
 起点课堂会员权益
起点课堂会员权益人机交互过程拆解:是什么?怎么做?
编辑导读:AI改变了我们与机器互动的方式,影响了我们的生活,重新定义了我们与机器的关系。本文作者对人机交互的过程进行了分析拆解,对语音识别技术为什么能把语音信号变成文字展开了详细的说明,一起来看看~

背景:市面上有哪些搭载类似交互系统的产品?
微信的小微平台、淘宝的淘小蜜、钉钉的智能工作助理、百度的小度等等,既有面向C端消费者,又有面向B端企业主,如果要论商业化的潜力无疑目前机器人行业很大程度上C端的机器人产品已经几乎被验证无法实现盈利了,参考微软小冰和siri,不过未来教育行业的幼儿机器人也许是一条光明大道。
更多的厂商已经转向了帮助企业主实现数字化管理、智能化办公而开发机器人能力,演化除了机器人的自定义平台,用于企业运维和管理。
智能语音交互系统简单来讲:就是语音识别+语义理解+TTS
虽然说的简单,但是内部系统往往都比较复杂,每个点拆开来可能就足够我们去研究迭代一生。为何说AI时代的重点和基础是语音智能交互?在人工智能时代,人们发现语音比文字输入更能收集到有用的大量信息,这也是一种未来的主流形式。
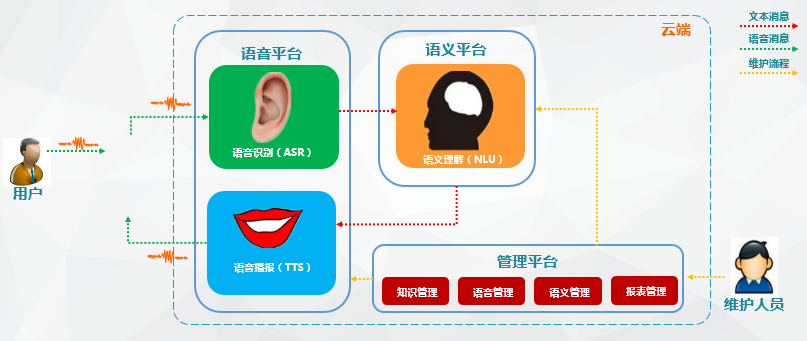
语音交互流程
智能语音交互系统概括起来就是一段音频被机器人所吸收检测,将识别到到的语音信号截取、转换成语料库里读音信号频率最为相近的文字(所以也有人形容语音识别其实是一种概率事件),而文本会通过特定接口进入语义分析引擎,进行分析。其中就可能要进行分词、命名实体识别、词性标注、依存句法分析、词向量表示与语义相似度计算等NLP基础功能。
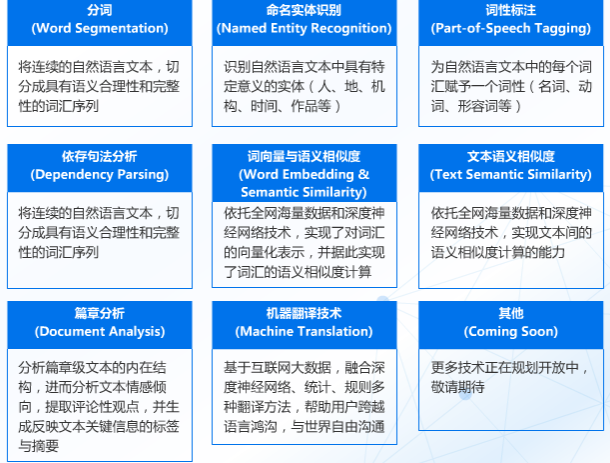
NLP基础技术
一般情况下都会首先进行分词分析:
例如:我想在房间里看电影
分词:【我】【想】【在】【房间】【看】【电影】
这就是分词的效果。而分词的目的是为了找出文字中最重要的核心语义,命名实体识别功能(假如需要的话)
分词:【我】【想】【在】【房间】【看】【电影】其中涉及到人物、地点、作品这些词汇就可以自动被提炼出来,很多应用场景会需要用到这种信息分类识别的能力,比如人口录入系统,只要将基本信息复制进去,自动分类此人的身份证号码、地址、年龄等需求信息。
词性标注:词性标注可以帮助我们找到其中的名称、动词、 形容词等。
依存句法分析的主要功能是能够针对句子找出句子的核心部分,比如分词:【我】【想】【在】【房间】【看】【电影】
经过词性标注和依存句法分析之后可以找出这句话的观点是:【在】【房间】【看】【电影】,这是整句话的核心。
从而我们可以通过检索知识库中和分词内容相似度计算,并输出相似度最高答案。
而词向量与相似度主要能解决什么问题呢?比如西瓜、呆瓜、草莓,在语义上哪两个更像呢?
这个时候我们可以将这三个词通过向量表达式工具和计算相似度来解决:
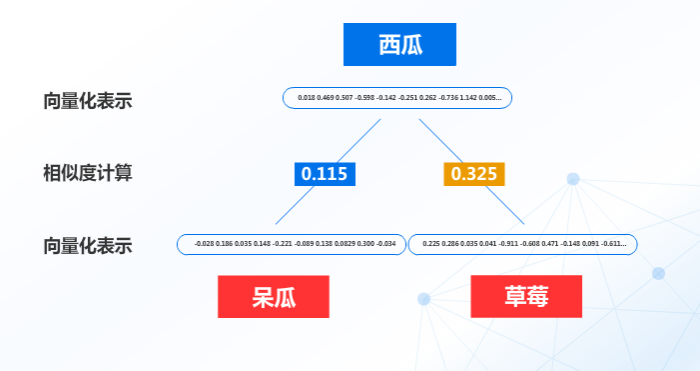
可以明显的看出,语义上西瓜和草莓更相似,同属水果,这样就解决了大部分字面意思相近但是语义差别较大的情况,避免机器人错误理解人类的意图。
回到题目,当我们的文本进入语义分析引擎,并经过上述的步骤后,计算相似度从而触发设定阀值以上的答案即可请求服务器发送正确答案给到终端处,如果需要机器人播报返回的文字时,可以接入TTS语音合成引擎(一般语音识别引擎就有这项功能)。

简单的来讲,语音交互系统流程框架大致如此,无论是软件语音交互机器人还是实体机器人,本质上流程变动不大,根据业务需求会有些许差别,比如展示相关问,模糊问题引导,词汇纠错等需求就需要插入特定的流程。
通过上面所写的内容,希望能让大家大致了解市面上搭载智能语音交互系统的产品后台流程,也能明白一个简单的对话框背后所涉及的技术高度。
四款人机交互系统:小i机器人、siri、汉娜、Echo。当然还有市面上众多针对toB的机器人产品
今后真正的个人虚拟助理一定会搭载智能语音交互系统,并且会调用各种让你意想不到的功能,从而成为你强大的私人秘书,能想象我们只需要说一声帮我订今晚到北京的机票,并通过语音密码付款即可完成购票的整个流程吗?这种场景真正商业化会在10年内大规模爆发。
说到这里有必要给大家普及一下语音识别的一些细节内容,有人说:我很纳闷,怎么就能把语音变成文字?
在AI越来越普遍令大家感到新鲜的同时,一些专业名词也让大家开始熟悉起来,起码也都能了解到一些术语所代表的含义。
例如:语音识别就是把语音信息变成文字的技术;自然语言处理就是能让机器人理解人类通用语言的技术;人脸识别就是拍个照就能认出你是谁的技术。不能不说技术的普及,生活水平的提高会让人们对技术基础的理解程度也越来越高,接受能力也变得很高。
经典案例:90年代我国开始研究二维码,但是大家并不熟悉,关键在于没有产品使得二维码变得普及,几年前微信和支付宝开始率先使用二维码支付后,二维码迅速成为大街小巷最普及的东西,大家从一开始的质疑到将信将疑最后变成信任,这就是技术普及的力量,让这种新鲜的技术变成一种社会的常识。
这篇文章我会详细给大家解释一下语音识别技术为什么能把语音信号变成文字?
过程的第一部分就是发送一段语音信号,有点像是心电图频率的波动,下图我们先介绍一下语音识别的整个流程,先有个概念。
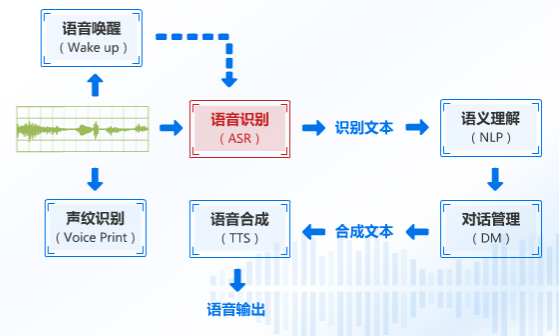
语音识别流程图
这段音频进入语音识别引擎之后,就会送出识别到的文本,我们将这个文本发送给语义分析并处理,进而得到相似度最高的答案,并合成文本发送到语音合成引擎之中进行语音输出。
那么重点来了这个【ASR】是怎么让语音变成文字的?
接下来我们继续分解,看下图:
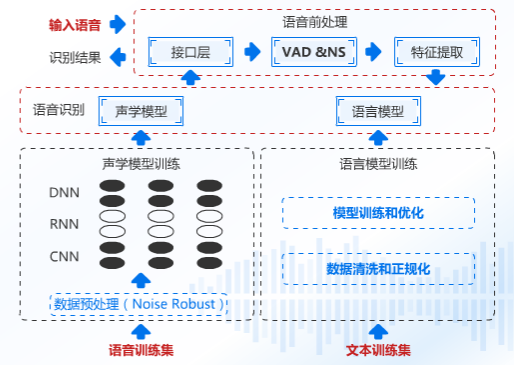
语音预处理
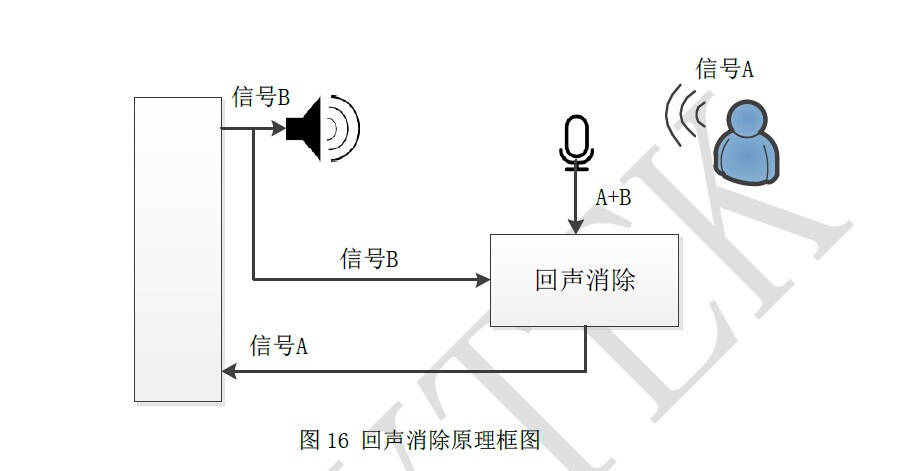
语音信号通过我们的接口送进语音引擎中,这段语音信号的质量其实是比较差的,这段语音有周围的噪声,机器本身噪声,所以我们先要做的处理就是降噪、回声消除、端点检测,可能大家不是很理解回声消除是怎么抑制回声的,我给个原理图示大家应该就明白了:
做完了语音预处理之后,把相对比较纯净的信号发送给特征提取部分,这个部分主要干什么呢?
我们人和人是不同的,肤色、身高、体重、样子这些都是特征,而语音部分我们提取什么呢?信号频率、振幅,这其实就是每个人音色不同的秘密所在,将这些特征提取送到语音识别引擎的声学模型中去。它会自动匹配这些语音信息最大概率的发音汉字。说白了就是这个读音是哪个汉字的读法,然后把这个汉字单独拎出来。
其实什么是声学模型呢?简单来讲就是一种刻画(拼音读法)韵母a、o、e,声母b、p、m这些的模型,那这些模型是怎么来的?它是怎么知道这个字怎么读的呢?这个时候我们就需要输入一些音频训练集了,例如我们正常说话一段话,同时输入刚才说的那一段话的文本,机器会自动取出其中不同的因素,并且拿去继续训练模型,修正误区。
这样对于机器算法来说,有了输入和输出,还能不断优化自身模型。算法是不是很神奇。这些不同因素数据会先进行预处理,例如百度就做了一定的加噪处理,这样在噪声环境下鲁棒。
其中语音识别模块除了声学模型之外还有一个同等重要的模块就是语言模块,什么叫语言模块呢?就是刻画文本和文本之间概率权重的。那么语言模型是怎么来的,假如我们要想做医学领域的语言模型,那就要让它去学习很多医学术语,这个时候就需要我们准备这些术语做成一个词表,但是同样需要数据清洗,原始数据会有些垃圾,在做一些权重的正规化,并送到模型中去训练,从而得出或者优化原有模型。简单说你提前给医学领域的专用术语背下来了,下次一听到相关的语音你就能记起来这个专用术语。
例如【板蓝根】,训练之后一听到这个语音就不会识别成【版烂根】
这样我们最终就能得到这个语音识别的模型,并且我们可以通过继续迭代来优化这个模型
既然模型有了,那怎么看好还是差呢?有几个方面来分辨。
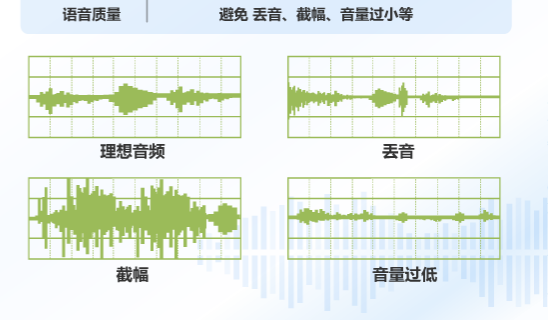
理想音频就是识别质量较好的情况,但是现实生活中语音识别往往回因为各种情况导致识别效果不佳,比如丢音,比如你按下手机麦克风按钮时,还没有启动录音你就开始说话了,那没启动时说的语音就被丢弃了,这种情况识别就差很多了,什么叫截幅呢?就是一般语音识别都是用两个字节来表示一个语音的取值范围,当你的增益太大就会被自动截掉,识别的效果也较差了。
回过头来,我们刚才所得到的语音训练模型只是一种特定情况下得到的语音模型,不具备普适性。为何这么说呢?
我们所得到的医学领域模型,假设是用手机录音采集的语料,那么这个模型就是近场识别模型,一旦同样的术语【板蓝根】你用手机询问就能回答正确,但是你一旦用音箱远场询问,那很可能就得出错误的回答,这叫声学一致性。
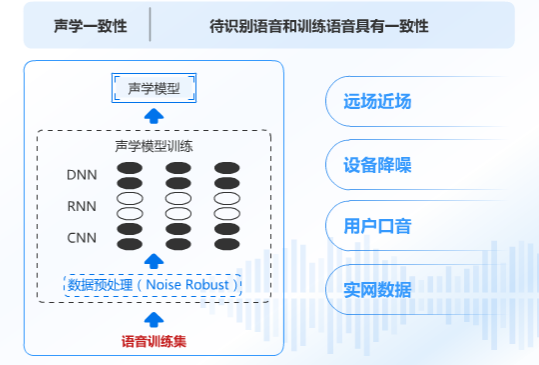
同样,不同领域也需要文本一致性,你希望这个领域能多识别该领域的专业词汇那就需要多训练这个领域的核心词汇,否则就会出现【板蓝根】的情况。
最后,通过不断的获取到不同的音频数据、文本数据,并继续迭代优化,我们会得到更好的模型,识别更准的效果。
这就是识别的细节,这也是一种科技的魅力,众多步骤完成了我们看似简单的动作。与其说机器的紧密不如说人类的身体系统更加复杂与奥妙。
本文由 @南国书生 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。






- 目前还没评论,等你发挥!


