
 起点课堂会员权益
起点课堂会员权益AI产品经理必修——揭开算法的面纱(EM算法)
只要有一些训练数据,再定义一个最大化函数,采用EM算法,利用计算机经过若干次迭代,就可以得到所要的模型。这实在是太美妙了,这也许是我们的造物主刻意安排的。所以我把它称作为上帝的算法。——吴军

01 极大似然原理
要立即EM算法,我们先来了解一个经典的原理——极大似然原理(也叫最大似然原理)。

看完这个示例,想必你对极大似然已经有了初步的认识,没错,满足某个条件,使得事件发生的可能性最大。上面这个例子,就是,满足小球从乙箱中取出,使得球是黑球的概率最大。
我们再来看一个经典的示例:
问题:假设我们需要调查我们学校的男生和女生的身高分布。
步骤1:在校园里随便地活捉了100个男生和100个女生,共200人。
步骤2:你开始喊:“男的左边,女的右边,其他的站中间!”。
步骤3:统计分别得到100个男生的身高和100个女生的身高。
求解:假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。
用刚才的语境来解释,就是,满足这个分部的均值u和方差∂2,使得我们的观测数据(100个男生身高和100个女生的身高)出现的可能性最大。
总结一下,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
02 EM算法(期望最大值算法)
回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,现在这200个人已经混到一起了。这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要估计的了:
- 这个人是男生还是女生?
- 男生和女生对应的身高的高斯分布的参数是多少?
那这个问题EM算法是怎么解决的呢?我们先来看答案。
步骤1:我们先随便猜一下男生(身高)的正态分布的参数:如均值和方差是多少。例如男生的均值是1米7,方差是0.1米(当然了,刚开始肯定没那么准)。女生的正态分布参数同理。
步骤2:计算出每个人更可能属于第一个还是第二个正态分布中的。例如,这个人的身高是1米8,那很明显,他最大可能属于男生的那个分布)。这个是属于Expectation一步。
步骤3:有了每个人的归属,我们已经大概地按上面的方法将这200个人分为男生和女生两部分了。
现在看出来了吗?我们已经分别得到了100个男生的身高和100个女生的身高。是不是回到了最大似然估计问题?
步骤4:根据最大似然估计,通过这些被大概分为男生的n个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计,也就是重新求解这个分布的均值u和方差∂2。这个是Maximization。
假定计算结果当前男生的均值是1米74,方差是0.08。
看出来了吗?这和我们最初随便猜的那个参数不一致呀!
步骤5:重新猜。假定我们第二次猜测时取个中间值,例如男生的均值是1米72,方差是0.09。继续步骤1——步骤2——步骤3——步骤4……如此往复,直到收敛,参数基本不再发生变化为止。
我们再用一个简单的例子来总结这EM算法的精髓:
小时候,老妈给一大袋糖果给你,叫你和你姐姐等分,然后你懒得去点糖果的个数,所以你也就不知道每个人到底该分多少个。咱们一般怎么做呢?先把一袋糖果目测的分为两袋,然后把两袋糖果拿在左右手,看哪个重,如果右手重,那很明显右手这代糖果多了,然后你再在右手这袋糖果中抓一把放到左手这袋,然后再感受下哪个重,然后再从重的那袋抓一小把放进轻的那一袋,继续下去,直到你感觉两袋糖果差不多相等了为止。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
现在,我们来总结一下:
EM(Expectation Maximization)算法包括了两个过程和一个目标函数:
E-step: 根据现有的聚类结果,对所以数据(点)重新进行划分。如果把最终得到的分类结果看作是一个数学的模型,那么这些聚类的中心(值),以及每一个点和聚类的隶属关系,可以看成是这个模型的参数。
M-step: 根据重新划分的结果,得到新的聚类。
目标函数:上面的点到聚类的距离d和聚类之间的距离D,整个过程就是要最大化目标函数。
03 EM算法在分类中的应用
了解了EM算法,我们来看一个EM算法在文本分类中的真实应用。
假设有N篇文本,对应N个向量V1,V2 …Vn, (文本如何转变为向量,之前的文章已经写过,详见《AI产品经理必修——揭开算法的面纱(余弦定理)》)希望把他们分到K类中,而这K类的中心是C1,C2 …Ck。K可以是一个固定的数,比如我们认为文本的主题只有100类;也可以是一个不定的数,比如我们并不知道文本的主题有多少类,最终有多少类就分成多少类。分类步骤如下:
步骤1.随机挑选K个点,作为起始的中心。(E-step)
 步骤2:计算所有点到这些聚类中心的距离,将这些点归到最近的一类中。(M-step)
步骤2:计算所有点到这些聚类中心的距离,将这些点归到最近的一类中。(M-step)
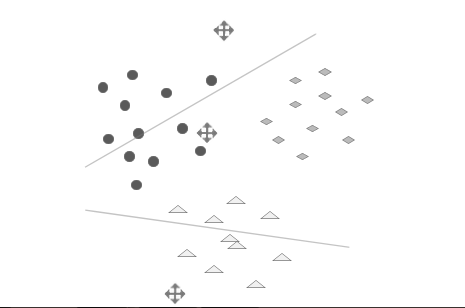 步骤3:重新计算每一类的中心。新的聚类中心和原先的相比会有一个位移。(E-step)
步骤3:重新计算每一类的中心。新的聚类中心和原先的相比会有一个位移。(E-step)
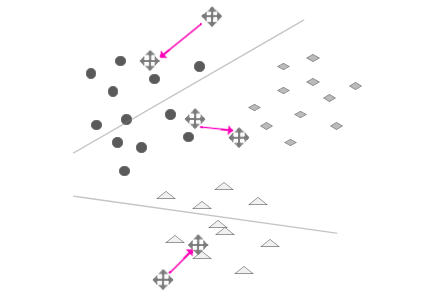 步骤4:重复上述过程,直到每次新的中心和旧的中心支局的偏移非常非常小,即过程收敛。(M-step)
步骤4:重复上述过程,直到每次新的中心和旧的中心支局的偏移非常非常小,即过程收敛。(M-step)
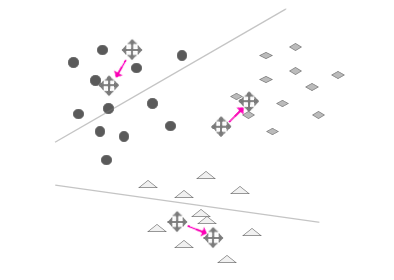
步骤5:迭代(重复E-step和M-step)
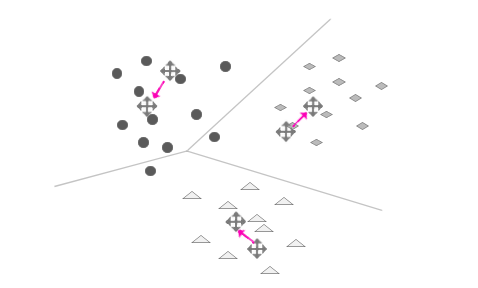
现在,我们已经实现了只利用一组观测数据自动对文本进行分类。这个方法不需要任何人工干预和先验的经验,是一些纯粹的数学计算,最后就完全得到了自动的分类,这简直有点令人难以置信!更奇妙的是,对文本分成多少类也是由观测数据自动得出的。
至此,我们已经了解了一种典型的非监督学习算法。堪称精妙!
本文由@CARRIE 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


