
 起点课堂会员权益
起点课堂会员权益如何用 AI 技术保护隐私安全?
在 AI 技术与相关产品高速发展的时代,大量用户隐私未经同意而被用于 AI 机器学习中,危害用户隐私安全。而 国内外 AI 巨头也意识到这一点,并积极用 AI 技术制定出保护隐私安全的产品。

一、隐私
我们处在一个智能变革的时代,人工智能技术正在“赋能”各行各业。大数据就像新能源, AI 算法就像发动机,装载了大数据和人工智能技术的企业就像搭上了一班通往未来的快速列车,把竞争对手远远地甩在后面。
然而,这样的快速发展不是没有代价的——
我们每个人的手机号、电子邮箱、家庭地址和公司地址经纬度坐标、手机识别码、消费记录、APP使用记录、上网浏览记录、搜索引擎结果的点击习惯、刷脸记录、指纹、心跳等等这些信息都是我们不愿意轻易给出的隐私数据,但在 AI 时代,这很可能已经成为某个公司用来训练 AI 算法的数据集中的一条。
正是众多不起眼的一条条个人隐私数据,构成了足够多的训练集,让 AI 从中学习到认知能力,让从未跟我们谋面的 AI 算法认识、了解我们,知道我们的喜好和动机,甚至还认识我们的家人、朋友。我们的隐私便是实现这些智能的“代价”。
当然,这个代价并不一定是你愿意拱手付出的。
那如何保护隐私?我不用行吗?
你以为关闭手机GPS就无法定位你的位置?你的手机还有陀螺仪、内置罗盘、气压计等装置,还是可以用来定位你的位置。只要使用手机,就不存在绝对的隐私保护。
对于很多手机应用来说,要么不用,用了就很难避免泄露隐私,比如很多APP必须用手机号注册,或者需要手机验证才能继续使用,还有的需要刷脸验证等等。那么,个人想保护隐私能做什么?什么也做不了,加上 AI 算法的黑盒性质,我们甚至对于 AI 背后的逻辑和动机一无所知。
二、监管
隐私保护靠个人防护真的很难实现,需要强有力的法律法规来限制。
2018年5月25日,欧盟的《通用数据保护条例》(GDPR)正式生效,这是在欧盟范围内的一个数据保护监管框架,这是目前最完善、最严格的隐私保护规定。根据DLA Piper公布的数据,在不到两年的时间内,GDPR已产生1.14亿欧元的罚款,其中开出的最大罚单是法国依据GDPR对谷歌罚款5000万欧元。
理由是谷歌在向用户定向发送广告时缺乏透明度、信息不足,且未获得用户有效许可。下图是GDPR生效以来至2020年1月份欧盟各个国家罚款的金额分布图。

对于企业,GDPR要求在收集用户的个人信息之前,必须以“简洁、透明且易懂的形式,清晰和平白的语言”向用户说明将收集用户的哪些信息、收集到的信息将如何进行存储、存储的信息将会被如何使用,并告知企业的联系方式。
对于个人,GDPR赋予数据主体七项数据权利:知情权、访问权、修正权、删除权(被遗忘权)、限制处理权(反对权)、可携带权、拒绝权。
目前GDPR在真实地影响到我们每个人的生活,最直观的影响就是当你浏览网页的时候,你会发现经常遇到网站弹出类似下图的提示,这是网站基于信息透明性的规定,向你征询信息收集的许可。
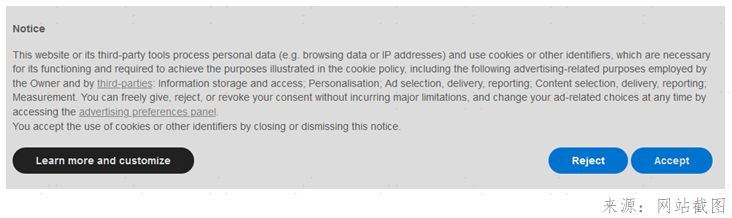
欧盟的GDPR具有全球影响力,它让用户对自己的个人数据有绝对的掌控权,让全球在发展新技术的同时必须开始关注隐私问题,世界各国已经纷纷出台自己的数据保护法规。
关于隐私保护,一切才刚刚开始。
欧盟在上个月正式启动了称为“打造欧洲数字未来”的新战略,打算通过制定一系列针对 AI 、隐私和安全的法规,成为 AI 发展的全球领导者。该战略的启动也被看成是在应对美国和中国的 AI 崛起。
可以预见,关于 AI 的隐私安全与监管将逐渐成为重点话题,实际上,就像欧盟委员会副主席Margrethe Vestager说的:
“人工智能本身并没有好坏之分,而是完全取决于人们为什么以及如何使用它。让我们尽可能做到最好,控制人工智能可能给我们的价值观带来的风险——不伤害,不歧视。”
保护隐私已经成为 AI 发展不可绕过的“槛”,是 AI 技术的难题,也是 AI 良性发展的契机。
三、趋势
可以说,保护隐私的各种法规的出台必然是未来不可避免的趋势,这势必让企业的数据收集、使用及流通的合规成本大幅增加,也容易让企业内部或者企业间形成数据孤岛问题,制约企业获取数据价值。因此,保护隐私的 AI 技术的落地使用成为 AI 领域最亟待实现的目标。
保护隐私的 AI 主要通过数据加密、分布式计算、边缘计算、机器学习等多种技术的结合来保护数据安全,近期比较热门的有Differential Privacy(差分隐私)、FederatedLearning(联邦学习,也叫联盟学习、联合学习、共享学习)。
保护隐私不是说完全不收集数据,而是要通过技术的手段防止个人隐私数据的泄露。
差分隐私是一种数学技术,比如,假设要分析数据集并计算其统计数据(例如数据的平均值、方差、中位数、众数等),如果通过查看输出,我们无法分辨原始数据集中是否包含了任何个体的数据,那么这种算法就被称为差异私有。
举个非常简单的例子,假设你的工作部门每个月都会用一个表格统计部门每个人的工资发放金额,除了制表人,别人无法查看这个表格,只能通过一个查询函数S知道这个表的总额。
某个月你调去了别的部门,那么别人就可以通过上个月表格A,和这个月表格B来知道你的工资,道理很简单,只需用S(A)减去S(B)。
B表格称为A表格的相邻数据集,它俩只相差一条数据,差分隐私技术就是要让相邻数据集的查询结果差不多,从而无法推出个人的信息来,这个差不多的程度可以看作隐私保护的力度。
苹果和Facebook已经使用这种方法来收集聚合数据,而不需要识别特定的用户。MITTechnology Review将差分隐私技术列为2020全球十大突破性技术之一。
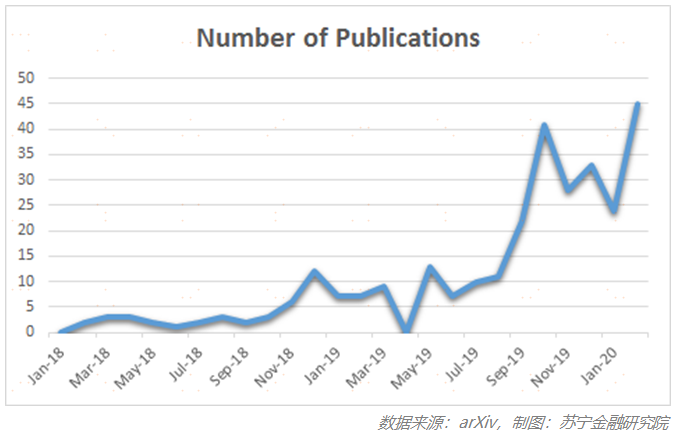
联邦学习采用了分布式机器学习方法,近年来越来越受欢迎,该技术假设用户数据不会被存储到中心化的服务器,而是私有的、保密的,仅存储在个人的边缘设备上,比如手机。
因此与传统机器学习方法相比,联邦学习从根本上增强了用户隐私。联邦学习不依赖从用户设备端收集的数据来训练,而是在用户移动设备端训练 AI 模型,然后将训练得到的参数信息传输回一个全局模型,这个过程不需要用户数据离开个人设备。
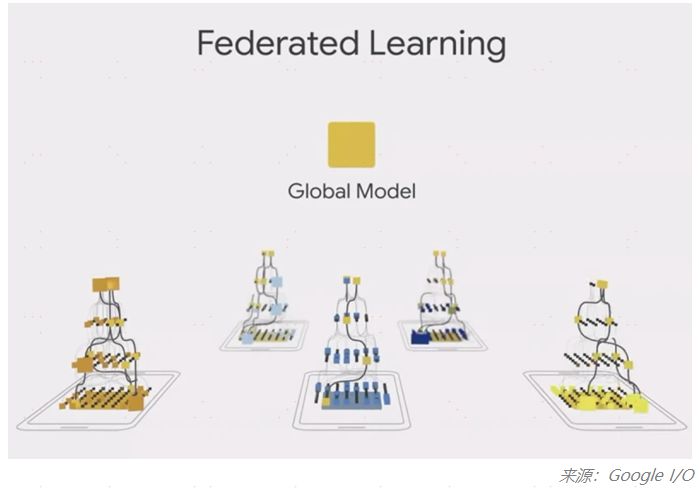
从近两年在arXiv(一个提交论文预印版的平台)上提交的论文数可以看出,该技术发展的快速趋势:
四、巨头的技术布局
从去年起全球最流行的两个机器学习框架,TensorFlow和PyTorch都增加了联邦学习等解决方案来保护隐私。
1. Google
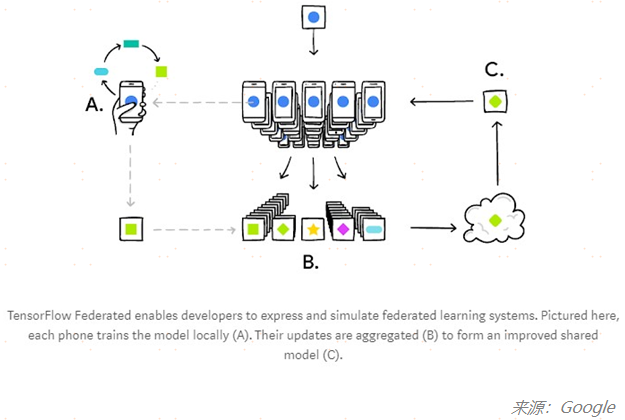
联邦学习的概念最早是由Google在2017年首次引入,去年又发布了TensorFlow Federated(TFF)框架,利用Tensorflow的机器学习框架简化联邦学习。
如下图所示,基于TFF框架搭建的学习模型在众多手机(如手机A)上进行本地化模型训练,更新权重并聚合(步骤B),进而更新提升后的全局模型(模型C),将全局模型再应用到各手机终端来提升算法应用效果。
2. Facebook
为了在保护隐私的机器学习领域取得进展,去年Facebook旗下优秀的深度学习框架PyTorch与OpenMined宣布开发一个联合平台的计划,以加速隐私保护技术的研究。
OpenMined是一个开源社区,专注于研究、开发和升级用于安全、保护隐私的 AI 工具。OpenMined发布了PySyft,是第一个用于构建安全和隐私保护的开源联邦学习框架。
PySyft很受欢迎,在Github已经拥有5.2k个Star,目前支持在主要的深度学习框架(PyTorch、Tensorflow)中用联邦学习、差分隐私和加密计算(如多方计算,同态加密),实现将隐私数据与模型训练解耦。
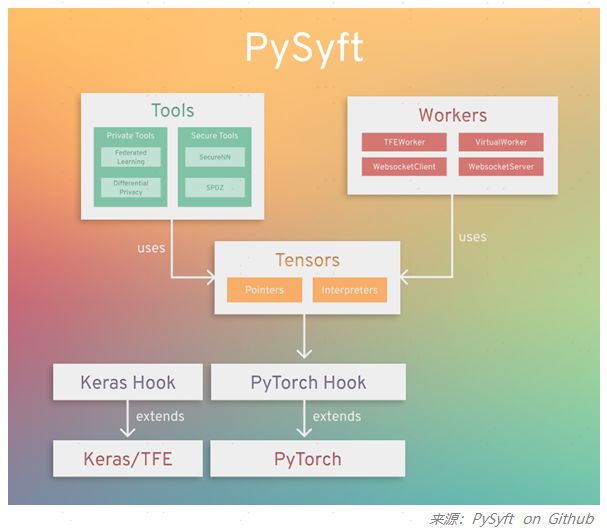
五、国内发展现状
国内的 AI 巨头们也早已开启保护隐私的技术布局,特别是金融领域,金融领域由于监管严格,数据的隐私性要求极高,因此,金融机构一方面在保护隐私数据方面面临技术难题,另一方面由于金融数据的孤立性,“数据孤岛”问题导致金融机构无法发挥出数据的真正价值。
国内多家金融机构以及金融科技公司已经尝试在获客、授信、风险控制等方面,利用联邦学习解决数据隐私的合规问题和数据分享的数据孤岛问题,最大化的发挥金融数据价值。
目前国内关于保护隐私的监管还不够成熟,个人和企业对于隐私保护的意识还不强。随着全球环境中对保护隐私的关注逐渐加强,以及保护隐私的 AI 技术的发展,我相信 AI 技术终究会向着更好的方向发展,希望通过科学家们的努力, AI 的黑盒不会是潘多拉之盒。
作者:李加庆,苏宁金融研究院研究员;公众号:苏宁财富资讯
本文由 @苏宁金融研究院 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


