
 起点课堂会员权益
起点课堂会员权益今日头条:AI助力用户推荐(下篇)
在上篇中主要讲了AI助力实现智能推荐的原理流程和方法,在下篇中笔者将通过上手操作,来讨论具体落地的方法。

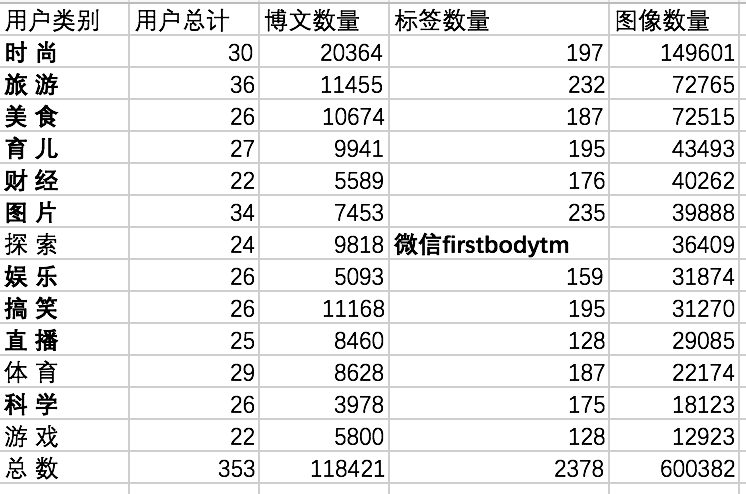
本篇笔者选择今日头条中的13个类别的信息作为上手对象,如:时尚、旅游、美食、育儿、财经、图片、探索、娱乐、搞笑、直播、体育、科学等,分别通过抽取粉丝数超过百万以上的用户最近的文章、用户标签和分享的图像,最终在13个类别上获取了353个用户的ID号和URL,共爬取13个类别的600 382张图像,118 421条文章和 2378个用户标签作为数据集;然而13个类别的2378个用户标签中有1110个标签重复,所以删除重复之后,最终得到1286个不重复的用户标签。
由于本篇笔者的目的在于展示AI产品如何上手,so“探讨用户分享图、文章和用户标签中的语义概念是否能够表征用户的兴趣倾向,并比较单模型数据和多模型数据的推荐效果”,因此将353个用户分为13个类别,其中图像、文章和标签数据如下图:
文章数据处理过程如下:
主要是将13个类别的353个用户的文本数据获取后。
首先:对每个类别用户的文本进行去停用词;
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。
接着:再进行分词,笔者所采用的是Python里的jieba分词,分词完毕后对文章进行深度学习,然后得出每个用户下所有文章的64维特征向量,生成353个用户文章的特征向量;
标签数据处理:
再对用户标签数据处理过程主要是将13个类别的353个用户的2378个用户标签数据获取后,将重复的标签删除,最终得到 1286 个兴趣标签,1286 个兴趣标签通过程序生成1286 维度词袋模型;
图像数据处理:
图像数据处理主要使用残差网络(ResNET),ResNet模型获得过图像识别大赛冠军,通过深度残差网络对图像进行识别,在深度和精度上比传统的CNN可以获得更好的语义信息表达。笔者通过使用ResNet模型来构建50层的神经网络,获取1000维特征向量。
最后,将13个兴趣类别的3种数据类型的特征向量进行组合,每位用户生成2350维特征向量。
推荐系统配置设置:
不同数量好友的推荐,分析比较它们的精确率(Preci⁃sion)、召回率(Recall)和F1 值(F1-measure)变化情况。
(1)精确率测试结果与分析。
七组数据对比测试在不同好友推荐数目的情况下的精确率(Precision)数据记录,其相应的数据对比情况如下图:
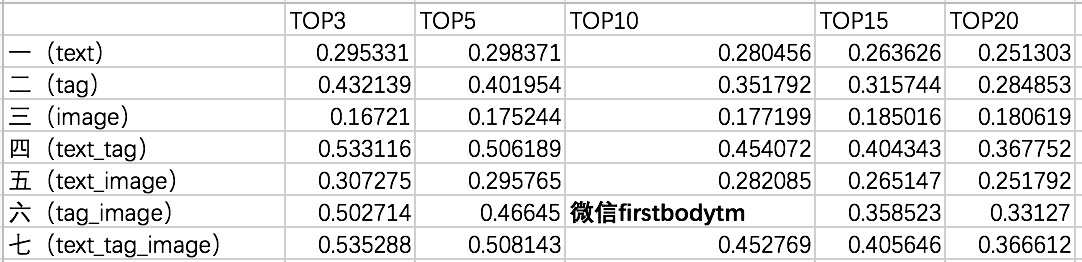
笔者根据上图测试的精确率可以得出以下三条结论:
①测试七文本、标签和图像三类数据的融合推荐效果及其推荐精确率要高于其它单模数据或其它组合数据推荐;但测试四基于文本和标签的融合推荐精确率和文本、标签和图像三类数据的融合推荐精确率相近似,相比其它的单模数据和多模数据的融合推荐效果要好;
②基于图像的好友推荐精确最低,说明图像在高维特征向量表达用户兴趣还比较模糊,但图像特征融合标签特征效果会好于其它单模特征;
③随着推荐好友数量的增加,单模和多模数据的推荐效果的精确率都在逐步降低。
(2)七组测试数据的召回率测试结果与分析。
七组数据对比测试在不同好友推荐数目的情况下的召回率(Recall)数据记录,其相应的数据对比情况如下图:
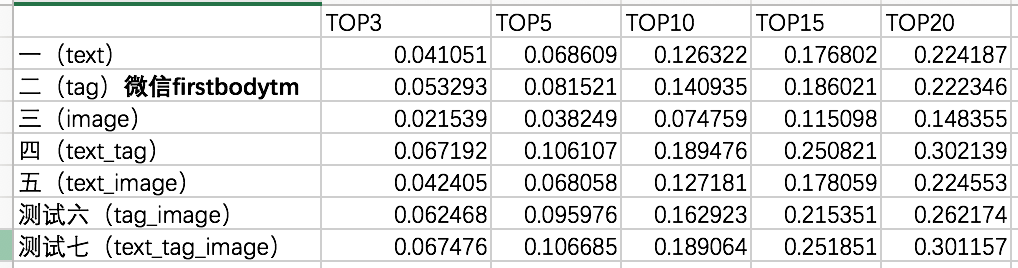
笔者根据上图测试召回率可以得出以下三条结论:
①测试七文本、标签和图像三类数据融合推荐效果的召回率要高于其它单模数据或其它组合数据的召回率;但测试四基于文本和标签的融合推荐效果的召回率和文本、标签和图像三类数据的融合推荐效果的召回率相近似,相比其它的单模数据和多模数据融合召回率效果要好;
②测试三基于图像的好友推荐召回率最低,说明图像在高维特征向量表达用户兴趣还比较模糊,但图像特征融合标签特征效果会好于其它单模特征;
③随着推荐好友数量的增加,单模和多模数据的召回率都在逐步增高。
(3)七组测试数据的F1值结果与分析。
七组数据对比测试在不同好友推荐数目的情况下的F1值(F1-Measure)数据记录,其相应的数据对比情况如下图:
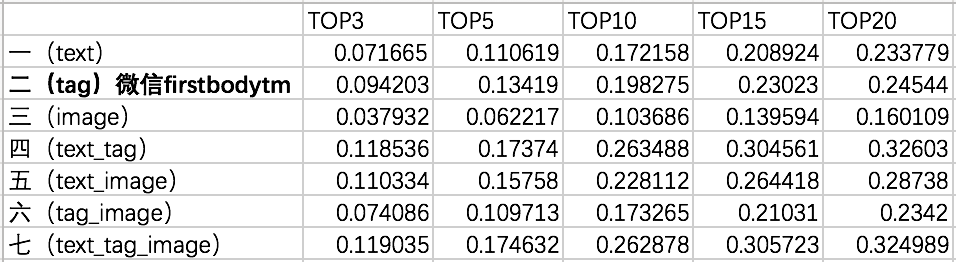
笔者根据测试的F1值可以得出以下三条结论:
①测试七文本、标签和图像三类数据的融合推荐效果及其推荐F1值要高于其它单模数据或其它组合数据推荐;但基于文本和标签的融合推荐F1值和文本、标签和图像三类数据的融合推荐F1值相近似,相比其它的单模数据和多模数据的融合推荐效果要好;
②基于图像的好友推荐F1值确最低,说明图像在高维特征向量表达用户兴趣还比较模糊,但图像特征融合标签特征效果会好于其它单模特征;
③随着推荐好友数量的增加,单模和多模数据的推荐效果的F1值都在逐步增高,但这种增高是随着好友的数量增加而缓慢增高。
总结:
在今日头条的产品落地中不仅将用户的文本、标签和图像特征融合进行推荐,也会将将用户的属性特征和社交关系特征融合进行好友推荐;
另外,用户的兴趣是多样性、可变性的,有时推荐系统还会加入情境感知信息,如:时间、情感、场景等。这也是今日头条产品重点迭代的一个方向。
最后:今日头条也好、抖音也好、多闪也好都是字节跳动旗下的明星产品,均为AI赋能助力的产品相信推荐系统会越来越融合跨行业和跨平台的推荐打法,突破数据孤岛。具体系统的知识可以见笔者的畅销书《AI赋能:AI重新定义产品经理》。
升华在以上例子中AI产品经理应该做的事是:
1. 停用词库的构建。
2. 明白关键词术语和意义例如:精确率、召回率及F1值,精确率(Precision),查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。F1值。F1值为算数平均数除以几何平均数。
3. 研究定义产品的分析对象、分析指标、能够应用分析结果。
如果你想系统化入门AI产品经理,掌握AI产品经理的落地工作方法,戳这里>http://996.pm/7bjab
#专栏作家#
连诗路,公众号:LineLian。人人都是产品经理专栏作家,《产品进化论:AI+时代产品经理的思维方法》一书作者,前阿里产品专家,希望与创业者多多交流。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议









花了5K大洋跟LineLian老师交流过AI产品三视图 正视 侧视和 俯视来看人工智能产品,受益良多,老师不仅是AI技术和产品设计和算法逻辑清晰,更多的是指导我们做产品的一种综合素质极高的模式
不错不错。