
 起点课堂会员权益
起点课堂会员权益
完整的语音交互,需要经过这五个环节

本文将从“若琪,帮我设置明天早上8点的闹钟”出发,讲解智能音箱的工作流程,以及语音交互设计流程,同时也会讲解各类型AI产品经理/Ai运营的工作内容和考核指标,Enjoy。

2018年全球智能音箱销量达到1.2亿台,其中中国市场销量达到2200万台。
随着智能音箱的兴起,语音交互开始崛起,语音是最自然的交互形态之一,有着输入效率高、门槛低、方便解放双手以及能有效进行情感交流的优势。BBC预计2020年语音助手市场规模将达到近100亿美金。
如下图所示,一次完整的语音交互,包含:唤醒→ASR→NLP→TTS→Skill的流程。
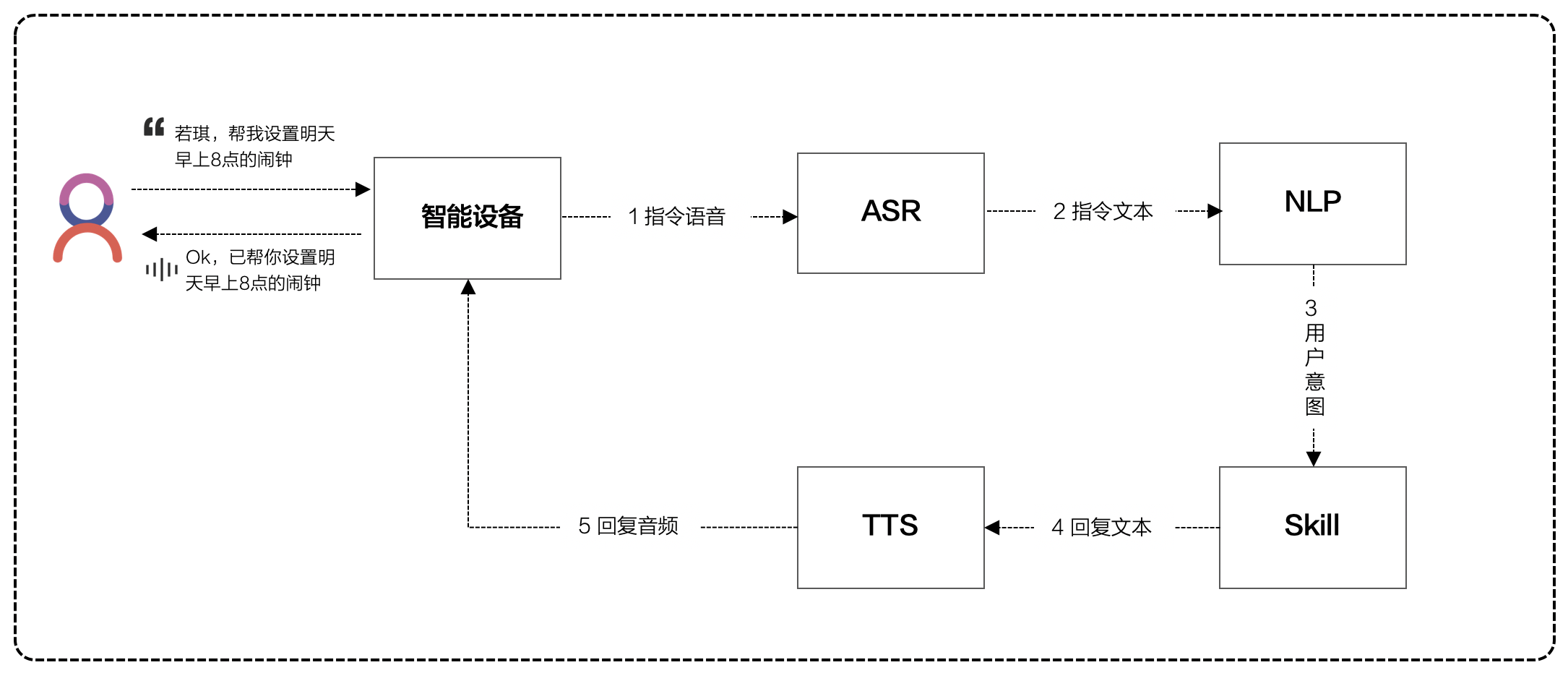
一、唤醒
智能音箱有别于智能手机的语音交互,需要先激活音箱,激活的办法有两类:
传统的方式是:通过按键激活,例如:锤子的大卫和希瑞音箱,增加了外设的按钮,可以点击按钮激活音箱进行说话。
业界的普遍做法是:通过设置激活词来唤醒音箱,例如:“天猫精灵”,“小爱同学”,“若琪”。
为什么唤醒词普遍是4音节,而不是中国人更习惯的3音节或者2音节?
这是因为音节越短,误唤醒的问题就会越严重。
误唤醒是指:设备被环境音错误激活。
误唤醒的压制是行业难题,除了模型优化,还有几种普遍的做法:
第一:云端2次校验——即将用户的语音上传到云端进行2次确认,再决定本地是否响应,但是带来的弊端就是唤醒响应时间被拉长。
一般设备的唤醒检测模块都是放在本地的,这是为了可以快速响应,本地响应可以将响应时间控制在300-700ms之间。如果进行云端2次确认,这个识别降低唤醒的响应时长,会被延长到900ms~1.2S之间,如果网络环境差,这个时间可能更久。
第二:从产品策略入手,一般白天偶尔的误唤醒用户都是可以理解的,或者说习以为常了。但是,如果是晚上睡觉时发生误唤醒,用户都是零容忍。
因此,一种做法是压制晚上的误唤醒,带来的问题是晚上唤醒的敏感度也同步降低,但是整体来看还是可以接受的。
唤醒词还承载了另外一个功能那就是声纹检测。业内的普遍做法是基于唤醒词的校对来判断用户身份,当然也有基于用户指令语句来是别的。
但是,目前业内普遍声纹识别的准确率不是特别高,当用户感冒、变音调,声纹识别就会失效,因此声纹在智能音箱的应用就非常受限。除了声纹支付,只能应用于对召回率要求不高的应用场景。
进阶知识点:
智能仲裁:当家庭有多台设备时,同时唤醒最好只有一台设备应答,这时候需要感知用户所在空间,以及距离设备的距离,选择合适的一台设备做应答并执行后续指令。
算法产品经理职责:
核心的职责是了解当前算法的能力和边界,提出产品侧解决方案去放大算法能力或者规避算法缺陷,例如:设置夜间模式压制误唤醒,增加用户自定义唤醒词提升用户侧的体验。
唤醒的衡量指标:
唤醒率、误唤醒率、唤醒响应时长。
而且,会进一步拆分为:安静环境下、噪音环境下、AEC环境下,用户端正常唤醒,快读唤醒,One-shot唤醒,分别去看以上3个指标。
二、ASR
ASR——自动语音识别:用于将声学语音进行分析,并得到对应的文字或拼音信息。
语音识别系统一般分为:训练和解码两阶段。
训练:通过大量标注的语音数据训练数学模型,通过大量标注的文本数据训练语言模型。
市场上主流的声学训练模型有:时序连接分类(CTC)和卷积递归神经网络(CRNN)。
解码:通过声学和语言模型将语音数据识别成文字。
声学模型可以理解为是对发生的建模,它能够把语音输入转换成声学表示的输入,更准确的说是给出语音属于某个声学符号的概率。
语言模型的作用可以简单理解为消解多音字问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
为了提供特定内容的识别率,一般都会提供热词服务,配置的热词内容实时生效,并且会提升ASR结果的识别权重,在一定程度上提高ASR识别的准确率。
进阶知识点:
- 寻向/声源定位:一般音箱的设计都是多麦克风,例如:4麦、6麦,呈线性或环形布局。寻向的作用就是判断用户方向,然后用用户方向的麦克风采集语音数据,保证语音的数据是最清晰的。
- 降噪:当有环境音时,需要对环境音进行消除,提高算法识别准确率。
- AEC:回音消除,如果当前设备既在使用Player进行播放,同时又使用Mic进行拾音,那MIc就会将自己播放出去的声音给重拾回来。这时为了避免影响算法识别结果,需要对回音进行消除。
- VAD:语音端点检查,使用音频特征等进行分析,确定人声的开始和结束时间点。
算法运营岗位职责:
除了算法,负责ASR优化的一般是运营,主要职责是ASR改写——即当发现线上一些语音总是识别成错误的结果时,可以强制将错误的结果纠正为正确的,以便在短期满足用户诉求。同时纠正的语料也会作为后面算法迭代的素材。
词错误率WER:一般作为语音识别系统中常用的评估标准。
三、NLP
NLP——自然语言处理:用于将用户的指令转换为结构化的、机器可以理解的语言。
NLP的工作逻辑是:将用户的指令进行Domain(领域)→Intent(意图)→Slot(词槽)三级拆分。
以“帮我设置一个明天早上8点的闹钟”为例:该指令命中的领域是“闹钟”,意图是“新建闹钟”,词槽是“明天8点”。
这样,就将用户的意图拆分成机器可以处理的语言。
算法运营岗位职责:
除了算法,负责ASR优化的一般是运营,主要职责是NLP说法和词表扩充。
词错误率WER:一般作为语音识别系统中常用的评估标准。
四、TTS
TTS——语音合成:即将从文本转换成语音,让机器说话。
TTS业内普遍使用两种做法:一种是拼接法,一种是参数法。
1. 拼接法
从事先录制的大量语音中,选择所需的基本发音单位拼接而成。
优点:语音的自然度很好。
缺点:成本太高,费用成本要上百万。
2. 参数法
使用统计模型来产生语音参数并转化成波形。
优点:成本低,一般价格在20万~60万不等。
缺点:发音的自然度没有拼接法好。
但是随着模型的不断优化,现在参数法的效果已经非常好了,因此业内使用参数法的越来越多。
五、Skill
Skiil,技能,也即AI时代的APP。
Skill的作用就是:处理NLP界定的用户意图,做出符合用户预期的反馈。
语音skill的设计与产品APP差别很大,笔者经过一段时间的积累,总结了一下原则供参考:
1. 设计原则
原则1:增加回复的多样性——高频的指令尽可能增加多的回复TTS语句,避免用户反复听到相同的回复。
原则2:重要信息后置——一般语音回复尤其是当用户在开车的过程中,需要将重要信息放在后面,因为心理学上有个“时近效应”,听觉刺激往往排在后面的影响力更大。
原则3:合理的简洁——用户可感知时简洁回复,用户不可感知时完整回复。
假如用户指令“停止播放”,这时候只需一个提示音或者一个简答的回复“好的”。
但是,如果用户的指令是“帮我设置一个明天早上8点的闹钟”,回复就需要是完整的,例如:“已帮你设置好明天早上8点的闹钟”,否则用户会没安全感,不知道你设置的到底对不对,如果不对,那带来的风险是很大的,所以一定要完整回复。
2. 建立流程
Skill的建立流程如下:
Step1:定义用户特征及使用场景。
Step2:定义产品人设。
Step3:收集用户意图并编写语义协议,包含Intent、slots的定义。例如建立一个“添加闹钟”的意图,slotes包含“DateTime”,表示的是具体的时间点。
Step4:撰写TTS文案,也即用户指令处理之后需要给与用户适当的反馈,例如:反馈语是“ok,我会再明天早上8点准时叫你起床”。
Step5:业务逻辑设计,例如:当用户深夜过了12点,说“帮我设置明天12点的闹钟”,大概率是想设置今天上午8点的闹钟。因此,可以直接设置成今天上午8点的闹钟,但是要明确告知用户。
Step6:开发实现,数据观察。
3. Skill产品经理职责
- Skill的设计要完善覆盖用户所有的可能意图和说法,然后给出最恰当的回应。
- Skill活跃率或者留存率是Skill产品的核心考核目标。
以上。
作者:Jason(微信号Smart_Byte),Rokid AI 产品经理,前阿里资深产品经理。
本文由 @Jason 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash, 基于CC0协议

















这里写错啦。“一次完整的语音交互,包含:唤醒→ASR→NLP→TTS→Skill的流程。”应该是 唤醒→ASR→NLP→Skill→TTS
在上海找合作伙伴,金海
正好在做这个 用的就是NLP
哎呀,有几个小小的错别字哦~
嗷嗷,下次注意
你的微信加不到呢~我是华为小艺的产品助理
是微信公众号
您好,问下贵司语音识别是自己研发,还是和语音公司合作的(例如科大讯飞),还有大量繁琐的语音数据的标注是怎么完成啊
全部自主研发的
标注这一块有合作机会么
很好奇,负责ASR优化的一般是运营,主要职责是ASR改写。不懂这部分的运营工作量会大吗,前期是不是会很大
除了算法常规升级,运营的主要职责是通过ASR改写解决应急性的badcase。同时也为后面模型的优化提供素材。
写的很棒,我也是智能音响的产品经理,多交流