
 起点课堂会员权益
起点课堂会员权益大语言模型时代来临,交互式对话搜索如何落地
传统的搜索模式有诸多受限,随着互联网的发展进步,带来了AI对话式搜索,这一搜索模式为用户带来了更好的搜索体验,其发展机遇是可见的,但是在未来AI对话将面临什么挑战呢?让我们看看作者的观点。
2022年11月30日:OpenAI发布ChatGPT,短短两个月时间月活过亿 ,预示着大模型时代的来临!
2023年2月8日:微软宣布上线 New Bing 和 Edge浏览器,整合 OpenAI 的 GPT 技术,可以与用户进行对话式搜索、交互聊天。
2023年4月6日:《华尔街日报》报道称,谷歌也计划在其搜索引擎中,添加对话式AI功能。
业界大佬纷纷入局抢占先机,国内大厂也纷纷入场开启“军备竞赛”。
今天小编就带大家粗浅了解下什么是大模型,大模型未来对企业、人们的日常生活到底会有哪些颠覆和影响。各行业又能将LLM大语言模型应用到哪些业务中去。
一、什么是LLM大语言大模型?
LLM=Large Language Model 大语言模型,是一种基于深度学习的自然语言处理模型。它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓“语言模型”,就是只用来处理语言文字(或者符号体系)的AI 模型,发现其中的规律,可以根据提示(prompt),自动生成符合这些规律的内容。
简言之:能够理解输入的文字、语言,并给出相应回答。
典型代表有ChatGPT(OpenAI)、通义千问(阿里)、文心一言(百度)、ChatGLM(清华)、Chatlaw(北大)。
二、大模型训练门槛有多高?
- 需要大量的数据进行训练
- 非常大的参数数量的人工神经网络(数十亿)
- 需要投入大量的机器资源进行优化和调整
- 技术团队的工程实现能力要求非常高
总结下来就是财力及投入意愿、工程能力、技术热情,都有极高的要求,目前市面上能支撑上述要求的机构少之又少。
并且这些模型训练数据来自世界知识,无论是多强大的LLM,能压缩的知识量仍然是有限的。当遇到企业专属知识时,这些模型也很难给出准确答案。
举一个例子,下图中的问题是关于阿里巴巴内部的技术产品,属于企业专属知识,就算是强大的ChatGPT模型给出的答案也是完全错误不相关的。
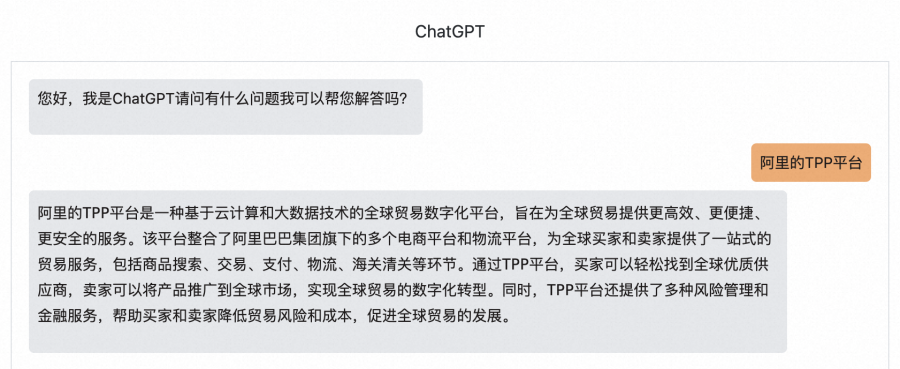
针对这个问题,OpenAI提出了chatgpt-retrieval-plugin、WebGPT,开源社区提出了DocsGPT、ChatPDF、基于langchain的检索增强chatbot等等一系列解决方案,足以证明业界对如何在个人/企业专属数据上结合LLM需求强烈。
三、传统搜索VS对话式搜索
下面举几个例子给大家直观感受下对话式搜索的的优势:
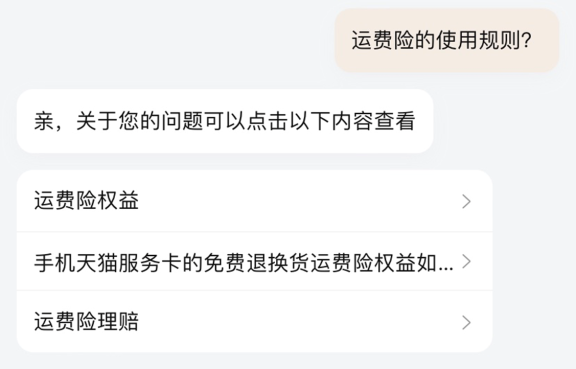
1. 传统的客服问答
下面画面常常发生在我们线上购物和机器人客服的对话,答案分散,不能快速抓到用户的搜索意图,用户体验较差。
同理,这也是很多人打银行客服电话还是喜欢转人工处理的原因。
2. 传统搜索引擎搜索
传统搜索引擎的没有目共睹。即时通信已经取代搜索引擎成为移动互联网时代新的核心流量入口。即使是全球市场占有率最高的谷歌搜索,其用户量也面临着被社交网站、短视频APP瓜分的危机。
传统搜索引擎的痛点首先是信息过剩,不能直接召回到用户搜索意图,需要在信息网里自行查找筛选,耗时耗力也不一定找到问题的解。其次信息壁垒。
从PC互联网时代走入移动互联网时代,信息散落到了各个App当中,用户随之流向其内部的搜索。
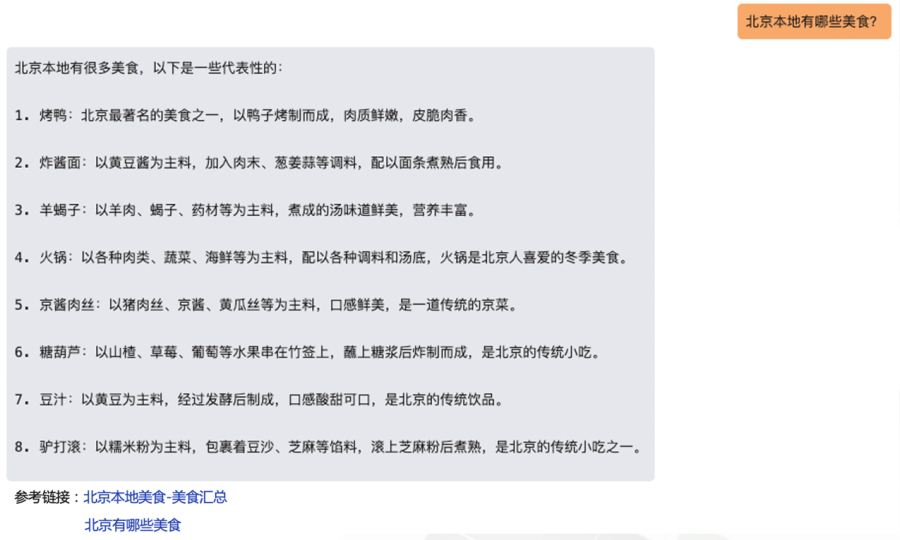
3. AI对话式搜索
更快、更准、更丰富,给予用户有建设性、拓展性的答案。将用户获取信息和服务的方式从输入冰冷的关键词转向人机“多轮对话”。
四、对话式搜索在业务中的应用
- 电商:用户答疑、直播选品、售前咨询、售后服务等
- 内容:IT、文娱、专业领域等个性化场景
- 企业知识库:企业内部资料、产品文档、技术资料等
- 教育:知识总结、搜题生成答案
AI对话式搜索在这些场景的应用可以有效提升用户信息获取效率、产品体验、业务转化、用户粘性、用户活跃。有效降低人工成本,运营成本。
目前这些典型场景却无法直接使用ChatGPT等大模型,实际用于到自身业务中去。
首先是数据问题,大模型来自公网数据,无法满足企业业务搜索需要。其次存在安全风险,生成内容不可控,风险较高。
企业需要基于自身数据构建垂直领域问答式搜索。
五、是机遇也是挑战
目前虽然大模型热度高,很多企业也关注到了对话式搜索给业务带来的机遇,但实际能应用起来的还很少。
一是落地难度大,技术能力要求高;二是缺乏场景,除头部客户以外,业务需求还未达到这个层次,处于观望了解阶段。
那如果是创业公司在选择大模型接入时,是选开源还是闭源呢?
各有优势。开源你只需要买TOKEN就好了,再加上 Prompt engineering和向量数据库等。闭源的优势在于,保护数据隐私,并且可以不断用数据填充完善自己的模型。
给大家介绍下市面接入较多的两种方案
1)企业自建方案:基于开源大模型,企业自行微调自建。
- 需要使用A100卡或单机多卡支持
- 专业的算法研发人员,数据处理→开发调试→训练模型→模型部署
- 对企业数据质量有要求,否则影响训练效果
- 涉及图文、音视频数据,需要转为向量化数据
2)产品化方案:阿里云OpenSearch LLM问答版端到端方案,可以构建企业专属模型。
- 基于阿里模型+企业自有数据进行模型微调拓展,自动生成Query对应的问答搜索结果,接入门槛较低
- 问答结果基于业务数据搜索生成,保证问答结果稳定性与数据安全性
- 支持图文多模态信息搜索,支持问答结果的人工干预
六、AI对话式搜索行业应用展望
1)助力企业创新能力
LLM可根据大量数据进行预测分析,为企业提供有针对性的战略建议,提供新的创新途径;开展垂直领域或行业子模型的研究,做应用场景和用户数据反哺、调优,实现企业定制化搜索。
2)优化客户支持和服务
智能客服可根据客户输入的问题,提供即时、准确的解答,减轻传统客服压力;对于复杂问题,LLM可为技术支持团队提供问题解决方案,提高问题解决效率。
3)复杂信息提炼,提升信息获取效率
利用LLM数据整合与分析能力,将复杂信息进行要点提炼,观点的归纳整理,节省用户信息获取效率,从而有更多的时间进行深度和系统的思考。
4)低代码应用
通过API融入到产品的标准模块里,更低的开发成本、更少的时间投入,来满足日益增长的客户个性化需求。
本文由 @KKai 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!








