
 起点课堂会员权益
起点课堂会员权益AI产品经理必修:揭开算法的面纱(隐含马尔可夫)
隐马尔可夫模型目前陆续成功地应用于机器翻译、拼写纠错、手写体识别、图像处理、基因序列分析等领域。近20年来,它广泛应用于股票预测和投资。本文抛弃那些眼花缭乱的数学公式,去看看隐含马尔可夫模型到底是什么?怎么用?

相信只要是涉足人工智能领域,你都会听到这样一个神秘的名字-隐含马尔可夫模型。是的,看了一圈文章和资料后,除了知道马尔可夫是个聪明绝顶的人,其他的就啥也不知道了。
正式开讲之前,先大概了解一下,这个算法有哪些主要的应用场景。
一个词概括,进行预测。
20世界80年代末李开复坚持采用隐马尔可夫模型的框架,成功的开发了世界上第一个大词汇量连续语音识别系统sphinx。接下来,隐马尔可夫模型陆续成功地应用于机器翻译、拼写纠错、手写体识别、图像处理、基因序列分析等领域。近20年来,它广泛应用于股票预测和投资。
今天,我想抛弃那些眼花缭乱的数学公式,去看看隐含马尔可夫模型到底是什么?怎么用?
一、隐含马尔可夫模型是什么?
我们还是分成三个阶段来了解。
概念一:马尔可夫假设
随机过程中各个状态st的概率分布,只与它前一个状态st-1有关。
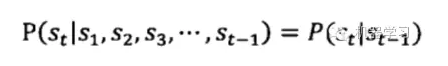
举一个例子,我们可以把S1 , S2 ,S3…St…看做北京每天的最高气温,这里面的每个状态St都是随机的。理论上,任何一天的最高气温St取值都可能和这段时间以前的最高气温是相关的。
马尔可夫这个大神为了简化问题,做出了如上图的简化的假设。回到上面的例子,第二天的最高气温只跟昨天有关而与其他日期没有任何关联。
概念二:马尔可夫链
符合马尔可夫假设的随机过程称为马尔可夫过程,也称为马尔可夫链。
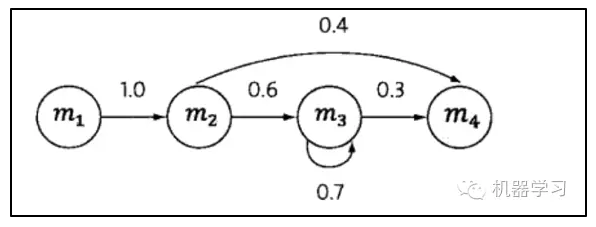
在这个马尔可夫链中,四个圈表示四个状态,每条边表示一个可能的状态转换,边上的权值是转移概率。
例如:某个时刻t的状态St是m2,则下一个时刻St+1=m3的概率是0.6,用数学符号表示是P(St+1=m3|St=m2)=0.6。
把这个马尔可夫链想象成一台机器,它随机选择一个状态作为初始状态,然后按照上述规则随机选择后续状态。
结果可能如下:
- S1=m1S2=m2 S3=m3 S4=m4
- S1=m2 S2=m4
- S1=m3 S2=m3 S3=m4
- ……
这样经过一段时间的运转,就会产生一个状态序列S1,S2,S3… St。我们可以数出mi出现的次数,以及mi转换到mj的转移概率。基于马尔可夫假设,每一个状态只与前一个状态相关,例如从m3 转移到m4,不论在此之前是怎么进入m3,这个概率都是0.3。
概念三:隐含马尔可夫模型
隐马尔可夫模型是上述马尔可夫链的一个扩展:任一时刻t的状态st是不可见的。所以观察者没法通过观察到一个状态序列s1,s2,s3,…sT-1来推测转移概率等参数。但是,隐马尔可夫在每个时刻t会输出一个符号ot,而且ot和st相关而且仅和st相关。这个被称为独立输出假设。
隐马尔可夫模型结构如下:
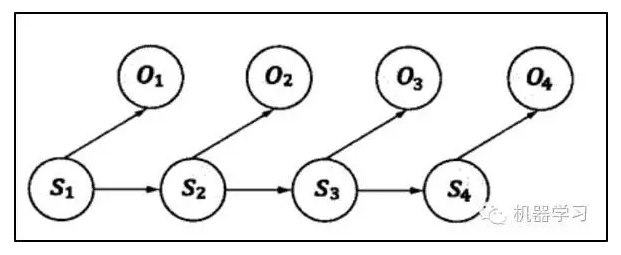
其中包含的状态s1,s2,s3,s4是一个典型的马尔可夫链。鲍姆把这种模型称为“隐含”马尔可夫模型。
那么,问题来了,什么是隐患状态?
从马尔可夫链中,我们看到的都是可见状态啊。这个问题真的困扰了我很久,我找了大量的资料,发现还是这样一个经典例子能够解释得清楚,请看:
假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
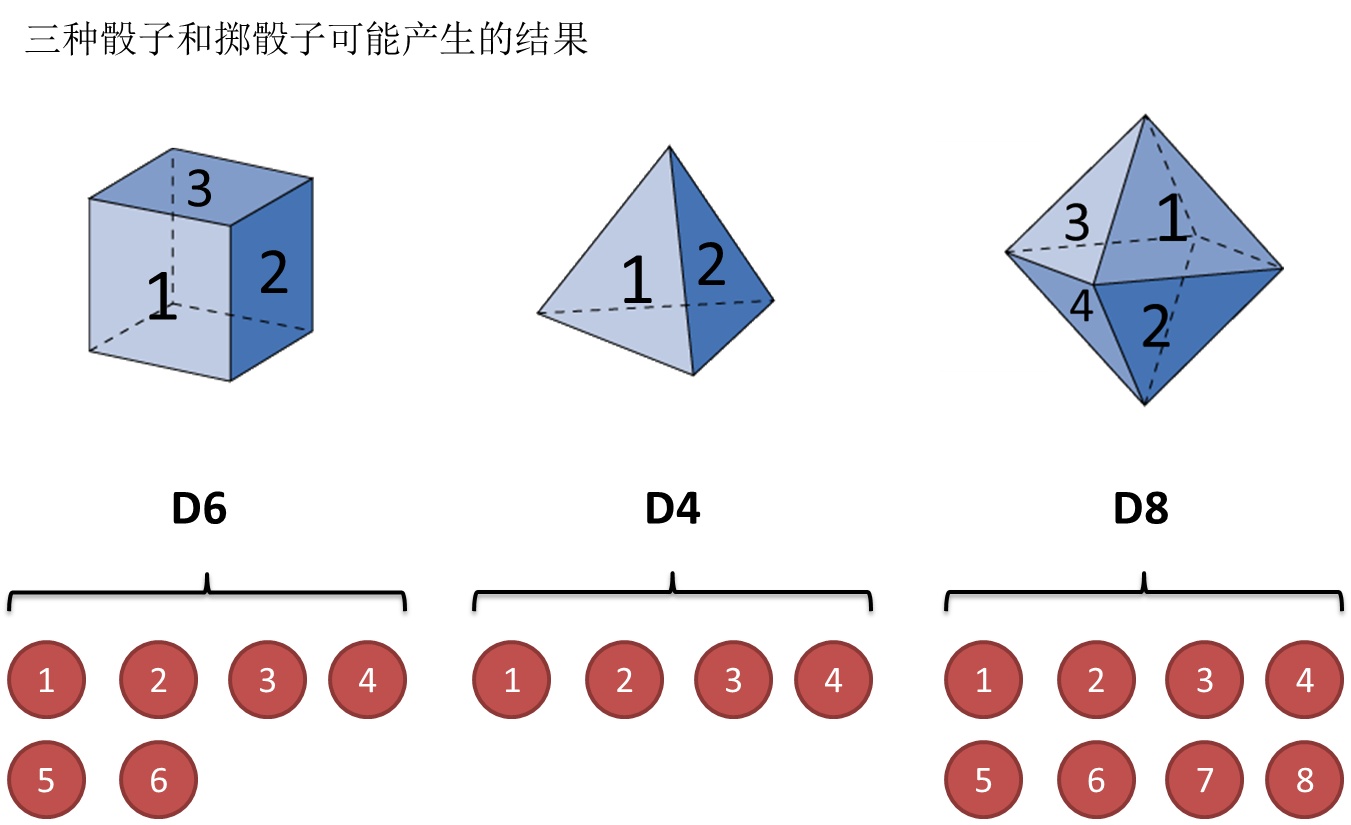
现在,我们开始掷骰子,得到如下结果:
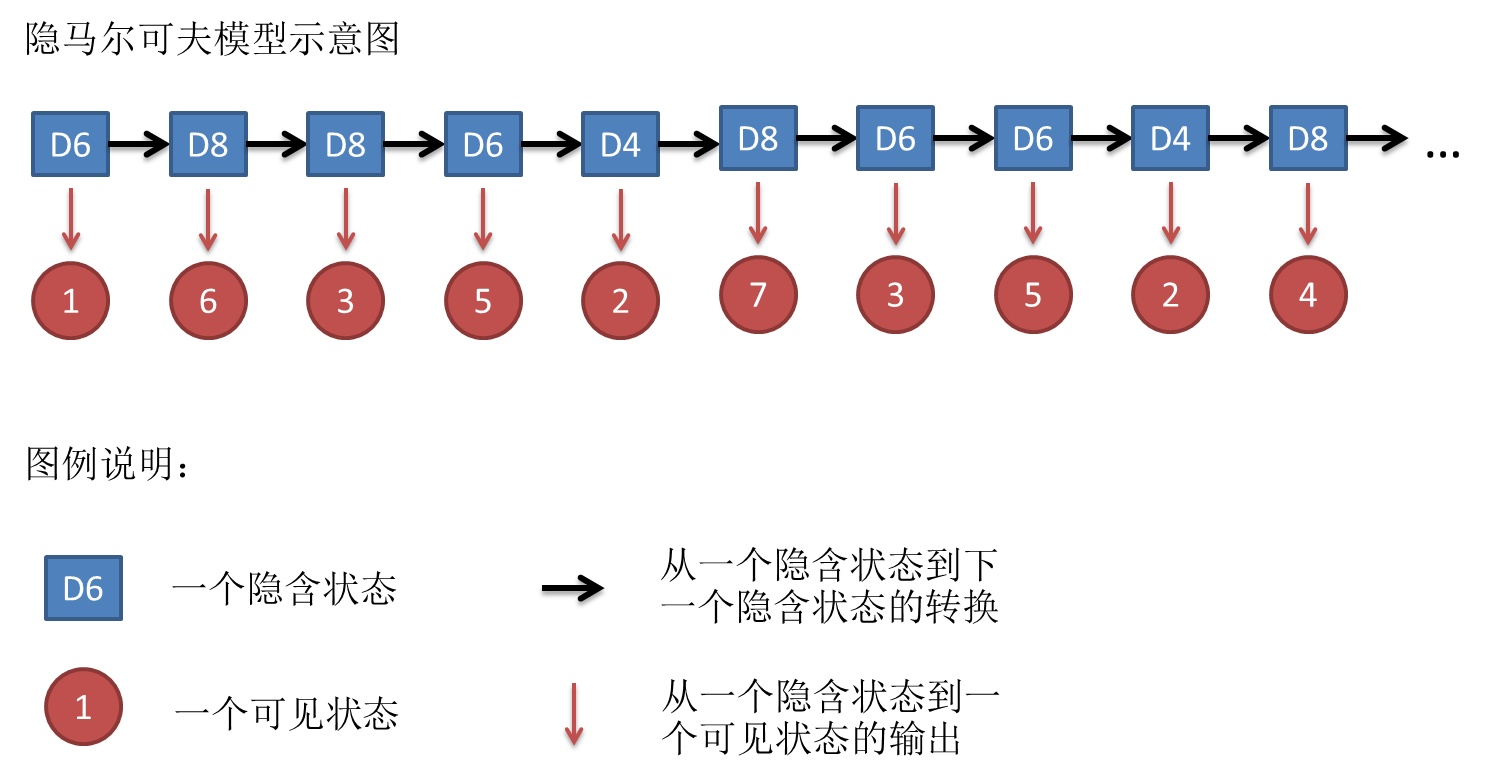
看出来了吧?什么是隐含状态?掷出来的数字是可见的,但是每次取哪个骰子,我们是不是不知道?
回到隐含马尔可夫模型,符号ot就是我们掷出来得数字(1,2,3,4,5,6,7,8),隐患状态st就是我们掷得骰子(D6,D4,D8)。
现在,我们以掷骰子为例,来总结一下隐患马尔可夫模型得几个构成要素:
- 可见状态集:D6的可见状态集(1,2,3,4,5,6),D4的可见状态集(1,2,3,4),D8的可见状态集(1,2,3,4,5,6,7,8)
- 隐患状态集:上图中的隐含状态集为D6,D8,D8,D6,D4……
- 初始(隐含)状态转移概率:比如,第一次拿到D6,D4和D8的概率分别是0.1,0.4,0.5。
- (隐含)状态转移概率:比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是9,是D8的概率是0.1。
- (隐含状态至可见状态的)输出概率:就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6,我们同样可以对输出概率进行其他定义。比如:我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
二、隐含马尔可夫模型能解决什么问题?
通用地讲,围绕HMM有三种类型的问题:
- 给定一个模型,如何计算某个特定的输出序列的概率。(概率计算问题)
- 给定一个模型和某个特定的输出序列,如何找到最可能产生这个输出的状态序列。(解码,预测问题)
- 给定足够的观测数据,如何估计隐马尔可夫模型的参数。(非监督学习方法)
目前来说,第二种问题最常用,【中文分词】【语音识别】【新词发现】【词性标注】都有它的一席之地。
隐含马尔可夫模型的应用
讲到这,隐马尔可夫模型的理论定义和三个问题都介绍完毕,新问题又来了,这个模型到底有什么用?
接下来请看一下典型的通信系统是什么样子的,想必“隐马尔可夫模型有什么用”这个问题便不攻自破了。
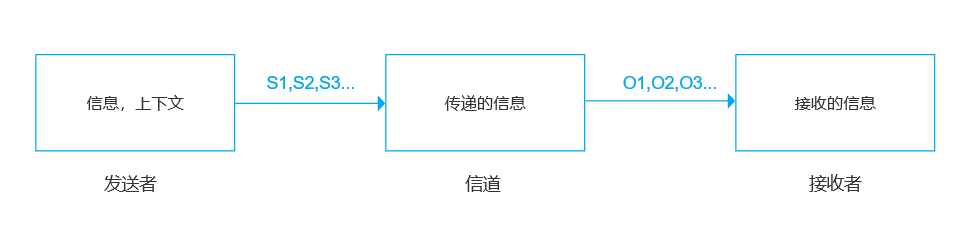
- 发送者(人或者机器)发送信息时,需要采用一种能在媒体中(比如空气、电线)传播的信号,比如语音或者电话线的调制信号,这个过程就是广义上的编码。
- 然后通过媒体传播到接收方,这个过程是信道传输。
- 在接收方,接收者(人或者机器)根据事先约定好的方法,将这些信号还原成发送者的信息,这个过程是广义上的解码。
其中S1,S2,S3,…表示信息源发出的信号,比如手机发送的信号。O1,O2,O3,…是接收器(比如另一部手机)接收到的信号。通信中的解码就是根据接收到的信号O1,O2,O3,…,还原出发送的信号S1,S2,S3,…。
这跟自然语言处理又有什么关系?不妨换个角度来考虑这个问题,所谓的语音识别,就是听者(机器)去猜测说话者要表达的意思。这就像通信系统中,接收端根据收到的信号去还原出发送端发出的信号。
在通信中,如何根据接收端的观测信号O1,O2,O3,…来推测信号源发送的信息S1,S2,S3,…呢?只需要从所有的源信息中找到最可能产生出观测信号的那一个信息。
同样,很多自然语言处理的应用也可以这样理解。在从汉语到英语的翻译中,说话者讲的是汉语,但是信道传播编码的方式是英语,如果利用计算机,根据接收到的英语信息,推测说话者的汉语意思,就是机器翻译。
同样,如果根据带有拼写错误的语句推测说话者想表达的正确意思,那就是自动纠错。这样,几乎所有的自然语言处理问题都可以等价成通信的解码问题。
本文由 @CARRIE 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









看不懂,好难啊…
我们算法也说很难 😥 作为产品知道这个算法大概在哪些领域有应用就行