
 起点课堂会员权益
起点课堂会员权益万字解析:“AI芯片”通识
本文作者团员书博 ,从事过芯片、硬件、嵌入式等相关工作,最近希望成为“AI芯片”领域的产品经理,所以专门深度研究这个领域,输出了这篇文章。本文,是用产品经理能够看得懂的语言和角度,讲述AI芯片相关干货;可以说,对于AI芯片这个相对偏技术的领域来说,没有他这样的技术背景,即使input了很多文章报道,也很难有这种高质量的产出的。

目录
一、AI芯片概述
二、AI芯片的分类和市场划分(云端/终端,训练/推理)
三、AI芯片技术路线(GPU/FPGA/ASIC,现状/短期/长期方向)
四、AI芯片市场分析(四大场景:数据中心、自动驾驶、安防、手机终端)
五、AI芯片主要厂商介绍(国外,国内)
六、AI芯片展望
附:未来两种可能的通用AI芯片技术路线介绍(类脑芯片、可重构通用AI芯片)
一、AI芯片概述
1. AI芯片产生的背景
AI的三大关键基础要素是数据、算法和算力。随着云计算的广泛应用,特别是深度学习成为当前AI研究和运用的主流方式,AI对于算力的要求不断快速提升。
AI的许多数据处理涉及矩阵乘法和加法。AI算法,在图像识别等领域,常用的是CNN;语音识别、自然语言处理等领域,主要是RNN,这是两类有区别的算法。但是,他们本质上,都是矩阵或vector的乘法、加法,然后配合一些除法、指数等算法。
CPU可以拿来执行AI算法,但因为内部有大量其他逻辑,而这些逻辑对于目前的AI算法来说是完全用不上的,所以,自然造成CPU并不能达到最优的性价比。因此,具有海量并行计算能力、能够加速AI计算的AI芯片应运而生。
2. 什么是AI芯片
一般的说,AI芯片被称为AI加速器或计算卡,即专门用于加速AI应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。
而从广义范畴上讲,面向AI计算应用的芯片都可以称为AI芯片。除了以GPU、FPGA、ASIC为代表的AI加速芯片(基于传统芯片架构,对某类特定算法或者场景进行AI计算加速),还有比较前沿性的研究,例如:类脑芯片、可重构通用AI芯片等(但距离大规模商用还有较长距离)。
以GPU、FPGA、ASIC为代表的AI芯片,是目前可大规模商用的技术路线,是AI芯片的主战场,本文以下主要讨论的就是这类AI芯片。
二、AI芯片的分类和市场划分
1. 从两个维度对AI芯片进行分类
维度1:部署位置(云端、终端)
AI芯片部署的位置有两种:云端、终端。所以根据部署的位置不同,AI芯片可以分为:云AI芯片、端AI芯片。
- 云端,即数据中心,在深度学习的训练阶段需要极大的数据量和大运算量,单一处理器无法独立完成,因此训练环节只能在云端实现。
- 终端,即手机、安防摄像头、汽车、智能家居设备、各种IoT设备等执行边缘计算的智能设备。终端的数量庞大,而且需求差异较大。
云AI芯片的特点是性能强大、能够同时支持大量运算、并且能够灵活地支持图片、语音、视频等不同AI应用。基于云AI芯片的技术,能够让各种智能设备和云端服务器进行快速的连接,并且连接能够保持最大的稳定。
端AI芯片的特点是体积小、耗电少,而且性能不需要特别强大,通常只需要支持一两种AI能力。
相比于云AI芯片来说,端AI芯片是需要嵌入进设备内部的,当在设备内部中嵌入了端AI芯片之后,能够让设备的AI能力进一步提升,并且让设备在没有联网的情况之下也能够使用相应的AI能力,这样AI的覆盖变得更为全面。
维度2:承担任务(训练、推理)
AI的实现包括两个环节:训练、推理。所以根据承担任务的不同,AI芯片可以分为:用于构建神经网络模型的训练芯片,利用神经网络模型进行推理预测的推理芯片。
- 训练,是指通过大数据训练出一个复杂的神经网络模型,即用大量标记过的数据来“训练”相应的系统,使之可以适应特定的功能。训练需要极高的计算性能,需要较高的精度,需要能处理海量的数据,需要有一定的通用性,以便完成各种各样的学习任务。
- 推理,是指利用训练好的模型,使用新数据推理出各种结论。即借助现有神经网络模型进行运算, 利用新的输入数据来一次性获得正确结论的过程。也有叫做预测或推断。
训练芯片,注重绝对的计算能力,而推断芯片更注重综合指标, 单位能耗算力、时延、成本等都要考虑。
训练将在很长一段时间里集中在云端,推理的完成目前也主要集中在云端,但随着越来越多厂商的努力,很多的应用将逐渐转移到终端。
推理相对来说对性能的要求并不高,对精度要求也要更低,在特定的场景下,对通用性要求也低,能完成特定任务即可,但因为推理的结果直接提供给终端用户,所以更关注用户体验方面的优化。
2. AI芯片市场划分
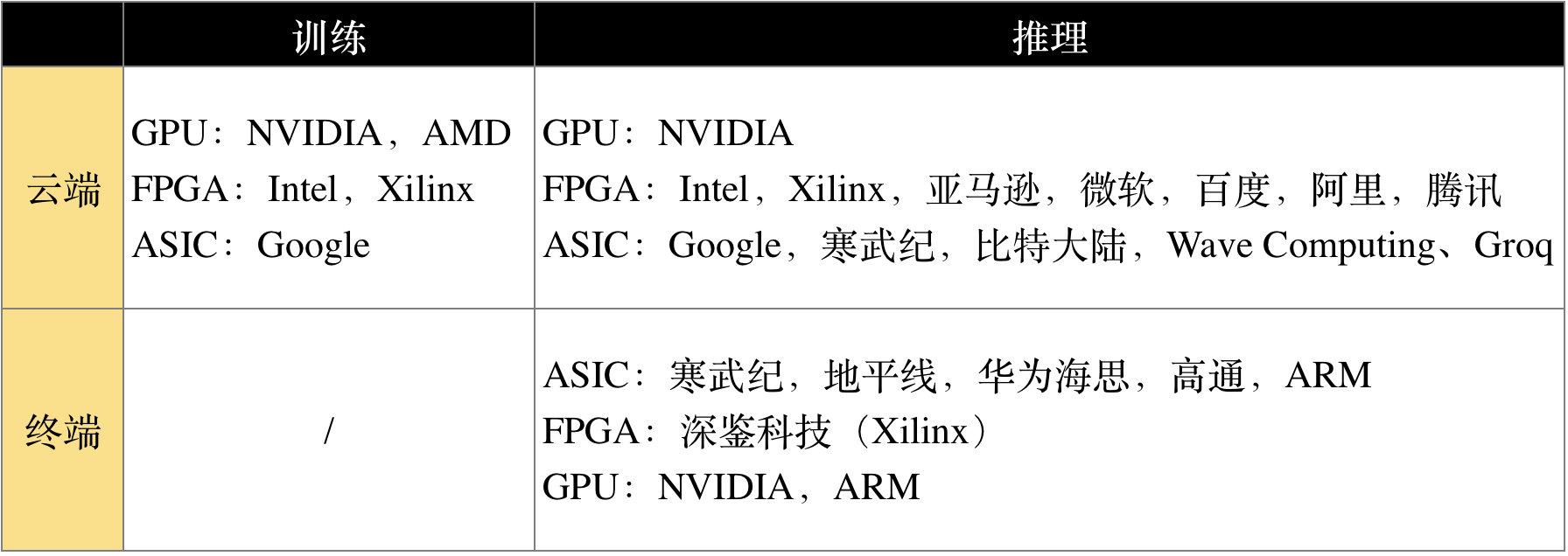
以部署位置(云端、终端)和承担任务(训练、推理)为横纵坐标,可以清晰的划分出AI芯片的市场领域,上表,列出了适用于各个市场的技术路线及相应厂商。
1)云端训练
训练芯片受算力约束,一般只在云端部署。
CPU由于计算单元少,并行计算能力较弱,不适合直接执行训练任务,因此训练一般采用“CPU+加速芯片”的异构计算模式。目前NVIDIA的GPU+CUDA计算平台是最成熟的AI训练方案,除此还有两种方案:
- 第三方异构计算平台OpenCL + AMD GPU或OpenCL + Intel/Xilinx FPGA
- 云计算服务商自研加速芯片(如Google的TPU)
训练市场目前能与NVIDIA竞争的就是Google,传统CPU/GPU厂家Intel和AMD也在努力进入训练市场。
2)云端推理
如果说云端训练芯片是NVIDIA一家独大,那云端推理芯片则是百家争鸣,各有千秋。
相比训练芯片,推理芯片考虑的因素更加综合:单位功耗算力,时延,成本等等。AI发展初期推理也采用GPU进行加速,目前来看,竞争态势中英伟达依然占大头,但由于应用场景的特殊性,依据具体神经网络算法优化会带来更高的效率,FPGA/ASIC的表现可能更突出。
除了Nvidia、Google、Xilinx、Altera(Intel)等传统芯片大厂涉足云端推理芯片以外,Wave computing、Groq 等初创公司也加入竞争。中国公司里,寒武纪、比特大陆等同样积极布局云端芯片业务。
3)终端推理
在面向智能手机、智能摄像头、机器人/无人机、自动驾驶、VR、智能家居设备、各种IoT设备等设备的终端推理AI芯片方面,目前多采用ASIC,还未形成一家独大的态势。
终端的数量庞大,而且需求差异较大。AI芯片厂商可发挥市场作用,面向各个细分市场,研究应用场景,以应用带动芯片。
传统芯片大厂如NVIDIA、Intel、ARM、高通等都积极布局,中国芯片创业企业,如寒武纪、地平线等,也有不俗表现,在一些细分市场领域颇有建树。
三、AI芯片技术路线
1. AI芯片主要技术路线
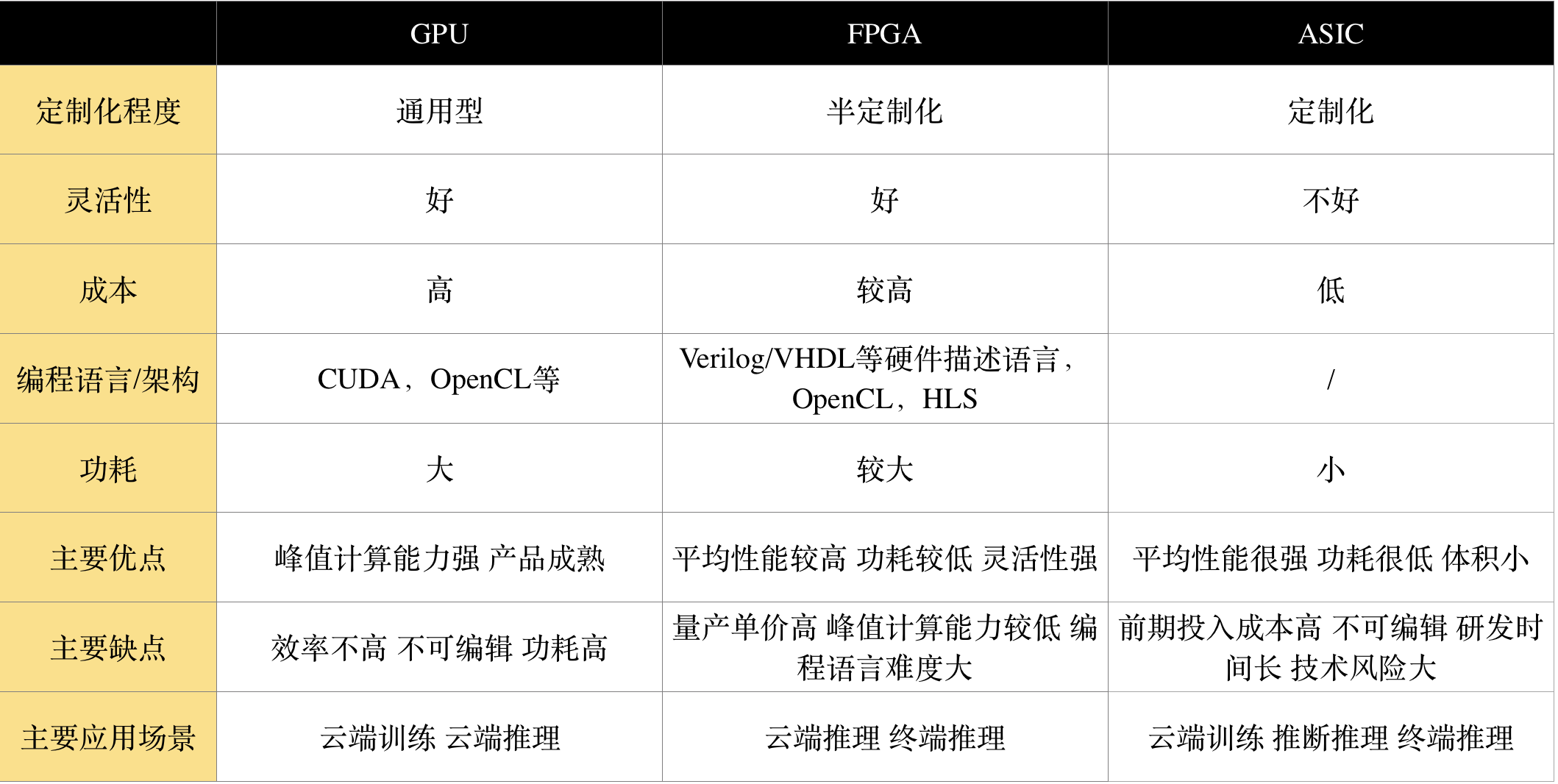
目前,作为加速应用的AI芯片,主要的技术路线有三种:GPU、FPGA、ASIC。
(可点击查看大图)
1)GPU
GPU(Graphics Processing Unit),即图形处理器,是一种由大量核心组成的大规模并行计算架构,专为同时处理多重任务而设计。GPU是专门处理图像计算的,包括各种特效的显示,更加针对图像的渲染等计算算法。这些算法与深度学习的算法还是有比较大的区别。当然,GPU非常适合做并行计算,也可以用来给AI加速。
GPU因良好的矩阵计算能力和并行计算优势,最早被用于AI计算,在数据中心中获得大量应用。GPU采用并行架构,超过80%部分为运算单元,具备较高性能运算速度。相比较下,CPU仅有20%为运算单元,更多的是逻辑单元,因此CPU擅长逻辑控制与串行运算,而GPU擅长大规模并行运算。
GPU最早作为深度学习算法的芯片被引入人工智能领域,因其良好的浮点计算能力适用于矩阵计算,且相比CPU具有明显的数据吞吐量和并行计算优势。
2011年谷歌大脑率先应用GPU芯片,当时12颗英伟达的GPU可以提供约等于2000颗CPU的深度学习性能,展示了其惊人的运算能力。目前GPU已经成为人工智能领域最普遍最成熟的智能芯片,应用于数据中心加速和部分智能终端领域,在深度学习的训练阶段其性能更是无所匹敌。
在深度学习上游训练端(主要用在云计算数据中心里),GPU是当仁不让的第一选择。目前GPU的市场格局以英伟达为主(超过70%),AMD为辅,预计未来几年内GPU仍然是深度学习训练市场的第一选择。
另外,GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
2)FPGA
FPGA(Field-Programmable Gate Array),即现场可编程门阵列,作为专用集成电路领域中的一种半定制电路出现。FPGA利用门电路直接运算,速度快,而用户可以自由定义这些门电路和存储器之间的布线,改变执行方案,以期得到最佳效果。
FPGA可以采用OpenCL等更高效的编程语言,降低了硬件编程的难度,还可以集成重要的控制功能,整合系统模块,提高了应用的灵活性,与GPU相比,FPGA具备更强的平均计算能力和更低的功耗。
FPGA适用于多指令,单数据流的分析,与GPU相反,因此常用于推理阶段。FPGA是用硬件实现软件算法,因此在实现复杂算法方面有一定的难度,缺点是价格比较高。
FPGA因其在灵活性和效率上的优势,适用于虚拟化云平台和推理阶段,在2015年后异军突起。2015年Intel收购FPGA市场第二大企业Altera,开始了FPGA在人工智能领域的应用热潮。
因为FPGA灵活性较好、处理简单指令重复计算比较强,用在云计算架构形成CPU+FPGA的混合异构中相比GPU更加的低功效和高性能,适用于高密度计算,在深度学习的推理阶段有着更高的效率和更低的成本,使得全球科技巨头纷纷布局云端FPGA生态。
国外包括亚马逊、微软都推出了基于FPGA的云计算服务,而国内包括腾讯云、阿里云均在2017年推出了基于FPGA的服务,百度大脑也使用了FPGA芯片。中国刚刚被Xilinx收购的深鉴科技也是基于FPGA来设计深度学习的加速器架构,可以灵活扩展用于服务器端和嵌入式端。
3)ASIC
ASIC(Application Specific Integrated Circuits),即专用集成电路,是一种为专用目的设计的,面向特定用户需求的定制芯片,在大规模量产的情况下具备性能更强、体积更小、功耗更低、成本更低、可靠性更髙等优点。
ASIC与GPU和FPGA不同,GPU和FPGA除了是一种技术路线之外,还是实实在在的确定的产品,而ASIC就是一种技术路线或者方案,其呈现出的最终形态与功能也是多种多样的。
近年来越来越多的公司开始采用ASIC芯片进行深度学习算法加速,其中表现最为突出的是Google的TPU。TPU比同时期的GPU或CPU平均提速15~30倍,能效比提升30~80倍。相比FPGA,ASIC芯片具备更低的能耗与更高的计算效率。但是ASIC研发周期较长、商业应用风险较大等不足也使得只有大企业或背靠大企业的团队愿意投入到它的完整开发中。
AlphaGo就使用TPU,同时TPU也支持着Google的Cloud TPU平台和基于此的机器学习超级计算机。此外,国内企业寒武纪开发的Cambricon系列芯片受到广泛关注。华为的麒麟980处理器所搭载的NPU就是寒武纪的处理器。
2. AI芯片技术路线走向
1)短期:GPU仍延续AI芯片的领导地位,FPGA增长较快
GPU短期将延续AI芯片的领导地位。目前GPU是市场上用于AI计算最成熟应用最广泛的通用型芯片,在算法技术和应用层次尚浅时期,GPU由于其强大的计算能力、较低的研发成本和通用性将继续占领AI芯片的主要市场份额。
GPU的领军厂商英伟达仍在不断探寻GPU的技术突破,新推出的Volta架构使得GPU一定程度上克服了在深度学习推理阶段的短板,在效率要求和场景应用进一步深入之前,作为数据中心和大型计算力支撑的主力军,GPU仍具有很大的优势。
FPGA是目前增长点,FPGA的最大优势在于可编程带来的配置灵活性,在目前技术与运用都在快速更迭的时期具有巨大的实用性,而且FPGA还具有比GPU更高的功效能耗比。企业通过FPGA可以有效降低研发调试成本,提高市场响应能力,推出差异化产品。在专业芯片发展得足够重要之前,FPGA是最好的过渡产品,所以科技巨头纷纷布局云计算+FPGA的平台。
随着FPGA的开发者生态逐渐丰富,适用的编程语言增加,FPGA运用会更加广泛。因此短期内,FPGA作为兼顾效率和灵活性的硬件选择仍将是热点所在。
2)长期:三大类技术路线各有优劣,会长期并存
GPU主攻高级复杂算法和通用型人工智能平台
GPU未来的进化路线可能会逐渐发展为两条路,一条主攻高端复杂算法的实现,由于GPU相比FPGA和ASIC高性能计算能力较强,同时对于指令的逻辑控制上也更复杂一些,在面临需求通用型AI计算的应用方面具有较大优势。第二条路则是通型人工智能平台,GPU由于设计方面,通用性强,性能较高,应用于大型人工智能平台够高效地完成不同种类的调用需求。
FPGA适用变化多的垂直细分行业
FPGA具有独一无二的灵活性优势,对于部分市场变化迅速的行业非常适用。同时,FPGA的高端器件中也可以逐渐增加DSP、ARM核等高级模块,以实现较为复杂的算法。FPGA以及新一代ACAP芯片,具备了高度的灵活性,可以根据需求定义计算架构,开发周期远远小于设计一款专用芯片,更适用于各种细分的行业。
ACAP的出现,引入了AI核的优点,势必会进一步拉近与专用芯片的差距。随着 FPGA 应用生态的逐步成熟,FPGA 的优势也会逐渐为更多用户所了解。
ASIC芯片是全定制芯片,长远看适用于人工智能
因为算法复杂度越强,越需要一套专用的芯片架构与其进行对应,而ASIC基于人工智能算法进行定制,其发展前景看好。ASIC是AI领域未来潜力较大的芯片,AI算法厂商有望通过算法嵌入切入该领域。ASIC具有高性能低消耗的特点,可以基于多个人工智算法进行定制,其定制化的特点使其能够针对不同环境达到最佳适应,在深度学习的训练和推理阶段皆能占据一定地位。
目前由于人工智能产业仍处在发展的初期,较高的研发成本和变幻莫测的市场使得很多企业望而却步。未来当人工智能技术、平台和终端的发展达到足够成熟度,人工智能应用的普及程使得专用芯片能够达到量产水平,此时ASIC芯片的发展将更上一层楼。
此外,AI算法提供商也有望将已经优化设计好的算法直接烧录进芯片,从而实现算法IP的芯片化,这将为AI芯片的发展注入新的动力。
四、AI芯片市场分析
1. AI芯片市场概览
2018年全球AI芯片市场规模预计将超过20亿美元,随着包括谷歌、Facebook、微软、亚马逊以及百度、阿里、腾讯在内的互联网巨头相继入局,预计到2020年全球市场规模将超过100亿美元,其中中国的市场规模近25亿美元,增长非常迅猛,发展空间巨大。
目前全球各大芯片公司都在积极进行AI芯片的布局。在云端,Nvidia的GPU芯片被广泛应用于深度神经网络的训练和推理。Google TPU通过云服务Cloud TPU的形式把TPU开放商用。老牌芯片巨头Intel推出了Nervana Neural Network Processors(NNP)。而初创公司如Wave Computing、Groq、寒武纪、比特大陆等也加入了竞争的行列,陆续推出了针对AI的芯片和硬件系统。
智能手机是目前应用最为广泛的边缘计算终端设备,包括三星、苹果、华为、高通、联发科在内的手机芯片厂商纷纷推出或者正在研发专门适应AI应用的芯片产品。另外,也有很多初创公司加入这个领域,为包括智能手机在内的众多类型边缘计算设备提供芯片和系统方案,比如寒武纪、地平线等。
传统的IP厂商,包括ARM、Synopsys、Cadence等公司也都为手机、平板电脑、智能摄像头、无人机、工业和服务机器人、智能音箱等边缘计算设备开发专用IP产品。此外在终端应用中还蕴藏着IoT这一金矿,AI芯片只有实现从云端走向终端,才能真正赋予“万物智能”。
2. 四大场景的芯片赛道
1)数据中心
在云计算数据中心,上游训练端GPU是当仁不让的第一选择。目前GPU的市场格局以英伟达为主(超过70%),AMD为辅,预计未来几年GPU仍然是深度学习市场的第一选择。
下游推理端更接近终端应用,更关注响应时间而不是吞吐率,需求更加细分,除了主流的GPU芯片之外,下游推理端可容纳FPGA、ASIC等芯片。竞争态势中英伟达依然占大头,但随着AI的发展,FPGA的低延迟、低功耗、可编程性(适用于传感器数据预处理工作以及小型开发试错升级迭代阶段)和ASIC的特定优化和效能优势(适用于在确定性执行模型)将凸显出来。
2)自动驾驶
自动驾驶对芯片算力有很高的要求, 而受限于时延及可靠性,有关自动驾驶的计算不能在云端进行,因此终端推理芯片升级势在必行。根据丰田公司的统计数据,实现L5级完全自动驾驶,至少需要12TOPS的推理算力,按照Nvidia PX2自动驾驶平台测算,差不多需要15块PX2车载计算机,才能满足完全自动驾驶的需求。
目前,自动驾驶上游系统解决方案逐渐形成英伟达与英特尔-Mobileye联盟两大竞争者。
除了上述两大主力汽车芯片竞争方,百度虽然与英伟达合作密切(Apollo开放平台从数据中心到自动驾驶都将使用英伟达技术,包括Tesla GPU和DRIVE PX 2,以及CUDA和TensorRT在内的英伟达软件),却也采用Xilinx的FPGA芯片加速机器学习,用于语音识别和汽车自动驾驶。
3)安防
AI正在以极其声势浩大的节奏全面“入侵”整个安防产业。作为这一波人工智能浪潮最大落地领域——安防,是必争之地。一大批AI芯片厂商扎堆涌入,其中既有AI芯片创业玩家,也有传统安防芯片霸主海思的强势入局。
总的来说,寒武纪、地平线等AI芯片公司提供的安防AI芯片属于协处理器,需要搭配其他公司的摄像机SoC芯片使用。而海思的安防AI芯片本身就是安防摄像机SoC芯片,只是新加入了AI模块——这也是海思安防AI芯片的最大竞争力。
也要看到,AI与AI芯片离大规模快速落地仍有距离,其中一大原因就是工程化困难——尤其是在安防这种产业链漫长而复杂的产业,新技术落地需要长时间的积累与打磨,以及人力资源的不断投入,这些都是摆在AI与AI芯片企业面前的难题。
4)手机终端AI
手机芯片市场的玩家定位包括:
- 采用芯片+整机垂直商业模式的厂商:苹果、三星、华为等;
- 独立芯片供应商:高通、联发科、展锐等;
- 向芯片企业提供独立IP授权的供应商:ARM、Synopsys、Cadence,寒武纪等。
采用垂直商业模式厂商的芯片不对外发售,只服务于自身品牌的整机,性能针对自身软件做出了特殊优化,靠效率取胜。独立芯片供应商以相对更强的性能指标,来获得剩余厂商的市场份额。
从2017年开始,苹果、华为海思、高通、联发科等主要芯片厂商相继发布支持AI加速功能的新一代芯片,AI芯片逐渐向中端产品渗透。由于手机空间有限,独立的AI芯片很难被手机厂商采用。在AI加速芯片设计能力上有先发优势的企业(如寒武纪)一般通过IP授权的方式切入。
高通很有可能在手机AI赛道延续优势地位,近日发布的骁龙855被称为当前最强AI芯片,比起苹果A12、华为麒麟980,性能提升1倍,并将成为全球第一款商用5G芯片。
五、AI芯片主要厂商介绍
在AI芯片领域,国外芯片巨头占据了绝大部分市场份额,不论是在人才聚集还是公司合并等方面,都具有领先优势。尤其是美国巨头企业,凭借芯片领域多年的领先地位,迅速切入AI领域,积极布局,四处开花,目前处于引领产业发展的地位,并且在GPU和FPGA方面是完全垄断地位。国内AI芯片公司多为中小型初创公司,在一些细分市场也有建树,诞生了多个独角兽企业。
1. 国外主要厂商
(可点击查看大图)
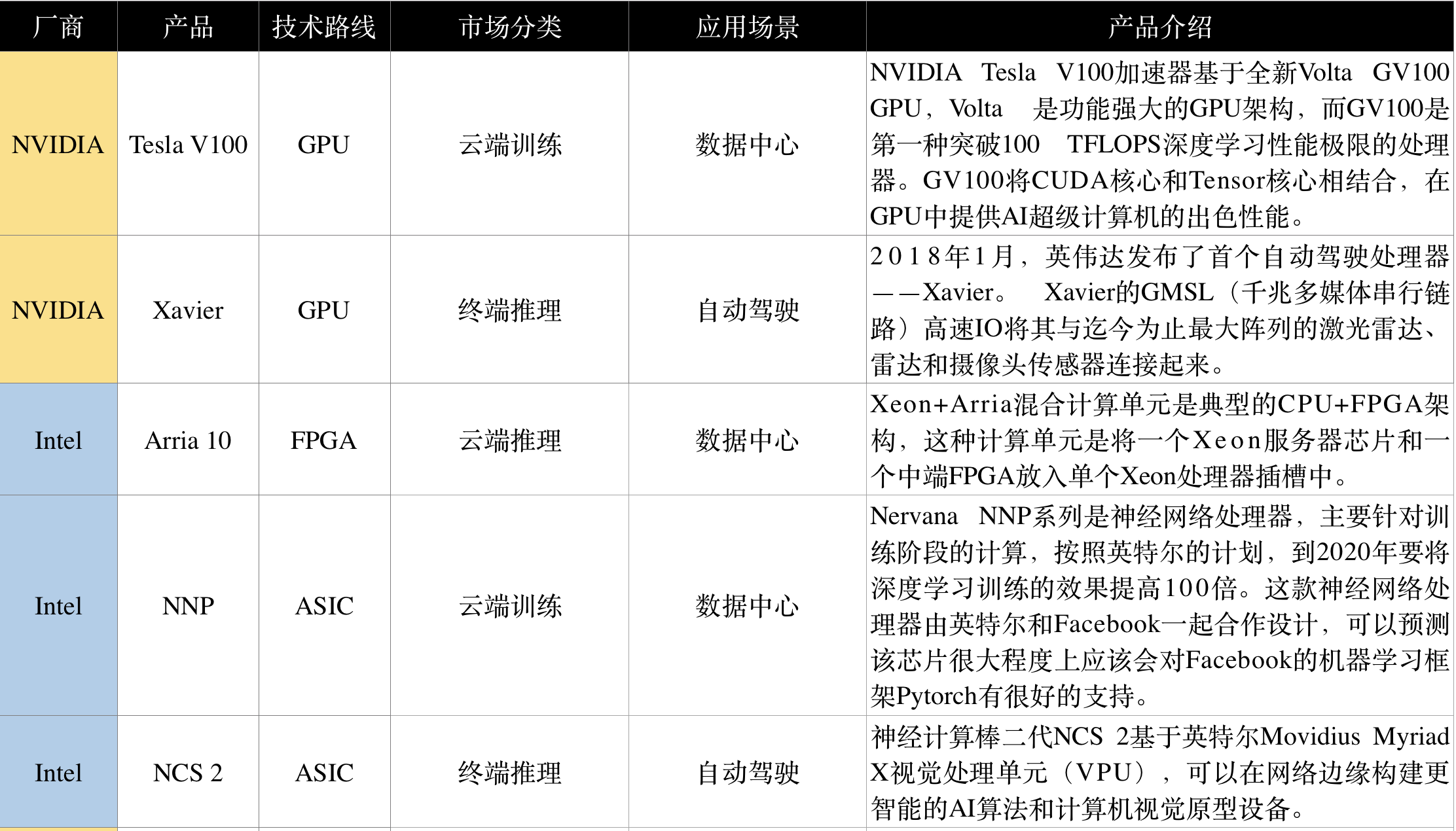
1)NVIDIA 英伟达
目前AI芯片领域主要的供应商仍然是英伟达,占全球AI芯片50%以上市场份额。英伟达保持了极大的投入力度,快速提高GPU的核心性能,增加新型功能,保持了在AI训练市场的霸主地位,并积极拓展终端嵌入式产品形态,推出Xavier系列。
英伟达旗下产品线遍布自动驾驶汽车、高性能计算、机器人、医疗保健、云计算、游戏视频等众多领域。
英伟达拥有目前最为成熟的开发生态环境——CUDA ,因其统一而完整的开发套件,丰富的库以及对英伟达GPU的原生支持而成为开发主流,目前已开发至第9代,开发者人数超过51万。
英伟达还将联合芯片巨头ARM打造IoT设备的AI芯片专用IP,这款机器学习IP集成到ARM的Project Trillium平台上,以实现机器学习,其技术源于英伟达Xavier芯片以及去年开源的DLA深度学习加速器项目。
2)Intel 英特尔
英特尔作为传统PC芯片的老大,也在积极向PC以外的市场转型。
为了加强在AI芯片领域的实力,英特尔收购FPGA生产商Altera,收购自动驾驶技术公司Mobileye,以及机器视觉公司 Movidius和为自动驾驶汽车芯片提供安全工具的公司Yogitech,收购人工智能软硬件创业公司Nervana。在数据中心、自动驾驶等重要领域布局扎实。
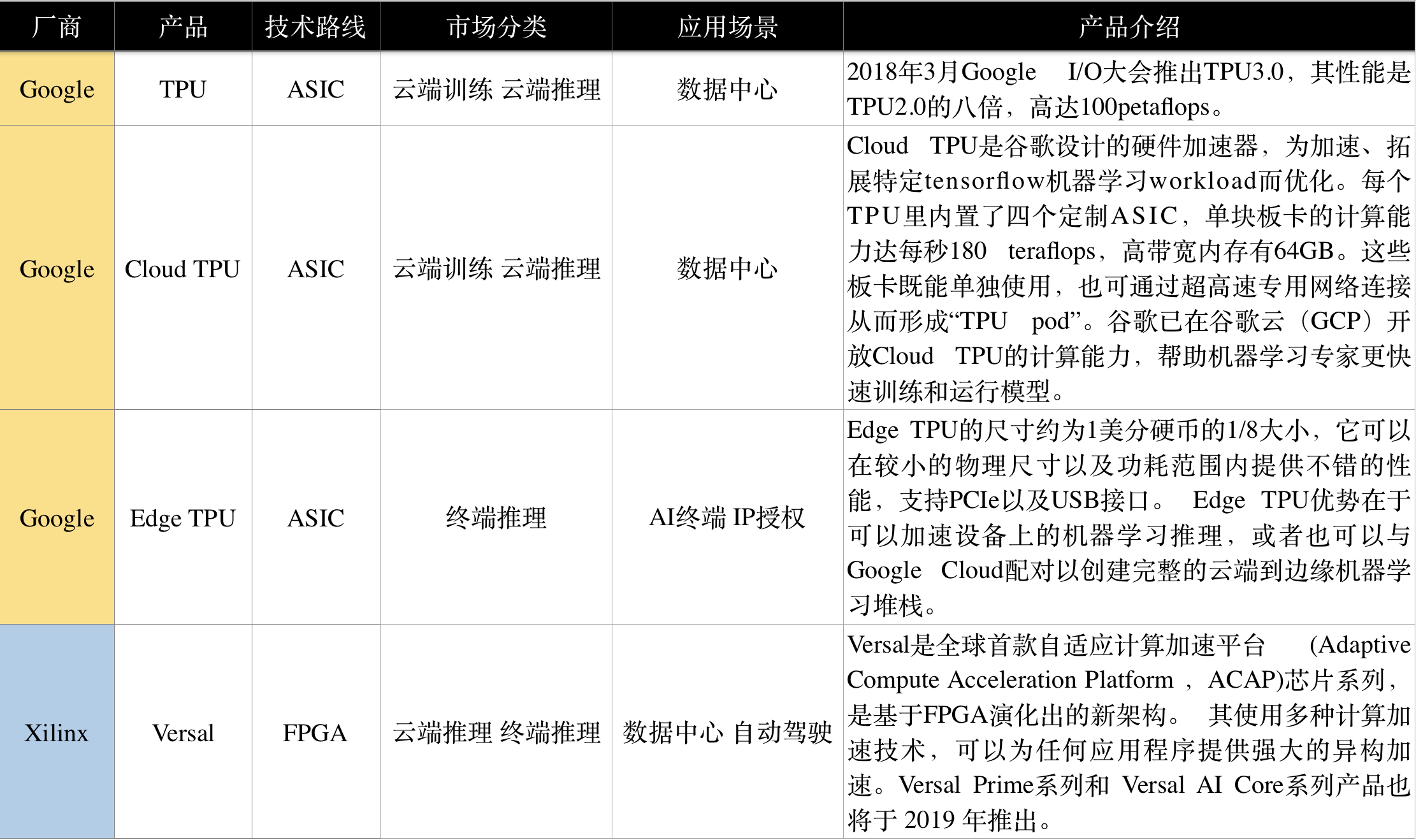
3)Google 谷歌
Google在2016年宣布独立开发一种名为TPU的全新处理系统。在2016年3月打败了李世石和2017年5月打败了柯杰的的AlphaGo,就是采用了谷歌的TPU系列芯片。
TPU是专门为机器学习应用而设计的专用芯片。通过降低芯片的计算精度,减少实现每个计算操作所需的晶体管数量,从而能让芯片的每秒运行的操作个数更高,这样经过精细调优的机器学习模型就能在芯片上运行得更快,加深了人工智能在训练和推理方面的能力,进而更快地让用户得到更智能的结果。
2018年3月Google I/O大会推出TPU3.0。据官方数据,TPU3.0的性能是TPU2.0的八倍,高达 100 petaflops。
Cloud TPU是谷歌设计的硬件加速器,为加速、拓展特定tensorflow机器学习workload而优化。每个TPU里内置了四个定制ASIC,单块板卡的计算能力达每秒180 teraflops,高带宽内存有64GB。这些板卡既能单独使用,也可通过超高速专用网络连接从而形成“TPU pod”。谷歌已在谷歌云(GCP)开放Cloud TPU的计算能力,帮助机器学习专家更快速训练和运行模型。
Edge TPU的尺寸约为1美分硬币的1/8大小,它可以在较小的物理尺寸以及功耗范围内提供不错的性能,支持PCIe以及USB接口。Edge TPU优势在于可以加速设备上的机器学习推理,或者也可以与Google Cloud配对以创建完整的云端到边缘机器学习堆栈。
4)Xilinx 赛灵思
2018年3月,赛灵思宣布推出一款超越FPGA功能的新产品——ACAP(自适应计算加速平台),其核心是新一代的FPGA架构。10月,发布最新基于7nm工艺的ACAP平台的第一款处理器——Versal。其使用多种计算加速技术,可以为任何应用程序提供强大的异构加速。Versal Prime系列和Versal AI Core系列产品也将于 2019 年推出。
Xilinx和Intel两家不约而同把FPGA未来市场重心放到数据中心市场。
2. 国内主要厂商
国内AI芯片厂商以中小公司为主,没有巨头,多集中于设备端AI ASIC的开发,并已有所建树,如寒武纪成为全球AI芯片领域第一个独角兽初创公司,其NPU IP已被应用于全球首款手机AI芯片——麒麟970。
但是,中国在FPGA、GPU领域缺乏有竞争力的原创产品,只是基于FPGA/GPU做进一步开发,这主要与我国在芯片领域一直缺乏关键核心自主技术有关,FPGA/GPU的技术壁垒已很高,很难有所突破。
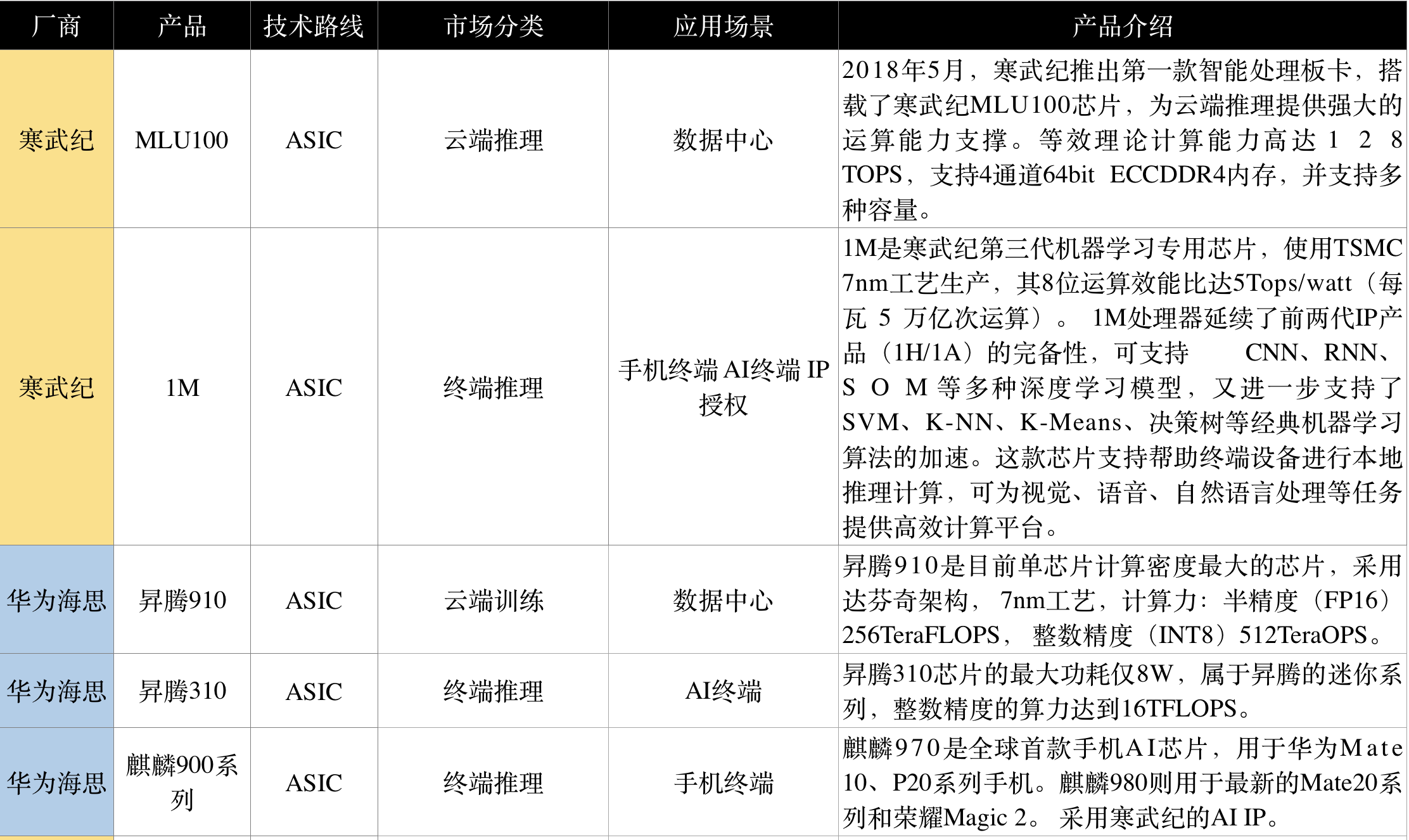
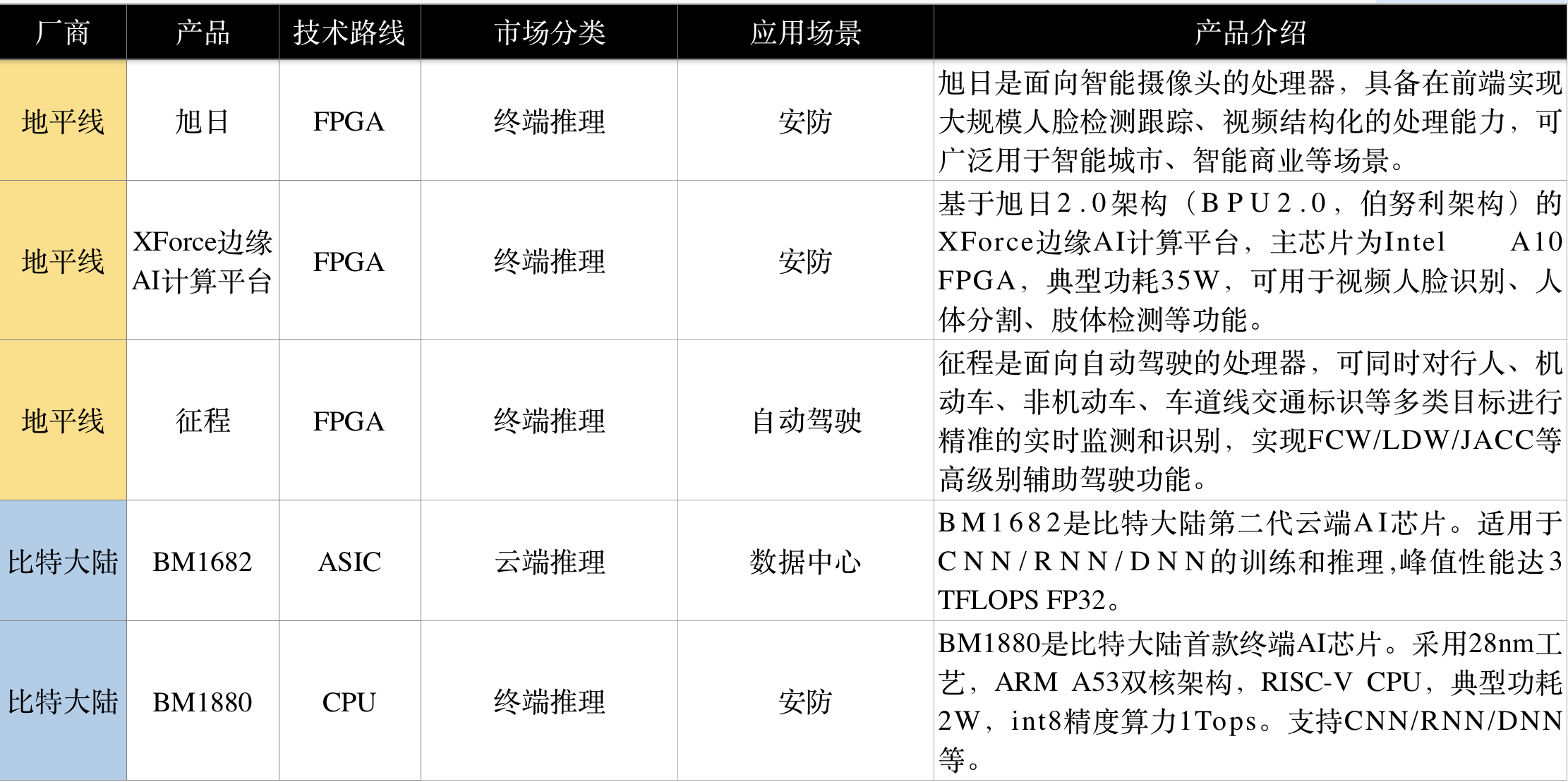
(可点击查看大图)
1)寒武纪 Cambricon
寒武纪创立于2016年3月,是中科院孵化的高科技企业。
2018年5月,寒武纪推出第一款智能处理板卡,搭载了寒武纪 MLU100 芯片,为云端推理提供强大的运算能力支撑。等效理论计算能力高达128 TOPS,支持4通道64 bit ECCDDR4内存,并支持多种容量。
1M是寒武纪第三代机器学习专用芯片,使用TSMC 7nm工艺生产,其8位运算效能比达 5Tops/watt(每瓦 5 万亿次运算)。寒武纪1M处理器延续了前两代IP产品(1H/1A)的完备性,可支持CNN、RNN、SOM等多种深度学习模型,又进一步支持了SVM、K-NN、K-Means、决策树等经典机器学习算法的加速。这款芯片支持帮助终端设备进行本地训练,可为视觉、语音、自然语言处理等任务提供高效计算平台。
寒武纪也推出了面向开发者的寒武纪人工智能软件平台Cambricon NeuWare,这是在终端和云端的AI芯片共享的软件接口和生态,包含开发、调试和调优三大部分,体现了创始人陈天石提出的“端云一体”的思路。
2)华为海思 Hisilicon
海思半导体成立于2004年10月,是华为集团的全资子公司。
麒麟970集成NPU神经处理单元,是全球第一款手机AI芯片,它在处理静态神经网络模型方面有得天独厚的优势;新一代的麒麟980用于最新的Mate20系列和荣耀Magic 2。二者均采用寒武纪的AI IP。
安防是一众AI芯片公司纷纷瞄准的重要落地场景,作为传统安防芯片霸主,海思表示以后的所有IPC芯片新品,都将搭载专用AI模块。
华为近期提出了全栈全场景AI解决方案,发布了两款AI芯片,昇腾910和昇腾310。昇腾910是目前单芯片计算密度最大的芯片,计算力远超谷歌及英伟达,而昇腾310芯片的最大功耗仅8W,是极致高效计算低功耗AI芯片。
3)地平线 Horizon Robotics
地平线成立于2015年7月,是一家注重软硬件结合的AI初创公司,由Intel、嘉实资本、高瓴资本领投。
2017年12月,地平线自主设计研发了中国首款嵌入式人工智能视觉芯片——旭日1.0和征程1.0。
旭日1.0是面向智能摄像头的处理器,具备在前端实现大规模人脸检测跟踪、视频结构化的处理能力,可广泛用于智能城市、智能商业等场景。
征程1.0是面向自动驾驶的处理器,可同时对行人、机动车、非机动车、车道线交通标识等多类目标进行精准的实时监测和识别,实现FCW/LDW/JACC等高级别辅助驾驶功能。
地平线今年又推出了基于旭日(Sunrise)2.0的架构(BPU2.0,伯努利架构)的XForce边缘AI计算平台,其主芯片为Intel A10 FPGA,典型功耗35W,可用于视频人脸识别、人体分割、肢体检测等功能。
4)比特大陆 Bitmain
比特大陆成立于2013年10月,是全球第一大比特币矿机公司,目前占领了全球比特币矿机 70%以上的市场。并已将业务拓展至AI领域,于2017年推出云端AI芯片BM1680,支持训练和推断。目前已推出第二代产品BM1682,相较上一代性能提升5倍以上。
BM1880是比特大陆首款面向边缘端计算的低功耗AI协处理器,采用28nm工艺,ARM A53双核架构,RISC-V CPU,其典型功耗2W,int 8精度算力能够达到1Tops。
比特大陆提供端云一体化的AI解决方案,与终端AI芯片不同,比特大陆的云端AI芯片将不会单独发售,只搭载在板卡、云服务器中提供给合作伙伴。
比特大陆将其AI芯片落地产业拓展到了四大类,分别是:安防、园区、智慧城市、互联网。
3. 互联网巨头入局与新模式
1)互联网巨头入局
全球互联网巨头纷纷高调宣布进入半导体行业,阿里、微软、Google、Facebook、亚马逊等都宣布在芯片领域的动作。当互联网巨头开始进入芯片市场时,会对芯片行业产生巨大的影响。
首先,互联网巨头追求硬件能实现极致化的性能以实现差异化用户体验用来吸引用户。在摩尔定律即将遇到瓶颈之际,想要追求极致体验需要走异构计算,自己定制化芯片的道路,光靠采购传统半导体厂商的芯片,已经没法满足互联网巨头对于硬件的需求,至少在核心芯片部分是这样。
因此,Facebook、Google、阿里等互联网巨头都是异构计算的积极拥护者,为了自己的硬件布局或计划设计芯片,或已经开始设计芯片。这么一来,原来是半导体公司下游客户的互联网公司现在不需要从半导体公司采购芯片了,这样的产业分工变化会引起行业巨变。
其次,互联网巨头制造硬件的目的只是为了吸引用户进入自己的生态,使用自己的服务,其最终盈利点并不在贩卖硬件上而是在增值服务上。因此,互联网巨头在为了自己的硬件设计芯片时可以不计成本。
从另一个角度来说,一旦自己设计核心芯片的互联网公司进入同一个领域,那些靠采购半导体公司标准芯片搭硬件系统的公司,就完全没有竞争力了,无论是从售价还是性能,拥有自己核心芯片的互联网巨头都能实施降维打击。一旦这些硬件公司失去竞争力,那么依赖于这些客户的半导体公司的生存空间又会进一步被压缩。
总而言之,互联网巨头进入芯片领域,首先出于性能考虑不再从半导体公司采购核心芯片,这冲击了传统行业分工,使传统芯片公司失去了一类大客户;另一方面互联网巨头的生态式打法可以让自研硬件芯片不考虑成本,这又冲击了那些从半导体公司采购芯片的传统硬件公司,从而进一步压缩了半导体公司的市场。
在这两个作用下,半导体芯片公司的传统经营模式必须发生改变才能追上新的潮流。
2)Designless-Fabless模式
目前,半导体行业领域的分工,大概可以分为定义、设计、设计定案、制造等几个环节。
今天的半导体行业,最为大家熟知的是Fabless模式,即芯片设计公司负责定义、设计和设计定案,而制造则是在提供代工的Fab完成,如高通,是Fabless的典型代表。
在互联网巨头入局半导体行业后,又出现了一种新的模式,即互联网公司负责定义芯片、完成小部分设计、并花钱完成设计定案流片,设计服务公司负责大部分设计,而代工厂负责芯片制造。这种新模式可以称为Designless-Fabless模式。
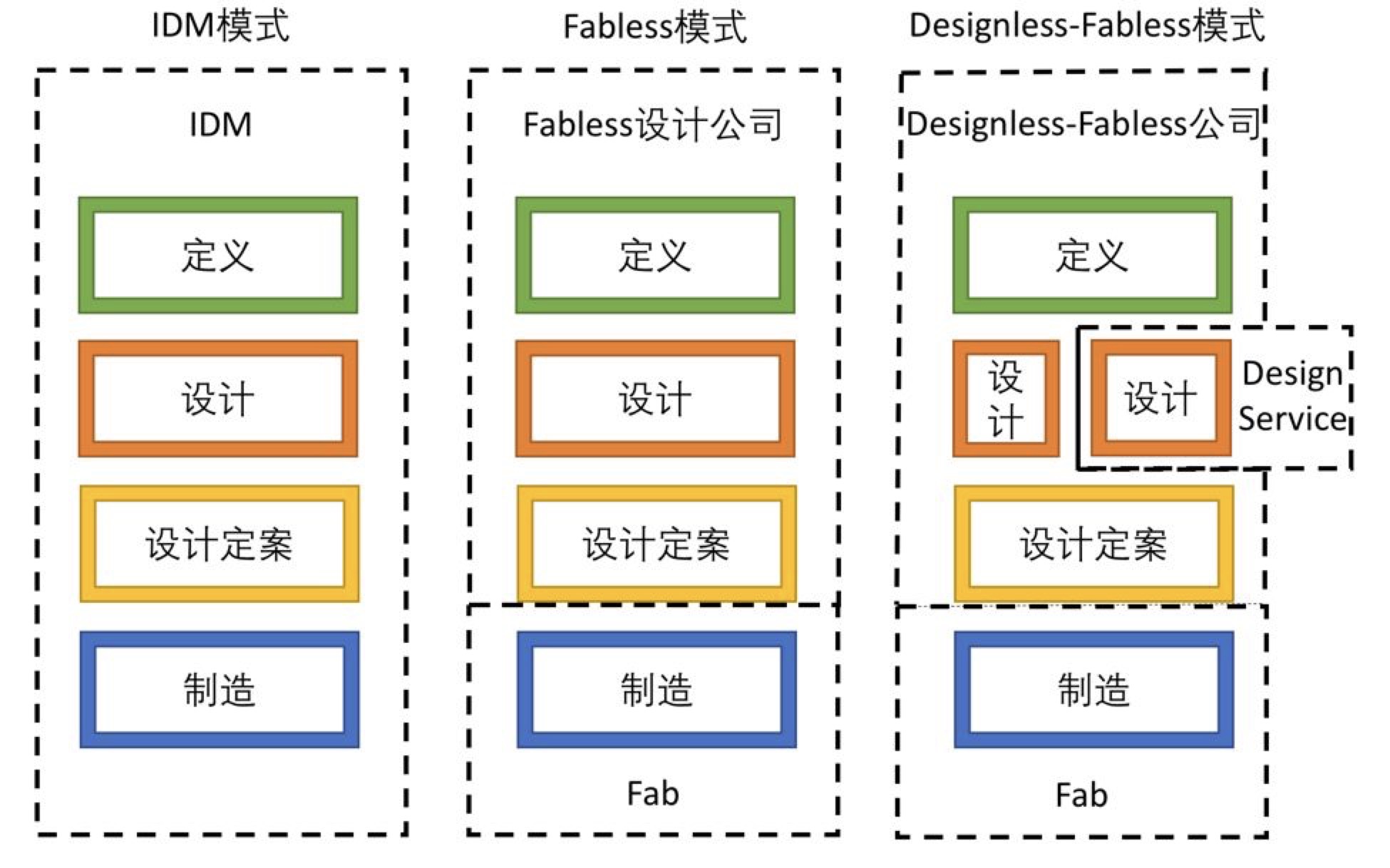
历史上,半导体公司从传统的IDM走到Fabless模式,主要是因为Fab开销过高,成为了半导体公司发展的包袱,而代工厂则提供了一个非常灵活的选项。
今天,互联网公司入局半导体后走Designless-Fabless模式,把大量设计外包,则主要是因为时间成本。互联网巨头做芯片,追求的除了极致性能之外,还有快速的上市时间。对于他们来说,如果要像传统半导体公司一样,需要从头开始培养自己的前端+后端设计团队,从头开始积累模块IP,恐怕第一块芯片上市要到数年之后。这样的节奏,是跟不上互联网公司的快速迭代节奏的。
那么如何实现高性能加快速上市呢?
最佳方案就是这些巨头自己招募芯片架构设计团队做芯片定义,用有丰富经验的业界老兵来根据需求定制架构以满足性能需求,而具体的实现,包括物理版图设计甚至前端电路设计都可以交给设计服务公司去做。
半导体芯片的一个重要特点就是细节非常重要,ESD、散热、IR Drop等一个小细节出错就可能导致芯片性能大打折扣无法达到需求。因此,如果把具体设计工作交给有丰富经验的设计服务公司,就可以大大减少细节出错的风险,从而减小芯片需要重新设计延误上市时间的风险。
随着分工的进一步细化,原先起辅助作用的设计服务公司,将越来越重要,能够与互联网巨头产生互补效应。不少半导体公司也注意到了设计服务的潮流,并开始向设计服务靠拢。联发科前一阵高调公开设计服务业务,就是半导体公司转向的重要标志。
对于国内的AI芯片初创公司来说,善用这种Designless-Fabless模式,对于缩短产品研发周期,提升产品设计水平,都有很大帮助。
六、AI芯片展望
1. AI芯片发展面临的问题
目前,AI芯片发展速度虽然很快,但是现在的人工智能新算法也是层出不穷的,这样一来就没有一个具体的标准,也没有对相应的规格进行固定。其次,现在的人工智能算法都仅仅只是针对于单个应用进行研发的,并没有能够覆盖全方位,所以鲜有杀手级别的AI应用。
在发展过程中,AI芯片首要解决的问题就是要适应现在人工智能算法的演进速度,并且要进行适应,这样才能够保证匹配发展。
此外,AI芯片也要适当的对架构进行创新兼容,让其能够兼容适应更多的应用,这样能够开发出更好的包容性应用。
目前全球人工智能产业还处在高速变化发展中,广泛的行业分布为人工智能的应用提供了广阔的市场前景,快速迭代的算法推动人工智能技术快速走向商用,AI芯片是算法实现的硬件基础,也是未来人工智能时代的战略制高点,但由于目前的 AI算法往往都各具优劣,只有给它们设定一个合适的场景才能最好地发挥其作用,因此,确定应用领域就成为发展AI芯片的重要前提。
从芯片发展的大趋势来看,现在还是AI芯片的初级阶段。无论是科研还是产业应用都有巨大的创新空间。从确定算法、应用场景的AI加速芯片向具备更高灵活性、适应性的通用智能芯片发展是技术发展的必然方向。未来几年AI芯片产业将持续火热,公司扎堆进入,但也很可能会出现一批出局者,行业洗牌,最终的成功与否则将取决于各家公司技术路径的选择和产品落地的速度。
2. 半导体行业周期:下一个黄金十年
分析半导体市场的历史(如下图),我们会看到典型的周期性现象,即每个周期都会有一个明星应用作为引擎驱动半导体市场快速上升,而在该明星应用的驱动力不足时半导体市场就会陷入原地踏步甚至衰退,直到下一个明星应用出现再次引领增长。
这些明星应用包括90年代的PC,21世纪第一个十年的手机移动通信,以及2010年前后开始的智能手机。在两个明星应用之间则可以看到明显的半导体市场回调,例如1996-1999年之间那段时间处于PC和手机之间的青黄不接,而2008-2009年则是传统移动通信和智能手机之间的调整。
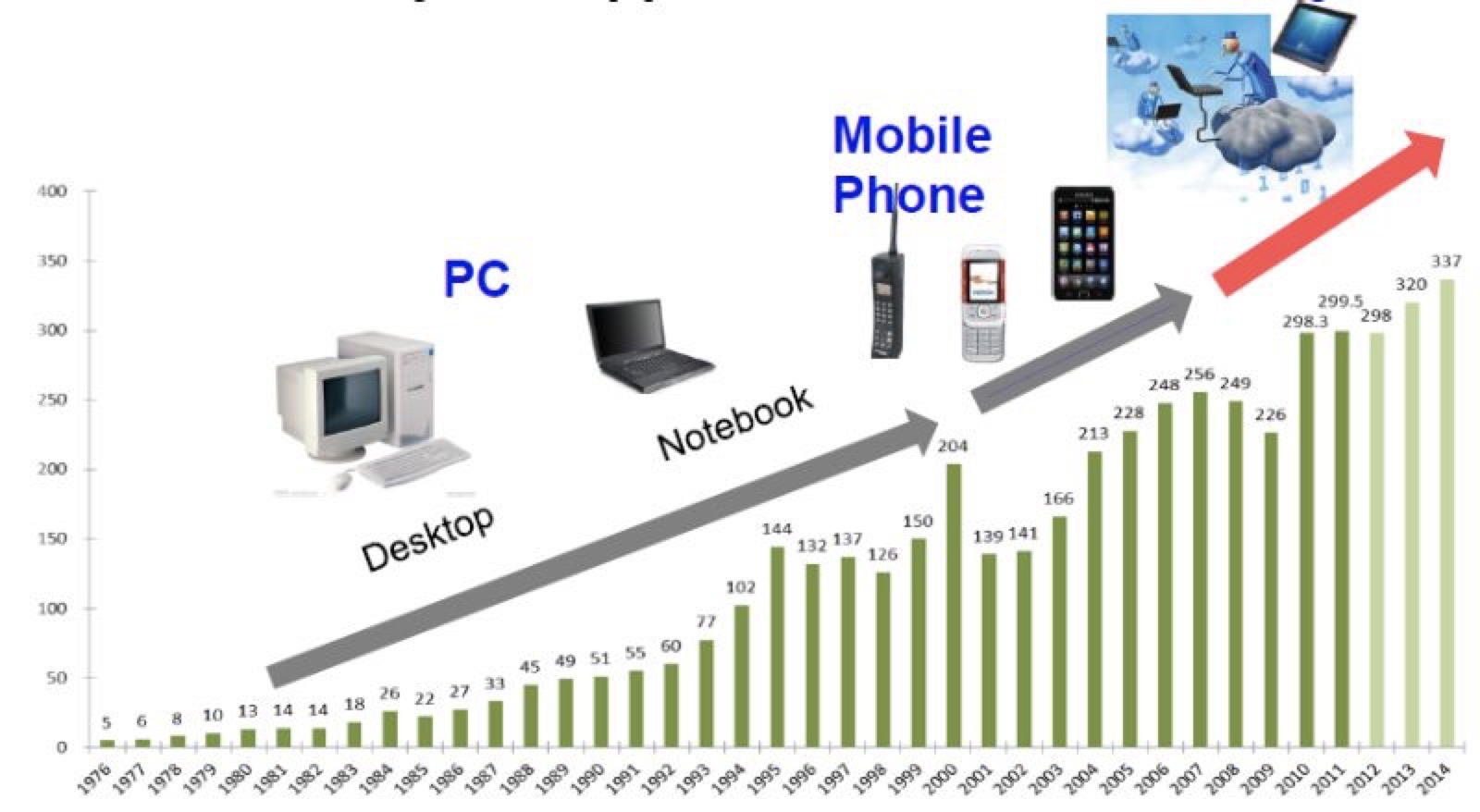
半导体过去的十年,是以iPhone为首的智能手机带动的黄金十年。现在的半导体行业,即将进入两个明星应用出现之间的调整期。
谁将成为引领半导体下一个黄金十年的明星应用?
一个应用对于整个半导体行业的驱动作用可以分为两部分,即应用的芯片出货量以及技术驱动力。
半导体行业是一个十分看重出货量的领域,只有应用的芯片出货量足够大时,这个市场才能容下足够多的竞争公司,从而驱动半导体行业。有些应用市场总额很大,但是其走的是高售价高利润率的模式,芯片出货量反而不大,这样的话其对于半导体行业的驱动作用就有限。
除了出货量之外,另一个重要因素是应用的技术驱动力,即该应用是否对于半导体技术的更新有着强烈而持续的要求,因为只有当半导体技术一直在快速更新迭代时,半导体行业才能是一个高附加值的朝阳行业,才能吸引最好的人才以及资本进入,否则一旦半导体技术更新缓慢,整个行业就会陷入僵化的局面。
PC时代的PC机就是对半导体有强烈技术驱动力的典型,PC上的多媒体应用对于处理器速度有着永不满足的需求,而这又转化成了对于处理器相关半导体技术强烈而持续的更新需求,直接推动了摩尔定律和半导体行业在90年代的黄金时期。
反之,有一些应用的出货量很大但是其对于半导体的技术驱动力并不大,例如传统家电中的主控MCU芯片,这些MCU芯片出货量很大,但是在技术上并没有强烈的进步需求,不少传统家电多年如一日一直在用成熟半导体工艺实现的8位MCU,那么这样的应用对于半导体来说实质上引领作用也比较有限。
应用出货量决定了半导体行业的横向市场规模,而技术驱动力则决定了半导体技术的纵向进化动能。回顾之前几个成为半导体行业引擎的明星应用,无不是出货量和技术驱动力双双领先。
PC出货量(在当时)很大,且是当年摩尔定律黄金时代的主推者。移动手机在出货量很大的同时,还推动了CMOS/III-V族工艺射频相关电路设计技术的大幅进展。
智能手机则更是驱动了多项半导体芯片相关技术的发展,例如2.5D高级封装,用于3D识别的激光模组,触摸屏和指纹相关芯片等,而一个智能手机中包含的半导体芯片数量从射频前端、存储器到惯性传感器数量也极多,因此其能撑起半导体的上一个黄金十年。
所以,能撑起下一个半导体黄金十年的应用,必然在芯片出货量和技术驱动力,这两个维度上都有强劲的动力。
从这个观点出发,可以发现:
- 只存在于云端的云AI芯片,是作为一种基础设施出现的,归根到底是服务2B客户,因此云AI芯片的出货量相比智能手机这样的智能设备要小很多。技术驱动力很强,但是出货量相对较小。
- IoT的出货量很大,但是对于半导体技术发展的驱动力就比较有限。
- 汽车电子的增长点主要还是汽车的智能化,包括自动驾驶,车联网等等,但是汽车电子的出货量比起智能手机设备少很多。
以上三种应用虽然有巨大的空间,但还不能成为支撑力量。
能够起到支撑作用的,推测应该是在当前智能手机基础上发展起来的下一代个人智能设备,可能是以AI手机的形势呈现。手机首先出货量很大,几乎人手一个;此外AI手机上运行的应用程序的不断更新迭代对于手机中的芯片技术提出了强烈而持续的技术进化需求,因此其对于半导体行业的技术驱动力极强。
附1、未来两种可能的通用AI芯片技术路线介绍
(1)类脑芯片
这类AI芯片属于神经拟态芯片,从结构层面去模拟大脑,参考人脑神经元结构和人脑感知认知方式来设计芯片,俗称“类脑芯片”。
类脑芯片在架构上直接通过模仿大脑结构进行神经拟态计算,完全开辟了另一条实现人工智能的道路,而不是作为人工神经网络或深度学习的加速器存在。类脑芯片可以将内存、CPU和通信部件完全集成在一起,实现极高的通信效率和极低的能耗。
目前该类芯片还只是小规模研究与应用,低能耗的优势也带来预测精度不高等问题,没有高效的学习算法支持使得类脑芯片的进化较慢,还不能真正实现商用。
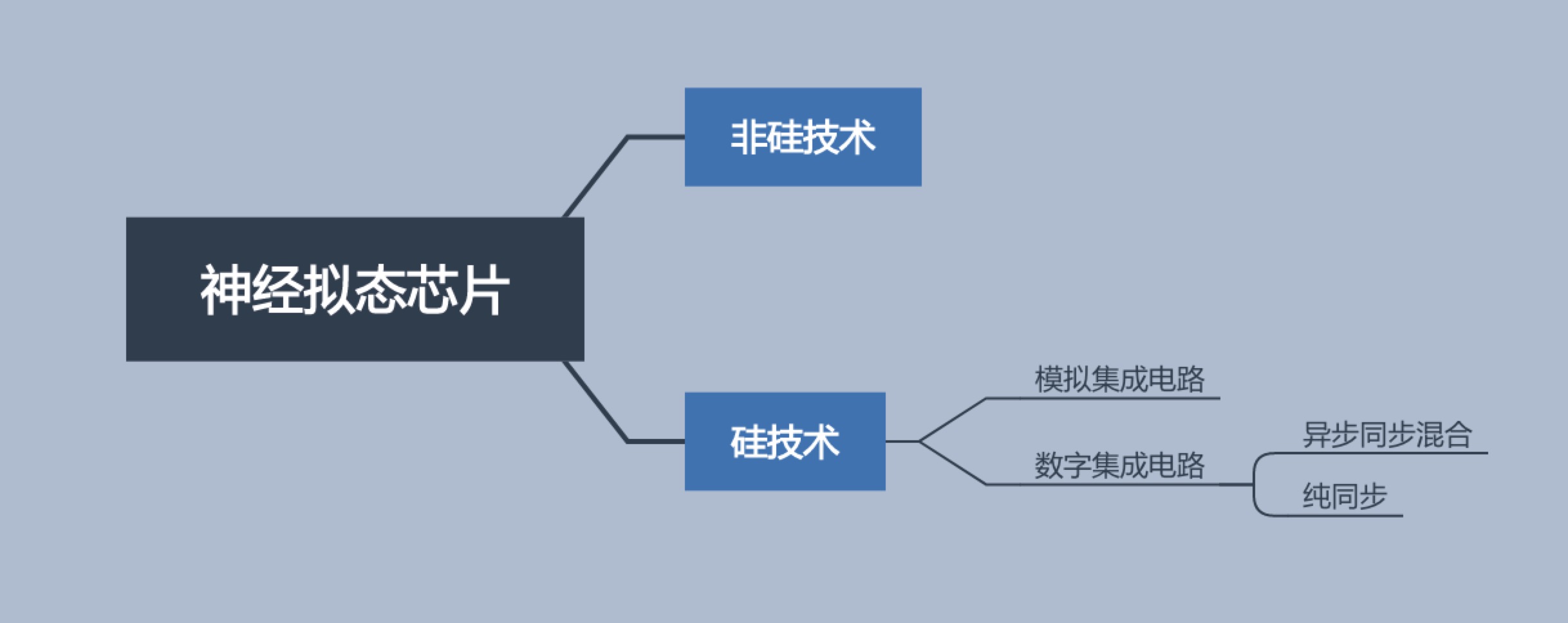
目前神经拟态芯片的设计方法主要分为非硅和硅技术。非硅主要指采用忆阻器等新型材料和器件搭建的神经形态芯片,还处于研究阶段。硅技术包括模拟和数字两种。模拟集成电路的代表是瑞士苏黎世联邦理工学院的ROLLS芯片和海德堡大学的BrainScales芯片。数字集成电路又分为:异步同步混合和纯同步两种。
其中异步(无全局时钟)数字电路的代表是IBM的TrueNorth,纯同步的数字电路代表是清华大学的“天机”系列芯片。
另外,对于片上自学习能力,最近Intel推出了Loihi芯片,带有自主片上学习能力,通过脉冲或尖峰传递信息,并自动调节突触强度,能够通过环境中的各种反馈信息进行自主学习。中国研究类脑芯片的企业还有:西井科技,灵汐科技,深思创芯等。
(2)可重构通用AI芯片
这类AI芯片遵循软件定义芯片思想,是基于可重构计算架构的芯片,兼具处理器的通用性和ASIC的高性能与低功耗,是未来通用AI芯片的方向之一。
可重构计算技术允许硬件架构和功能随软件变化而变化,兼具处理器的通用性和ASIC的高性能和低功耗,是实现软件定义芯片的核心,被公认为是突破性的下一代集成电路技术。清华大学微电子学研究所设计的AI芯片Thinker,采用可重构计算架构,能够支持卷积神经网络、全连接神经网络和递归神经网络等多种AI算法。
值得一提的是,DARPA在电子振兴计划(ERI)中提出了三个支柱:材料、架构、设计,用于支撑美国2025 – 2030年之间的国家电子设计能力。这其中每一个方向都设置了一个课题,其中一个课题在架构中提出了软件定义硬件的概念,也就是 Software defines Hardware。
ERI中讲道:所谓要建立运行时可以实时重新配置的硬件和软件,他们具备像ASIC一样的性能,而没有牺牲数据密集型计算的可编程性。
现今的AI芯片在某些具体任务上可以大幅超越人的能力,但究其通用性与适应性,与人类智能相比差距甚远,大多处于对特定算法的加速阶段。而AI芯片的最终成果将是通用AI芯片,并且最好是淡化人工干预的自学习、自适应芯片。
因此未来通用 AI芯片应包含以下特征:
- 可编程性:适应算法的演进和应用的多样性。
- 架构的动态可变性:能适应不同的算法,实现高效计算。
- 高效的架构重构能力或自学习能力。
- 高计算效率:避免使用指令这类低效率的架构。
- 高能量效率:能耗比大于5 Tops/W(即每瓦特进行5×10^12次运算)。
- 低成本低功耗:能够进入物联网设备及消费类电子中。
- 体积小:能够加载在移动终端上。
- 应用开发简便:不需要用户具备芯片设计方面的知识。
对于可重构架构,大家可能觉得FPGA早就可以这样做了,但实际上FPGA有很多局限性,包括以下这些:
- 细粒度:由于要实现比特级运算,运算颗粒度必须为细粒度;
- 配置信息量大:通常为几兆到十几兆字节;
- 配置时间长:通常需要十几毫秒到几十毫秒;
- 静态编程:一旦配置完成,不可更改。如果要改变 FPGA 的功能,只能下电或在线重新载入配置信息;
- 逻辑不可复用:所有电路必须全部装入FPGA ,复用性为零;
- 面积效率低:每个LUT只能实现一位运算,面积效率只有5%。一个千万级的FPGA只能实现几十万门的逻辑电路;
- 能量效率低:由于逻辑利用率低,引发无效功耗巨大;
- 需要特种工艺:FPGA 往往需要最先进的制造工艺,且需对工艺进行特别调整;
- 电路设计技术:应用者必须具备电路设计知识和经验;
- 成本高昂:目前的FPGA价格为几千到几万美元一片。
目前尚没有真正意义上的通用AI芯片诞生,而基于可重构计算架构的软件定义芯片(software defined chip)或许是通用AI芯片的出路。
附2:参考文章
[1] AI芯片和传统芯片有何区别?,EETOP,2018-7-20
[2] AI芯片的“战国时代”:计算力将会驶向何方?,AI科技大本营,2018-11-6
[3] 16位AI芯片玩家疯狂涌入!安博会成AI芯片阅兵场,智东西,2018-10-24
[4] 五大趋势看透2018安博会!AI芯片扎堆涌入,人脸识别成小儿科,智东西,2018-10-23
[5] 比特大陆推首款低功耗边缘AI芯片 主攻安防场景,智东西,2018-10-17
[6] 半导体下一个黄金十年,谁主沉浮?,矽说,2018-11-15
[7] 互联网巨头入局芯片,将给半导体产业带来深远变化,矽说,2018-6-24
[8] 人工智能芯片发展的现状及趋势,科技导报,2018-9-29
[9] 中美AI芯片发展现状与趋势,微言创新,2017-11-02
[10] 一文看懂所有类型的AI芯片!(附全球最顶尖AI芯片的企业名录),IT大佬,2018-6-11
[11] AI芯片:一块价值146亿美元的蛋糕,被三大门派四大场景瓜分,IT大佬,2017-12-06
[12] 250多位专家对AI芯片未来发展的预测,半导体行业观察,2018-9-30
[13] 【世经研究】AI芯片行业发展正当时,世经未来,2018-7-11
[14] AI芯片最新格局分析,半导体行业观察,2018-9-9
[15] AI芯片届巨震!英伟达ARM联手打造数十亿AI芯片 | GTC 2018,智东西,2018-3-28
[16] 华为大转型!AI战略重磅发布,两颗AI芯片问世,算力超谷歌英伟达!,新智元,2018-10-10
[17] 华为秘密“达芬奇计划”首曝光!自研AI芯片或重创英伟达,新智元,2018-7-13
[18] 独角兽寒武纪已生变数,中国AI芯片抢跑者前路未明,DeepTech深科技,2018-10-11
[19] 甲小姐对话陈天石:AI芯片市场广阔,寒武纪朋友遍天下,甲子光年,2018-10-12
[20] 清华魏少军:大部分AI芯片创业者将成为这场变革中的先烈,AI科技大本营,2018-3-25
[21] 人工智能芯片行业深度研究,天风证券,2017-11-29
[22] 碾压华为苹果的AI芯片问世!高通发布全球首款5G芯片骁龙855,新智元,2018-12-5
#专栏作家#
hanniman,人人都是产品经理专栏作家,前腾讯、现创业公司PM;专注于人工智能领域的产品化研究,关注人机交互(特别是语音交互)在手机、机器人、智能汽车、智能家居、AR/VR等前沿场景的可行性和产品体验;擅长对创业团队管理、个人成长提出实战型的建议方案;知乎/简书/微博帐号,均为hanniman。
本文原创发布于人人都是产品经理,未经许可,不得转载。
题图来自Unsplash,基于CC0协议









结构清晰,逻辑清楚,佩服!
还是看不懂···················