
 起点课堂会员权益
起点课堂会员权益语音交互:如何设计一个语音技能?
编辑导语:随着科技的快速发展,如今我们的生活越来越便捷,很多时候通过说话便有机器代替我们去完成一些事情,这便是语音技能带给我们的好处。日常生活中,语音技能仿佛无处不在,小到手机、智能音箱,大到机器人,那么,语音已经应该如何设计出来呢?

随着语音交互的普及,我们首先用到的最多的就是语音技能,比如:我们让智能音箱唱歌、查天气、讲笑话等,这些都是语音技能。今天,我们就来聊聊如何从零到一的设计一个语音技能。
1. 基础信息介绍
在设计语音技能之前,我们首先要掌握技能用到的一些基础定义,每家公司可能叫法上面会有区别,但是都大同小异。
1.1 基础定义
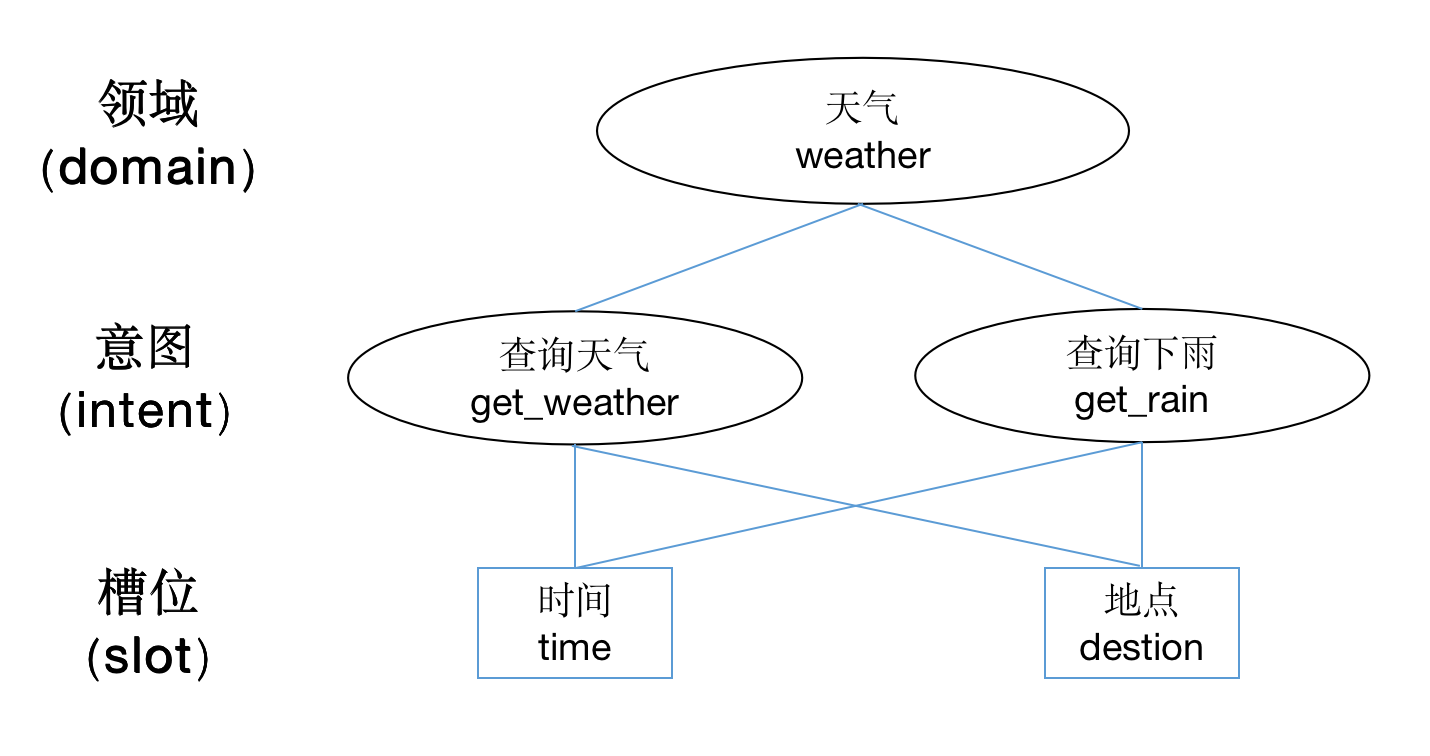
我们在聊聊语音技能常见的一些名词和定义,主要有领域(domain)、意图(intent)和槽位(slot),这些都是语音技能必不可少的一些参数内容。
1.1.1 领域
听到这个词,我们就感觉到了约束性,其实领域这个词就是约束语音技能范围的意思。一般一个语音技能,会有一个明确的领域,剩下的内容都在这个领域里面做处理。
1.1.2 意图
顾名思义就是判断用户具体要做什么的意思,领域可以是一个大范围的事情,而意图是领域中的一个小分类。
比如:让机器人跳舞是一个领域的事情,那么“开始跳舞”和“停止跳舞”就是领域下的意图的事情。意图一般会非常明确,会有明确的边界,在自然语言处理中属于封闭域的问题。
1.1.3 槽位
根据槽位的有无,语音技能可以分为有槽位的和没有槽位的。槽位一般就是指我们前面说到的实体词,用来做信息抽取用的,补全和完善用户的意图。
比如:“唱首歌”就是没有槽位的语音技能,只需要知道是唱歌的意图就可以;而查天气是常用的有槽位的语音技能,除了识别出这是一个查天气的意图之外,机器人还要知道要查什么时间、什么地点的天气,时间和地点在这里就是槽位信息。
有槽位信息的一般还会有默认槽位,就是没有槽位信息的时候,直接使用默认的槽位信息,从而保证语音技能的正常。常见的就是“天气预报”,默认的就是当地当天的天气。
1.2 底层逻辑
再聊聊一下目前语音技能的底层逻辑,基于什么能力实现的。
目前大部分做语音技能的公司,都是用正则表达式来写的,就是基于一些文本规则,作为约束条件,筛选出来明确的意图。抽取的槽位也是基于规则,或者穷举的方式。
这样做的好处是改动方便,以及改动后的影响好评估,而且冷启动非常方便,甚至可以做到每天迭代;缺点也同样明确,泛化能力弱,没有学习能力。
也有一小部分公司已经开始使用算法做语音技能了。
语音技能本质是一个意图识别的事情,而意图识别实际上又是一个分类问题,有基于传统机器学习的SVM,基于深度学习的CNN、LSTM、RCNN、C-LSTM等。
槽位识别实际上是一种序列标记的任务,有基于传统机器学习的DBN、SVM,也有基于深度学习的LSTM、Bi-RNN等。用算法做的优点就是泛化能力强,有一定的学习能力;缺点就是成本高,适合复杂技能后期迭代的方向。

2. 语音技能的定义
在开始动手做语音技能的之前,要先对语音技能进行定义,知道技能的边界,要有明确的反馈逻辑在里面。我们这里用“查天气”这个烂大街,也是最典型的技能来举例子。
2.1 定义技能
我们要明白为什么做“查天气”这个技能,以及要做到多细。
原因可能是我们就觉得这个技能很基础,用户都被教育过了,必须要有;也可能是我们看用户的交互日志,发现每天都有很多人有这个意图,现在是未满足状态,值得单拿出来作为一个技能。
还可能是老板觉得竞争对手有了,我们也要做。
假设我们是觉得是技能很基础,必须要做。接下来我们就要考虑怎么定义这个技能,需要注意以下几点:
2.1.1 要明确技能的边界,就是那些query是该技能要识别的,需要有一个明确的定义
这个看起来很容易,其实执行起来会很纠结,因为自然语言本身就有一定的歧异性。
就拿“查天气”举例子,比如:“今天该穿什么?”、“明天能不能出去玩”算不算查天气的意图,都是要明确的。其实最让你纠结的往往是模糊的语义,算作技能也不为错,不算吧,又觉得用户可能有这个意思。
所以明确的边界的时候,有三种处理逻辑:
2.1.1.1 只处理特别明确的意图,不care模糊的语义
比如:只处理“明天天气”、“查一下天气”等这样的

2.1.1.2 模糊的意图也一起处理,都归为该技能
比如:“明天该穿秋裤吗?”也属于该意图,和“明天天气”一起处理

2.1.1.3 还有一种精细化的处理,把明确的意图和模糊的意图分开处理
比如:可以让明确意图直接执行,模糊意图选择反问,用户确认后执行。用户一旦确认后,以后这句话就归位了明确意图。
比如:用户问“今天穿什么出去好呢?”,计算机回答“您是不是想查询今天的天气?”,用户回答“是的”,计算机回答“今天北京气温20度,适合……”;然后下次用户问“今天穿什么出去好呢”,计算机就可以回答“今天北京气温20度,适合……”,反之亦然。
当然如果模糊问的问法比较多,可以专门做意图优化。

2.1.2 明确技能的领域、意图和槽位的信息
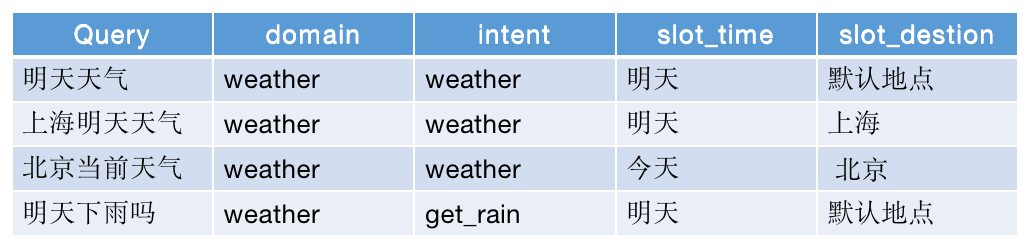
就拿“查天气”这个技能为例,领域我们一般设置为“weather”,但是意图定义就会有两种方案:
一种是简单的,只有一个意图,比如意图也是“weather”;还有一种是精细化的处理,有若干饿意图,比如“北京空气质量?”算是“get_haze”,“今天会下雨吗?”算是“get_rain”等,就是每个不一样的问法,对应不同的意图。
本质上越精细化的技能,给用户的体验会越好。

2.1.3 考虑技能内多轮的支持,以及支持的效果
由于自然语言先天是具有多轮属性的,很多时候需要借助上轮的信息,才能理解这句话,在做语音技能的时候,也要考虑到这方面的可能。
比如:用户先说“明天天气”,紧接着,用户又说“后天呢?”,这个时候是否考虑支持,都需要在定义技能的时候明确。像用户隔多久的多轮需要支持,支持的逻辑,我们这里就不展开了。

定义好了技能,就知道了这个技能能干什么,方便后面的测试同学测试,也知道未来要迭代的方向。一般如果没有数据支撑的话,建议先做最基础的就可以,边界越小越好。
2.2 触发技能反馈
反馈这块一方面依赖于产品底层的设计;另一方面依赖于产品形态,按照有无屏幕,可以简单的分为两种产品形态:有屏幕和没有屏幕。这两方面结合,才能设计出一个人性化的体验。
产品的底层设计要考虑意图要不要细化,比如:“今天有雾霾吗?”和“今天天气怎么样?”这两种问法有没有必要分开处理,设置不一样的回复内容。
还要考虑如果槽位超出技能的边界怎么处理,比如:“三年后的天气预报”,这个时候我们需要怎么反馈,都是需要在语音技能定义的时候写清楚。
具体怎么展示以及怎么回复,就要依赖于产品形态考虑。
有屏幕的可能更多的信息会通过屏幕展示,语音只是做到一个提醒的效果,有些场景甚至都不需要语音,而没有屏幕的就要考虑语音播报的表达方式,要注意文字的长度,都播报那些内容,播报的先后顺序,甚至播报的句式的丰富度都要考虑。
技能的反馈,是用户直接能够感受到的,其重要心怎么强调都不为过,这块可以参考语音交互的设计规则。

3. 数据的准备
前面说到的都是产品设计的时候要考虑到的问题,如果你把技能已经设计的差不多的时候,就可以准备这个意图的训练和测试数据,因为我们最终语音技能的开发是基于数据的,数据覆盖的越全面,技能的效果越好。
无论训练数据还是测试数据,简单可以把数据分为两部分,正例和反例。
3.1 正例数据
正例数据指的是正常的触发文本,就是你设计的触发query,像“明天天气怎么样”、“天气预报”、“查询天气预报”等,这些都是我们定义的“查天气”的意图。
一般在准备正例的数据时,最关心的是数据的来源,还有数据的丰富性。
如果是冷启动的话,建议团队内部,或者有专门的数据部门,进行人肉泛化,就是每个人自己写几条符合意图的触发query。
这里亚马逊在做智能音箱的时候有一个要求,就是每个意图的正例训练集的数据,不能少于30条(测试数据也一样)。数据来源就是公司员工制造,数据丰富性就是依靠数据量标准约束。
如果是语音能力已经有了,每天都有大量的交互数据,我们就可以从真实的交互中拿数据。导出交互日志需要逐一标注,从中找到属于该意图的数据。
这些数据的好处就是更加贴近用户真实的情况,缺点就是成本会比较高,但一般都是可控的。
基于现有的交互数据标注,可以轻轻松松准备30该意图的数据,建议越多越好,100条以上为最佳。数据来源就是用户的交互,数据丰富性是依靠用户的。
3.2 反例数据
反例数据指的是非该意图的数据,就是除了正例数据,理论上所有的数据都是反例数据。像“明天要是不下雨就好了”、“我知道现在在下雨”、“我不想查天气预报”等,这些都不是我们定义的“查天气”的意图。
很多时候,我们做语音技能的时候,是很容易忽略反例数据的。
反例数据最好是能够有意图相关的关键词,数据量最好可以和正例数据一样多。在准备反例数据的时候,要注意一些意图相反的操作,比如:“我不想查天气预报”,这是比较典型的反例数据。
往往反例数据比正例数据要难收集,尤其是高质量的反例数据,一般交互日志是最好的资源。

正例数据可以保证准确率,而反例数据可以减少误召回,提高召回率。
4. 语音技能的实现
训练数据准备好之后,就是技能的实现了,这块需要工程师的支持。有些公司是工程师直接写语音技能的逻辑,有些公司是会提供一个平台,通过培训,让产品经理和运营同学也可以写。
这里就会用到一些基础能力,当一句query传过来,首先会使用中文分词对这句话进行分词。
比如:“北京明天天气怎么样”,会被分为“北京”、“明天”、“天气”、“怎么样”,然后就是命名实体识别;比如:“北京”就是地点实体,“明天”就是时间实体,对应的就是语音技能的槽位。
最后就是匹配我们写的正则表达式,这里就不过多赘述,感兴趣的同学可以搜搜看。
中文分词:为什么叫中文分词呢?因为英文是以词为单位的,词和词之间是依靠空格和标点隔开的,而中文是以字为单位的,一句话的所有字是连在一起的。
所以就需要算法把一句话切分成有意义的词,这就是中文分词,也叫切词,主要为了NLU后面处理做准备。了解锤子手机的人可能知道上面有一个叫做“大爆炸”的功能,就是基于该算法的。
这是NLU最底层的能力,一般都是用的开源的算法,大家能力相差不大,基本可以保证准确率在90%以上。
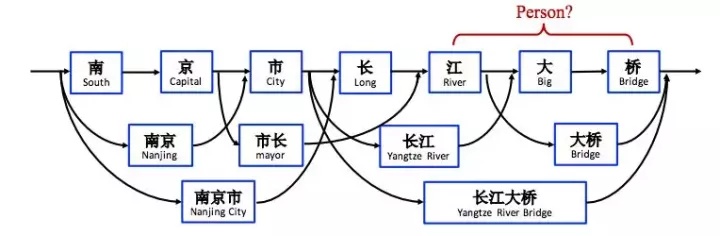
命名实体识别:词性标注是把每个词的词性标注出来,而命名实体识别是指识别文本中具有特定意义的实体,包括人名、地名、时间等。
一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
这个一般会根据本身业务的需求进行调整,不做明确的限制。
还有比较简单的实现方式,就是通过穷举实体+写正则的方式,而不需要用到模型去做处理。
比如:“查天气”这个技能,我们通过穷举的方式,把表达地点和时间的词语都穷举出来,然后分别存到词典里面。最后使用这两个词典写一些正则表达式,用来覆盖我们准备的训练集。
这样做的的前提需要是实体词是可以穷举的,否者就会遇到召回率很低的问题。除了实现方法,我们还要考虑实现过程的效率,以及实现效果怎么样。
5. 测试验收效果
一般的语音技能开发会比较快,开发完成之后就是验收了,验收最关心的指标是精准率和召回率。
5.1 验收指标介绍
本质上就是计算机判断了一次,然后人工判断了一次,默认以人工判断的为真实标签,计算机判断的为预测标签,如下表:
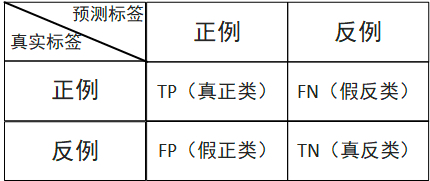
5.1.1 精准率(Precision)
计算机认为对的数据中,有多少判断对了。
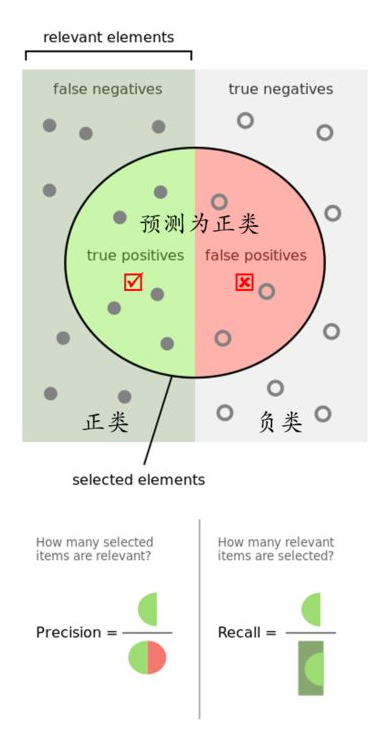
精准率表示的是预测正例的样本中有多少是真正类,预测为正例有两种可能,一种就是真正类(TP),另一种就是假正类(FP),公式表示如下:
![]()
5.1.2 召回率(Recall)
的样本中,有多少被计算机找出来了。
召回率表示的是样本中的正例有多少被预测正确了。也只有两种可能:一种是真正类(TP),另一种就是假反类(FN),公式表示如下:
![]()
其实就是分母不同,一个分母是预测标签的正例数,另一个真实标签的正例数。一般情况这两个指标都会在0-1之间,越趋近于1,语音技能的效果越好。
5.2 验收步骤
验收这里分为两个步骤:一个NLU批量验证;一个是端到端验证,都可以用测试集来验证。
NLU批量验证就是把测试集的query,全部通过语音技能的逻辑跑一边,一般用来验证技能在NLU上面的效果。通常这一步只会测试新增的技能,单独测试这个技能的效果,主要关心的是精准率和召回率,这一步理论上来说,必须这两个指标都要达到95以上。
端到端验证是模拟用户正常使用,需要把技能放在整个语音链路上面,来观察语音技能在实际情况中的表现。
通常这一步才会发现一些问题,比如:语音技能之间的冲突,甚至会发现ASR识别不对的情况。这一步主要关心响应时间、语音技能是否正常等情况。
测试一定要把好最后一道关卡,保证语音技能的精准率和召回率,同时也要测试技能之间优先级的关系,是否技能之间会出现优先级的问题。如果有多轮的语音技能,也要测试多轮的效果。
6. 总结
做一个语音技能,产品首先要有一个明确的定义,其次就是基于产品定义准备训练集和测试集,然后基于训练集完成技能的开发,最后使用测试集进行验证。
本文由 @我叫人人 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议。










人人兄,有空接着更,超级赞哦!!!
最近单位有项目是语音交互领域,自己之前没有做过,有没有书籍课程推荐一下哦 谢谢啦
正在做这方面,哇
在BAT做类似领域的 希望有机会交流下,作者是不是腾讯滴?嘻嘻
你是那家单位的?讯飞,百度,or其他?
其他,哈哈哈
点赞!!!
谢谢