
 起点课堂会员权益
起点课堂会员权益AI产品经理必修——揭开算法的面纱(余弦定理)
余弦定理作为初中课本就学过的知识,AI产品经理将会把它运用到相似度计算当中。

世界上有些事物的联系常常超出人们的想象。
在数据采集及大数据处理的时候,数据排重、相似度计算是很重要的一个环节,由此引入相似度计算算法。
但你知道我们在初中课本中学过的余弦定理是如何完成相似度计算的吗?
要揭开谜底,我们先来“三步走”。
一、TF-IDF单文本词汇频率/逆文本频率值
1. 单文本词汇频率(TF: Term Frequency,是词频一词的英文缩写)
即一个词在文中出现的次数。具体地讲,如果一个查询包含n个关键词,它们在一个特定网页中的词频分别是: TF1……TFn。
那么,这个查询和该网页的相关性(即相似度)就是:T1+T2+…+Tn。
2. 逆文本频率指数(Inverse Document Frequency,缩写为IDF)
在词频的基础上,要对每个词分配一个“重要性”权重。
最常见的词(“的”、“是”、“在”)给予最小的权重,较常见的词(“中国”“北京”)给予较小的权重,较少见的词(可能就是文章的主题词)给予较大的权重。
这个权重叫做“逆文本频率”,它的大小与一个词的常见程度成反比。
概括地讲,假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小,反之亦然。它的公式为logD/Dw,其中D是全部网页数。
二、特征向量
先看一下特征向量的严格定义吧:
特征向量是数学学科中的一个专业名词,即线性变换的特征向量(本征向量)是一个非退化的向量。其方向在该变换下不变,该向量在此变换下缩放的比例称为其特征值(本征值)。
一个线性变换通常可以由其特征值和特征向量完全描述,相同特征值的特征向量集合称之为特征空间。
嗯,这段话看看就好了。我们知道特征向量是有方向的就好了。
接下来我们看看如何把一篇文章或一段话或一句话转换成特征向量。
首先,我们需要有一个词汇表,比如是这样的64000个词:

其次,我们需要把输入的文章或是段落或是语句进行分词。目前市面常用的分词器有很多,比如结巴分词器、hanlp分词器等,每种分词器都有自己的优缺点,我们知道可以利用第三方的分词工具帮助我们分词就好了。
然后,就是最重要的一步,结合分词结果,得到一个64000维的向量,比如是这样的:

好了,现在对于每一个输入,无论这篇文章多长,我们都能得到这样一个向量。
例如向量1:[0,0.0034,0,0.00052,0…,0.034,…0.075]。
至此,我们已经完成了最重要的一步,把一篇篇文章变成一串串数字。是不是很有意思?
三、余弦定理:向量距离的度量
好了,回顾一下余弦定理。
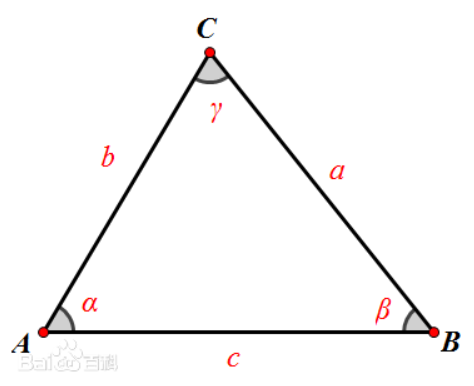
只看夹角A。
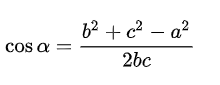
如果把三角形的两边b和c看成是两个以A为起点的向量,那么上述公式等价于:
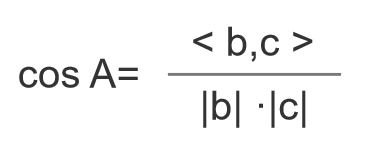
现在以两篇文章为例,说明是如何进行计算的。
加入文章1和文章1对应的向量分别是x1,x2,…,x64000和y1,y2,…,y64000。
那么他们夹角的余弦等于:
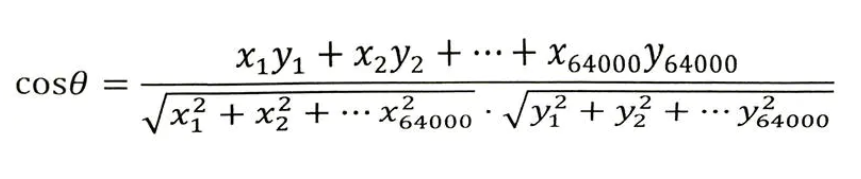
计算所得的余弦取值在0和1之间,也就是说夹角在0度到90度之间。
现在,结论闪亮登场:
- 当两篇文章向量夹角的余弦等于1时,这两个向量的夹角为零,两篇文章完全相同;
- 当夹角的余弦接近于1时两篇文章相似,从而可以归成一类;
- 夹角的余弦越小,夹角越大,两篇文章越不相关;
- 当两个向量正交时(90度),夹角的余弦为零,说明两篇文章根本没有相同的主题词,它们毫不相关。
四、余弦定理总结
余弦定理:通过对两个文本分词,TF-IDF算法向量化,对比两者的余弦夹角,夹角越小相似度越高,但由于有可能一个文章的特征向量词特别多导致整个向量维度很高,使得计算的代价太大不适合大数据量的计算。
余弦定理的应用非常广泛,我们在做智能问答系统中就用到余弦定理做问题的相似度计算。
大概原理是这样:用户输入问题1,系统对语料库中的问题进行相似度计算,找出相似度最高的问题2,然后输出问题2的答案。
可以看看下面的例子:
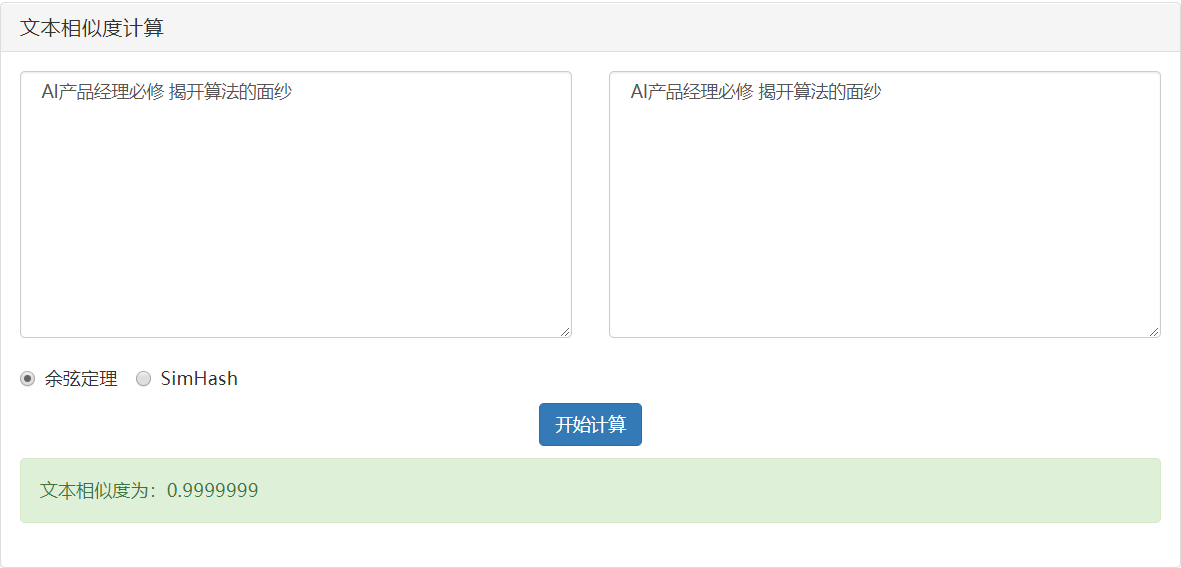
情况1:完全相同
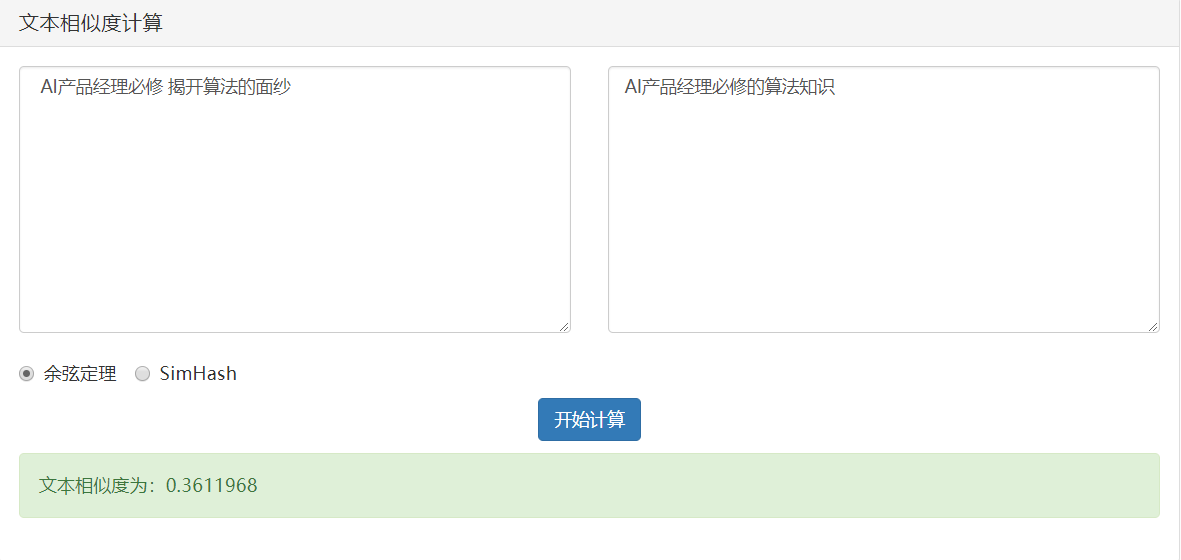
情况2:相似
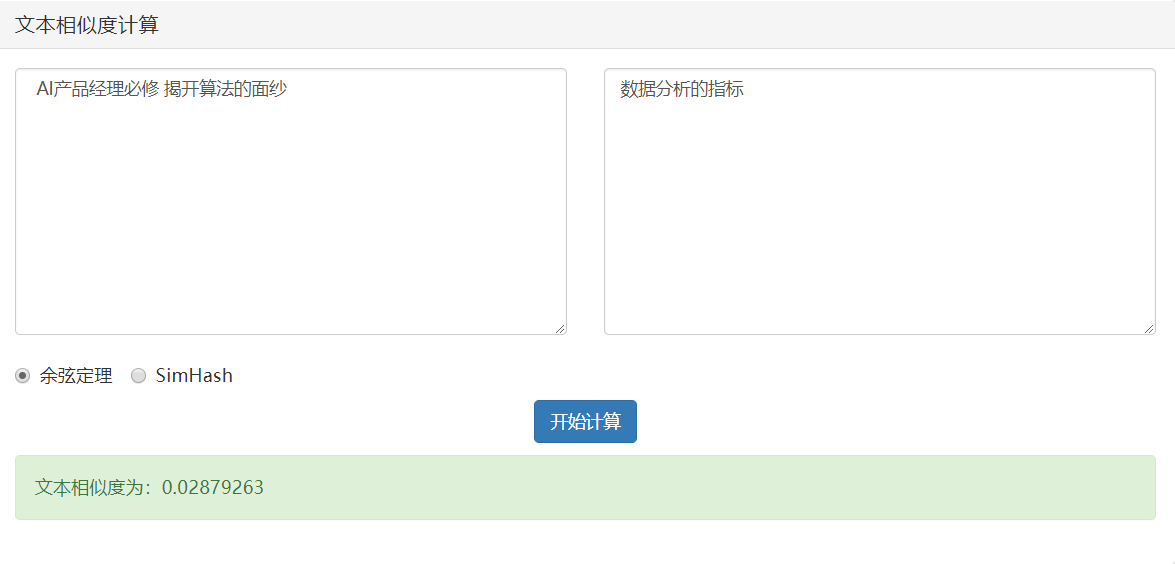
情况3:不相关
本文由@CARRIE 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议









有意思
作为一个技术小白,可太喜欢这类文章了,太有趣了,抽象成数学问题,通过简单的指标进行判断,amazing!!
是的呀,完全是打开了另一扇门!