
 起点课堂会员权益
起点课堂会员权益
向量数据库—大模型时代的【存储新基座】

今年,黄仁勋的一次演讲让众多人的目光聚焦到向量数据库上,作者也介绍,如果大模型是肉体,那向量数据库则是灵魂。那么,向量数据库到底存在哪些我们不知道的潜在能力呢?让我们看看作者的分析吧~

AI大模型基座在以【日更】进展的同时,也给资本市场带来了焦虑的情绪价值:估值 130 亿美元的 AI 写作工具 Grammarly 在 ChatGPT 发布后网站用户直线下降;AI 聊天机器人独角兽公司 Character.AI 的自建大模型在 ChatGPT 进步之下,被质疑能否形成足够的竞争壁垒 …
一、向量数据库—怎么火起来的
时间回转到今年的Q1季度,2023.3.21,NVIDIA创始人兼CEO黄仁勋在2023 GPU技术大会(2023 GTC)上发表演讲。并表示今年将推出新的向量数据库:RAFT。RAFT在此基础上,还具有加速索引、数据加载和近邻检索等功能。
黄仁勋认为:“对于自研大型语言模型的组织而言,向量数据库至关重要。”他总结:“初创公司竞相构建具有颠覆性的产品和商业模式,而老牌公司则在寻求应对之法——生成式AI引发了全球企业制定AI战略的紧迫感。”

这一消息在演讲结束只是直接震动了投资界及AI大模型的创业者们,很多VC也是调转方向纷纷看向——向量数据库项目。
二、走进向量数据库的工作原理
1. 为什么需要向量数据库
向量数据库这一概念随着黄仁勋的演讲火爆了之后,不少的创业者以及厂商们开始纷纷投入此类项目的研发。
在研发之际,需要明白一个道理:我们为什么在大模型时代需要向量数据库,为了证实这个概念在这里给大家科普三个非常关键的知识点,帮助大家了解我们为什么在大模型时代需要向量数据库。
1)CPU工作原理
中央处理器(Central Processing Unit,简称CPU)是一块由超大规模集成电路组成的运算和控制核心,主要功能是运行指令和处理数据。包括逻辑运算、算术运算、控制逻辑、时钟信号、内存读写、寄存器、缓存。

图片来源:知乎
- 运算逻辑。CPU 内部有一组运算逻辑单元 (ALU),用于执行各种逻辑运算和算术运算。ALU 可以执行加、减、乘、除等基本操作,还可以执行各种复杂的操作,如排序、查找等。
- 控制逻辑。控制逻辑用于控制 CPU 的执行流程。它可以根据程序的需要,控制 CPU 执行不同的指令。控制逻辑还包括中断控制器和时序控制器等组件。
- 时钟信号。CPU 内部有一个时钟信号,用于控制 CPU 的执行速度。时钟信号以固定的频率发送,每个时钟周期被划分为多个阶段,每个阶段用于执行不同的操作。
- 内存读写。CPU 可以从内存中读取数据和指令,也可以向内存中写入数据和指令。CPU 通过地址总线和数据总线来与内存进行通信。
- 寄存器。CPU 内部有一组寄存器,用于存储临时数据和指令。寄存器是 CPU 内部的逻辑单元,可以像内存一样读取和写入。
- 缓存。CPU 内部还有缓存,用于存储较快的数据和指令。缓存可以加速 CPU 的执行,提高计算机的性能。
CPU 的工作原理是通过基础的指令来完成复杂的运算逻辑,但是弊端在于CPU中大部分晶体管主要用于构建控制电路(象分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。
2)GPU工作原理
在GPU出现以前,显卡和CPU的关系有点像“主仆”。简单地说这时的显卡就是画笔,根据各种有CPU发出的指令和数据进行着色,材质的填充、渲染、输出等。
随着计算机的普及较早的娱乐用的都是【集成显卡】,由于大部分坐标处理的工作及光影特效需要由CPU亲自处理,占用了CPU太多的运算时间,从而造成整体画面不能非常流畅地表现出来。
例如:渲染一个复杂的三维场景,需要在一秒内处理几千万个三角形顶点和光栅化几十亿的像素。
CPU进行各种光影运算的速度变得越来越慢,更多多边形以及特效的应用榨干了几乎所有的CPU性能。
于是GPU产生了NVIDIA公司在1999年8月31日发布GeForce 256图形处理芯片时首先提出GPU的概念。
GPU为了高效率的处理执行矩阵运算,从而配置了大量的处理核心并行+专一的思路并行矩阵运算。

简而言之,GPU的图形处理会已流水线完成如下的工作:
- 顶点处理。这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。在支持DX系列规格的GPU中,这些工作由硬件实现的Vertex Shader(定点着色器)完成。
- 光栅化计算。显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。
- 纹理帖图。顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射(texture mapping)工作完成对多变形表面的帖图。通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。TMU(Texture mapping unit)即是用来完成此项工作。
- 像素处理。这阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Pixel Shader(像素着色器)完成。
- 最终输出。由ROP(光栅化引擎)最终完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区。
GPU的工作通俗的来说就是完成3D图形的生成,将图形映射到相应的像素点上,对每个像素进行计算确定最终颜色并完成输出。
3)二者的差异
多线程机制
GPU的执行速度很快,但是当运行从内存中获取纹理数据这样的指令时(由于内存访问是瓶颈,此操作比较缓慢),整个流水线便出现长时间停顿。在CPU内部,使用多级Cache来提高访问内存的速度。GPU中也使用Cache,不过Cache命中率不高,只用Cache解决不了这个问题。
所以,为了保持流水线保持忙碌,GPU的设计者使用了多线程机制(multi-threading)。当像素着色器针对某个像素的线程A遇到存取纹理的指令时,GPU会马上切换到另外一个线程B,对另一个像素进行处理。等到纹理从内存中取回时,可再切换到线程A。
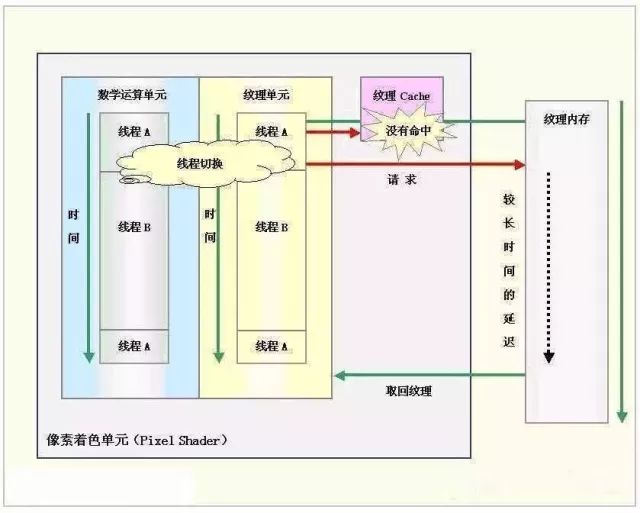
图片来源:知乎
4)总结
从设计目的,工作原理,任务执行效率,应用领域来看二者的区别简单做一个总结。
- 设计目的:CPU 的设计目的是处理数据和执行指令,主要用于计算和控制计算机的运行。GPU 的设计目的是处理图形和视频数据,主要用于游戏、视频处理和科学计算等领域。
- 工作原理:CPU 和 GPU 的工作原理不同。CPU 是基于逻辑运算和算术运算的处理器,主要依靠内部缓存和寄存器来存储和处理数据。GPU 则是基于图形渲染和计算的处理器,主要依靠内部图形缓存和寄存器来存储和处理数据。
- 执行效率:在执行效率方面,CPU 往往比 GPU 更快。因为 CPU 的设计目的是处理大量数据和执行复杂计算,所以它的内部缓存和寄存器容量较大,可以同时处理多个数据。而 GPU 的设计目的是处理图形和视频数据,所以它的图形缓存和寄存器容量较大,更适合处理单个数据。
- 应用领域:CPU 主要用于计算和控制计算机的运行,如办公文档处理、网页浏览和简单游戏等。GPU 主要用于图形和视频处理,如游戏、视频渲染和科学计算等。
GPU对比CPU就相当于是为了完成某件事情单独训练了一个特种兵团,而CPU是单兵作战所有GPU完成的又快又好。
现在CPU的技术进步正在慢于摩尔定律,而GPU(视频卡上的图形处理器)的运行速度已超过摩尔定律,每6个月其性能加倍。
5)大模型的工作原理
科普完CPU与GPU接下来我们看一下,什么的大模型的工作原理,其实逻辑非常的简单只分为两个模块【学习】+【推理】。
学习
首先进入一个生活场景,人的大脑在看见任何物体时首先要:眼睛看到先感知,分析这个过程传给大脑处理成像识别,然后大脑给出相应的指令,将大脑的工作过程抽象成一个盒子,接受输入完成任务后输出结果这个过程就是模型。

所以现在的人工智能网络结果都是在模拟人工神经网络方法。
假设我们以4层网络模型为例子来进行一个数字识别的模拟实验。
假设一个手写数字9是由28*28的像素组成的,将其作为输入层展开,中间需要加上两层中间层来完成模型架构的设计最后一层为输出层。

该模型的计算原理是关键,首先在输入层的每个节点都会作为输入对每个输入都会 经过一次计算。
模型中的节点越多参数也就越多模型也就越复杂,所以参数数量=模型规模。
在模型训练时需要大量的多模态数据收集通过反复调整模型的参数来让模型进行反复的推理和学习,以便在输入数据时产生的差距 越来越小最后达到准确的状态。
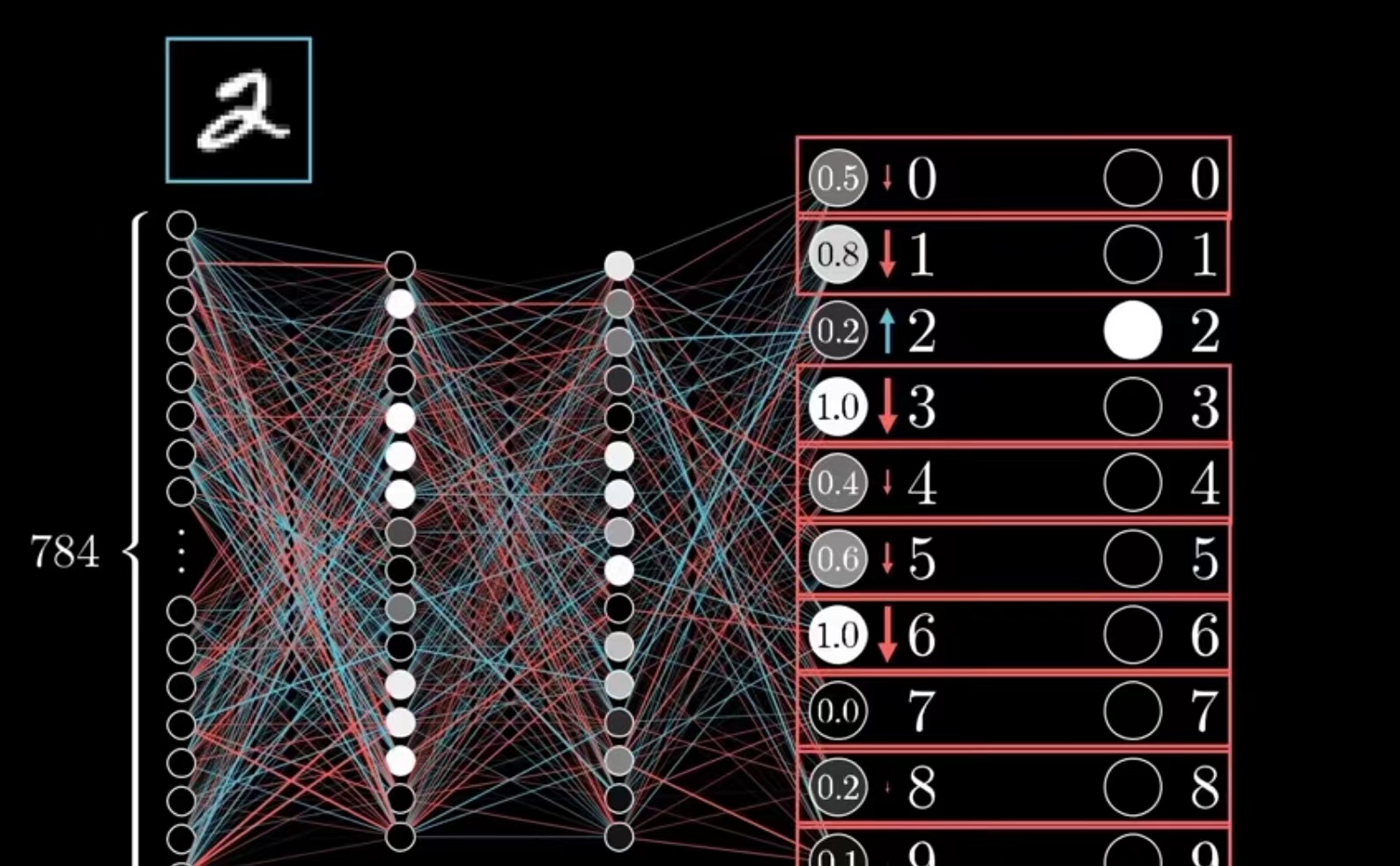
推理
到这里大家不禁会有一个疑问产生:模型为什么会越推理误差越小?这便运用到了数学中的向量,通过将数据分批次进行向量化的方式来进行模型训练之后每批计算结束,调整一次参数,经过多次调整模型就会准确的推理出所需要的信息了。
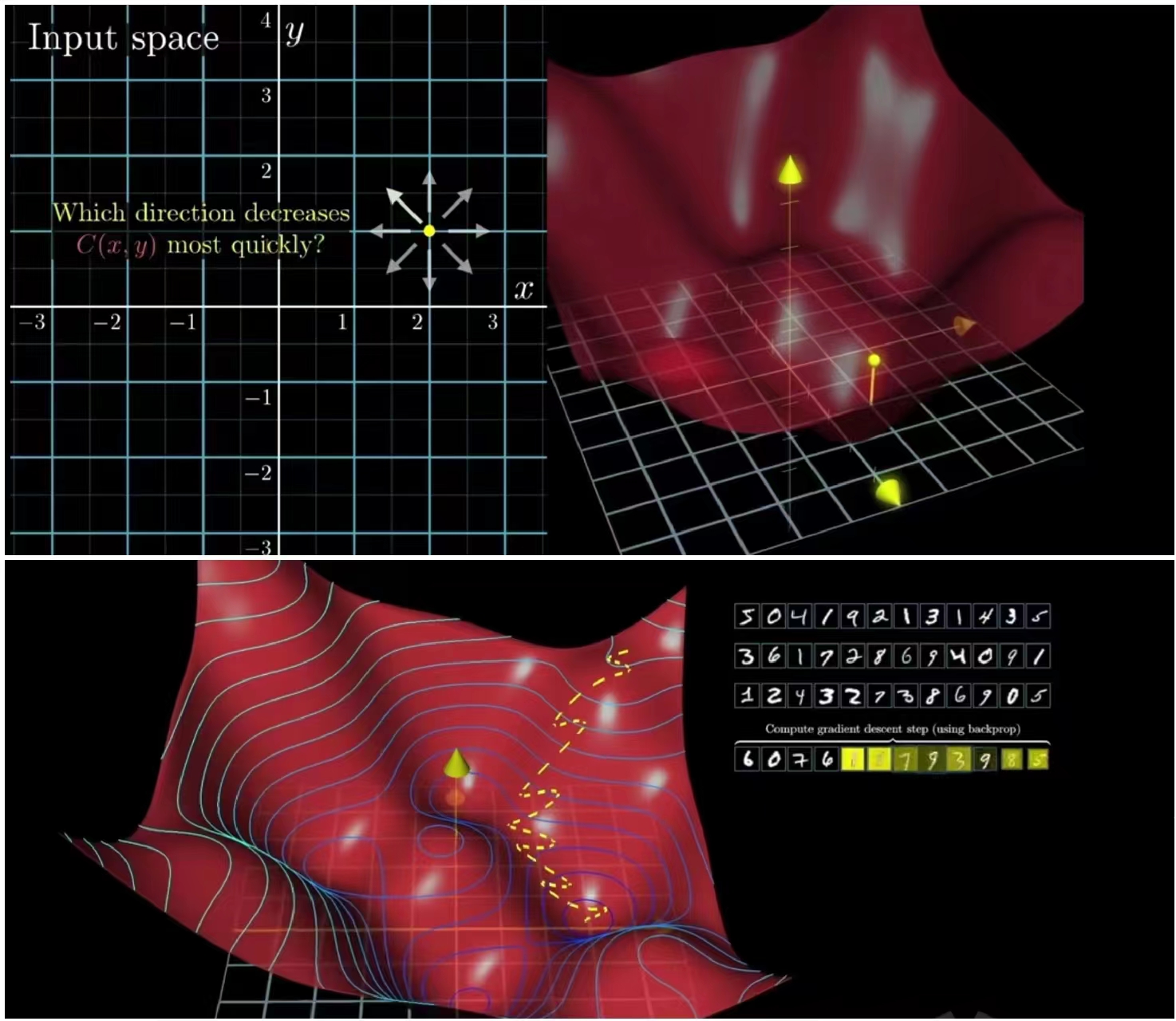
至此到这里大家应该都明白了大模型以及,GPU、CPU的工作原理。
到这里想必大家应该理解了为什么ChatGpt需要用GPU来训练了,因为从原理上来讲无论是游戏还是AI都是不断通过GPU来运算向量坐标来完成的。
案例如下图,大家可以看到这个紫色的图形模态元素想要移动,实际上就是通过各个三角形的色块来进行坐标向量移动实现的,这背后需要大量的公式运算逻辑:
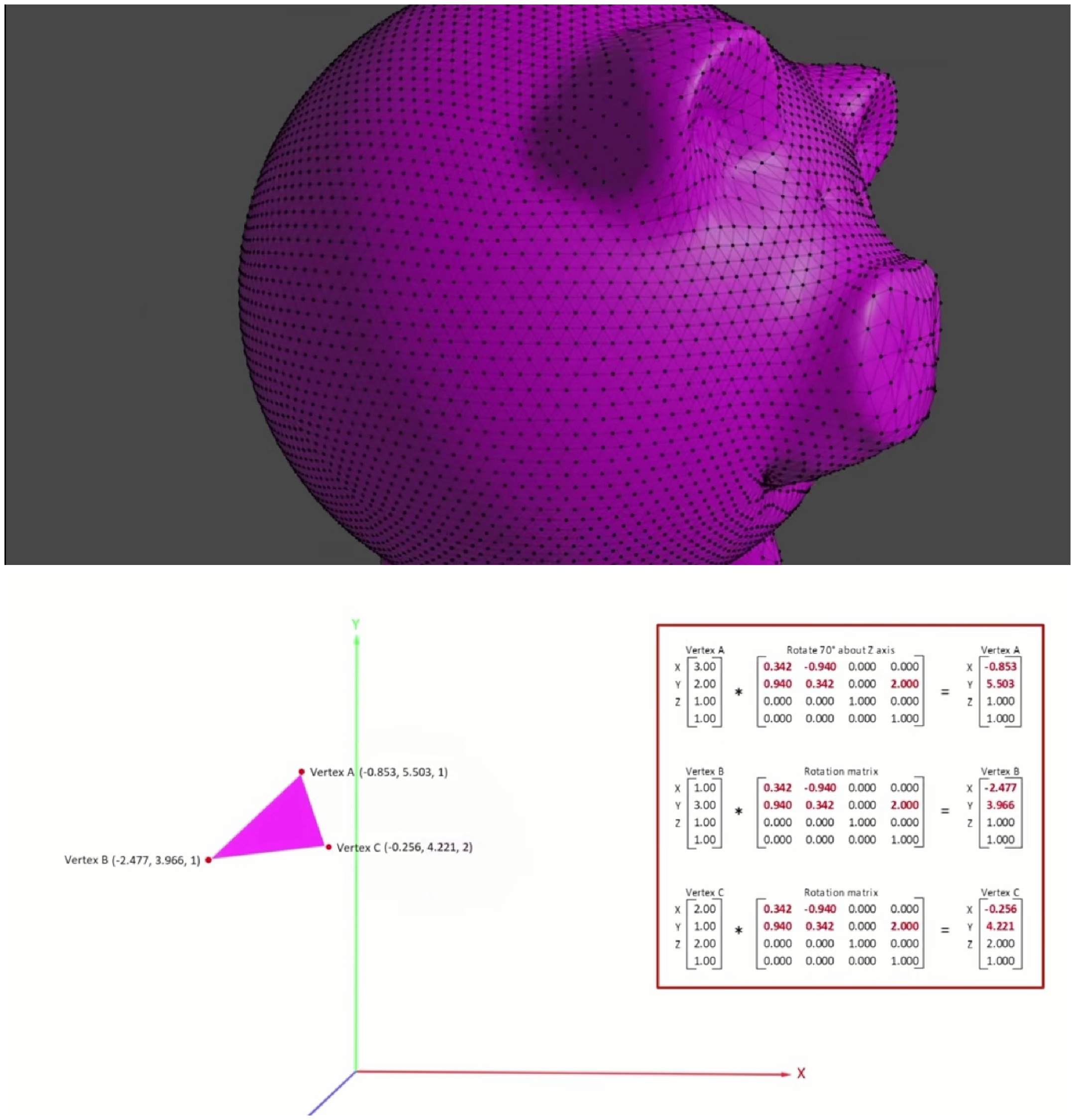
所以在GPU的架构下多矩阵的计算也让在游戏领域中大放异彩。反观AI的发展思路,神经网络的计算基础也同样是矩阵的乘法运算引入GPU作为训练引擎应对深度神经网络巨大的计算量就再合适不过了。
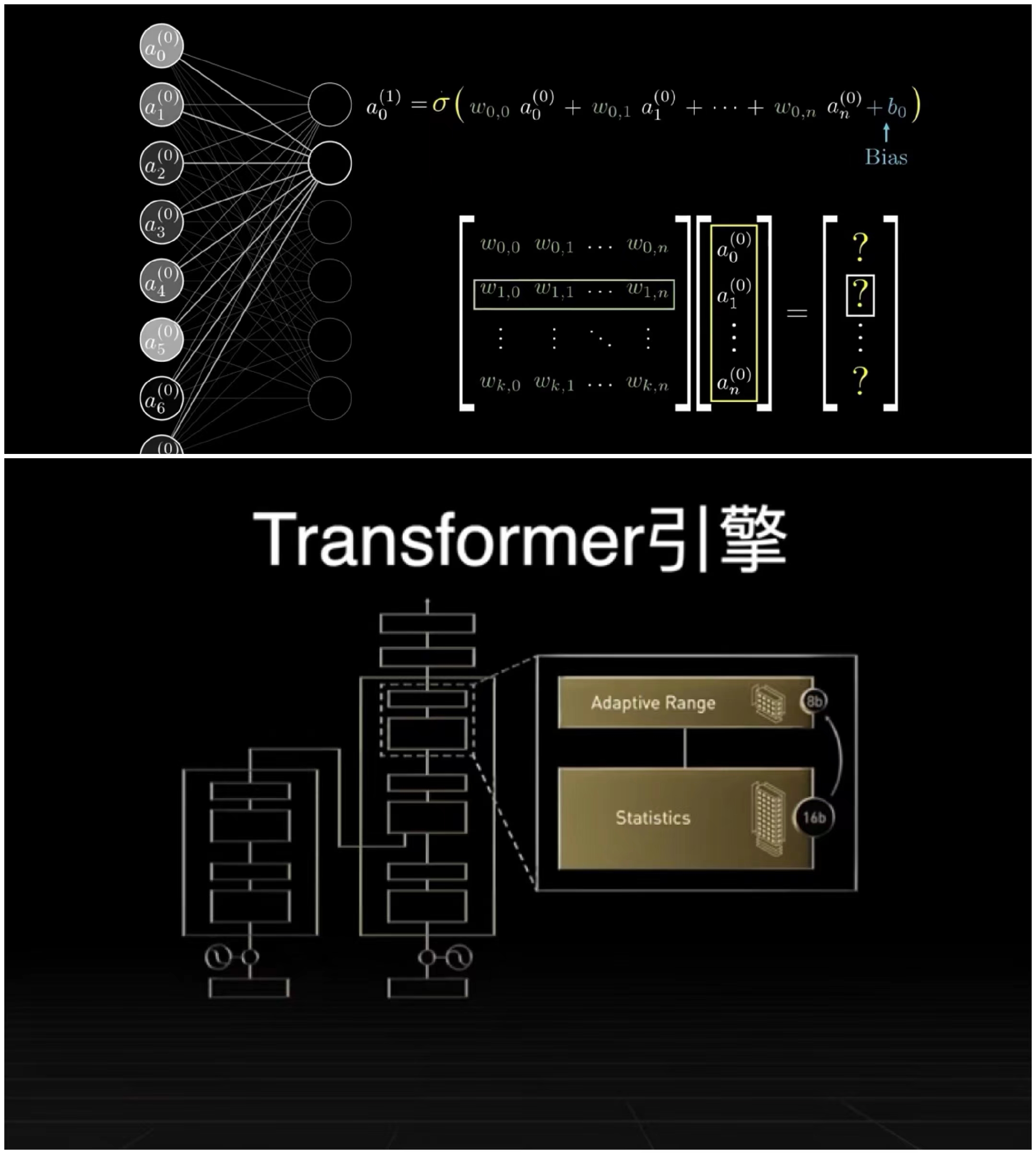
GPU目前已经发展成了专门的Transformer引擎,这种应用的行为也加快了AI行业的发展和爆发,也让GPU自身成了算力的动力源泉。
移动互联网时代,JSON 文档作为支撑大规模灵活数据存储的通用格式,推动了 MongoDB 的流行;而在 AI 重塑软件的时代,向量作为大模型理解世界的数据形式,也就促成新的重要基建:向量数据库。
二、大模型是肉体,向量数据库是灵魂
由上文的说明;我们在神经元激活后形成对眼前事物的神经表征,这就是人脑真正理解和学习的对象。AI 模型实际识别和理解的不是一个个具体的文字符号,而是神经网络对各类数据的向量化表示,表示的结果便是向量。
如果如果把 ChatGPT 类的大语言模型比作大脑,其天然就缺失了灵魂。
在大模型中,世界知识和语义理解被压缩为了静态的参数,模型不会随着交互记住我们的聊天记录和喜好,也不会调用额外的知识信息来辅助自己的判断。
所以向量数据库的意义与就是在给大语言模型提供记忆与加强记忆。
大模型是新一代的 AI 处理器,提供的是数据处理能力;那么向量数据库提供就是 memory,是它的存储。
三、市场情况及资本热度
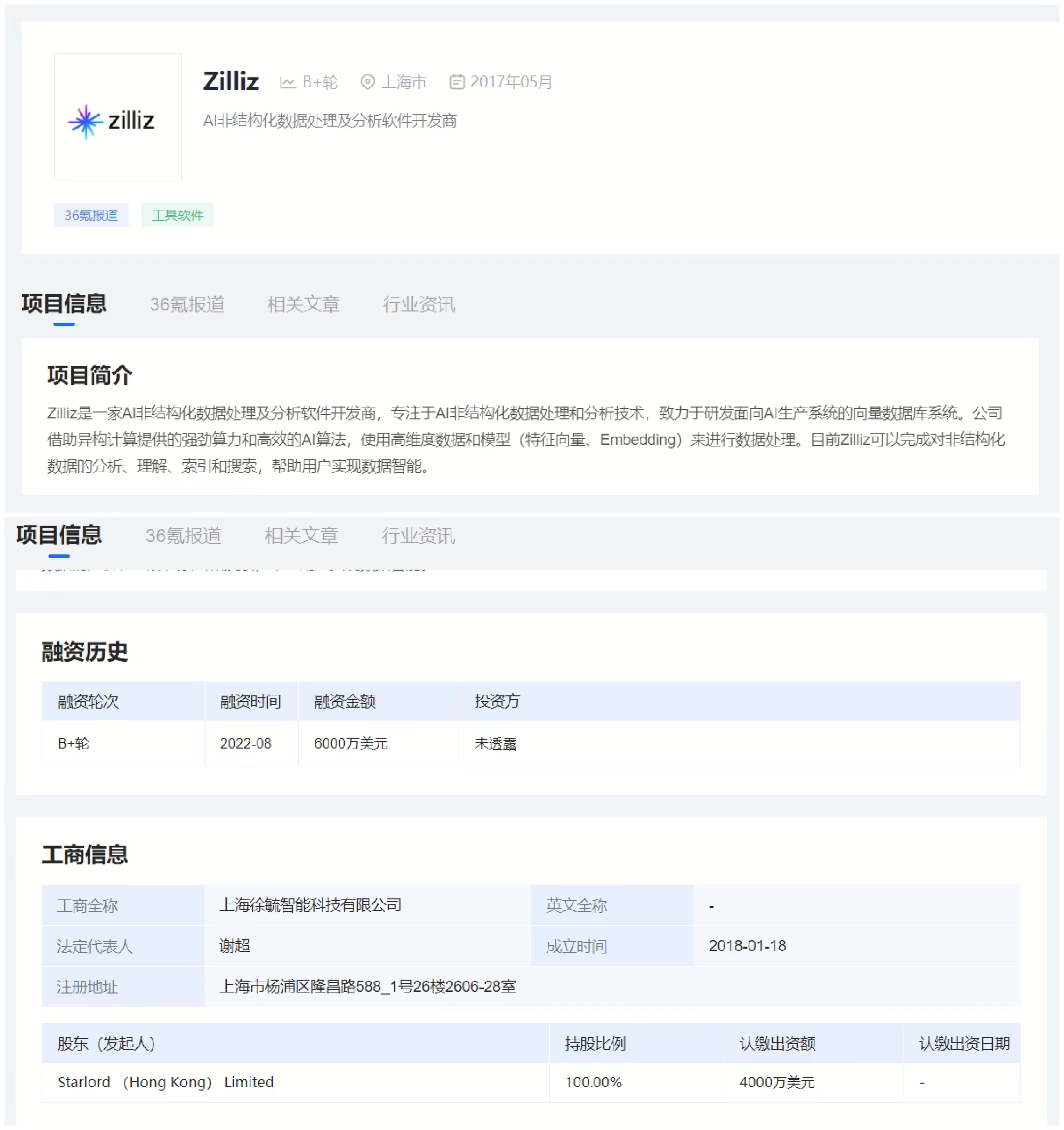
图片来源:36Kr
目前Zilliz在全球拥有超过 1000 家企业用户,成为目前全球最流行的开源向量数据库。2022 年,Zilliz 累计超过 1.03 亿美金的 B 轮融资,估值达到 6 亿美金。也被官宣是 NVIDIA 的向量存储的官方合作伙伴。
紧接着,OpenAI ChatGPT plugins 发布的官方文章中,Milvus 和 Zilliz Cloud 同时作为首批插件合作伙伴被提及成为唯一一家开源项目与商业化云产品同时入选的向量数据库公司。
而在近一个月之内,向量数据库迎来了融资潮。Qdrant 、Chroma 和 Weaviate 纷纷获得融资;而 Pinecone 也正式官宣了新的 1 亿美金 B 轮融资,估值达到了 7.5 亿美元。
由此推论资本是跟着科技走的,向量数据库的存储逻辑也必将是革命性的产品。
四、未来发展
向量数据库的核心能力为大模型提供记忆。
多模态数据想量化调用与输入,压缩Token长度,效率更高调用更快;但其实向量这一数据结构,和向量搜索的需求都是随着 ML/AI 模型逐渐发展到今天的,接下来就来构想一下这一领域的演进历程。
1. 向量是 AI 理解世界的通用数据形式
无论是游戏,网络,教育,医疗等等等世界各行各业的领域中AI大模型的应用场景是趋近于无限的,正因为可应用场景多,需要或许到的数据毅然很多很杂,所以在做模型训练的时候应该无限趋近于向量搜索和向量训练,向量在未来也将会成为AI的灵魂和大脑是AI理解世界学习世界的通用形式。
2. 多模态向量化是最终趋势
人的大脑在思考时:首先需要眼睛看到,传递给大脑,激活信号传输到你的颞叶,你的大脑解释为:我看到了XXX。也就是说,当大脑试图理解和解释看到的信息时,大脑解读的是视觉皮层输出的神经表示,而非进入眼睛的原始图像。
所以在大语言模型学习和训练的过程中也是如此尽管大模型呈现出的形式是端到端、文本输入输出的,但实际模型接触和学习的数据并不是文本本身,而是向量化的文本,为了让我们的大模型更加聪明更加懂所问的问题。
所以说,在用向量化的数据来训练模型时多模态(语音数据、图片数据、视频数据、文本数据)是最终的趋势,只有将多模态的数据全部打碎进行向量化的压缩让大模型来进行学习,才可能让大模型聪明起来。
输出的文本更加丰富,更加懂问他的问题。
五、结语
在大模型时代,传统的数据库已经没有办法来做基于AI大模型的应用级人工智能产品的数据调用需求了。
这是一个向量数据库开始疯狂增长的时代,也是向量数据库未来十年高速增长的开端。
作者:于天航,微信公众号:懂技术的产品汪
本文由 @小于爱学习 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

















咩咩……
意思就是,主要学Zilliz
【人工神经网络】那一块好难理解 这应该涉及到机器学习的内容了
是的
半年后 本宝宝又过来打卡了 温故而知新 但还是很难理解 感觉很绕~~