
 起点课堂会员权益
起点课堂会员权益知识图谱与自然语言处理的故事
你指尖跃动的代码,是我此生不变的信仰,唯我NLP永世长存。

从NLP和知识图谱说起

本人的主要领域是知识图谱的方向,但是自然语言处理是知识图谱是绕不开的话题,一种普遍看法是知识图谱是自然语言处理的基石,而知识图谱靠自然语言处理的应用落地。
为什么是这样呢?我们可以从两者的定义出发:
什么是知识图谱?
借鉴其中一个理解:起源于语义网络,主要的目标是用来描述真实世界中间存在的各种实体和概念,以及它们之间的关联关系。
什么是NLP?
也借鉴一个理解,机器接受用户自然语言形式的输入,并在内部通过人类所定义的算法进行加工、计算等系列操作,以模拟人类对自然语言的理解,并返回用户所期望的结果。
从上述描述中可以看到相近的几个词汇:“语义网络”、“自然语言”、“自然客观世界”。所以NLP和知识图谱是为了解决同一个目的: 让机器和人类有相同的思考理解能力,并且机器可以和人类进行拟人化的交互。
在实际应用中,知识图谱和NLP的目的也是相同的,比如:智能问答、翻译、推荐系统等。知识图谱的构建离不开NLP技术对于自然语言的抽取、NLP的应用离不开知识图谱的关联方分析和推理能力。
所以在研究知识图谱的过程中,自然语言处理是无法回避的领域。
想理解,先分词
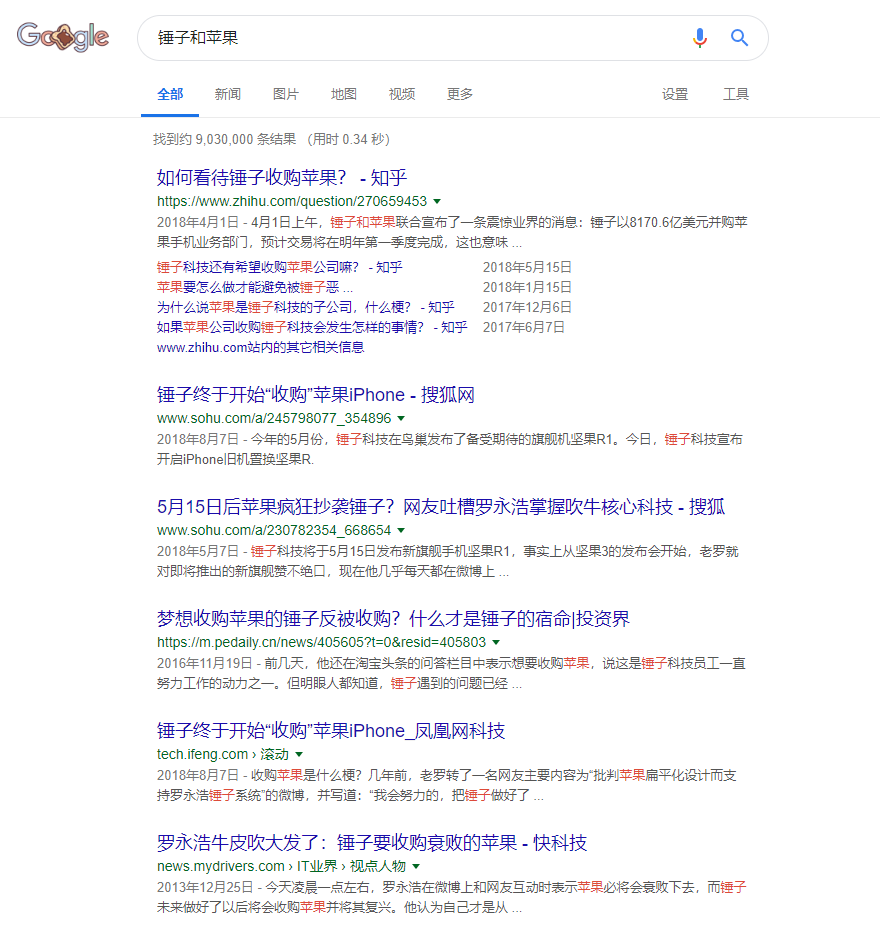
如果用搜索引擎搜索“苹果和锤子”, 你猜会不会出现一个河神问你想搜索的是金苹果还是金锤子。如果你回答你想搜索的是铁苹果,你就能获赠一个金锤子手机。
你可以用任何一个搜索引擎去试验,仅仅是搜索“苹果和锤子”这两个完全没有前后语境的词语,搜索返回的结果会全部都是关于“苹果手机”和“锤子手机”。 但是如果单独搜索“苹果”或者“锤子”,如果不是网站记录了搜索偏好,返回的结果里多少都会包含非手机的“苹果”和“锤子”。
出现这样情况的原因,是搜索网站的知识图谱里一定存在“手机”“苹果”“锤子”之间的关联关系,所以机器能够把三者之间建立联系并且返回结果。
如果搜索的是一句话呢?
“苹果和锤子哪个更好。”
那么机器可能首先要从这个句子中正确的提取出“苹果”和“锤子”两次词语了,而不是提取出“萍、果和、锤、子”。
所以搜索“苹果和锤子哪个更好”的时候,搜索引擎干了很多事情,其中至少包含了这两件事情: 理解输入、遍历图谱。其中,理解输入就是一个自然语言处理过程,这个过程大概可以分为:词法分析、句法分析、语义分析。
搜引擎收到输入,首先将每个句子切割为词语,然后进行词性标注,接着对标注过的句子进行命名实体识别,最后搜索实体间可能存在的关系。所以在对文句子进行命名实体识别之前,必须对进行分词和词性标注。
所以词法分析是自然语言处理的第一个环节,把词法分析细分步骤即为:分词、词性标注、命名实体识别和词义消歧。
其中命名实体和词义消歧是知识图谱构建的关键流程,而分词是词法分析最基本的任务。关于分词的算法当前已经比较成熟了,准确率基本可以达到90%以上了,而剩下不到10%却是技术落地应用的巨大鸿沟。出现这样的情况是因为在实际应用中对于分词准确度的要求极高,用一个常见的例子举例:“南京市长江大桥”,这里涉及到三个基本问题:
- 分词粒度:“长江大桥”是一个词还是两个词。
- 语境歧义:比如“南京市长江大桥”可以理解为“南京市/长江大桥”,,也可以理解为“南京/市长/江大桥”。
- 词典未录入:如果“江大桥”没有在词典里,是否能够判断出这是一个词语。
分词算法综述
如上所诉,分词是自然语言处理中最经典同时也是最基础的问题。而分词首先要面临的场景是不同的语言“分词”的重点是完全不同的。
对于英文等语言来说,句子中的词语是通过单词天然分割的,所以对这类语言来说更多工作是集中在实体识别、词性标注等。
对于像中文这样的语言来说,文章是由句子组成、句子是由词语组成、词语是由字组成,所以切割句子抽取词语是理解文章句子最基础的一步。
这里主要讨论中文分词的算法,但是中文定义一个句子中的词语是很难的。以前看到过一个调查是对以汉语为母语的人进行测试,对于句子中词语的认同率只有70%左右。人尚且如此,对于机器来说就更是一个巨大的挑战。
分词算法按照规则来说可以分为:按照字典的分词和按照字的分词。
按照技术发展来说可以分为:基于规则的分词、基于统计学的分词、基于神经网络的分词。
下面将介绍最基本的三种分词算法:
- 基于规则的方法:最大匹配分词算法;
- 基于统计的方法:n-gramn分词算法;
- 基于神经网络的方法:BiLSTM+CRF。
1. 最大匹配分词算法
最大匹配算法是基于词典的算法即首先要有一个词典作为语料库,所匹配到的词语是提前录入到词典中的词语。算法的基本原理其实很直接,按照现代正常的阅读习惯从左往右进行,去匹配可以匹配到的词典中最长词语,若组不了词的字则单独划分。
算法需要两个输入,一个是分词词典(已知的词语集合),另一个是需要被分词的句子。以下举一个简单的例子来说明匹配过程:
分词词典:{“今天”,”好吃的”,”吃”,”什么”}
待分词句子:今天吃什么?
找第一个词的分词过程:
今天吃什么 =>
今天吃什 =>
今天吃 =>
今天 => 得到词语:今天
上述例子是正向匹配,还可以进行逆向匹配,进一步可以结合最小切分和限定最大词语长度提高匹配的准确率。但是该算法在实际使用的准确率仍旧是很差的,因为很容易就构造出反例,比如:刚刚提到的“南京市长江大桥”,根据分词词典有可能得到“南京市长”这样的结果。另外一个问题是该算法依赖于已知的词典,如果出现新词不在词典里则无法得到正确的结果。
2. n-gramn 分词算法
N-Gram是一种基于统计语言模型的算法,利用概率判断词语的组成情况。算法基于一个前提:句子中包含常见词语的可能性会肯定大于包含生僻词的可能性,所以该算法的目的是“为分词寻找最有可能的结果”。
求概率最直接的方法就是数个数,比如对于刚刚的例子“南京市长江大桥”有各种分词方法:
- 南京/市/长江/大桥
- 南京/市/长江大桥
- 南京市/长江大桥
- 南京/市长/江/大桥
- 南京/市长/江大桥
- ……
每种分词在语料库中出现的次数为m,语料库的总数为n,则每种分词的概率为m/n。
上述的方法在理论上是没问题的,但是对于实际应用场景来说,语料库不可能包含所有的句子,所以,如何高效的数个数是问题关键。
该算法思想不复杂,但是介绍起来却要写很多,这里只大概描述下过程,详细算法介绍可以很轻松找到!
在介绍算法之前作如下两个定义:
- 词语序列:
- 链式规则:
现在我们要计算“南京市/长江/大桥”的概率,按照贝叶斯公式则有:
仔细想想上面的计算,其中:
纳尼?!P(“南京市” ,”长江” , “大桥”) 不就是我们要计算的概率么,要计算P(A)要先已知P(A)?!
废话这么多,终于轮到N-Gram算法上场了。该算法基于以下假设:第n个词w_n只与前面n-1个词有关,该假设也叫作马尔可夫假设。
N-Gram中的N是窗口长度,
n=1时,
n=2时,
n=3时,
比如n=2时,则
然后再用数数的方法就可以得到以上结果。
把所有分词可能用图的方式表示出来,就是求一个有向加权图的最短路径问题。概率最大的分词结果即为所得。在实际应用中还是会觉得计算空间很大,比如有5000个词语,那么2-gram就是 5000 * 5000个二维组合,但是相比于直接用贝叶斯公式也会小很多,另外还会采用数据平方式减少上述二维表的稀疏性。
N-Gram算法最典型应用是搜索引擎或者输入法的词语联想补全,输入前面几个字的时候,会自动联想出最有可能的接下来的词。
3. BiLSTM+CRF分词算法
该算法实际上是两个算法的合成,即BiLSTM和CRF算法。这两个算法,如果真的详细介绍起来会涉及很多基础知识,包括马尔科夫链、神经网络等。以后有机会详细写一篇博客来介绍两者的细节,这里暂时简单罗列下。
CRF想比较于传统统计学的方法的最大优势在于考虑了上下文场景,对多意词和词典未录入的词有更好的效果,但是效率比较低,需要的大量的训练和计算时间。
LSTM为RNN变种的一种,在一定程度上解决了RNN在训练过程中梯度消失和梯度爆炸的问题。双向(Bidirectional)循环神经网络分别从句子的开头和结尾开始对输入进行处理,将上下文信息进行编码,提升预测效果。相比于其它模型,可以更好的编码当前字等上下文信息。
基本步骤是:
- 标注序列;
- 双向LSTM网络预测标签;
- Viterbi算法求解最优路径。
BiLSTM-CRF是两种算法模型的结合,可以保证最终预测结果是有效的。算法输入是词嵌入向量,输出是每个单词对应的预测标签。
NLP技术工程化
语言理解是人工智能领域皇冠上的明珠。”
——比尔盖茨。
通常认为人工智能是机器从感知到认知的过程。在感知阶段,最知名的应该是计算机视觉技术。视觉感知在理论上已经达到了一个很成熟的阶段,不止能够识别物体图像,甚至还能预测物体的下一个动作。在应用上,视觉技术在大部分场景种对于准确度的要求并不会太严苛,相比于自然语言处理则是“差之毫厘谬之千里”。
在技术上,NLP的最难的问题是以下四类场景:问答、翻译、复述、文摘。
- 问答即人和机器进行聊天交互,聊天可以是语音识别也可以是文字交互,机器要能理解聊天内容,内容的情感,并且能够给出合适的回应,再进一步能够根据聊天内容进行自我学习增长知识。
- 翻译是机器要理解多种不同的语言,在语法语境语义上能够相互转化。
- 复述可以更加广义的理解为把一种结构的数据转化成另外一种结构。
- 文摘是将一大段内容进行抽象提炼,通过更少的内容概括更多的内容。
以上的应用场景会涉及一整套自然语言处理方法流程,包括: 词法分析、句法分析、文档分析、语义分析、分类、相似度匹配等。
将以上的基础问题包装成具体的业务场景,即为常见的:自动问答、纠错消歧、词典翻译、自动编文、标签分类、情感分析、推荐系统、爬虫系统等。
自然语言处理如何落地到具体应用?
个人认为当前对于NLP的应用落地来说最重要的是“两端问题”,即顶层产品和底层数据。在底层是否有面向垂直领域的足够大的语料库,在顶层是否有足够好的交互系统。
在底层,不管是自然语言处理还是知识图谱,多数努力的方向都是建立一个通用的知识库和词典等。
- 而在面向垂直领域则有很高的市场壁垒,一方面是基于数据安全和数据资产的原因,大部分数据都是非公开的,无法直接使用。
- 另外一方面是垂直领域建模需要有深入的业务理解,这也是需要在一个行业深耕的经验为基础。
通过针对具体的业务特点做定制化构造一个面向垂直领域的知识图谱,以及基于这个图谱的NLP应用,才能真正的提升相关业务的生产力。
在顶层,需要用产品将理论落地。除了产品本身符合正确的业务流程,更需要良好的交互来提升用户体验。比如智能客服应用,对于多轮交互肯定无法做到100%,但是可以通过友好的交互使用户愿意接受结果。如果交互做的不好,即便技术上准确率会很高也会被抱怨。
再比如:对于语音实施翻译来说,又会面临噪音、远场、口音等问题。所以将NLP技术落地会涉及很多定制化场景,除去技术,对于产品经理也提出了很高的要求。
有意思的是知识图谱被看作是人工智能的基石,而NLP被称作人工智能皇冠上的明珠。这句话足以体现两者间的互相依赖,知识图谱需要借助自然语言处理技术去构建图谱,而自然语言处理需要借助知识图谱完成推理。
技术算法是通用的,但是业务场景确是定制化的。产品经理对于技术落地需要做非常深入的思考,如何把理论技术工程化、产品化、最后商业化变现?
用技术讲故事的同时,要求更多的干货来提升业务目标。
作者:Eric ,数据产品经理。金融大数据方向,知识图谱工程化。
本文由 @Eric_Xie 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。















知识图谱需要借助自然语言处理技术去构建图谱,而自然语言处理需要借助知识图谱完成推理。
请问下实际落地的时候,彼此都需要对方才行,,那是先有哪个呢
大哥,如何申请转载
请问要转载到哪里呀?