
 起点课堂会员权益
起点课堂会员权益从算法到产品:NLP技术的应用演变
文章回顾了近几年NLP的发展历程,从项目实施的两个阶段中带我们梳理了NLP技术的应用演变。

第一个与大家分享的Case,基于NLP展开。分为3个部分,分别是NLP的发展、项目叙述、以及Lesson Learned。
讲述NLP的发展,是为了更好地理解这门技术,为项目的展开做铺垫。Lesson Learned是笔者总结整个项目下来自己的收获。
笔者本身并非计算机课班,对理论知识的理解难免不深刻,以及可能会有偏差,请大家不吝指教。
目录:
- NLP的发展
- 项目阐述
- Lesson Learned
一、NLP的发展
1.1 NLP的定义
The field of study that focuses on the interactions between human language and computers is called Natural Language Processing, or NLP for short. It sits at the intersection of computer science, artificial intelligence, and computational linguistics ( Wikipedia)
总结一下维基百科对NLP的定义, NLP关注人类语言与电脑的交互。
使用语言,我们可以精确地描绘出大脑中的想法与事实,我们可以倾诉我们的情绪,与朋友沟通。
电脑底层的状态,只有两个,分别为0和1。
那么,机器能不能懂人类语言呢?
1.2 NLP的发展历史
NLP的发展史,走过两个阶段。第一个阶段,由”鸟飞派“主导,第二个阶段,由”统计派“主导。
我们详细了解一下,这两个阶段区别,
阶段一,学术届对自然语言处理的理解为:要让机器完成翻译或者语音识别等只有人类才能做的事情,就必须先让计算机理解自然语言,而做到这一点就必须让计算机拥有类似我们人类这样的职能。这样的方法论被称为“鸟飞派”,也就是看鸟怎样飞,就能模仿鸟造出飞机。
阶段二,今天,机器翻译已经做得不错,而且有上亿人使用过,NLP领域取得如此成就的背后靠的都是数学,更准确地说,是靠统计。
阶段一到阶段二的转折时间点在1970年,推动技术路线转变的关键人物叫做弗里德里克. 贾里尼克和他领导的IBM华生实验室。(对IBM华生实验室感兴趣的朋友可以阅读吴军老师的《浪潮之巅》,书中有详细讲述。)
我们今天看到的与NLP有关的应用,其背后都是基于统计学。那么,当前NLP都有哪些应用呢?
1.3 目前NLP的主要应用
当前NLP在知识图谱、智能问答、机器翻译等领域,都得到了广泛的使用。
二、项目阐述
2.1 业务背景
说明:在项目阐述中,具体细节已经隐去。
客户是一家提供金融投融资数据库的科技公司。在其的产品线中,有一款产品叫做人物库,其中包括投资人库和创始人库。
- 创始人库供投资人查看,使用场景,当投资人考察是否要投资创业者,因此会关注创业者的学校(是否名校)、工作(大厂)、以及是否是连续创业者、是否获得荣誉,如“30 under 30”。
- 投资人库供创业者查看,使用场景:当创业者需要投资人,会考察投资人的投资情况。因此会关注投资者的学校(是否名校)、工作(大厂)、投资案例、投资风格等
我提供的服务,便是为这两条产品线服务。因为本项目主要关注,相关人物的履历信息,因此该项目代号为「人物履历信息抽取」。
需要抽取的人物履历信息,由5个部分组成:学校、工作、投资(案例)、创业经历、获取荣誉。
2.2 项目指标
项目指标包括算法指标与工程指标。
2.2.1 算法指标
算法层面,指标使用的是Recall和Precision。为了避免大家对这两个指标不太熟悉,我带大家一起回顾一下。
我们先来认识一下混淆矩阵(confusion matrix)。混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。矩阵中的每一行,代表的是预测的类别,每一列,代表的是真实的类别。
通过混淆矩阵,我们可以直观地看到系统是否混淆了两个类别。
我们可以举一个混淆矩阵的例子:
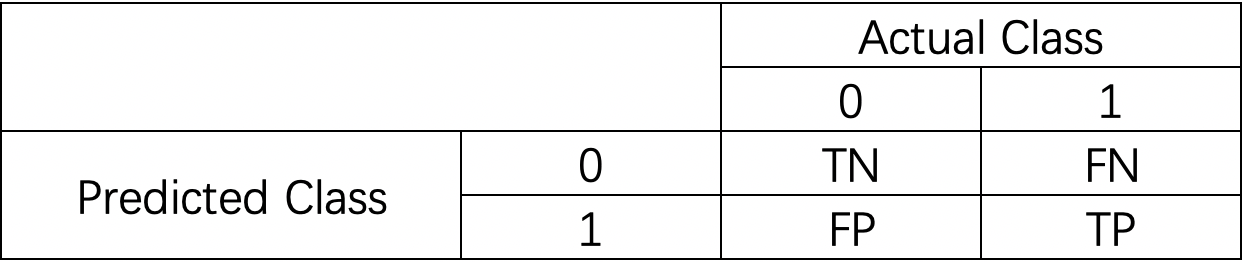
0代表Negative,1代表 Positve。
- TN:当真实值为0,且预测值为0,即为TN(True Negative)
- FN:当真实值为1,而预测值为0,即为FN(False Negative)
- TP: 当真实值为1,且预测值为1,即为TP(True Positive)
- TN:当真实值为0,而预测值为1,即为FP(False Positive)
除了上面,我们还需要了解下面三个指标,分别为Recall、Precision、和F1。
- Recall(召回率)是说我们的Predicted Class中,被预测为1的这个item的数量,占比Actual Class中类别为1的item的数量。如果,我们完全不考虑其他的因素,我们可以将所有的item都预测为1,那么我们的Recall就会很高,为1。但是在实际生产环境中,是不可以这样操作的。
- Precision(精准率)是说,我们预测的Class中,正确预测为1的item的数量,占比我们预测的所有为1item的数量。
- F1是两者的调和平均。
Ok~了解了上面这些衡量算法模型用到的基础概念之后,我们来看看本项目的指标。
模型算法指标为:recall 90;precision 60。
一个思考题?为什么recall 90,precision 60?以及,为什么没有f1,或者说为什么不将f设置为72,因为如果recall 90,precision60,那么这种情况下,f1就是72嘛。
要回答上述问题,我们要从业务出发。需要记住,甚至背诵3遍。
为什么,制定指标的时候,一定要从业务出发呢?
我们来举一个很极端的例子,如果一个模型能做到recall90 precision90,是不是能说这个指标就很好了?
我相信绝大多数场景下,这个模型表现都是十分优秀。请注意,我说的是绝大多数,那么哪些场景下不是呢?
比如说,癌症检测。
假设,你目前在紧密筹备一个“癌症检测”项目。对于每一个被检测的对象,都有如下两个结果中的任意一个结果:
- 1 = 实在抱歉,你不幸患上了癌症。
- 0 = 恭喜你,你并没有换上癌症。
你同事告诉你了一个好消息,你们模型的在测试集上的准确率是99%。听起来很棒,但是你是一个严谨认真的AI PM,所以你决定亲自review一下测试集。
你的测试集都被专业的医学人士打上了标签。下面你测试集的实际情况
- 一共有1,000,000(一百万张医学影像图)
- 999,000医学影像图是良性(Actual Negative)
- 1,000医学影像图是恶性(Actual Positive)
有了上述的数据,即我们模型验证的GroundTruth,接着,我们来看看这个模型的Predicted Result。既然,我们上面学了confusion matrix,那么我们回顾一下Confusion Matrix的两个特征,行代表Predicted class,列代表Actual class。让我们看一下:
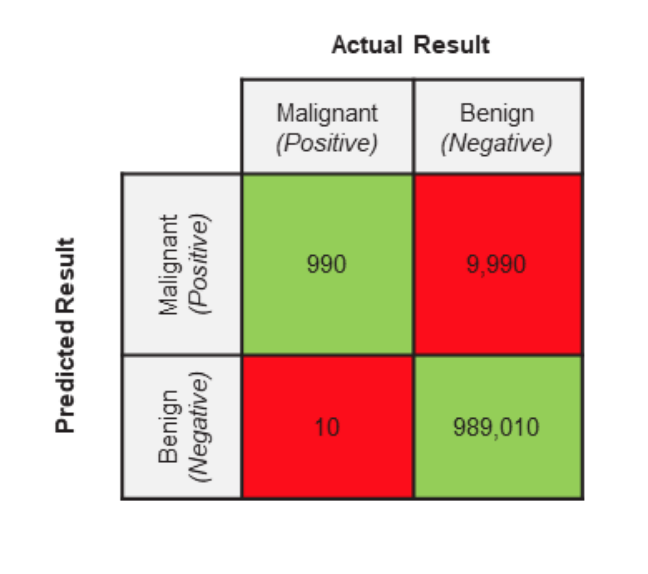
根据所学,实际应用一下:
- TP(实际是Malignant,预测是Malignant)
- FP(实际是Benign,预测是Malignant)
- TN(实际是Benign,预测是Benign)
- FN(实际是Malignant,预测是Benign)
看到这里可能有点头晕,没关系,我马上为大家总结一下:模型正确的判断是1和3,不正确的判断是2和4.
我们希望这个模型将医学影像图片是否为恶性肿瘤做好的区分,好的区分就是指的1和3。除此之外,其余的都是错误的区分。
到这里,我们再看看看模型的表现。
当同事告诉我们模型的正确率是99%的时候,她到底说的是什么呢?我们来仔细分析一下哦~
?她说的是Precision吗?
Precision回答的问题是,我们模型预测为1的样本数量在实际为1样本数量中的占比。用公式表示
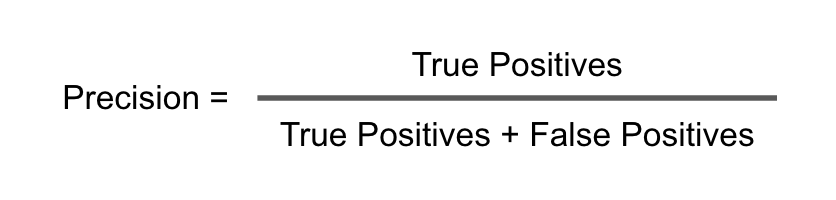
应用真实场景中,我们的准确率 Precision = 990 / (990 + 9,990) = 0.09 = 9%
?她说的是Recall吗?

上述场景中,我们的召回率Recall = 990 / (990 + 10) = 990 / 1,000 = 0.99 = 99%
?她说的是Accuracy吗?

上述场景中,我们的Accuracy是 Accuracy = (990 + 989,010) / 1,000,000 = 0.99 = 99%
从上面的指标,我们可以了解到我们的这个算法模型有一个高的recall和高的accuracy,但是低的precision。
我们的算法模型的precision只有9%。这就意味着被预测为maglignant的医学图像大多数都是良性。我们是不是可以这样就说我们的算法模型很垃圾呢?
并不是。实际上,在我们这个算法模型里面,recall的重要性是比precision高的。所以,尽管我们的precision只有9%,但是我们的召回有99%,这其实是一个很理想的模型表现。因为,患者有癌症,但是在检查时候被漏掉,这种情况,是任何人都不希望发生的。
可能这个时候,你会有一个疑问,这个recall和precision的重要性如何来确定呢?好问题,让我们来仔细看看。
首先,了解一下指标制定的原则:指标的制定取决于我们的商业目标,以及False Positive和False Negative带来的损失。
?什么时候recall比precision重要
当FN会带来极大损失的时候,Recall会显得非常重要。比如,如果将恶心肿瘤预测为良性,这就是非常严重的后果。
这样的预测,会让病人无法得到应该的治疗,从而导致这位病人失去生命,并且这个过程是不可逆的!高的recall是我们希望尽量减少False Negative,尽管这样会带来更多的False Positive。但是通过一些后续的检查,我们是能够将这个FP排除的。
?那什么时候precision比recall重要呢?
当FP会带来很大损失的时候,Precision就显得非常重要。比如在邮件检测里面。垃圾邮件是1,正常邮件是0,如果有很多FP的话,那么大量的正常邮件都会被存储到垃圾邮件。这样造成的后果是非常严重的。
到了这里,让我们来回过头去看看我们业务的recall 90 precision 60,我们会为什么这样制定?这还是得从业务背景谈起。在我和团队分享,如何评估客户AI需求时候,一个很重要的步骤是,首先需要了解这个在没有机器的条件下,他们是如何做这件事的?他们做这件事的判断标准?以及具体的操作步骤。
只有在了解了这个的前提下 ,我们才可以根据这些domain knowledge来进行AI解决方案设计。提取人物履历信息这些工作是由客户的运营同学负责的,那么客户的运营同学之前是怎么做的呢?他们会阅读一篇文章,然后找出符合人物履历标准的信息,做抽取,并进行二次加工。
注意哦,他们的重点是,需要做二次加工,这里的二次加工指的是什么呢?就是将人物的一些履历信息进行整合。因此,其实对他们来说,召回不会最重要的,因为不断有新的语料(文章)发布,他们总可以获取相关人物的信息,但是从一篇好几千字甚至上万字的文章中,准确定位人物履历有关的信息,就显得非常重要,可以提升效率。
是的,效率, 是我们制定我们算法指标的标准,提高召回,可以提高运营同学的效率。
下一个问题?为什么不将f1设置为72呢?因为如果我们recall 90,但是precision 60,最后f1也是72,但是这是不符合业务场景需求的。
2.2.2 性能指标
以API的形式交付。对长度为1000字的文本,每秒查询率(QPS)为10,一次调用在95情况下响应时间(RT)为3秒。接口调用成功率为99%。
让我们拆解一下这个性能指标,首先说一下交付形式。
当前AI项目交付主要有两种,API和Docker,各自适用于不同的业务场景。
QPS(Query Per Second)每秒查询率是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即美妙的响应请求数,也是最大吞吐能力。
RT响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主管感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间
2.3 项目实施
项目实施分为两个阶段,阶段一的尝试主要是使用规则,阶段二的尝试中,我们将策略从规则切换到了模型。从规则到模型的转换,影响因素比较多,有随着项目进展,项目组对项目难度的认识更加深刻的因素,也有数据集的积累更加丰富的原因。
2.3.1 阶段一:规则
在项目中的阶段一,我们的尝试,主要在于规则。首先,我们来介绍一下,在机器学习里面,什么是规则。
那么我们第一阶段,使用规则具体是怎么做的呢?
在第一个阶段,我们整理出了3个文本:白名单、黑名单、打分词。
先来说说这三个文本在我们规则中的使用逻辑,接着我会解释为什么,我们要这么设计。
白名单:白名单是一个list,里面有很多词。当一句话中出现了属于白名单词典中的词,我们就将这句话提取出来。
黑名单:当一句话中出现了这个词,我们就将这句话扔掉。
打分词:当一句话中出现了打分词list中的词,我们就给这句话加1分。(因为词的权重不同,因此权重不一定都是1)
所以,为什么我们要这样设计呢?
我们首先来看看白名单,白名单中的典型词汇有:毕业于、深造、晋升等。大家可以发现,这些词汇,有强烈的属性表现,表现一个人物的履历。因此,当出现了这些词汇之后,我们就默认将这句话抽取(extract)出来。
黑名单中的典型词汇有:死于,逝世、出席等。这些词,明显与人物履历毫无关系。
最后,我们来看一下这个打分词。在打分的设计逻辑上,我们使用了TF-IDF。同时,为了减少因为我们自己样本量少,而带来的负面影响,我们爬取了百度百科人物库,通过TF-IDF,筛选出了几百个和人物履历描述相关的词,并且人工对这些词进行了打分。我们通过匹配一句话中出现的打分词,来为一个句子打分。并且,我们可以通过调节句子得分的阈值,来调节我们命中人物履历的句子。
通过规则,我们发现,模型的效果,在precision不错,但是recall不够好。通过分析bad case,我们发现模型的泛化性能差。
分析Bad Case的思路:
- 找出所有bad cases,看看哪些训练样本预测错了?
- 对每一个badcase分析找出原因
- 我们哪部分特征使得模型做了这个判断
- 这些bad cases是否有共性?
- 将bad cases进行分类,并统计不同类别的频数
这里顺便提一下,在我们分析bad case的时候,除了分析模型预测的错误之外,我们也会发现一些标注数据存在问题,在训练集中,有人为标记错的样本很正常,因为人也不能保证100%正确。我们需要注意的是,这种标记错误分为两类:
- 随机标记错误,比如因为走神、没看清给标错数据
- 系统性标记错误,标错数据的人,是真的将A以为是B,并且在整个标注流程中,都将A以为是B
对于随机标注错误,只要整体的训练样本足够大,放着也没事。对于系统性标注错误,必须进行修正,因为分类器会学到错误的分类。
说明一下,关于Bad Case分析,吴恩达的课程都有讲,如果想对这一块知识,有进一步了解,可以自行进行学习。
?阶段一遇到的困难
通过对bad case的分析,我们发现通过规则中最大的问题是,模型无法分清动名词。因此,导致precision非常地低。
举2个例子:
A:小红投资的运动装公司西蓝花。
B:小红投资了运动装公司西蓝花。
第一句表达的主旨意思是运动装公司,而第二句话表达的主旨是小红进行了投资,因此从最开始对需要抽取句子的定义上来说,我们应该抽取第二句。但是,因为是打分机制,AB两句都命中了“投资”,因此,均被抽取。
从这里,就发现,我们的规则之路,基本上走到了尽头,打分的方式是永远无法将AB区分出来,于是,我们开始了我们下一段探索之旅。
2.3.2 阶段二:模型
在阶段一,我们讲到了规则的一个弊端,就是规则无法区分词性。
经过评估,我们还是打算使用模型来做,并且根据上一阶段的发现,做对应的优化,在这里,让我们介绍一下“Part-of-Speech Tagging”
Part-of-Speech Tagging,也叫词性标注。
词性标注很有用,因为他们揭示了一个单词以及其相临近词的很多信息。
我们看一下具体的用例。

根据POS,我们发现,”dog“是名词,“ran”是动词。是不是觉得这个方法刚好就能弥补我们上面谈到的,模型无法分清动名词这个困难。
因此,我们对所有数据,加了POS,然后放进了Bert,这里还有一个小的tip,因为我们数据量其实是很小的,所以Bert只训练了一轮。
既然这里讲到了Bert,那么我也和大家一起重新复习一下Bert(我不是科班专业,也不是专门研究NLP方向的,所以我自己的知识积累有限,如果大家有更好的想法,欢迎交流讨论90度鞠躬)
首先,我们了解一个概念“预训练模型”。
预训练模型就是一些人用某个较大的数据集训练好的模型,这个模型里面有一些初始化的参数,这些参数不是随机的,而是通过其他类似数据上面学到的。
Bert呢,是一个Google开源的模型。非常的牛逼,那到底有多牛逼呢?这要从Bert的试用领域和模型表现效果,两个维度来说说。
适用领域,Bert可以用于各种NLP任务,只需要在核心模型中添加一个层,例如:
- 在分类任务中,例如情感分析,只需要在 Transformer 的输出之上加一个分类层
- 在问答任务中,问答系统需要接收有关文本序列的question,并且需要在序列中标记answer。可以使用 BERT学习两个标记 answer 开始和结尾的向量来训练 Q&A模型
- 在命名实体识别(NER),系统需要接收文本序列,标记文本中的各种类型的实体(人员、组织、日期等)可以用BERT将每个token的输出向量送到预测 NER 标签的分类层。
在part of speech 和Bert的加持下,我们模型的表现,达到了recall 90,precision 90。
暂且讲到这里吧~
三、Lesson Learned
其实从项目推进上,数据集管理上,策略分析上,感觉还有好多可以讲,可以写的,写下来又感觉写的太多了。之后,单开篇幅来写吧
参考资料:
1. 语言本能
2. 数学之美
3. 智能时代
4. 2018年,NLP研究与应用进展到什么水平了?
5. https://en.wikipedia.org/wiki/Confusion_matrix#cite_note-Powers2011-2
6. https://lawtomated.com/accuracy-precision-recall-and-f1-scores-for-lawyers/
7. [吞吐量(TPS)、QPS、并发数、响应时间(RT)概念 – 胡立峰 – 博客园](https://www.cnblogs.com/data2value/p/6220859.html)
8. [Bad Case Analysis](http://gitlinux.net/2019-03-11-bad-case-analysis/)
9. [【结构化机器学习项目】Lesson 2—机器学习策略2_人工智能_【人工智能】王小草的博客-CSDN博客](https://blog.csdn.net/sinat_33761963/article/details/80559099)
10. [5 分钟入门 Google 最强NLP模型:BERT – 简书](https://www.jianshu.com/p/d110d0c13063)
11. https://arxiv.org/pdf/1810.04805.pdf 《BERT: Pre-training of Bidirectional Transformers for Language Understanding》
本文由 @一颗西兰花 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议








倒是打分那一段没太明白,请问题主方便私信我一起讨论讨论吗?
就题主所说的召回率和准确率的方向说一下自己的见解,先前在百度做策略基建时的概念:
1. 召回率:个人认为召回率是指能被模型所识别的样本数量/全体样本数量,即召回率=可以识别的样本数量/全部样本数量,举个例子,我在做一款识别低质内容的模型,我输入了1000条样本,其中反馈结果为-1,0,1三种,0代表模型未能识别,即无法给出预测答案的样本数量,倘若0的数量为50,那么模型的召回率即为95%(召回率=950/1000);
2. 准确率:这个和题主所说的差不多,但是一般而言不会区分模型准确率抑或是业务准确率,防止概念混淆,个人认为模型的准确率是指预测正确的结果数占预测总数的比值,举上述的例子来说,倘若1代表预测为真,数量为500,而在这500份样本中,实际为真的数量为450,0代表预测低质,数量为450,而在这450份样本中,实际为低质的样本数为430份,那么这个模型的准确率即为93%,即(450+430)/950。
感谢大佬分享~最近在做相关产品,受益匪浅~
大老,我转载可以吗
转载是什么意思呀?