
 起点课堂会员权益
起点课堂会员权益机器的深度学习究竟有多“深”?
每次提起深度学习,没有接触过的人会处于一种模糊臆想状态,认为其遥不可及。本文旨在摘下深度学习“高大上”的面纱,用一些简化的模型和通俗的比喻阐述其中的概念。

深度学习由来
1980年福岛邦彦提出的感知机,但由于计算代价过大,,并且“神经网络”这个名词听起来和生物相关,投资者们纷纷拒绝,导致未能进行实际的应用。
经过一段漫长的沉寂与暗中生长,2006年Geoffrey Hinton等人在Science杂志上发表Deep Belief Networks的文章。为了能更好地骗经忽悠信徒,率先使用了“深度”这个词,从此开启了深度神经网络的新时代。
深度学习的本源其实就是神经网络的在机器学习中的应用,它是机器学习的子集,如下图:
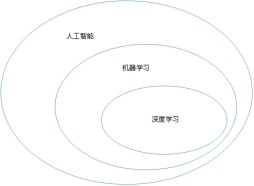
机器学习
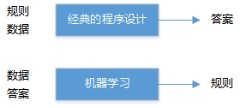
我们日常做数学题,是已知公式(规则),拿到题目(数据)去求答案;机器学习正好相反,它是给出数据和答案,需要机器去学习规则。
机器学习,尤其是深度学习,呈现出相对较少的数学理论,并且是以工程为向导的。
这是一门需要上手实践的科学,想法更多地是靠实践来证明,而不是靠理论推导。
机器学习分类:
- 无监督式学习(回归、分类)
- 有监督式学习(回归、分类)
- 半监督式学习(聚簇)
我们用养孩子的比喻来理解机器学习。
无监督式学习:孩子生出来直接散养,让孩子自己去面对世界建立礼义廉耻的价值观。把小孩和猫咪狗狗放在一块,经过一段时间,他会知道猫和狗是不同类型的东西,但没有人为引导,他不知道“猫”“狗”这样明确的定义。
由于事物具有多面性和复杂性的特点,仅通过有限的特征进行无监督式学习,容易出现与人类期望不符的结果,例如“长头发的人和长头发的狗”,如下图。这种方式是把具有相似性的事物归为一类(聚簇),分离结果只能通过特征的表象,缺点是结果容易跑偏,不符合期望。

(图片来源于网络)
有监督式学习:和无监督式学习相反,孩子出生后,虎爸虎妈手把手教学,兴趣班叠加补习班,任何事情都直接给出正确答案。
经过一系列应试教育,孩子成绩非常优秀(有监督学习的识别率普遍比无监督高许多)。但一旦遇到稍微超纲的问题,立马懵逼,这就是“过拟合”。而且,标签的获取常常需要极大的人工工作量,所以这种方式多用于有明确结果的数据有限的集合。
半监督式学习介于以上两者之间,小时候亲力亲为教导小孩,长大后让他基于已有的基本伦理和社会道德去接触大千世界。
所以,半监督式学习会有小部分已标注的训练集用于初始化学习,而留下一大部分未标注的训练数据让其自我学习。
深度学习
先回忆下中学的生物知识,神经反射接受信息的过程:感受器(肌肉)->反射弧->中枢神经系统。
我们识别一个人通过模糊到具体的特征,如衣着、头发、脸、眼睛、眉毛等特征,每个特征由一个神经元判断,深度学习就是通过一个个特征组不断学习识别出事物。
深度学习的“深”相对“浅”而言,优点是慢慢深入,前期容易筛选出有用的数据集,结果较准确。
如文章开头所说,深度学习是神经网络的在机器学习中的应用,其技术定义:学习数据表示的多级方法。也可以把深度网络看做多级信息蒸馏操作:信息穿过连续的过滤器,其纯度越来越高(即对任务的帮助越来越大),即权重越高。
权重怎么理解?
假设我们通过衣着判断性别,分为四类:穿裤子的女生、穿裙子的女生、穿裤子的男生、穿裙子的男生。通过日常经验知道,穿裙子较大概率是女生,所以资源不应该平均分配,也就是权重不同。
深度网络可以先提取“衣着”作为一层神经元的筛选,如果恰好筛选出为裙子,那么在筛选出来的集合里,我们已经可以大概率的认为这个样本90%的概率是女性了。
人会根据外界反馈调节自身的状态,深度学习也是。在深度学习中,衡量实际与期望误差的函数称为损失函数,根据损失函数的损失值反过来优化调整权重,以达到局部最优解。
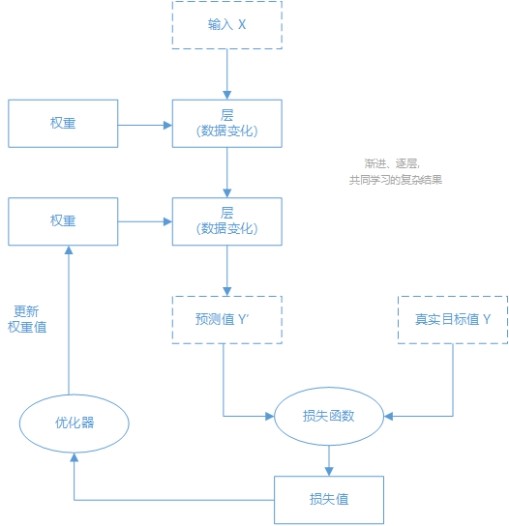
(深度学习的“学习”方式)
常见的深度学习模型:
- 有监督的神经网络
- 神经网络(Artificial Neural Networks)和深度神经网络(Deep Neural Networks),ANN&DNN
- 循环神经网络(Recurrent Neural Networks)和递归神经网络(Recursive Neural Networks),RNN
- 卷积网络(Convolutional Neural Networks),CNN
- 无监督的神经网络
- 深度生成模型(Deep Generative Models),DGM
- 玻尔兹曼机(Boltzmann Machines)和受限玻尔兹曼机(Restricted Boltzmann Machines),BM&RBM
- 深度信念网络(Deep Belief Neural Networks),DBNN
- 生成式对抗网络(Generative Adversarial Networks),GAN
不同的深度学习模型有自身的优缺点,有的擅长处理分类任务,有的擅长处理存在前后依赖关系、有序列关系的数据,有的擅长处理格状结构化的数据等等,开发会按需选择。
对常见的损失函数“平方误差函数”、权重的自我学习“梯度下降法”(寻找局部最优解)、不同类型的深度学习感兴趣的朋友可以在知乎找资料或阅读一些相关书籍。
深度学习应用举例
刷资讯APP时,低俗、标题党等文章易吸引眼球但体验差,这类内容若泛滥会严重伤害用户体验,所以对这类内容应该进行打压,深度学习可以帮上忙。
以低俗识别为例,俗即“庸俗、低俗、媚俗”,指某人某事不入流、情趣低下或微色情、low等,社会、情感、搞笑、娱乐等类别特别容易出现,低俗内容过多会影响阅读体验和流量生态的良性循环。
如何应用深度学习找出低俗内容呢?
第一步:定义低俗和制定标准(case辅助)
第二步:给机器提供种子词(具有分值的关键词)+分类等特征+部分人为规则+训练集(标题+摘要+正文等文本)
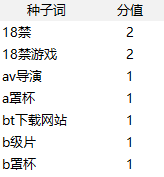
(种子词示例)

(训练集正样本示例)
第三步:机器深度学习和调参
例如采用CNN(卷积神经网络),深度学习中根据损失函数调整特征权重或训练样本。
第四步:验证集的效果测评
低俗文章的识别属于二分类评估,每个评估对象有唯一的结果,YES或NO。评估留意三大指标:准确率,精确率,召回率。
- 准确率:机器识别正确的样本数/样本总数(备注:正确识别包含把低俗样本识别为色情,把非低俗样本识别为非低俗两种情况);
- 精确率:机器正确识别出的低俗样本数总和/机器识别出的低俗样本总;
- 召回率:机器正确识别出的低俗样本数总和/低俗样本总数。

(以上数据仅做理论说明,不做实际参考)
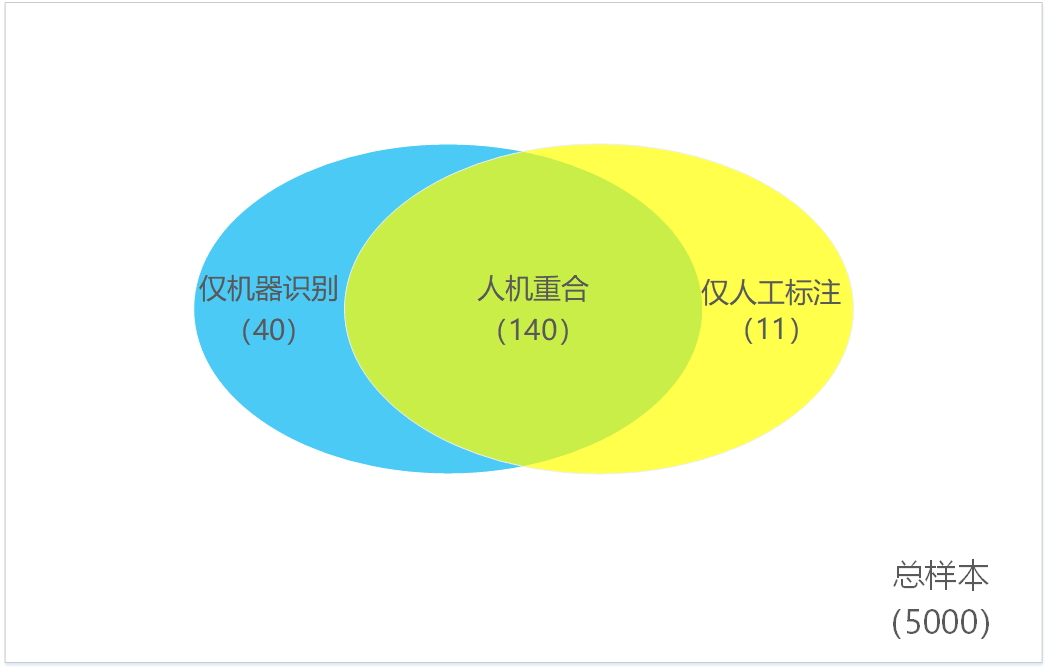
- 准确率=(5000-40-11)/5000=98.98%
- 精确率=140/180=77.78%
- 召回率=140/151=92.72%
低俗样本对于大盘来说,浓度很低,所以,评估准确率没有多大意义,更主要是看精确率和召回率。更多经典例子来自疾病试纸和验孕试纸(有兴趣的朋友可以查阅一下),所以统计的时候需要注意本体的对象。
第五步:上线或反馈badcase
当模型效果达预期(召回率和精确率呈现负相关,最佳组合可用 F Score求得,见文末)即可上线做“苦工”,若不达预期,根据badcase继续优化。
附:F Score,[0,1],值越大表示效果越好
F1 Score:召回率和精确率同等重要
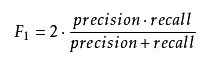
Fβ Score:召回率和精确率不同等重要
- F2:召回率的重要程度是准确率的2倍
- F0.5:召回率的重要程度是准确率的一半
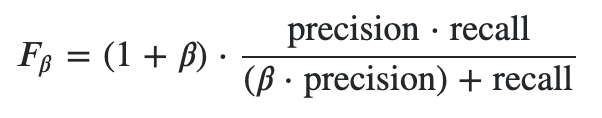
(β大于0)
关于F Score,详细可查阅:https://stats.stackexchange.com/questions/221997/why-f-beta-score-define-beta-like-that/221999#221999
参考文献:《Deep Learning with Python》[美]弗朗索瓦·肖莱 著;张亮 译
本文由 @张小喵Miu 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。










666