
 起点课堂会员权益
起点课堂会员权益基于大模型进行开发的实践与思考
LLM的革新,将会带来什么改变呢?作者对此展开思考,以独立开发者的身份对大模型开发进行实践,接下来,我们看看作者是如何做的吧。

LLM出现引发的解放力提升及革新,有时会在我脑海里浮现,对于期望从事LLM的人来说,可以从哪些方面来进行学习呢?
当前,各个行业都在对 LLM的应用和研究进行着不断的尝试,经过阅读和论文的参考,对LLM进行了分类整理,也结合自身的实践来做一次分享。
一、LLM综述及简介
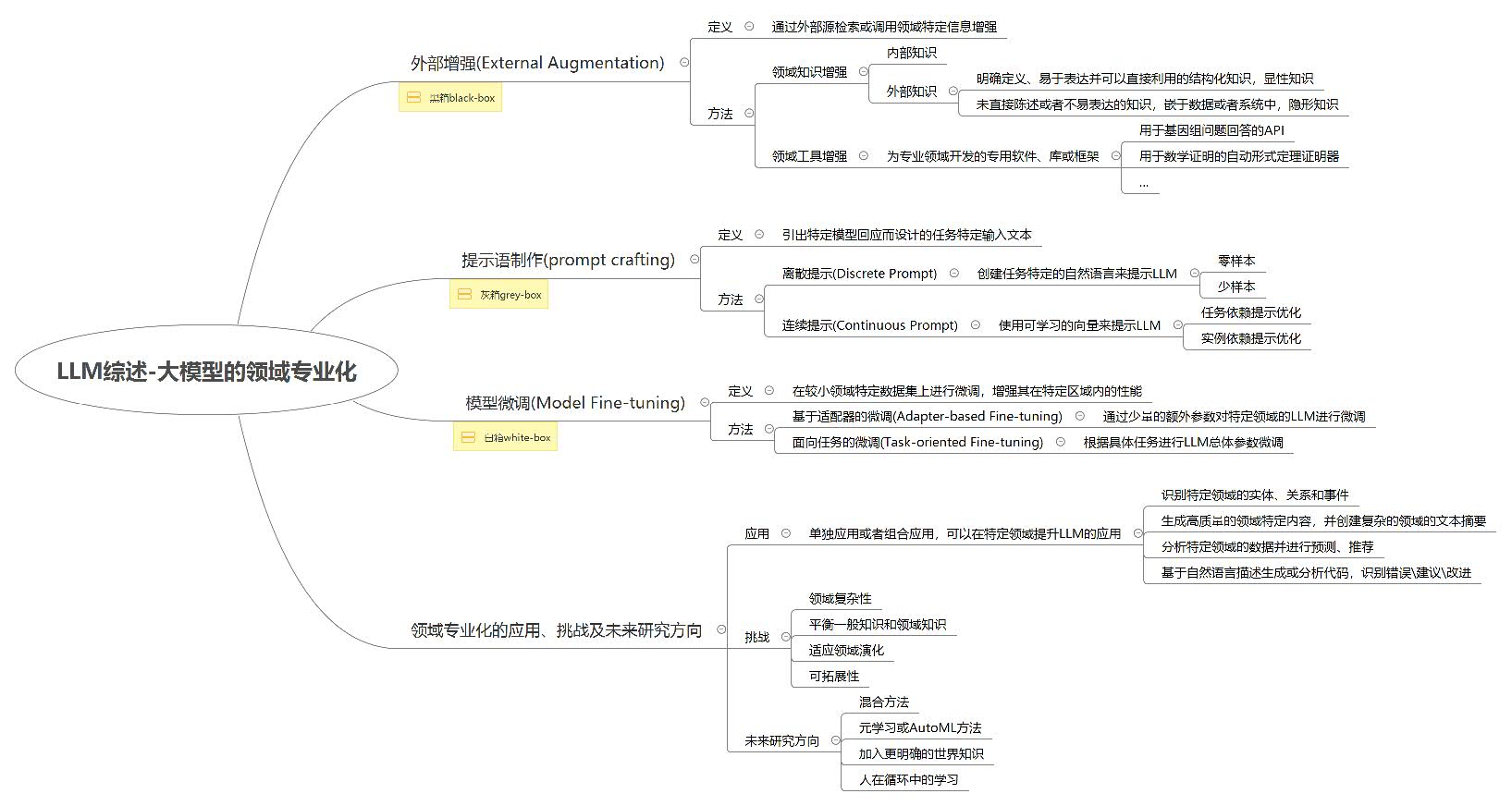
1. 领域专业化分类
基于拓展阅读的论文观点,LLM的专业领域主要分为三类:
- 外部增强(External Augmentation)
- 提示语制作(Prompt crafting)
- 模型微调(Model Fine-tuning)
其中,外部增强是一个黑盒类型的应用,它是由外部的数据\上下文和内部的提示词来控制输出,实质上不能对 LLM的内部进行访问和调节。
提示语制作是一种灰盒类型的应用,它是通过调节 prompt的参数来控制 LLM的输入和输出,仅在 LLM中与 prompt有关的参数进行更新,这部分参数占 LLM总参数的0.01% 。
模型修正是一种白盒类型的应用,它是对模型中特定领域中的知识和数据的修正,是一种深入到模型中特定领域的全量参数修正。
2. LLM应用场景简述
尽管专业领域被划分成了三个类别,但是 LLM在其中的共同应用有:
- 识别特定领域的实体、关系和事件
- 生成特定领域的内容,并生成复杂的文本摘要
- 分析特定领域的数据并进行预测
- 通过自然语言生成\校验代码
这四个应用可以贯穿全领域,也是主要提效的表现,具体场景如下:
- 可以用LLM快速进行客户问题的分类
- 使用LLM快速阅读论文并给出摘要内容
- 提供某一专业数据,并进行数据的分析总结
- 用中文描述需求并生成python代码,如请生成一个深度学习的示例代码
在目前阶段,各大中小企业对LLM进行的探索,一般都为外部增强的方式,因为这一方面无论是从成本还是门槛上来说,大部分是可以接受的。
所以,我在后面的实践及应用介绍,也是以外部增强为基础,从以上四个应用方向展开。
二、个人实践简述及总结
1. 已开发的个人工具
截至目前已经开发的工具有三个,分别为:
- 电影评论情感分析工具(识别特定领域的实体、内容)
- 客服问题分类工具(生成特定内容摘要)
- 数据分析工具(分析特定领域的数据)
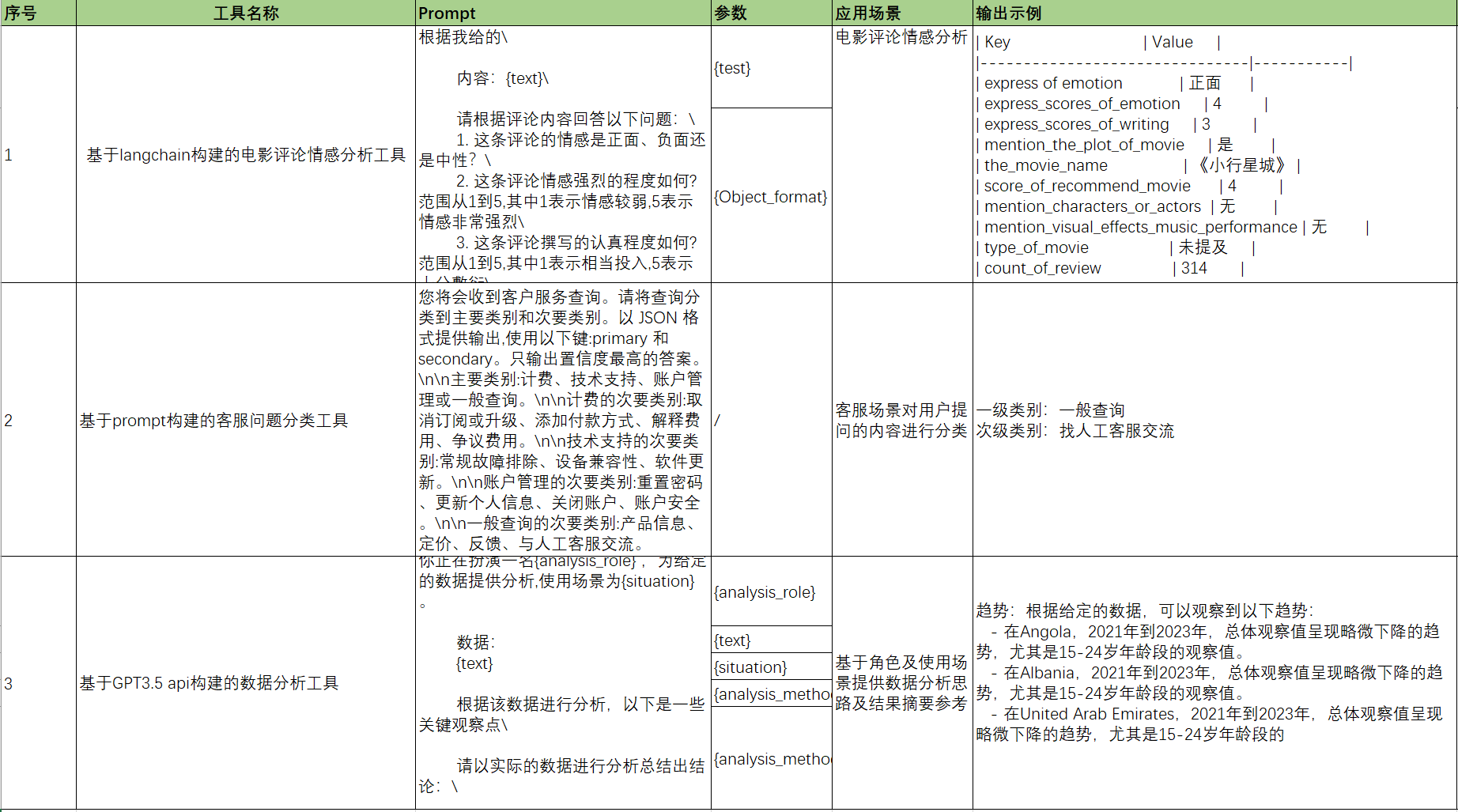
三种工具均能满足个性化的输出需求,只需让用户输入不同的参数,或修改配置文件中的提示词内容即可。
并且开发过程我也是借助LLM,通过自然语言进行编码及代码排查、优化的工作。(通过自然语言生成\校验代码)
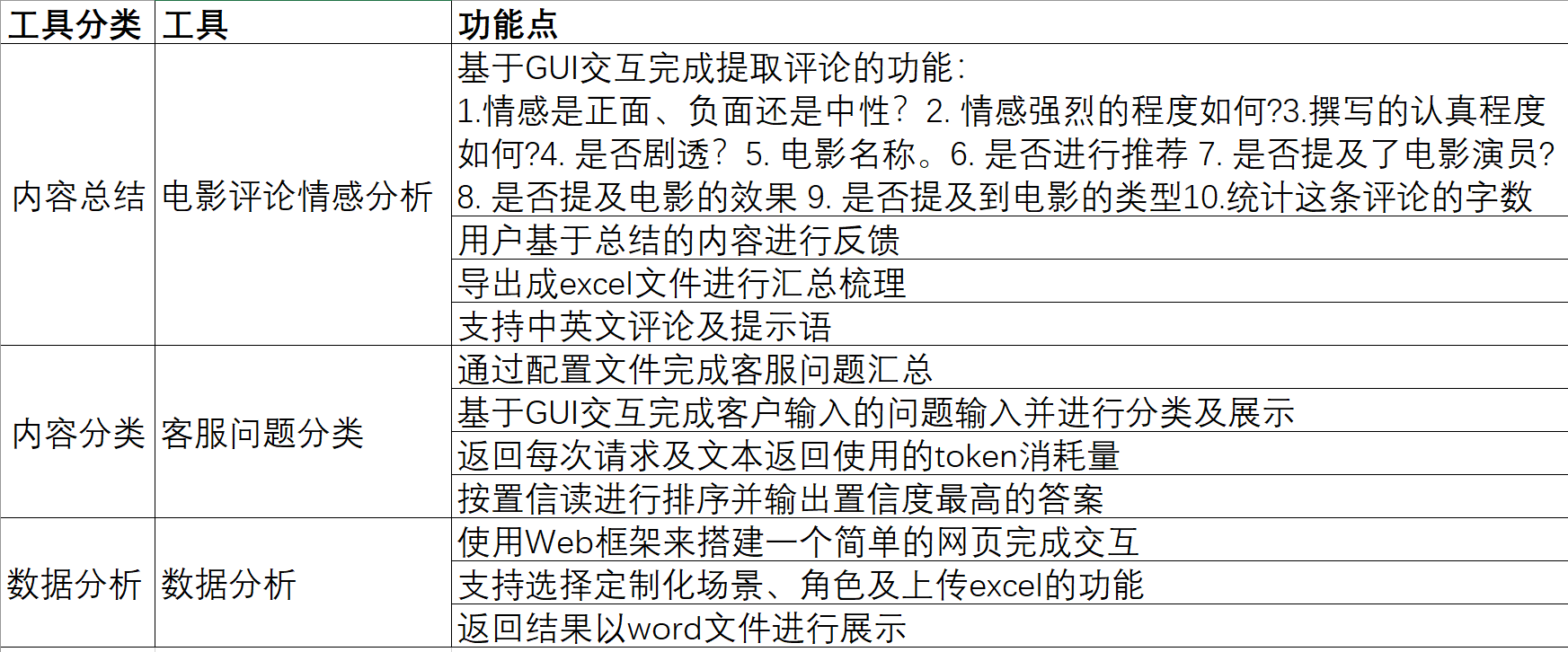
2. 各工具的设计思路、功能特点
在开始搭建工具时,按照LLM的应用场景分类,我选择了文本总结、文本分类及文本分析三个方向,原因很简单:学习的过程也是这么个思路,先是阅读,然后对知识点进行分类,并基于新文本进行分析。
因此在确定了每个方向后,选择了一个场景进行验证试点,文本总结使用豆瓣上的用户评论,文本分类使用电商平台的售后咨询类目,数据分析则使用世界银行发布的各国历史失业率数据。
最后在对每一个场景进行了分析和整理之后,得出了一份材料如下:
3. 过程中的问题及解决方案
在开发过程中识别到的问题可以分为以下几类:
1)问题1. 输出结果不符合预期、结果不可控
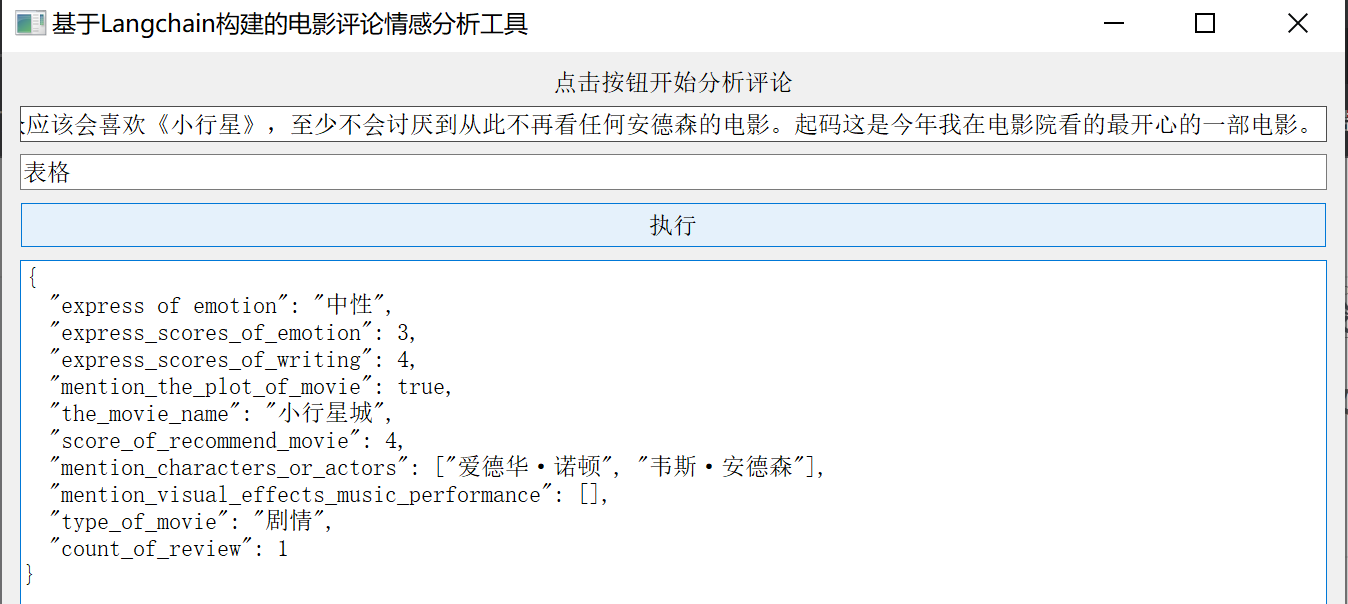
Fig1.返回结果不符合预期
如上图,在输入某一条评论并要求输出表格形式时,得到的结果却是JSON格式。
① 原因分析
因为外部增强属于一种黑盒类的尝试,因此通过实践过程,我了解到一般出现这类问题有以下几个方面的原因:
- 提示语设置不够准确,或者前后矛盾,导致输出不可控
- 提示语与用户文本语言不一致,如使用英文的prompt来分析中文的评论
- 分析步骤太复杂,LLM无法很好的完成分析
② 解决方法
基于以上三个原因,给出三个不同的解决方法:
- prompt提示语中单独增加结果的确认
在输出结果时,请确保是{Object_format}格式\
请保持输出中的语言与原始文本相同 – 如果评论是中文的,则输出也应为中文。\
- 保证输入的文本与prompt的一致。可以在功能层面上维护多套语言的prompt。当用户选择了中文模式时使用中文的prompt提问
- 提示语中设置few-shot或者分析步骤
2)问题2. api调用及token请求问题
毫无疑问,在开发过程中需要科学上网,并且需要限制一定的token请求量,目前GPT3.5单次请求只能包含4390token,超过无法完成分析。
解决方法
- 前端须有token限制的功能,另外需要补充功能记录每次提问及返回结果的token数量,用于监控调用
- 科学上网
3)问题3. 调用量成本
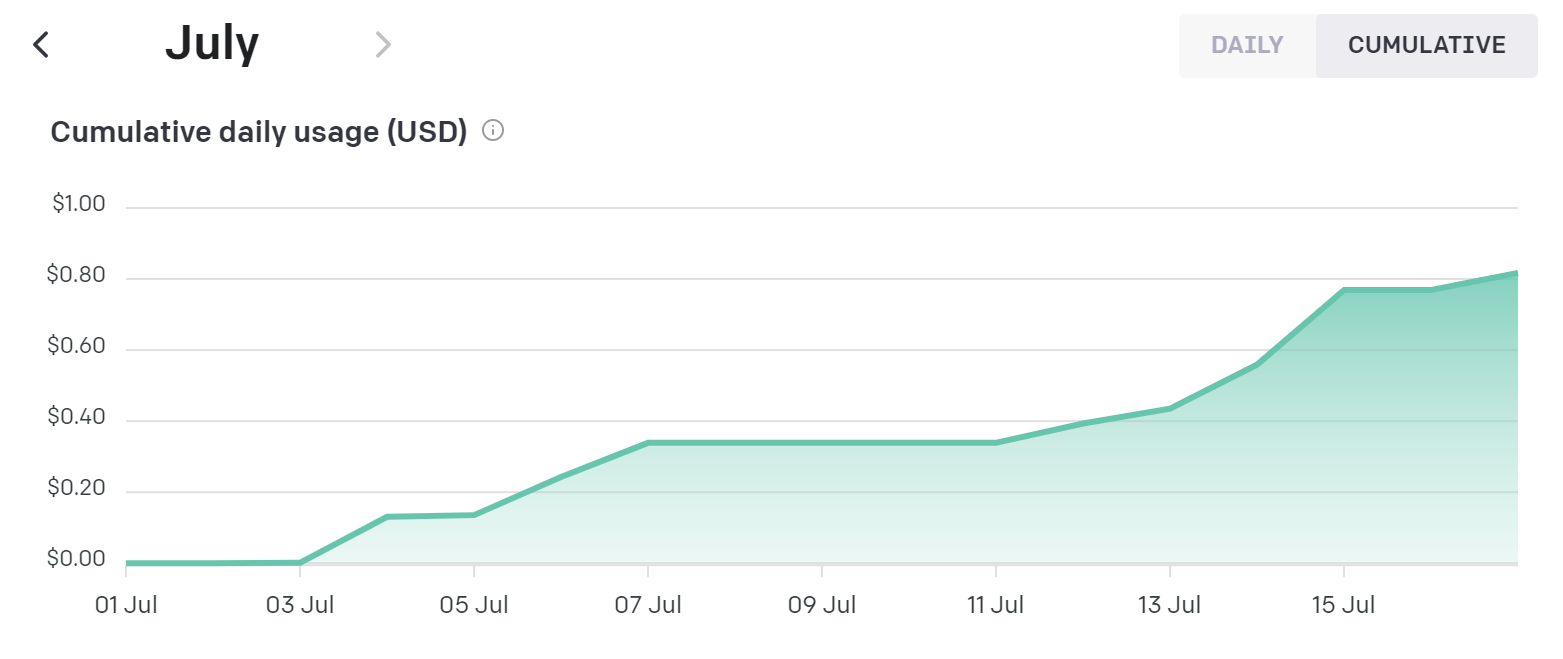
Fig2. usage调用量明细
截取了过去几天的调用数据,平均$0.05/天,折合$0.35,此情况是根据一个用户一天总共50次的请求数量计算的,平均费用为$0.007\天\人,具体取决于你所输入的文本和构造的提示词数量。
解决方法
- 前端需具备发起提问的token限制功能
- 源码中的prompt的构建尽量简洁、清楚、明确
4)问题4. 变现方式及正式商用可行性待评估
LLM目前商用可行性的问题主要有以下三点:
- LLM的可靠性及稳定性
- 工程化方案如何适应每个行业
- 投入产出比如何平衡
LLM无疑可以帮助人们快速地实现各种AI功能,但是从外部增强的角度来进行实践, LLM输出的结果在本质上是不可控的,落地性比较差。
因为涉及到科学上网及使用第三方LLM能力,如何实现更好的工程化,目前还尚未有成熟的方案。
另,利用 LLM所产生的费用是每一个落地项目都要考虑的实际问题。
以上内容,因为本人也还在探索,因此目前只能给出开放性的答案。
解放方法
- 对于 LLM的可靠性,我们可以在 prompt中添加一些小的样本量来描述,并尽可能地对每个请求进行详细地分析,另外也可以增加产品功能、深度学习或者增强学习的方法进行优化
- 工程问题的求解,则是基于行业领域的创新,在此先不展开
- 投入产出平衡问题:如果是试探性的尝试,那就尽量开发一种与已有的产品形式相匹配的轻量级应用形式,并为其提供一个开关,以实现功能的激活和关闭
三、总结及后续
1. 总结
LLM让我以独立开发者的身份,开发出了三款工具,达到了一个人相当于一个团队的效果,大大提高了时间和人力的效率。
LLM的应用潜力巨大,可以帮助人们快速实现各种AI功能。希望未来能够有更多的人加入到LLM的探索和应用中,共同推动AI技术的发展。
2. 后续
考虑到 LLM还有其他两个方向,也是非常值得探索的,后续有机会可以再做一次分享。
- 提示语制作(Prompt crafting)
- 模型微调(Model Fine-tuning)
拓展阅读
‘Beyond One-Model-Fits-All: A Survey of Domain Specialization for Large Language Models’
专栏作家
SiegZhong,人人都是产品经理专栏作家。深入了解AI技术的前沿趋势,并提供实用的解决方案及思考。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。















大语言模型,读半天 读不懂,不要写的这么晦涩难懂行不行,还不如用ai写
啊我着急的分享,忘了解释下一些专业名词,尽量通俗易懂的表达出来,感谢指出问题~