三家都在“矿”、“蓝山”、“创元”、“时代”等字眼上纠结。
从这三组中,我们能发现360偏好于基于“语境”的逻辑进行分词,虽然也有做的不到位的,像针对诗词这样复杂的情感语句就无法准确传达,但是在“流行语”优势明显。
而谷歌和百度基本上是基于词组进行断句,因此,翻译也是一个词一个词,尤其是对古诗词的理解,谷歌就显得比较忧愁了。
因此,AI翻译的问题主要反映在三大方面:
- 第一,机器翻译难以应对语言规则不统一的口语;
- 第二,AI翻译难以结合文化语境进行理解,解析不出深层次的情感;
- 第三,针对较长的段落,以及较为复杂的语境,往往会出现语法问题多,语句出错率高的毛病。
AI翻译要“地道”,技术倒不是关键
翻译界老将何恩培曾讲:
“机器翻译一直被公认为人工智能领域最难的课题之一。而且语言背后的多元文化和复杂社会属性,注定了语言规则不可能规律化”。
但是,中国有句老话:勤能补拙。
对于AI翻译而言,最难的不是技术,而是“语境”理解,而AI翻译能力的级别高低又体现在这,集中体现了平台喂养语料的资源状况。AI翻译能否“地道”,取决于以下几点。
1. 训练数据库的内容整体优质程度
这影响到翻译准确程度,取决于信息资源的整合能力。不论是BAT,还是360、搜狗、有道等,都在注重内容生态建设,搜狗有了腾讯微信入口搜索,360抢占了安全领域的数据来源。
但是,这不可能是一个完全开放的体系,没有哪一家能够整合整个互联网的资源,各平台训练数据库各有侧重,AI翻译特色也不尽相同,例如:360翻译侧重于地道的口语与流行语,百度翻译则显得大而全。
2. 开放平等的中外数据交流,或可加强AI的深度学习
国内对标竞品之间的合作相对较难,但中外数据交流却是最好的互补。因此,百度上线过英文搜索产品,而360与微软Bing有过技术合作。
此外,有了国界互译也变得更有意义。因此,中外数据合作,或许对于文化背景的数据积淀有很好的补充,也是扩充深度学习的语料最直接的方式。
3. 需要准备大量的网络语及口语语料
除了诗词蕴含深厚文化底蕴外,网络语和口语是与一个地域的文化最为接近的语言形态,时下搜索引擎从被动搜索向主动的,基于用户兴趣的内容推荐引擎转型,这对于构建口语语料训练模型倒是一个不错的尝试。
总之,AI翻译能够精准识别“语境”是需要很长一段路要走!
【完】
#专栏作家#
曾响铃,微信公众号:科技向令说,人人都是产品经理专栏作家。TMT新媒体“铃声”创始人,《移动互联网+ 新常态下的商业机会》《趋势革命:重新定义未来四大商业机会》作者,《网红经济学》作者之一,《商界》等多家杂志撰稿人。重点关注SaaS、智能硬件、互联网金融、O2O、新媒体运营方向。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pixabay,基于 CC0 协议






- 目前还没评论,等你发挥!


