
 起点课堂会员权益
起点课堂会员权益
关于语音交互,你了解多少?
 产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..
产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..编辑导读:随着智能音箱、智能家居等智能硬件的普及,语音交互热度也不断飙升。本文从交互模式的发展出发,梳理分析了语音交互的优势、存在的问题和设计要点,并展望了语音交互的未来发展,希望通过此文能够加深你对语音交互的认识。

随着人工智能技术的发展,语音交互逐渐成为我们主流的交互方式之一,一方面是因为语音交互更加自然,一方面也得益于技术的发展。从智能音箱到智能手机,语音交互正在被大众所接受。
一、交互模式的发展
自从工业革命以来,人机交互就逐渐进入人们的视野。
- 开始是传统的按压交互,一个机械按键,按下去以后机器会有相应的反馈,就像现在手机的开机键。
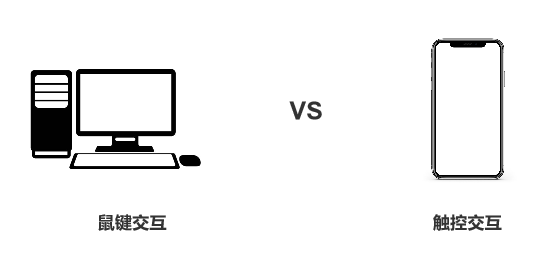
- 然后就是鼠键交互,通过鼠标+键盘这个组合,映射到可视的显示器上,点击来进行交互。
- 紧接着是触控交互,触摸屏的普及,人们开始习惯在屏幕上戳戳点点,这就是我们每天都在使用的触摸交互。
- 一直到现在,在以上两种交互的基础之上,又衍生出了语音交互和手势交互,这都是得益于大数据和人工智能的发展,这就是我们常用的智能音箱和手机助手。
- 未来最有可能被普及的就是意识交互,计算机可以识别人脑的想法,从而直接进行反馈,之前看的Facebook有一个输入法就可以通过脑电波输入,最近又有埃隆·马斯克的脑机接口演示,感觉这一天离我们越来越近。

现在语音交互在技术上也越来越成熟,识别的准确率和处理的效率越来越高,也已经有了很多落地的产品,足以证明语音交互在现在的可行性。随着5G和物联网的普及,语音交互会有更大的应用场景,让所有的物体都会说话,真是一件不能再酷的事情了。
二、语音交互的优缺点
从最开始的按压交互,到现在的语音交互,中间经历了几百年的时间,但是按压交互依然没有被完全替代,像手机上的音量按键,电脑上的键盘等,在我们身边随处可见。语音识别和自然语言处理技术这么成熟,为什么我们不能完全由语音控制呢?
这就要说到交互的基本原则,也就是什么样子的交互设计用着爽:
- 简单:尽可能的降低用户的学习成本
- 精准:能够准确的完成我们想做的事情
- 自然:符合人体工程设计,看起来像一个正常人
我们先看鼠键交互和触控交互,鼠键交互相比触摸交互,最大的优势是精准,而简单和自然就不如触控交互了。触摸是人类的天性,相比于鼠标的映射更加简单,学习成本低,操作起来也更自然,不用正襟危坐的在电脑前,随时随地都可以操作。这也是为什么手机的交互方式碾压电脑的原因,但是电脑因为有更精准的特点,也会一直存在。
没有什么方式能够比直接说话来的更简单,更自然,更不需要学习成本,但是语音交互最大的问题是不够精准。首先是受环境的影响,导致语音识别的准确率较低;再者就是表达一个意图的说法千变万化,更本无法覆盖全;最后就是语音交互是一个开放域的事情,需要处理很多意外的情况。这里还没有考虑有些场景不适合语音交互,比如会议场景,家人睡觉的时候等。
语音交互的优点和他的缺点一样突出,这也就导致语音交互最终无法取代其他的交互模式,多种交互模式会长期并存。所以我们需要结合实际场景,充分发挥语音交互的优势,而不是一味的追求语音交互。
三、如何设计语音交互?
由于技术的限制,语音交互的精确性不高,这也导致语音交互在未来很长一段时间里,不会成为唯一的交互方式,而是和多种交互模式并存,可能会处于一种辅助的状态。
在设计语音交互的时候,可以按照三步进行梳理。
1. 确定交互场景
先要考虑当前场景是否适合语音交互。适合语音交互的场景有以下几个特点:
- 环境噪音少,或者噪音处于一个稳定可控的状态;
- 使用环境私密,或者当前环境交互没有心理负担;
- 对指令下发失败容忍度高,或者有补救的方案;
- 使用对象双手被占用,或者距离操作按钮很远;
- 触发的指令意图简短且明确。
根据以上特点,我们发现手机的智能助手满足以上条件,因为手机的使用场景足够丰富,几乎覆盖生活的方方面面,那么总会有场景完全适合语音交互,所以大家都在尝试做自己的语音助手。我们常见智能音箱和车载助手,也完全符合。
2. 确定交互反馈
其次要考虑语音交互后的反馈,要能够保证信息的准确传达。简单可以把语音交互夫人反馈分为三种:
- 听懂了的反馈;
- 没听懂的反馈;
- 异常状态的反馈。
(1)听懂了的反馈:这个比较好理解,相对比较容易设计。只要知道用户所表达的意图,我们就可以给出一个明确的反馈,一般会结合视觉和听觉同时反馈给用户,并执行对应的指令。
(2)没听懂的反馈:没听懂需要分层次,是完全没听懂,还是听懂了一点,还是感觉听懂了,但是不确认,这都算在没有听懂里面。如果是完全没有听懂,一般反馈内容分为两部分,一是表示没听懂,另外需要引导用户说机器人会的内容。比如“XXXXXXX”,没有对应的处理方案,对于机器人就是没有听懂,可以回复“这个我没听懂,您可以对我说’打开空调’。”
如果是听懂了一点,只听出一个关键词,或者是说话的语气,也可以做一些回复。比如“打开XX”,没有听清后面的设备,那么就可以回复“您想要打开什么设备呢?”,然后根据反馈再做多轮回复。
如果是听懂了,但是不确认,就可以直接进行反问,让用户进行二次确认。比如“打开空条”,感觉用户是想要说“打开空调”,就可以直接反问“您是要打开空调吗?”,然后根据反馈再做多轮回复。
(3)异常状态的情况也有很多,但是我们全都需要有反馈。比如噪音、断网等情况,要提示用户当前状态,避免用户频繁交互而没有结果。

3. 确定交互关系
最后还要设定语音交互和其他交互方式的关系。往往一个设备不会只搭载一种交互方式,而是多种交互方式相结合。手机就是一个典型的多种交互方式结合的产物,所以要考虑语音和触控之间的关系,比如是否要语音支持手机关机,语音指令是否支持打断当前任务等等。
做语音交互的产品,首先要明确是否适合语音交互,其次再分层次的解决语音交互中的反馈,最后设计清楚语音和其他交互的关系。
四、语音交互的未来
说到语音交互,很多人会说这是最符合人类的交互方式,因为我们感觉人和人之间都是语音交互。其实并不是这样的,我们说话的时候,是带有表情和动作的,我们把这种丰富的交互模式叫做多模态交互。
多模态交互才是语音交互的未来。现在我们传统的语音交互,只是简单的获取了用户的文本信息,基于字面意识去做处理,高级一点的会利用上文聊过的信息,再往前一步,会根据用户画像做反馈。多模态交互不仅仅需要文本信息,同样需要视觉,音频等信息,然后根据不同的权重,作出合理的反馈。
其实在人与人对话的时候,除了字面意思外,还有很多隐藏的的信息,面对不同身份,不同关系的人,可能反馈的内容都不一样。所以需要给机器设定人设,还要对用户进行分类,有时候甚至需要做到千人千面。
语音交互相比于传统的交互模式,更依赖于算法和数据,所以语音交互的未来是需要技术突破的。
五、总结
我们生活中有多种多样的交互方式,每一种交互方式都有它的优缺点,所以很多传统的交互方式会一直存在。而语音交互是最简单,最自然的交互方式,但同样也是精准度最低的交互方式。这也就注定了语音交互将长期处于一个协助触控交互的状态,不过有些精准度要求不高的场景,也可以实现纯语音交互。
未来语音交互继续发展,将会进一步对人群进行分类,并结合多模态信息反馈。
本文由 @我叫人人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议。
















受教了