起点课堂会员权益
起点课堂会员权益AI产品经理需要了解的数据知识:余弦相似度

本文概括介绍了余弦相似度是什么、如何应用以及案例说明,目的是希望我们产品经理在设计相关跟相似度功能或是利用相似性功能解决某一业务的场景时能利用上余弦相似度,并希望您读完对自己在设计相关推荐业务、搜索业务、识别业务时能有更深层次的理解。
在机器学习算法中,有很多方法计算某个对象之间的距离或是相似性,余弦相似度是通过衡量两个向量间的夹角大小,通过夹角的余弦值表示结果,余弦相似度的取值为[-1,1],值越大表示越相似。
计算余弦值的公式如下:
![]()
注释:其中a和b代表两个向量(向量是在空间中具有大小和方向的量,在数据计量中表示带箭头的线段,相关向量知识可自行阅读相关文献)。
如果是在二维空间,余弦相似度的值通过如下公式计算:
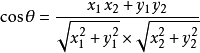
对于以上公式的理解,我们可以看如下两图(二维向量图和余弦定理)
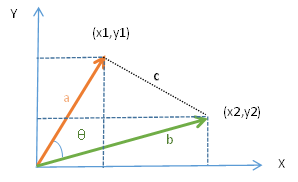
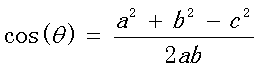
以上左图是将a\b两个向量二维化,右图是余弦定理,通过余弦定理与二维空间结合,即可推导出来二维空间下计算两个向量的余弦相似性公式。(有兴趣的同学可以看上面两个图,自行推导一下)
如果假设空间是多维的,那么余弦相似度公式可扩展如下公式:
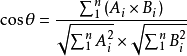
以上是对余弦相似度概括解释,以及公式演化形式,在下一节将会对以上公式的应用说明,请各位同学先好好理解以上公式。
一、余弦相似度应用说明
余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
案例一:文本相似度
比如有如下两个句子:
句子A:他不仅是一个歌手,还是一个舞者;
句子B:他既是一个歌手,也是一个舞者。
那么如何计算以上两个句子的相似度,首先我们要找到如何评价这两个句子,用什么方法将这两个句子向量化?我们最直观的看,连个句子用词相近,那句子整体相似度就高,因此我们从词频入手,来计算其相似性。
首先,进行分词处理:
句子A:他 不仅 是 一个 歌手 还 是 一个 舞者
句子B:他 既 是 一个 歌手 也 是 一个 舞者
其次,列出所有的词:
他 不仅 既 是 一个 歌手 还 也 舞者
第三步:计算词频
句子A: 他(1) 不仅(1) 既(0) 是(2) 一个(2) 歌手(1) 还(1) 也(0) 舞者(1)
句子B:他(1) 不仅(0) 既(1) 是(2) 一个(2) 歌手(1) 还(0) 也(1) 舞者(1)
第四步:
我们总结出来两个句子的词频向量:
句子A(1,1,0,2,2,1,1,0,1)
句子B(1,0,1,2,2,1,0,1,1)
这样问题就变成了如何计算这两个向量的相似程度。都是从原点([0, 0, …])出发,指向不同的方向的向量。
通过公式计算得出:
A和B的余弦相似度=
![]()
通过余弦相似度公式,我们计算出来这来两句话意思很相近。
我们通过这个案例不难发现,想要利用余弦相似性公式来计算两者之间的相似性,首先要确定向量化的方法(比如本案例中,通过将连个句子通过分词的方式,计算词频来向量化),理解向量值的多维度(我们通过分词可以得出来9各维度的向量值),然后将向量化后将值带入到公式中,去计算相似度。
通过以上案例我们可以联想其他案例,比如对于两篇文章,连个实体的相似性对比,我们可以通过向量化关键词、实体画像特征等进行向量化,然后通过这些特征向量化的维度值,进行计算相似性。
案例二:用户相似度
比如一个外卖平台,两个用户A和B,外卖新出了两款新品套餐,分别是a和b,用户A对这两款新品的评分是1分和2分,b对这两款新品的评分是4分和5分,我们通过余弦相似度来评价一下两个用户的相似度。
假如我们将对这新品套餐评分作为特征向量,两个产品的评分分别连个维度的向量值,是那么A和B的特征向量分别是(1,2)、(4、5),我们代入公式计算得出:0.98。
通过公式计算发现两个相似度很高,但是这跟我们直觉判断这两个应该相似度很低才是,这说明我们选定好评价的特征向量后,对于向量值的的确定出现了问题,我们对(1,2)、(4、5)进行转换,变成与平均分3的差额,的出来新的向量值(-2,-1)、(1、2)之后,重新计算得出相似度为-0.8,那么我们看这个结果比较接近事实。
通过这个案例我们可以看到:再找到特征向量后,对于向量值的取值与评价也需要灵活考虑,可以结合统计学知识。
二、总结
对于产品经理,尤其是对于AI产品经理,在理解和运用余弦相似性时需要考虑一下问题:
首先,余弦相似性是对两个对象之间的比较,将两个对象向量化,向量化的过程中,我们要找到两个对象比较的基础;也就是特征,真对与不同特征赋予向量值的意义,并且在选取向量值时,定量化的评分要符合逻辑,然后通过公式计算相似性。
其次,余弦相似性很难做到向量长度的归一化。
比如两篇文章,讲的同一个事情,一篇200字,一篇5000字。假如通过关键词相似可以判定两个文章是高度相似的,假如我们还是用内容分词通过词频的方式,那么有很大可能是不相似的,因为词量差距太大。因此我们选取的特征向量尽量少维度,但是又能全面评价二者的指标。
除此之外,关于相似性的判断,在机器学习中除了余弦相似性还有其他方法,比如欧氏距离、皮尔逊相关度、杰卡德(Jaccard)相似度等方法,有兴趣的小伙伴可以进一步了解。
本文由 @罗飞 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议






- 目前还没评论,等你发挥!