
 起点课堂会员权益
起点课堂会员权益
如何用数学函数去理解机器学习?
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等本文主要分享了如何基于数学函数原理去理解机器学习的本质,并简要介绍了机器学习的过程。

近期也是在做项目的过程中发现,其实AI产品经理不需要深入研究每一种算法,能了解机器学习的过程,这其中用到哪些常用算法,分别使用与解决哪些问题和应用场景,并基于了解的知识,去更好的建立AI产品落地流程、把控项目进度、风险评估,这个才是最关键的地方,算法研究交给专业的算法工程师,各司其职,相互配合。
基于最近看的一些文章和书籍,本文将重点分享,如何用数学函数去理解机器学习的过程,以及用数学原理指导产品工作的一些思考。
一、机器学习的本质
机器学习,即学习人类的分析、判断、解决问题的能力。人的能力如何得来?通过长期的信息输入,再经过大脑思考,最后输出对事物的判断。
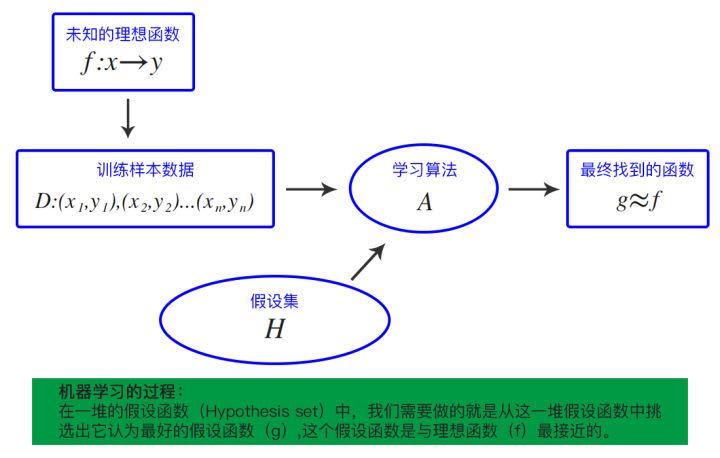
那么机器如何学习?通过大量的训练数据,学习找规律,找到问题的理想最优解。所以,机器学习的本质其实是函数预测,即f:x->y。
图片来源:网络
中学时期,我们常解的数据问题之一便是:求解方程。已知坐标(x1,y1),(x2,y2)…(xn,yn)求解n元n次方程,再将新的x带入方程对应的y。机器学习的过程可以类比方程求解过程:
- 样本数据:已知的坐标集D:(x1,y1),(x2,y2)…(xn,yn);
- 算法:即求解函数的方法;
- 模型训练:最后求解的方程或函数;
- 评估方法:将新的x带入方程验证函数“预测”是否正确。
与普通的函数不同的是,机器学习往往很难求解出完整的方程,通过各种手段求最接近理想情况下的未知项取值。以人脸识别为例,预测函数为:f:X(图片脸部特征)—>Y(身份),其中f则是通过机器学习后,具有人脸识别能力的模型。使用不同的机器学习方法训练的模型不同,即对应的函数形式也不同。
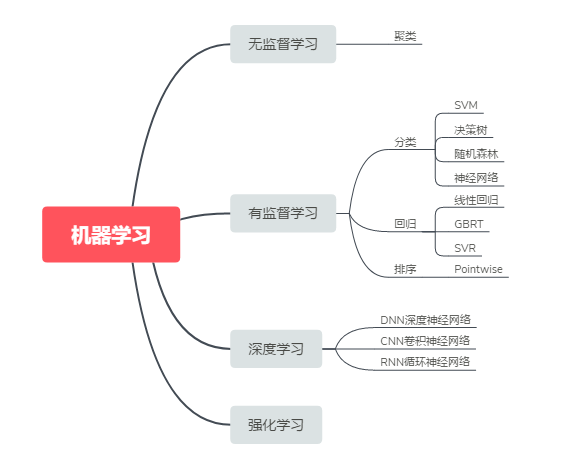
机器学习解决的常见四类问题:分类、聚类、排序和推荐。
(1)分类问题:一般包括二分类和多分类的问题,二分类即非黑即白,比如垃圾邮件过滤;多分类问题,即有多种类别的输出结果,比如图像识别。
(2)聚类问题:在一个集合中,将相似度高的对象组成多个类的过程叫聚类。比如一些新闻类的应用,将未标注的数据通过聚类算法来构建主题。
(3)排序问题:根据相关度、重要度、匹配度等,让用户在海量的信息中找到想要的信息,常见的应用场景,如搜索引擎。
(4)推荐问题:典型的应用场景,电商行业的千人千面,根据用户的购买、收藏等行为,分析用户的喜好,实现精准营销。
在理解了机器学习的本质以及常见的问题类型后,下面将介绍机器学习的过程。
二、机器学习的过程
机器学习的过程主要分为三个步骤:样本准备、算法选取、模型评估。
1. 样本准备
机器学习,需要先学习才能预测判断,样本则是机器学习的信息输入,样本的质量很大程度上决定了机器学习的效果。以人脸识别为例,其样本是大量的人脸图片。那么,大量的样本如何获取?按数据来源分类,可分为内部样本和外部样本。
(1)内部样本
内部样本数据,一般可基于内部已积累的样本数据,或通过对产品进行数据标注或者埋点,来收集更多维度的样本数据。
(2)外部样本
若数据的量级或丰富度不够,则可能需要获取一些外部样本。比如通过搜索典型的大型公开数据集,或者数据爬取等方式,来获取一些指定场景的新样本。
2. 算法选取
在机器学习的过程中,找到接近理想模型(函数)的方法即算法。机器学习的常用算法很多,不同的算法,解决的问题不同,适用的场景也不同。
如下图,比如解决聚类问题,一般使用无监督学习算法,分类问题,一般使用有监督学习算法:支持向量机SVM、神经网络等,目前神经网络依然是研究热点之一。
(1)神经网络原理
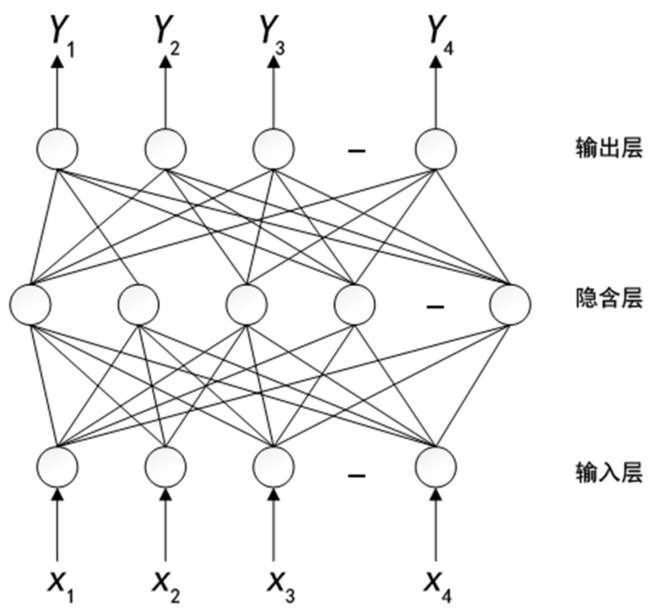
神经网络是一种模仿人类思考方式的模型,就像飞机模仿鸟的形态一样,神经网络也借鉴了生物学的神经元结构。神经元细胞主要由树突、轴突和细胞体构成,树突用于接收信号并传递给细胞体,细胞体处理信号,轴突输出信号。神经网络结构与此类似,一个典型的单隐含层神经网络架构如下图:
图片来源:网络
- 输入层:接收输入数据,如图片、语音特征等;
- 隐藏层:承载数据特征运算;
- 输出层:输出计算的结果;
其本质是,通过调整内部大量处理单元的连接关系、激励函数和权重值,实现对理想函数的逼近。
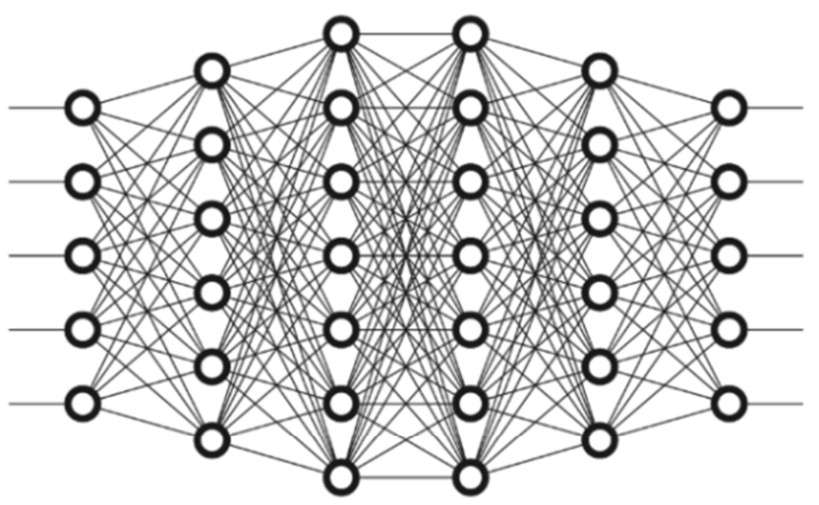
(2)深度学习
深度学习是神经网络的一种算法,目前在计算机视觉等领域应用十分广泛,相比单隐藏层神经网络结构,深度学习神经网络是一种多隐藏层、多层感知器的学习结构。如下图所示,增加更多的隐藏层后,网络能更深入得表示特征,以及具有更强的函数模拟能力,能获得更好的分类能力。
图片来源:网络
深度学习三类经典的神经网络分别是:深度神经网络DNN、卷积神经网络CNN、和循环神经网络RNN。其中DNN、CNN一般解决计算机视觉、图像识别等分类问题,RNN适用于自然语言处理等问题。
基于大量的样本、选取合适的算法进行模型训练后,下一步则是对模型的预测效果进行评估。
3. 模型评估
模型评估一般可分为两个阶段:实验阶段和上线阶段,在实验阶段能达到一定的使用标准指标,才能进入实际上线使用阶段。
(1)实验阶段
为了评估模型的可用性,需要对模型的预测能力进行评价,其中很重要的一个评价指标就是准确率,即模型预测和标签一致的样本占所有样本的比例。即选择不同于训练数据的,有标签数据的测试集,输入模型进行运算,计算预测的准确率,评估模型对于测试集的预测效果是否能模型可用指标。
(2)上线阶段
在模型投入使用后,基于上线后的真实数据反馈,评估模型的能力,并基于新的反馈数据,持续迭代优化模型,提高或保持模型的泛化能力。
三、总结与思考
作为产品赋能的一个“工具”,产品化的整个流程可总结为:业务需求->转化为业务函数>样本数据获取->选择合适的算法->模型训练->内部评估->上线验证迭代。
其实这个过程,最底层的逻辑还是基于数学建模原理的思路来解决问题,也可用来指导一些日常产品工作中的问题。比如,《增长黑客》中的增长杠杆、北极星指标等方法,其本质也是数据建模的原理。定义业务函数、确定影响因素、权重成本分析、判断最优解决方案,评估上线反馈形成闭环。
所有,很多问题表面看起来各式各样、各不相同,但抽象出来可能就是一些学科问题,比如数学、物理、经济学等,联想到我前段时间分享的一篇文章 《透过《奇葩说》论点,看背后的多元思维模型》中提到的多元思维模型核心观点——越往深层次思考,越能挖掘事物本质,越接近学科原理。
愿我们都能掌握一把尚方宝剑,一路“升级打怪”、“斩妖除魔”……
作者:小谭同学;微信公众号:斜杠产品汪
本文由 @小谭同学 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议







- 目前还没评论,等你发挥!









