
 起点课堂会员权益
起点课堂会员权益人脸识别之图像预处理
编辑导读:虽然技术的进步,人脸识别在生活中的应用越来越普遍。在上篇人脸识别的基本原理中,作者介绍了人脸识别背后的原理和方法,本文顺着这个思路继续完善人脸识别的基本产品原型,希望对你有帮助。

一、产品原型
简化的产品原型中包括识别前端和识别服务器两部分。
识别前端承担人脸照片采集和识别结果反馈职责,是面向用户交互的入口。目前主流的产品形态包括人脸考勤机、人证核验终端和人脸识别闸机等。
人脸识别服务器主要包括人脸底库管理和识别算法管理,并基于产品特点包含对应的业务模块,如考勤报表、预警记录等,实现基本的业务闭环。
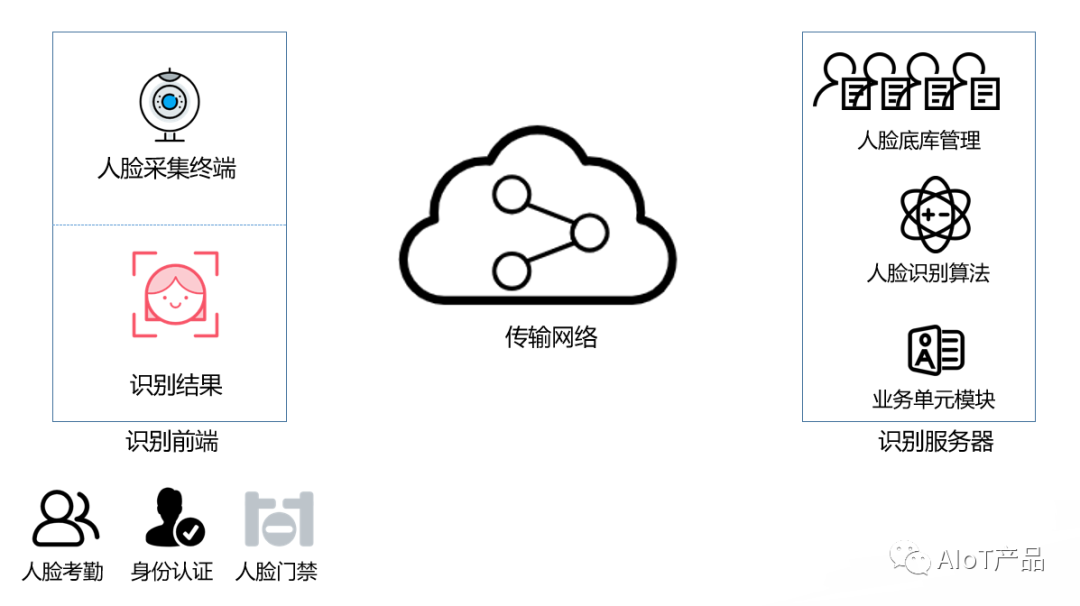
目前的产品原型,已有了基本框架,但系统需求和设计较简单,无容错能力,用户体验较差,离可用有较大的差距,需要继续对需求深化和细化。
人脸识别在实际使用中可能出现以下情况:
- 采集到的人脸照片角度、大小等和预设的人脸底库不一致,系统无法辨识;
- 采集的人脸照片和人脸底库像素不一致,系统无法进行相似度计算;
- 环境、灯光等干扰造成成像质量较差,导致漏识别、误识别;
- 比对速度较慢,精准度不够,用户使用抱怨多。
二、解决思路
在产品研发过程中,经常会出现这种产品实际体验和预设体验不一致的状况。当发生这种情况时,需要认真分析原因,理顺解决思路,不断对产品迭代升级。
上面的问题其实可以分为两类:
第一类是因为环境、距离、角度等因素干扰使得采集到的照片和系统底库照片不一致,导致相似度计算有问题;
第二类问题是人脸相似度计算速度太慢、精度偏低。
其中第二种问题一般出现在算法层面,需要协同算法工程师进行算法更新、升级进行解决。
我们将目标聚焦在第一类问题,即待识别照片和识别底库不一致的情况。这种情况下,我们可以分别从采集照片和底库照片两个角度入手,提出针对性的解决思路:
思路一:限制通过前端采集到的照片,保持与人脸底库的一致性。
比如,当强制采集照片和底库都采用身份证照片时,系统比对通过率较高。类似的方法在较早的人脸考勤机中使用,通过限制用户在打卡时的表情、距离、光线等提升精度,并强迫用户通过同样的前端采集并识别人脸,俗称「同源识别」。
强迫用户在人脸打卡时保持姿势固定不动,用户体验很差。目前市面上主流的人脸识别系统均采用「动态识别技术」,不限制用户保持静止,在移动过程中即可完成识别过程,并且不要求采集照片和识别照片同源。
思路二:增加底库中照片的数量,将人员不同角度、环境、距离的照片都录入系统,提高比对的成功率。
这种做法操作难度很大,变量条件过多,基本无法实施。即使系统存储了多张照片,问题没有完全解决,识别精度并没有明显提升,且由于增大了数据量,增加了运算的复杂性,降低运算速度,系统响应时间也相应延长。
既然没有办法限制采集照片和底库照片,在基本不影响精度和速度的前提下,可以在采集和比对之间插入中间环节,对照片进行处理,使得两者尽可能相似。
在人脸识别和其他图像处理领域这是种通用做法,并有专业名称叫做「图像预处理」。不管是在传统的人脸识别系统还是基于深度学习的人脸识别系统中,都少不了这个环节。对原有的系统设计更新如下。
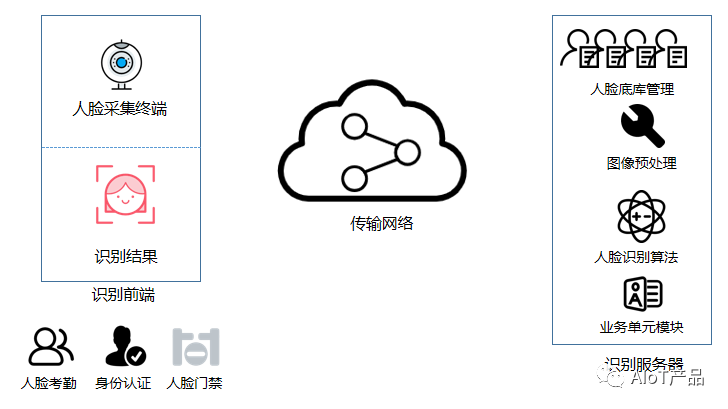
接下来对图像预处理所包含的内容和需求做简单的介绍。
1)设置ROI
当图像内容包含过多像素时,系统很难定位到有效信息。比如,当图像整体像素大小为800*800,包含人脸的区域像素只有200×200,其他均为背景,直接比对效果很差。可以对图像进行预处理,快速找到包含有效信息的目标区域,即Region of Interest(ROI),「感兴趣区域」。
在人脸识别系统中,可以对采集到的人脸照片,通过方框、圆、椭圆、不规则多边形等方式勾勒出需要处理的区域,在这个区域内进行进一步处理或者直接对比。
寻找ROI有很多方法,比如基于肤色。从颜色上看,不同颜色人种的肤色在照片上具有稳定的特征,不会随表情、角度、尺寸等而发生变化。可以根据肤色属性的这种特点和规律建模,快速识别到人脸ROI,从而将人脸区域和非人脸区域分开。
2)几何变换
由于成像、采集角度等原因可能造成采集的人脸有一定的变形,对于肉眼来说这些变形并不会带来太大的干扰,但对计算机来说却是截然不同的。
这种情况叫做图像的「几何失真」,可以对图像进行缩放、翻转、仿射、映射等几何变换最大程度地消除。几何变换通常不改变图像的像素值,而是将像素进行坐标变换,改变像素之间的排列关系,进而将注意力集中在图像内容本身的特征,而不是位置、角度、尺度等其他信息。
3)阈值处理
几何变换由于不改变图片的像素值,无法解决由于灯光等环境因素导致图像呈现出不同情况。以灰度图像为例,使用8bit表示某一像素时,单像素就存在256个灰度阶,直接利用灰度阶进行计算会带来计算误差。
这种情况下,需要对灰度阶进行限制,尽量将采集图像和底库照片的灰度阶统一,从肉眼上图片可能会有些失真,但不影响计算机的处理和识别。可以根据实际情况,将256个灰度阶划分为几个区间,将区间内的像素指定为某一个像素值,减少不同灰度值所带来的影响,这种处理方法称为「阈值处理」。
4)噪声去除
图像在形成、传输过程中往往会受到干扰,在结果图像中引入噪声。轻度的噪声信号不会干扰图像的可观测性,但当噪声严重时,图像中呈现出较多的无用信息,人脸无法识别或出现误识别等情况。

在尽量保留图像可观测信息的情况下,检测出现的噪声并进行过滤,这个过程叫做「图像滤波」。图像滤波是图像预处理中不可缺少的环节,一般通过构造图像滤波器进行解决。滤波器可以高效地去除噪音,能够保留图像目标的特征,并不会损坏图像轮廓及边缘。
对于图片中经常出现的噪声,通过统计学手段可以发现其特点,进而开发出通用滤波器,比如均值、中值、方框、双边等滤波进行噪音过滤。
当然,有一些噪声使用成熟的滤波技术去除时效果较差,而必须自行设计滤波,这种方法也被称为「卷积技术」。
不管是在传统机器学习还是基于深度学习的人脸识别系统中,都采用了卷积技术,不同点在于值的填充方式。传统系统由人工进行设计并填充,而深度学习可以通过自动学习得到所需要的值,处理起来更加灵活、高效。

5)其他处理
除了列举到的常规预处理手段,人脸识别系统中还会用到其他预处理手段,比如颜色变换、图像分割等。这些需求可以根据具体场景下图像的特点和产品需求进行细化,实现图像更精细化的处理。
除了进行图像质量处理,在产品设计时也需要考虑性能指标。由于增加了预处理手段,可能会影响人脸识别速度,增大了系统响应时间,所以必须在精度和速度之间取得平衡。
很多时候,往往是由用户需求驱动技术的进步。对于人脸识别系统来说也是如此,为了增强抗干扰能力而增加了图像预处理阶段,虽并不完美但保证了产品的落地,驱动技术寻找更优的方案,达到产品和技术的良性互动。
接下来,我们继续从产品的角度对人脸识别进行拆解,并提出完善思路。
作者:AIoT产品,10年B端产品设计经验;微信公众号:AIoT产品
本文由@AIoT产品 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议











学习了
大学教程