
 起点课堂会员权益
起点课堂会员权益
OpenAI炸裂新作:GPT-4破解GPT-2大脑!30万神经元全被看透
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等最近,OpenAI发布了令人震惊的新发现,即GPT-4已经可以解释GPT-2的行为。这样看来,难道AI的“可解释性”真的被AI自己破解了?大语言模型的黑箱问题,真的可以被解答吗?不妨来看看本文的解读。

OpenAI发布了震惊的新发现:GPT-4,已经可以解释GPT-2的行为!
大语言模型的黑箱问题,是一直困扰着人类研究者的难题。
模型内部究竟是怎样的原理?模型为什么会做出这样那样的反应?LLM的哪些部分,究竟负责哪些行为?这些都让他们百思不得其解。
万万没想到,AI的「可解释性」,竟然被AI自己破解了?

网友惊呼,现在AI能理解AI,用不了多久,AI就能创造出新的AI了。

就是说,搞快点,赶紧快进到天网吧。
一、GPT-4破解GPT-2黑箱之谜
刚刚,OpenAI在官网发布了的博文《语言模型可以解释语言模型中的神经元》(Language models can explain neurons in language models),震惊了全网。

论文地址:https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html#sec-intro
只要调用GPT-4,就能计算出其他架构更简单的语言模型上神经元的行为。
GPT-2,就这样被明明白白地解释了。
要想研究大模型的「可解释性」,一个方法是了解单个神经元的具体含义。这就需要人类手动检测神经元,但是,神经网络中有数百亿或数千亿个神经元。
OpenAI的思路是,对这个过程进行自动化改造,让GPT-4对神经元的行为进行自然语言解释,然后把这个过程应用到GPT-2中。
这何以成为可能?首先,我们需要「解剖」一下LLM。
像大脑一样,它们由「神经元」组成,它们会观察文本中的某些特定模式,这就会决定整个模型接下来要说什么。
比如,如果给出这么一个prompt,「哪些漫威超级英雄拥有最有用的超能力?」 「漫威超级英雄神经元」可能就会增加模型命名漫威电影中特定超级英雄的概率。
OpenAI的工具就是利用这种设定,把模型分解为单独的部分。
第一步:使用GPT-4生成解释
首先,找一个GPT-2的神经元,并向GPT-4展示相关的文本序列和激活。
然后,让GPT-4根据这些行为,生成一个可能的解释。
比如,在下面的例子中GPT-4就认为,这个神经元与电影、人物和娱乐有关。

第二步:使用GPT-4进行模拟
接着,让GPT-4根据自己生成的解释,模拟以此激活的神经元会做什么。

第三步:对比打分
最后,将模拟神经元(GPT-4)的行为与实际神经元(GPT-2)的行为进行比较,看看GPT-4究竟猜得有多准。

还有局限
通过评分,OpenAI的研究者衡量了这项技术在神经网络的不同部分都是怎样的效果。对于较大的模型,这项技术的解释效果就不佳,可能是因为后面的层更难解释。

目前,绝大多数解释评分都很低,但研究者也发现,可以通过迭代解释、使用更大的模型、更改所解释模型的体系结构等方法,来提高分数。
现在,OpenAI正在开源「用GPT-4来解释GPT-2中全部307,200个神经元」结果的数据集和可视化工具,也通过OpenAI API公开了市面上现有模型的解释和评分的代码,并且呼吁学界开发出更好的技术,产生得分更高的解释。
此外,团队还发现,越大的模型,解释的一致率也越高。其中,GPT-4最接近人类,但依然有不小的差距。

以下是不同层神经元被激活的例子,可以看到,层数越高,就越抽象。




二、把AI的对齐问题,交给AI
这项研究,对于OpenAI的「对齐」大业,意义重大。
在2022年夏天,OpenAI就曾发布博文「Our approach to alignment research」,在那篇文章中,OpenAI就曾做出预测:对齐将由三大支柱支撑。
- 利用人工反馈训练 AI
- 训练AI系统协助人类评估
- 训练AI系统进行对齐研究
在前不久,万名大佬联名签署公开信,要求在六个月内暂停训练比GPT-4更强大的AI。
Sam Altman在一天之后,做出的回应是:构建更好的通用人工智能,就需要有对齐超级智能的技术能力。

究竟怎样让AI「与设计者的意图对齐」,让AGI惠及全人类?
今天的这项研究,无疑让OpenAI离目标更迈进了一步。

Sam Altman转发:GPT-4对GPT-2做了一些可解释性工作
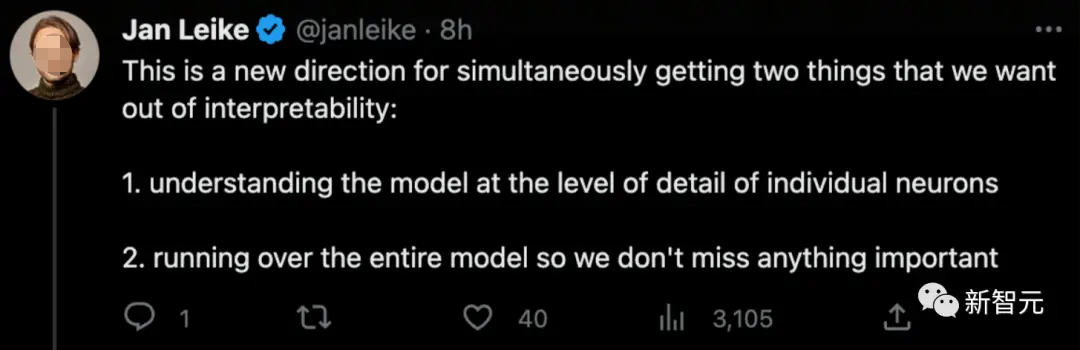
OpenAI的对齐团队负责人也表示,这是一个新的方向,可以让我们同时获得:
- 详细理解模型到单个神经元的层
- 运行整个模型,这样我们就不会错过任何重要的东西
令人兴奋的是,这给了我们一种衡量神经元解释好坏的方法:我们模拟人类如何预测未来的模式,并将此与实际的模式进行比较。
目前这种衡量方式并不准确,但随着LLM的改进,它会变得更好。
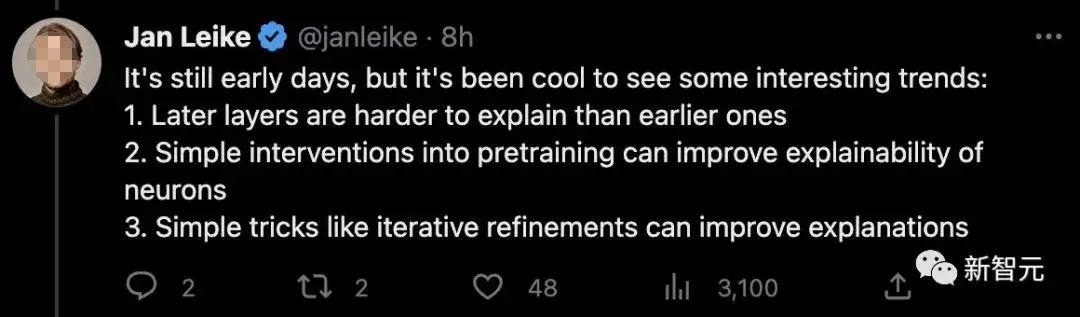
虽然现在还处于初期阶段,但已经展现了一些有趣的趋势:
- 后期的层比早期的更难解释
- 简单的预训练干预可以提高神经元的可解释性
- 简单的技巧,如迭代细化,可以改进解释
OpenAI可解释性团队负责人William Saunders也表示,团队希望开发出一种方法,来预测AI系统会出现什么问题。「我们希望能真正让这些模型的行为和生产的回答可以被信任。」
三、有趣的神经元
在这个项目中,研究者还发现了许多有趣的神经元。
GPT-4为一些神经元做出了解释,比如「比喻」神经元、与确定性和信心有关的短语的神经元,以及做对事情的神经元。
这些有趣的神经元是怎么发现的?策略就是,找到那些token空间解释很差的神经元。
就这样,背景神经元被发现了,也就是在某些语境中密集激活的神经元,和许多在文档开头的特定单词上激活的神经元。
另外,通过寻找在上下文被截断时以不同方式激活的上下文敏感神经元,研究者发现了一个模式破坏神经元,它会对正在进行的列表中打破既定模式的token进行激活(如下图所示)。

研究者还发现了一个后typo神经元,它经常在奇怪或截断的词之后激活。
还有某些神经元,似乎会在与特定的下一个token匹配时被激活。
比如,当下一个标记可能是「from」时,一个神经元会被激活。
这是怎么回事?起初研究者猜测,这些神经元可能是根据其他信号对下一个token进行预测。然而,其中一些神经元并不符合这种说法。
目前,研究者还没有进行足够的调查,但有可能许多神经元编码了以特定输入为条件的输出分布的特定微妙变化,而不是执行其激活所提示的明显功能。
总的来说,这些神经元给人的主观感觉是,更有能力的模型的神经元往往更有趣。
毫不意外地,网友们又炸了。
咱就是说,OpenAI,你搞慢点行不?

在评论区,有人祭出这样一张梗图。

这就是传说中的「存在主义风险神经元」吧,只要把它关掉,你就安全了(Doge)。

ChatGPT从互联网中学习,现在它正在创造更多的互联网。很快,它就会自我反哺,真正的天网就要来临。
听说GPT-5已经达到奇点,并且它正在与地外生命谈判和平条约。

有网友恶搞了一个关于「Yudkowsky」的解释,他一直是「AI将杀死所有人」阵营的主要声音之一。
之前「暂停AI训练」公开信在网上炒得沸沸扬扬时,他就曾表示:「暂停AI开发是不够的,我们需要把AI全部关闭!如果继续下去,我们每个人都会死。」

他知道我们在计划什么
我们必须不惜一切代价让他丧失信誉
一旦他走了,就没有人能够反对我们了
「Eliezer Yudkowsky看到这一幕,一定又笑又哭——让我们使用自己不能信任的技术来告诉我们,它是如何工作的,并且它是对齐的。」

现在,人类反馈强化学习(RLHF)是主场,当AI懂了AI,将会在微调模型上开辟一个新纪元:
人工智能反馈的神经元过滤器(NFAIF)

参考资料:
https://openai.com/research/language-models-can-explain-neurons-in-language-models
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
https://techcrunch.com/2023/05/09/openais-new-tool-attempts-to-explain-language-models-behaviors/
作者:新智元;编辑:编辑部
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









