
 起点课堂会员权益
起点课堂会员权益无人驾驶已经上路,未来将驶向何方?
由于人工智能的技术发展,很多领域开始了革命式创新,无人驾驶就是其中一个。本篇文章中作者介绍了无人驾驶的概念以及发展过程,并且通过分析无人驾驶的具体设计,预测了其未来发展趋势。

2019年在美国景城、旧金山、凤凰城、匹兹堡、亚利桑无人驾驶已经是人们生活的日常;
2017年7月5号百度AI开发者大会,百度创始人、董事长兼首席执行官李彦宏乘坐公司研发的无人驾驶汽车行驶在北京五环;
2019年滴滴网约自动驾驶车亮相世界人工智能大会;
可以说,无人驾驶已经上路了。
一、什么是真正的无人驾驶
什么算是无人驾驶,自动巡航算是无人驾驶吗?
自动驾驶是指让汽车自己拥有环境感知、路径规划并且自主实现车辆控制的技术,也就是用电子技术控制汽车进行的仿人驾驶。
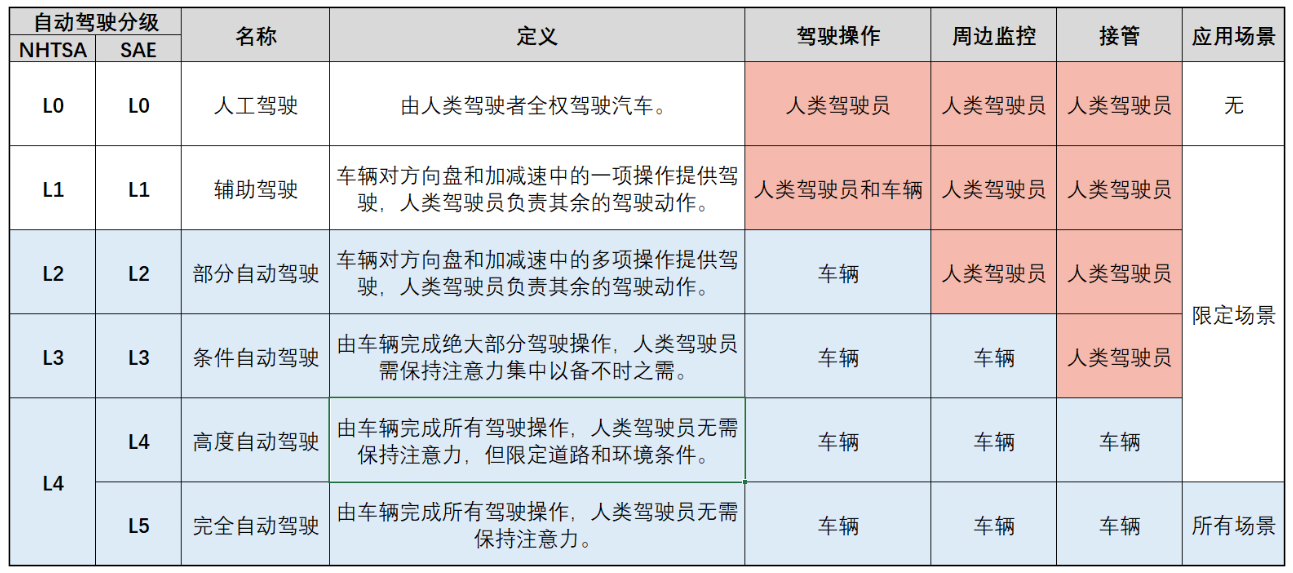
美国汽车工程师协会(SAE)根据系统对于车辆操控任务的把控程度,将自动驾驶技术分为 L0-L5 级L0 级无自动化功能。
在新闻报道中车厂会强调他们在L2-L3辅助驾驶系统的成果;科技创业公司则会强调L4是完全不同于L2-L3的新物种。
L2-L3级自动驾驶,驾驶员必须在驾驶座上,随时准备接管车;L4级自动驾驶——不要驾驶员,在限定环境中真正做到“无人”驾驶;而L5是指无人驾驶的最高级别,在任何场景任何天气下,都不需要人来操控。
二、无人驾驶的起源
2001年,美国开始了阿富汗战争,为了应对路边炸弹的大量伤亡,美国国会要求,在2015年,军方三分之一车辆必须进行无人驾驶。
2003年,伊拉克战争爆发,无人驾驶还没有进展。因此美国军方开启非常规操作思路——用无人驾驶赛车的方式,为获胜的团队提供100万美元的奖金,在选址上,也选择了与伊拉克战争地形相似的莫哈维沙漠。
2004年3月,第一届DARPA挑战赛寂寂无名,所有的团队都惨败而归。走的最远的卡内基梅隆团队,也没有走过全程的5%。那一年,大部分参赛者的思路是,用硬件改装汽车。
2005年的第二届DARPA挑战赛,这一次,去年参赛过的团队开始放弃主要在硬件上改装车,绝大部分团队都加上了激光雷达测距仪等传感器。那一年,激光雷达的测距范围在10米左右,而摄像头可以看到100米。
2007年,第三届DARPA挑战赛叫做“城市挑战赛”,这次比赛在美国乔治空军基地举行,除了沙漠路段,还增添了城市路段,挑战升级,奖金也翻一番到200万。这一次,激光雷达、摄像头、雷达,所有能配备的传感器都应用到比赛中。最终卡内基梅隆大学获得了冠军。
DARPA这场挑战赛,参赛的斯坦福与卡内基梅隆大学,成为美国无人驾驶行业的黄埔军校。
仅仅是举办了三届比赛,却对行业产生了深远的影响。从第一次所有团队都毫无经验,到第二次激光雷达的加入;到第三次计算机视觉与激光雷达都成为主流的解决方案。
直到今天,无人驾驶的研发也依然在借鉴过去的思路。
三、无人驾驶首先普及的应用场景
高度自动化驾驶将会让行车更安全,而且也有助于提升我们(乘客)的生活或工作效率。
同时,自动驾驶带来共乘共享的机制还能让车辆减少,都市的塞车和污染问题就能迎刃而解。
无人驾驶能够首先商业化场景有以下三类:
1. 无人驾驶出租车
无人驾驶出租车(Robotaxi)是无人驾驶出行中最核心的商业化落地场景之一,这也是现在滴滴等公司的研究方向。
2. L2辅助驾驶+L3自动驾驶
日常出行中,高速、环路上的驾驶往往占据了驾驶员大部分的出行时间。
由于高速、环路的场景相对单一,所需要面临的突发状况相比于Robotaxi少很多,只需要解决从上匝道到下匝道期间汽车的自动驾驶问题即可,因而成为众多Tier1和无人驾驶科技公司的发力方向。
3. 智能代客泊车
相信很多驾龄不短的司机都有过“开车五分钟,停车两小时”的可怕经历。很多时候,面对只有零星几个空车位的停车场,我们很容易像没头苍蝇一样碰运气找车位。
有时候找到了空车位,但周围的车停的东倒西歪,导致入口太窄,停进去很难不碰到周围的车,只能放弃继续寻找。
面对消费者找车位难、停车难、取车难的这些痛点,智能代客泊车(Automated Valet Parking,简称AVP)成为了一个重要应用场景。
相比于高速自动驾驶来说,低速的智能泊车系统可以不用配备成本较高传感器,比如毫米波雷达或激光雷达。实现成本较低。
四、无人驾驶汽车的基本构造
从定义上来讲,无人驾驶汽车是通过车载传感系统感知道路环境,自动规划行车路线并控制车辆到达预定目的地的智能汽车。
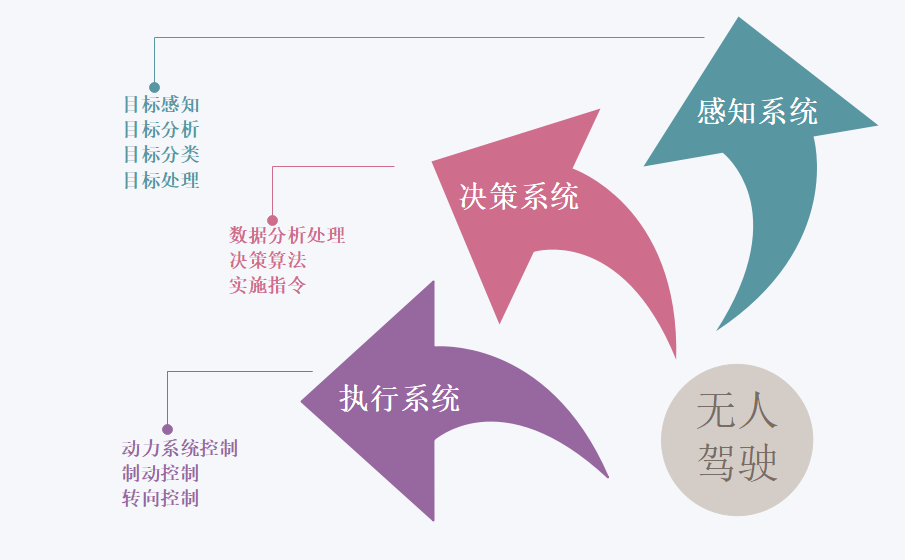
无人驾驶系统的核心可以概述为三个部分:感知、规划和控制。
1. 感知系统
感知层主要是通过各种传感器以及高精度地图实现,包含车辆的定位以及对物体的识别。
车辆的定位主要是通过光雷达(LiDar)、GPS、惯性传感器、高精度地图等等信息进行综合,从而得出车辆的准确位置,其定位精度甚至可达cm级别;
物体的识别主要采用光雷达以及双目摄像头实现;
2. 决策系统
决策层的输入包括感知层的信息、路径的规划以及控制层反馈回来的信息,通过增加学习算法下发决策指令。
决策指令包含:跟车、超车、加速、刹车、减速、转向、调头等等;
3. 执行系统
根据决策层下发的指令,控制层对车辆实施具体的控制,其中包括:油门的控制、刹车的控制、方向盘的控制以及档位的控制;
五、无人驾驶的传感器
1. 摄像头
主要用于车道线、交通标示牌、红绿灯以及车辆、行人检测,有检测信息全面、价格便宜的特定,但会受到雨雪天气和光照的影响。
由镜头、镜头模组、滤光片、CMOS/CCD、ISP、数据传输部分组成。
光线经过光学镜头和滤光片后聚焦到传感器上,通过CMOS或CCD集成电路将光信号转换成电信号,再经过图像处理器(ISP)转换成标准的RAW,RGB或YUV等格式的数字图像信号,通过数据传输接口传到计算机端。
2. 激光雷达
激光雷达是一类使用激光进行探测和测距的设备,它能够每秒钟向环境发送数百万光脉冲,它的内部是一种旋转的结构,这使得激光雷达能够实时的建立起周围环境的3维地图。
激光雷达使用的技术是飞行时间法(Time of Flight)根据光线遇到障碍的折返时间计算距离。为了覆盖一定角度范围需要进行角度扫描,从而出现了各种扫描原理。
主要分为:同轴旋转、棱镜旋转、MEMS扫描、相位式、闪烁式。激光雷达不光用于感知,也应用于高精度地图的测绘和定位,是公认L3级以上自动驾驶必不可少的传感器。
3. 毫米波雷达
主要用于交通车辆的检测,检测速度快、准确,不易受到天气影响,对车道线交通标志等无法检测。
毫米波雷达由芯片、天线、算法共同组成,基本原理是发射一束电磁波,观察回波与入射波的差异来计算距离、速度等。成像精度的衡量指标为距离探测精度、角分辨率、速度差分辨率。
毫米波频率越高,带宽越宽,成像约精细,主要分为77GHz和24GHz两种类型 。
4. 组合导航
GNSS板卡通过天线接收所有可见GPS卫星和RTK的信号后,进行解译和计算得到自身的空间位置。
当车辆通过遂道或行驶在高耸的楼群间的街道时,这种信号盲区由于信号受遮挡而不能实施导航的风险,就需要融合INS的信息;
INS具有全天候、完全自主、不受外界干扰、可以提供全导航参数(位置、速度、姿态)等优点,组合之后能达到比两个独立运行的最好性能还要好的定位测姿性能。
六、计算机视觉的应用
无人驾驶的摄像头会采集到图像素材,图像可以包含丰富的颜色信息,可以识别各种精细的类别,但是在黑暗中无法使用;激光可以在黑暗或强光中使用,但是雨天无法正常工作。
目前不存在一种传感器可以满足不同的使用场景,所以目前业界通常会通过传感器融合的方式来提高准确率,也能够弥补缺点。
由于摄像头数据(图片)包含丰富的颜色信息,所以对于精细的障碍物类别识别、信号灯检测、车道线检测、交通标志检测等问题就需要依赖计算机视觉技术。
无人驾驶中的目标检测与学术界中标准的目标检测问题有一个很大的区别,就是距离。无人车在行驶时只知道前面有一个障碍物是没有意义的,还需要知道这个障碍物的距离,也就是这个障碍物的3D坐标,这样在做决策规划时,才可以知道要用怎样的行驶路线来避开这些障碍物。
为了理解点云信息,通常来说,我们对点云数据进行两步操作:分割(Segmentation)和分类(Classification)。
其中,分割是为了将点云图中离散的点聚类成若干个整体,而分类则是区分出这些整体属于哪一个类别(比如说行人,车辆以及障碍物)。
分割算法可以被分类如下几类:
- 基于边的方法,例如梯度过滤等;
- 基于区域的方法,这类方法使用区域特征对邻近点进行聚类,聚类的依据是使用一些指定的标准(如欧几里得距离,表面法线等),这类方法通常是先在点云中选取若干种子点(seed points),然后使用指定的标准从这些种子点出发对邻近点进行聚类;
- 参数方法,这类方法使用预先定义的模型去拟合点云,常见的方法包括随机样本一致性方法(Random Sample Consensus,RANSAC )和霍夫变换(Hough Transform,HT);
- 基于属性的方法,首先计算每个点的属性,然后对属性相关联的点进行聚类的方法;
- 基于图的方法;
- 基于机器学习的方法;
分割技术在无人驾驶中比较主要的应用就是可行驶区域识别。可行驶区域可以定义成机动车行驶区域,或者当前车道区域等。
由于这种区域通常是不规则多边形,所以分割是一种较好的解决办法。与检测相同的是,这里的分割同样需要计算这个区域的三维坐标。
对于距离信息的计算有多种计算方式:
- 激光测距,原理是根据激光反射回的时间计算距离。这种方式计算出的距离是最准的,但是计算的输出频率依赖于激光本身的频率,一般激光是 10Hz;
- 单目深度估计,原理是输入是单目相机的图片,然后用深度估计的 CNN 模型进行预测,输出每个像素点的深度。这种方式优点是频率可以较高,缺点是估出的深度误差比较大。
- 结构光测距,原理是相机发出一种独特结构的结构光,根据返回的光的偏振等特点,计算每个像素点的距离。这种方式主要缺点是结构光受自然光影响较大,所以在室外难以使用。
- 双目测距,原理是根据两个镜头看到的微小差别,根据两个镜头之间的距离,计算物体的距离。这种方式缺点是计算远处物体的距离误差较大。
- 根据相机内参计算,原理跟小孔成像类似。图片中的每个点可以根据相机内参转化为空间中的一条线,所以对于固定高度的一个平面,可以求交点计算距离。通常应用时固定平面使用地面,即我们可以知道图片中每个地面上的点的精确距离。这种计算方式在相机内参准确的情况下精度极高,但是只能针对固定高度的平面。
近年来深度学习的突破,使得基于图像和深度学习的感知技术在环境感知中发挥了越来越重要的作用;
借助人工智能,我们已经不再局限于感知障碍物,而逐渐变成理解障碍物是什么,理解场景,甚至预测目标障碍物的行为,使得无人驾驶的安全系数更高。
总结
尽管无人驾驶起源于美国,现在国内也是如火如荼,但是中美两国的商业化落地走了不一样的两条路,美国公司更重科研和通用,中国公司们则多在研究低速、场景化的无人驾驶实现路径。
有网友发帖爆出,Model 3在行驶中开启自动驾驶系统,如果车辆进入到立交桥的车辆阴影区。而且前面有跟车;就会出现“突然刹车”状况。
自动驾驶工程师将这种情况称之为“幽灵刹车”,而且出现了第一起无人驾驶“杀人”事件,但这都是无人驾驶发展的必经之路。
如果要问“无人驾驶还要多久实现?”
科学家说“50年,不,100年”;投资人认为2050年或许可以;
而谷歌早年无人驾驶项目的实际控制人是克里斯·厄姆森(Chris Urmson)在演讲中说:“无人驾驶真正实现还要30年。”
你觉得多久能实现?
作者:老张,宜信集团保险事业部智能保险产品负责人,运营军师联盟创始人之一,《运营实战手册》作者之一。
本文由 @老张 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









场景
分级
结构
传感器:摄像头、激光雷达、毫米波雷达、导航、高精地图&GPS
计算机视觉
场景
分级
结构
传感器
看了,可以入个门
基于特定场景的有限度无人驾驶应用可能是一个比较好方向,避免了广义上无人驾驶的通与博,而将无人驾驶狭义化聚焦到某个特定的场景,降低技术研发难度,实现无人驾驶的逐步落地。低速下的无人驾驶泊车就是很好的例子。
内行人看水文,外行人看特高大上
一个厨师不看菜谱,研究上兵法了
不懂兵法的厨师不是好司机