
 起点课堂会员权益
起点课堂会员权益语音交互:聊聊语音识别-ASR
编辑导语:语音识别已经走进了大家的日常生活中,我们的手机、汽车、智能音箱均能对我们的语音进行识别。那么什么是语音识别呢?它又能应用于哪里?该如何对其进行测试与运营维护呢?本文作者为我们进行了详细地介绍。

现在人机语音交互已经成为我们日常生活的一部分,语音交互更自然,大大的提高了效率。上一篇文章我们聊了语音唤醒,这次我们继续聊聊语音交互的关键步骤之一——语音识别。
一、什么是语音识别
文字绝对算是人类最伟大的发明之一,正是因为有了文字,人类的文明成果才得以延续。
但是文字只是记录方式,人类一直都是依靠声音进行交流。所以人脑是可以直接处理音频信息的,就像你每次听到别人和你说话的时候,你就会很自然地理解,不用先把内容转变成文字再理解。
而机器目前只能做到先把音频转变成文字,再按照字面意思理解。
微信或者输入法的语音转文字相信大家都用过,这就是语音识别的典型应用,就是把我们说的音频转换成文字内容。
语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。
概念理解起来很简单,但整个过程还是非常复杂的。正是由于复杂,对算力的消耗比较大,一般我们都将语音识别模型放在云端去处理。
这也就是我们常见的,不联网无法使用的原因,当然也有在本地识别的案列,像输入法就有本地语音识别的包。
二、语音识别的应用
语音识别的应用非常广泛,常见的有语音交互、语音输入。随着技术的逐渐成熟和5G的普及,未来的应用范围只会更大。
语音识别技术的应用往往按照应用场景进行划分,会有私人场景、车载场景、儿童场景、家庭场景等,不同场景的产品形态会有所不同,但是底层的技术都是一样的。
1. 私人场景
私人场景常见的是手机助手、语音输入法等,主要依赖于我们常用的设备—手机。
如果你的手机内置手机助手,你可以方便快捷的实现设定闹钟,打开应用等,大大的提高了效率。语音输入法也有非常明显的优势,相较于键盘输入,提高了输入的效率,每分钟可以输入300字左右。
2. 车载场景
车载场景的语音助手是未来的趋势,现在国产电动车基本上都有语音助手,可以高效的实现对车内一些设施的控制,比如调低座椅、打开空调、播放音乐等。
开车是需要高度集中注意力的事情,眼睛和手会被占用,这个时候使用语音交互往往会有更好的效果。
3. 儿童场景
语音识别在儿童场景的应用也很多,因为儿童对于新鲜事物的接受能力很高,能够接受现在技术的不成熟。常见的儿童学习软件中的跟读功能,识别孩子发音是否准确,这就应用的是语音识别能力。
还有一些可以语音交互的玩具,也有ASR识别的部分。
4. 家庭场景
家庭场景最常见的就是智能音箱和智能电视了,我们通过智能音箱,可以语音控制家里面的所有电器的开关和状态;通过语音控制电视切换节目,搜索我们想要观看的内容。
三、语音识别详解
整个从语音识别的过程,先从本地获取音频,然后传到云端,最后识别出文本,就是一个声学信号转换成文本信息的过程。整个识别的过程如下图:
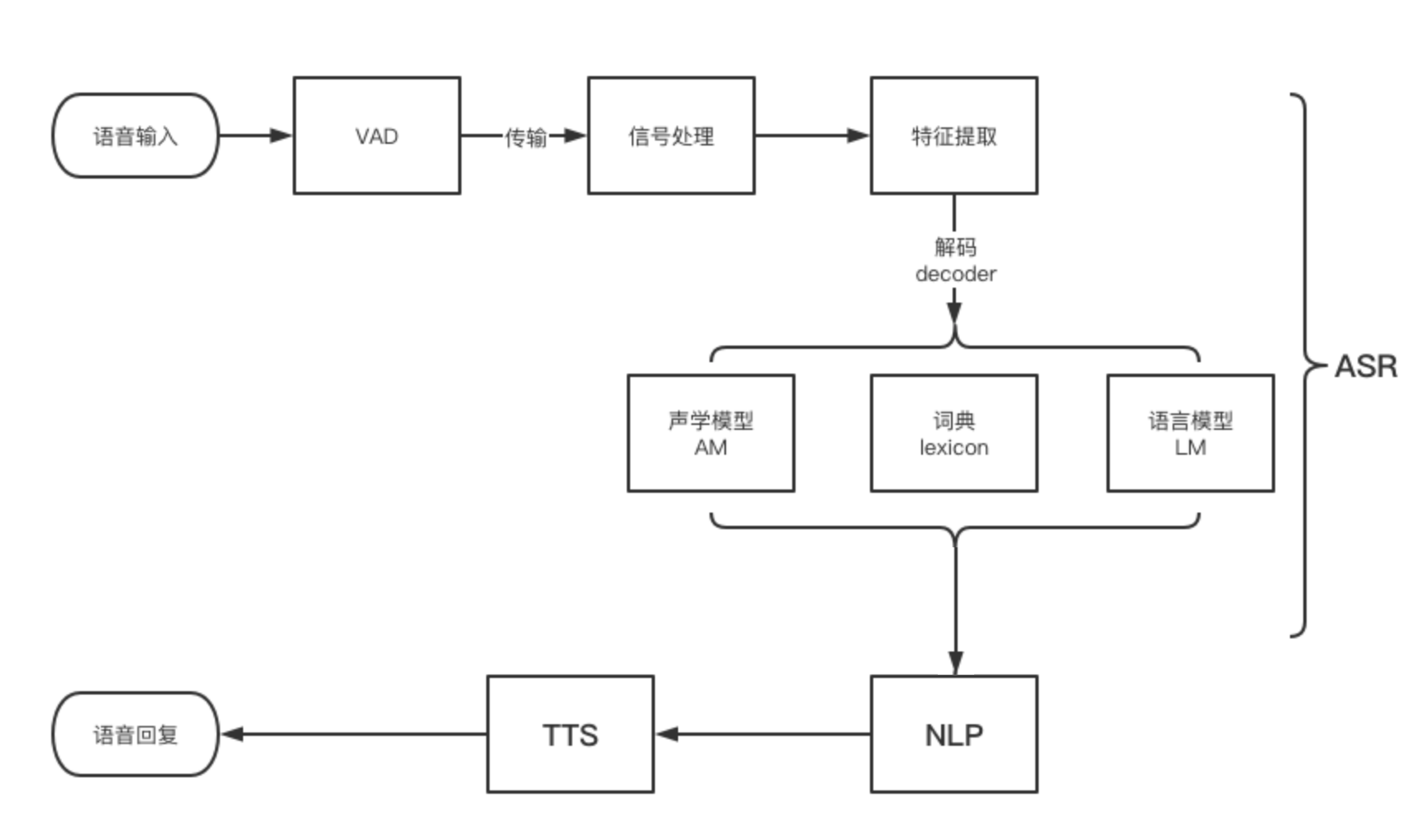
1. VAD技术
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成干扰,这个切除静音的炒作一般称为VAD。
这个步骤一般是在本地完成的,这部分需要用到信号处理的一些技术。
VAD(Voice Activity Detection):也叫语音激活检测,或者静音抑制。其目的是检测当前语音信号中是否包含话音信号存在,即对输入信号进行判断,将话音信号与各种背景噪声信号区分出来,分别对两种信号采用不同的处理方法。
算法方面,VAD算法主要用了2-3个模型来对语音建模,并且分成噪声类、语音类还有静音类。目前大多数还是基于信噪比的算法,也有一些基于深度学习(DNN)的模型。
一般在产品设计的时候,会固定一个VAD截断的时间,但面对不同的应用场景,可能会要求这个时间是可以自定义的,主要是用来控制多长时间没有声音进行截断。
比如小孩子说话会比较慢,常常会留尾音,那么我们就需要针对儿童场景,设置比较长的VAD截断时间;而成人就可以相对短一点,一般会设置在400ms-1000ms之间。
2. 本地上传(压缩)
人的声音信息首先要经过麦克风整列收集和处理,然后再把处理好的音频文件传到云端,整个语音识别模型才开始工作。
这里的上传并不是直接把收音到的音频丢到云端,而是要进行压缩的,主要考虑到音频太小,网络等问题,会影响整体的响应速度。从本地到云端是一个压缩➡上传➡解压的过程,数据才能够到达云端。
整个上传的过程也是实时的,是以数据流的形式进行上传,每隔一段时间上传一个包。
你可以理解为每说一个字,就要上传一次,这也就对应着我们常常看到的一个字一个字的往屏幕上蹦的效果。一般一句“明天天气怎么样?”,会上传大约30多个包到云端。
一般考虑我们大部分设备使用的都是Wi-Fi和4G网络,每次上传的包的大小在128个字节的大小,整个响应还是非常及时的。

3. 信号处理
这里的信号处理一般指的是降噪,有些麦克风阵列本身的降噪算法受限于前端硬件的限制,会把一部分降噪的工作放在云端。
像专门提供云端语音识别能力的公司,比如科大讯飞、谷歌,自己的语音识别模型都是有降噪能力的,因为你不知道前端的麦克风阵列到底是什么情况。
除了降噪以外可能还涉及到数据格式的归一化等,当然有些模型可能不需要这些步骤,比如自研的语音识别模型,只给自己的机器用,那么我解压完了就是我想要的格式。
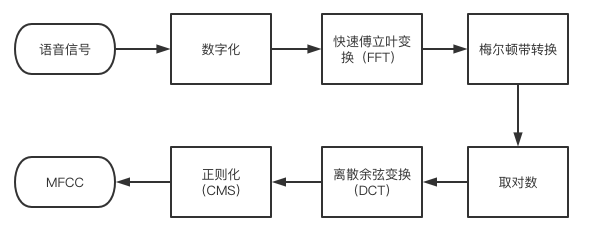
4. 特征提取
特征提取是语音识别关键的一步,解压完音频文件后,就要先进行特征提取,提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
特征提取首先要做的是采样,前面我们说过音频信息是以数据流的形式存在,是连续不断的,对连续时间进行离散化处理的过程就是采样率,单位是Hz。
可以理解为从一条连续的曲线上面取点,取的点越密集,越能还原这条曲线的波动趋势,采样率也就越高。理论上越高越好,但是一般10kHz以下就够用了,所以大部分都会采取16kHz的采样率。
具体提取那些特征,这要看模型要识别那些内容,一般只是语音转文字的话,主要是提取音素;但是想要识别语音中的情绪,可能就需要提取响度、音高等参数。
最常用到的语音特征就是梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC),是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性。
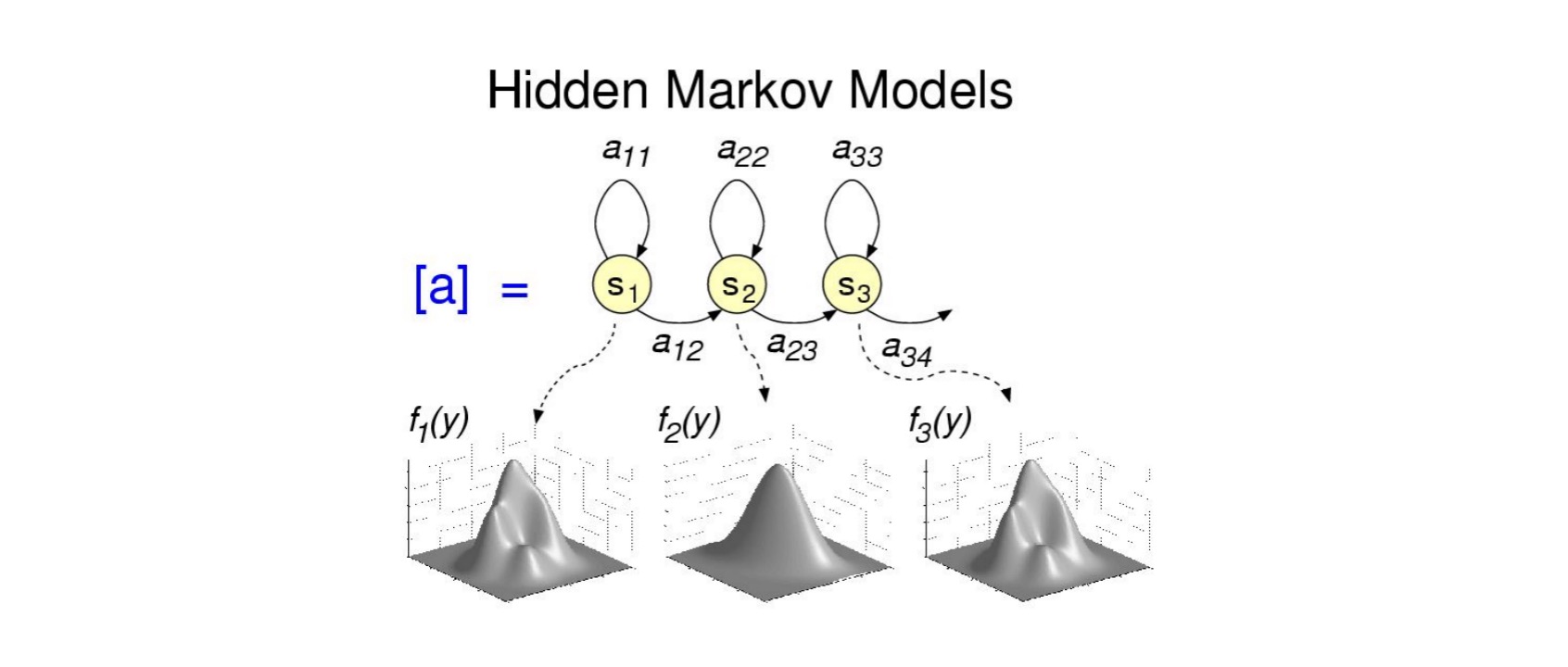
5. 声学模型(AM)
声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,计算音频对应音素之间的概率。简单理解就是把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
声学模型目前的主流算法是混合高斯模型+隐马尔可夫模型(GMM-HMM),HMM模型对时序信息进行建模,在给定HMM的一个状态后,GMM对属于该状态的语音特征向量的概率分布进行建模。
现在也有基于深度学习的模型,在大数据的情况下,效果要好于GMM-HMM。
声学模型就是把声音转成音素,有点像把声音转成拼音的感觉,所以优化声学模型需要音频数据。
6. 语言模型(LM)
语言模型是将语法和字词的知识进行整合,计算文字在这句话下出现的概率。一般自然语言的统计单位是句子,所以也可以看做句子的概率模型。简单理解就是给你几个字词,然后计算这几个字词组成句子的概率。
语言模型中,基于统计学的有n-gram 语言模型,目前大部分公司用的也是该模型。
还有基于深度学习的语言模型,语言模型就是根据一些可能的词(词典给的),然后计算出那些词组合成一句话的概率比较高,所以优化语言模型需要的是文本数据。

7. 词典
词典就是发音字典的意思,中文中就是拼音与汉字的对应,英文中就是音标与单词的对应。
其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来——简单理解词典是连接声学模型和语言模型的月老。
词典不涉及什么算法,一般的词典都是大而全的,尽可能地覆盖我们所有地字。词典这个命名很形象,就像一本“新华字典”,给声学模型计算出来的拼音配上所有可能的汉字。
整个这一套组成了一个完整的语音识别模型,其中声学模型和语言模型是整个语音识别的核心,各家识别效果的差异也是这两块内容的不同导致的。
一般我们更新的热词,更新的都是语言模型中的内容,后面会详细阐述。
四、语音识别相关内容
语音识别除了把语音转换成文本以外,还有一些其他用处,这里也简单提一下。
1. 方言识别/外语识别
这里把方言和外语一起讨论,是因为训练一个方言的语音识别模型,和训练一个外语的模型差不多,毕竟有些方言听起来感觉和外语一样。
所以方言和外语识别,就需要重新训练的语音识别模型,才能达到一个基本可用的状态。
这里就会遇到两个问题:
- 从零开始训练一个声学模型需要大量的人工标注数据,成本高,时间长,对于一些数据量有限的小语种,就更是难上加难。所以选择新语种(方言)的时候要考虑投入产出,是否可以介入第三方的先使用,顺便积累数据;
- 除了单独的外语(方言)识别之外,还有混合语言的语音识别需求,比如在香港,英文词汇经常会插入中文短语中。如果把每种语言的语言模型分开构建,会阻碍识别的平滑程度,很难实现混合识别。

2. 语种识别(LID)
语种识别(LID)是用来自动区分不同语言的能力,将识别结果反馈给相应语种的语音识别模型,从而实现自动化的多语言交互体验。简单理解就是计算机知道你现在说的是中文,它就用中文回复你,如果你用英文和计算机说话,计算机就用英文回复你。
语种识别主要分三个过程:首先根据语音信号进行特征提取;然后进行语种模型的构建;最后是对测试语音进行语种判决。
算法层面目前分为两类:一类是基于传统的语种识别,一种是基于神经网络的语种识别。
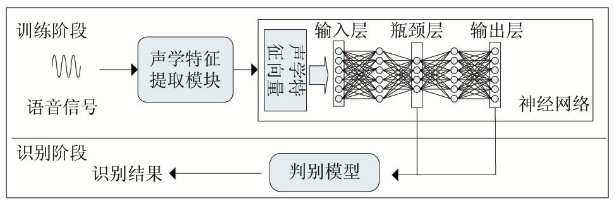
传统的语种识别包括基于HMM的语种识别、基于音素器的语种识别、基于底层声学特征的语种识别等。神经网络的语种识别主要基于融合深度瓶颈特征的DNN语种识别,深度神经网络中,有的隐层的单元数目被人为地调小,这种隐层被称为瓶颈层。
目前基于传统的语种识别,在复杂语种之间的识别率,只有80%左右;而基于深度学习的语种识别,理论上效果会更好。当然这和语种的多样性强相关,比如两种语言的语种识别,和十八种语言的语种识别,之间的难度是巨大的。
3. 声纹识别(VPR)
声纹识别也叫做说话人识别,是生物识别技术的一种,通过声音判别说话人身份的技术。其实和人脸识别的应用有些相似,都是根据特征来判断说话人身份的,只是一个是通过声音,一个是通过人脸。
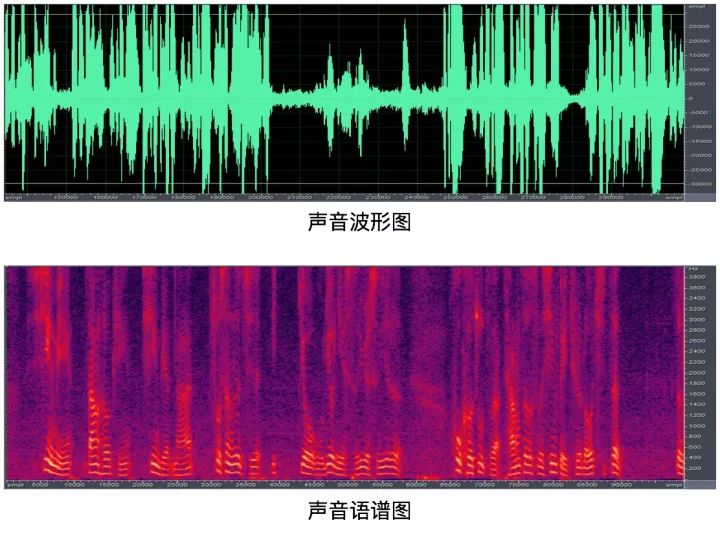
声纹识别的原理是借助不同人的声音,在语谱图中共振峰的分布情况不同这一特征,去对比两个人的声音,在相同音素上的发声来判断是否为同一个人。
主要是借助的特征有:音域特征、嗓音纯度特征、共鸣方式特征等,而对比的模型有高斯混合模型(GMM)、深度神经网络(DNN)等。
注:
- 共振峰:共振峰是指在声音的频谱中能量相对集中的一些区域,共振峰不但是音质的决定因素,而且反映了声道(共振腔)的物理特征。提取语音共振峰的方法比较多,常用的方法有倒谱法、LPC(线性预测编码)谱估计法、LPC倒谱法等。
- 语谱图:语谱图是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维信息,所以能量值的大小是通过颜色来表示的,颜色深,表示该点的语音能量越强。
声音识别也会有1to1、1toN、Nto1三种模式:
- 1to1:是判断当前发声和预存的一个声纹是否一致,有点像苹果手机的人脸解锁,判断当前人脸和手机录的人脸是否一致;
- 1toN:是判断当前发声和预存的多个声纹中的哪一个一致,有点像指纹识别,判断当前的指纹和手机里面录入的五个指纹中的哪一个一致;
- Nto1:就比较难了,同时有多个声源一起发声,判断其中那个声音和预存的声音一致,简单理解就是所有人在一起拍照,然后可以精确的找到其中某一个人。当然也有NtoN,逻辑就是所有人一起拍照,每个人都能认出来。
除了以上的分类,声纹识别还会区分为:
- 固定口令识别,就是给定你文字,你照着念就行,常见于音箱付款的验证;
- 随机口令识别,这个就比较厉害了,他不会限制你说什么,自动识别出你是谁。
声纹识别说到底就是身份识别,和我们常见的指纹识别、人脸识别、虹膜识别等都一样,都是提取特征,然后进行匹配。只是声纹的特征没有指纹等特征稳定,会受到外部条件的影响,所以没有其他的身份识别常见。
4. 情绪识别
目前情绪识别方式有很多,比如检测生理信号(呼吸、心率、肾上腺素等)、检测人脸肌肉变化、检测瞳孔扩张程度等。通过语音识别情绪也是一个维度,但是所能参考的信息有限,相较于前面谈到的方法,目前效果一般。
通过语音的情绪识别,首先要从语音信息中获取可以判断情绪的特征,然后根据这些特征再进行分类;这里主要借助的特征有:能量(energy)、音高(pitch)、梅尔频率倒谱系数(MFCC)等语音特征。
常用的分类模型有:高斯混合模型(GMM)、隐马尔可夫模型(HMM)长短时记忆模型(LSTM)等。
语音情绪识别一般会有两种方法:一种是依据情绪的不同表示方式进行分类,常见的有难过、生气、害怕、高兴等等,使用的是分类算法;还有一种是将情绪分为正面和负面两种,一般会使用回归算法。
具体使用以上哪种方法,要看实际应用情况。
如果需要根据不同的情绪,伴随不同的表情和语气进行回复,那么需要使用第一种的分类算法;如果只是作为一个参数进行识别,判断当前说话人是消极还是积极,那么第二种的回归算法就够了。
五、语音识别如何测试
由于语言文字的排列组合是无限多的,测试语音识别的效果要有大数据思维,就是基于统计学的测试方法,最好是可以多场景、多人实际测试,具体要看产品的使用场景和目标人群。
另外一般还要分为模型测试和实际测试,我们下面谈到的都是实际测试的指标。
1. 测试环境
人工智能产品由于底层逻辑是计算概率,天生就存在一定的不确定性,这份不确定性就是由外界条件的变化带来的,所以在测试语音识别效果的时候,一定要控制测试环境的条件。
往往受到以下条件影响:
1)环境噪音
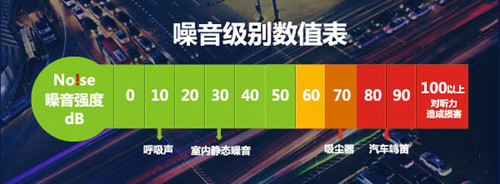
最好可以在实际场景中进行测试,如果没有条件,可以模拟场景噪音,并且对噪音进行分级处理。
比如车载场景,我们需要分别测试30km/h、60km/h、90km/h、120km/h的识别效果,甚至需要加入车内有人说话和没人说话的情况,以及开关车窗的使用情况——这样才能反应真是的识别情况,暴露出产品的不足。
2)发音位置
发音位置同样需要根据场景去定义 ,比如车载场景:我们需要分别测试主驾驶位置、副驾驶位置、后排座位的识别效果,甚至面向不同方向的发音,都需要考虑到。
3)发音人(群体、语速、口音、响度)
发音人就是使用我们产品的用户,如果我们产品覆盖的用户群体足够广,我们需要考虑不同年龄段,不同地域的情况,比如你的车载语音要卖给香港人,就要考虑粤语的测试。
这里不可控的因素会比较多,有些可能遇到之后才能处理。
2. 测试数据
整个测试过程中,一般我们会先准备好要测试的数据(根据测试环境),当然测试数据越丰富,效果会越好。
首先需要准备场景相关的发音文本,一般需要准备100-10000条;其次就是在对应的测试环境制造相应的音频数据,需要在实际的麦克风阵列收音,这样可以最好的模拟实际体验;最后就是将音频和文字一一对应,给到相应的同学进行测试。
关于测试之前有过一些有趣的想法, 就是准备一些文本,然后利用TTS生成音频,再用ASR识别,测试识别的效果。这样是行不通的,根本没有实际模拟用户体验,机器的发音相对人来说太稳定了。

3. 词错率
词错率(WER):也叫字错率,计算识别错误的字数占所有识别字数的比例,就是词错率,是语音识别领域的关键性评估指标。无论多识别,还是少识别,都是识别错误。
公式如下:
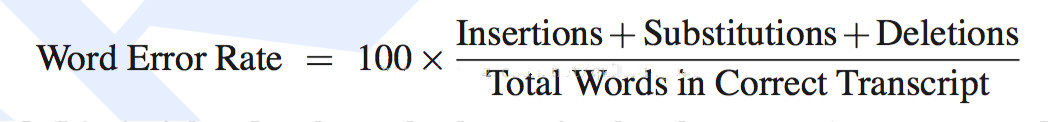
- Substitutions是替换数;
- Deletions是删除数;
- Insertions是插入次数;
- Total Words in Correct Transcript是单词数目。
这里需要注意的是,因为有插入词的存在,所以词错率可能会大于100%的,不过这种情况比较少见。
一般测试效果会受到测试集的影响,之前有大神整理过不同语料库,识别的词错率情况,数据比较老,仅供参考:
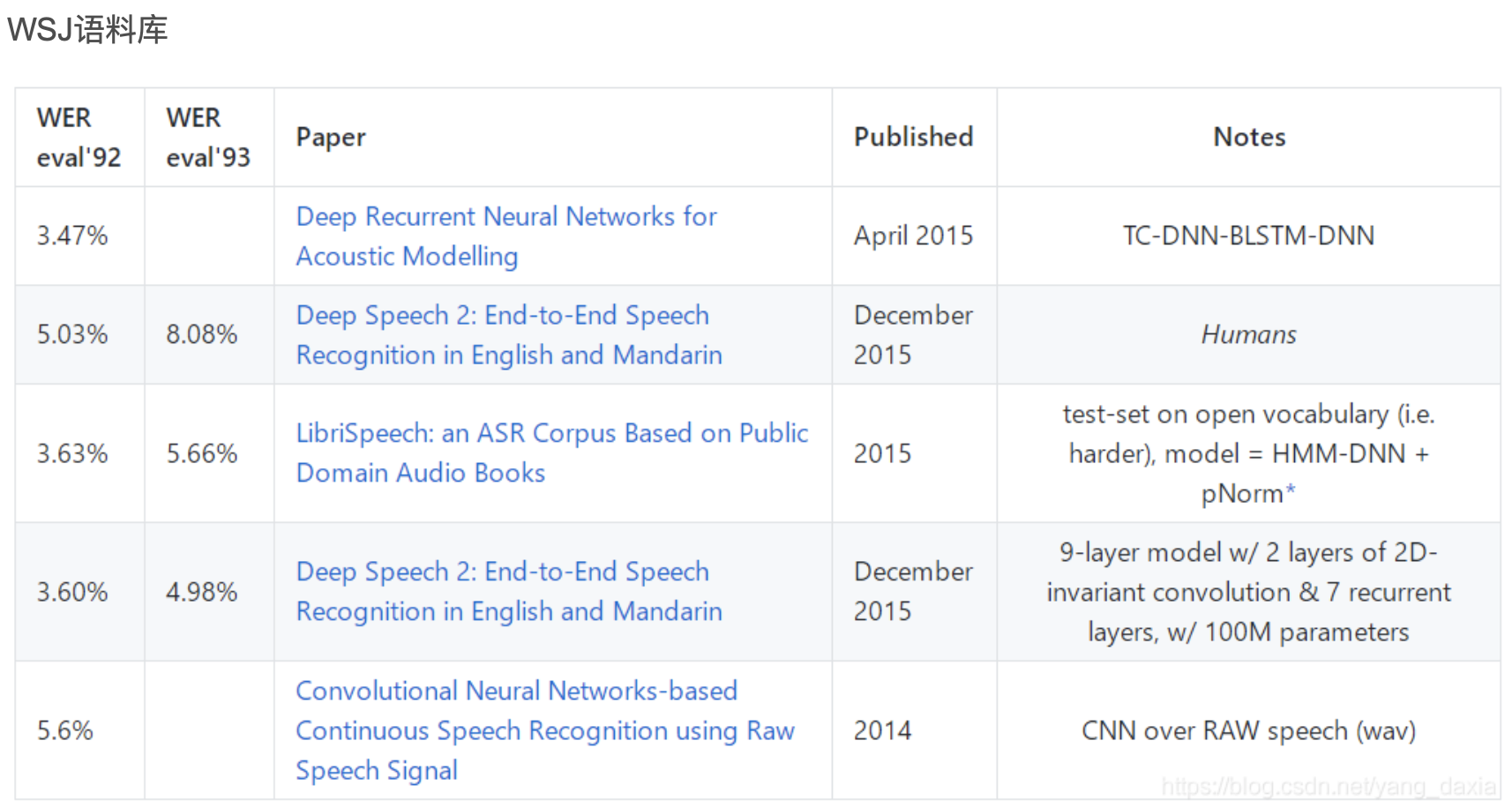
4. 句错率
句错率(SWR):表示句子中如果有一个词识别错误,那么这个句子被认为识别错误,句子识别错误的个数占总句子个数的比例,就是句错率。
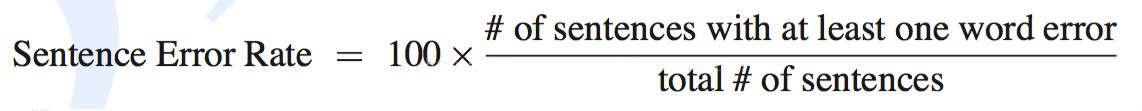
- # of sentences with at least one word error是句子识别错误的个数;
- total # of sentences是总句子的个数。
一般单纯测模型的话,主要以词错率为关键指标;用户体验方面的测试,则更多偏向于句错率。因为语音交互时,ASR把文本传给NLP,我们更关注这句话是否正确。
在实际体验中,句子识别错误的标准也会有所不同,有些场景可能需要识别的句子和用户说的句子完全一样才算正确,而有些场景可能语意相近就算正确,这取决于产品的定位,以及接下来的处理逻辑。
比如语音输入法,就需要完全一样才算正确,而一般闲聊的语音交互,可能不影响语意即可。
六、后期如何运营维护
在实际落地中,会频繁的出现ASR识别不对的问题,比如一些生僻词,阿拉伯数字的大小写,这个时候就需要通过后期运营来解决。
一句话或者一个词识别不对,可能存在多种原因;首先需要找到识别不对的原因,然后再利用现有工具进行解决。一般会分为以下几种问题:
1. VAD截断
这属于比较常见的问题,就是机器只识别了用户一部分的语音信息,另一部分没有拾到音。
这个和用户的语速有很大关系,如果用户说话比较慢的,机器就容易以为用户说完了,所以会产生这样的问题。
一般的解决方案分为两种:第一种是根据用户群体的平均语速,设置截断的时间,一般400ms差不多;第二种是根据一些可见的细节去提示用户,注意说话的语速。
2. 语言模型修改
这类问题感知最强,表面上看就是我说了一句话,机器给我识别成了一句不想相关的内容:这种问题一方面和用户想要识别的词相关,一方面和用户的发音有关,我们先不考虑用户的发音。
一般生僻词会遇到识别错误的问题,这主要是模型在训练的时候没有见过这类的内容,所以在识别的时候会比较吃力。遇到这种问题,解决方案是在语言模型里面加入这个词。
比如说:我想看魑魅魍魉,训练的时候没有“魑魅魍魉”这四个字,就很可能识别错误,我们只需要在语言模型中加入这个词就可以。一般工程师会把模型做成热更新的方式,方便我们操作。
有的虽然不是生僻字,但还是会出现竞合问题,竞合就是两个词发音非常像,会互相冲突。一般我们会把想要识别的这句话,都加到语言模型。
比如:带我去宜家商场,这句话里面的“宜家”可能是“一家”,两个词之间就会出现竞合。如果客户希望识别的是“宜家”,那我们就把 “带我去宜家商场”整句话都加入到语言模型之中。

3. 干预解决
还有一类识别错误的问题,基本上没有解决方法。
虽然我们上面说了在语言模型中加词,加句子,但实际操作的时候,你就会发现并不好用;有些词就算加在语言模型里面,还是会识别错误,这其实就是一个概率问题。
这个时候我们可以通过一些简单粗暴的方式解决。
我们一般会ASR模型识别完成之后,再加入一个干预的逻辑,有点像NLP的预处理。在这步我们会将识别错误的文本强行干预成预期的识别内容,然后再穿给NLP。
比如:我想要一个switch游戏机,而机器总是识别成“我想要一个思维词游戏机”,这个时候我们就可以通过干预来解决,让“思维词”=“switch”,这样识别模型给出的还是“我想要一个思维词游戏机”。
我们通过干预,给NLP的文本就是“我想要一个switch游戏机”。
![]()
七、未来展望
目前在理想环境下,ASR的识别效果已经非常好了,已经超越人类速记员了。但是在复杂场景下,识别效果还是非常大的进步空间,尤其鸡尾酒效应、竞合问题等。
1. 强降噪发展
面对复杂场景的语音识别,还是会存在问题,比如我们常说的鸡尾酒效应,目前仍然是语音识别的瓶颈。针对复杂场景的语音识别,未来可能需要端到端的深度学习模型,来解决常见的鸡尾酒效应。
2. 语音链路整合
大部分公司会把ASR和NLP分开来做研发,认为一个是解决声学问题,一个是解决语言问题。其实对用户来讲,体验是一个整体。
未来可以考虑两者的结合,通过NLP的回复、或者反馈,来动态调整语言模型,从而实现更准确的识别效果,避免竞合问题。
3. 多模态结合
未来有可能结合图像算法的能力,比如唇语识别、表情识别等能力,辅助提高ASR识别的准确率。比如唇语识别+语音识别,来解决复杂场景的,声音信息混乱的情况。
目前很多算法的能力都是一个一个的孤岛,需要产品经理把这些算法能力整合起来,从而作出更准确的判断。
八、总结
语音识别就是把声学信号转化成文本信息的一个过程,中间最核心的算法是声学模型和语言模型,其中声学模型负责找到对应的拼音,语言模型负责找到对应的句子。
后期运营我们一般会对语言模型进行调整,来解决识别过程中的badcase。
通过声音,我们可以做语种识别、声纹识别、情绪识别等,主要是借助声音的特征进行识别,其中常用的特征有能量(energy)、音高(pitch)、梅尔频率倒谱系数(MFCC)等。
未来语音识别必将会和自然语言处理相结合,进一步提高目前的事变效果,对环境的依赖越来越小。
本文由 @我叫人人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于CC0协议










催更!!
感觉作者分享 是整个社区看到写ASR最干货的,受益匪浅!!好奇作者是PM还是RD?
太棒了,希望作者有时间可以聊聊NLP和TTS。催更催更~
不错
感谢作者的分享,受益匪浅!