
 起点课堂会员权益
起点课堂会员权益白话科普 | 一次性搞懂AI绘画是如何生成图像的!
为什么我们输入一句话,人工智能便能产出一幅画作呢?AI绘画究竟是如何生成图像的?这篇文章里,作者将AI绘画过程拆解成了5个核心问题,或许搞清楚这5个核心问题,你就能明白AI绘画的工作原理了,一起来看看吧。

写在前面
前段时间和Leader聊AIGC时,提到了关于AI绘画原理的话题,一直只知道人工智能是降噪画图的原理,但是很多细节不是很清楚,挺好奇为什么输入一句话,人工智能就能理解,并且画出来一幅“可圈可点”的画作。
趁着周末爬了些资料,也找学术界朋友给推荐了一些研究论文,大概明白了AI绘画是如何工作的,分享给大家,共勉。
Ps:主要通过白话的方式阐述AI绘画原理,手动绘制了插图和流程图作为示意,算法原理略去了很多细节,适用于泛AIGC爱好者阅读和学习了解。
整个AI绘画过程,我拆解成了五个核心问题,搞清楚这五个问题,AI绘画也就清晰了:
- 我只输入了一句话,AI是怎么知道这句话描述的是什么?
- AI绘画流程里提到的噪声图是哪里来的?
- 就算有了噪声图,噪声图是怎么被一点一点去掉“马赛克”的?
- 那AI是怎么去掉无用的“马赛克”的,最终去掉后是符合效果的?
- 就算有了最终效果,为什么重新作画的结果不一样?
是不是看到这五个问题也有点懵,别着急,下面我们先看下AI绘画的绘制过程,就清楚这五个问题都是在问什么了。
先看总述:AI绘画的绘制过程
AI绘画发展很快,最典型的就是去年的《太空歌剧院》,获得科罗拉多州艺术一等奖,当时还是蛮震撼的。
因为再往前看几年,其实AI绘画的效果是这样的(12年吴恩达和团队用1.6万GPU和上万张数据,花了3天时间画出来的猫…):

我们再看下现在AI绘画的效果(普通人输入一句话,几秒钟画出来的作品):
Source: https://liblib.ai/ 官网
可以看出画质高清、精致,写实感很强,甚至可以比得上摄影师的作品了。
所以AI到底是怎么越来越优秀,根据一句话和几个参数就能画出这么好的作品呢?
先抛结论,AI绘画原理就是:
去除马赛克,就能看清了。
其实N多年前某些成人网就有了类似的技术,不过那个是1vs1还原,AI绘画本质是1vsN还原,核心就是把马赛克一点一点抹掉,最终“漏出”底图,完成所谓的“AI绘画”。

图像绘制:Designed byLiunn
我们先看下,AI绘画的使用场景,所有的软件或模型,基本上第一步都是让用户输入绘画关键词,也就是Prompt。
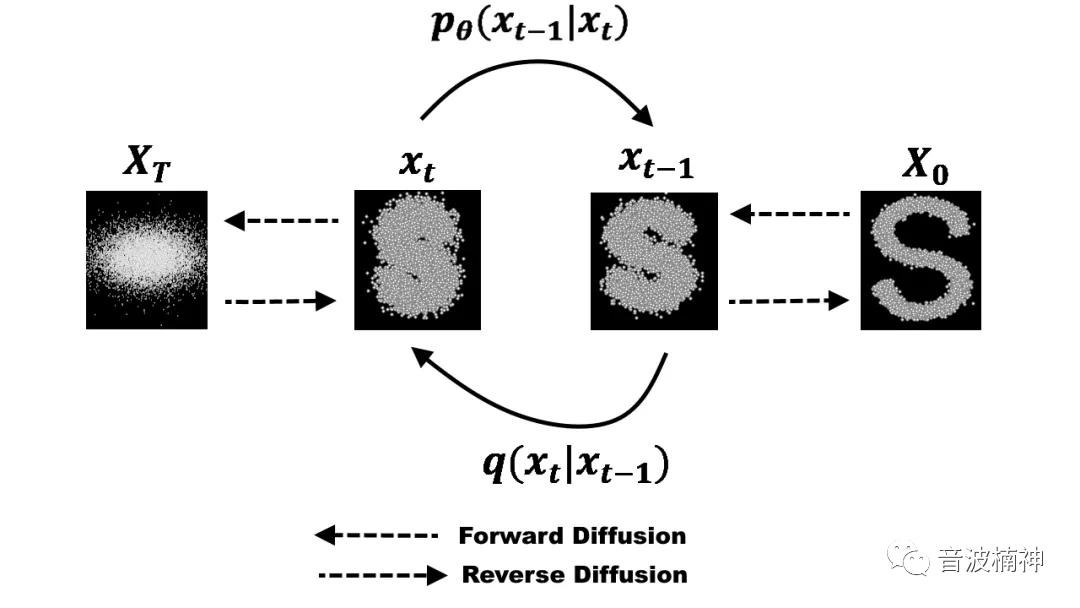
以Diffusion Model的示意如下,我们把最右边的当做正常图片,从右到左是不断模糊的,直至最后看不出来是什么,这个过程就是算法的叠加噪声。
你可以理解为不断对图片进行马赛克处理,这就是最著名的“扩散(Diffusion)”过程。
Source:https://mp.weixin.qq.com/s/ZtsFscz7lbwq_An_1mo0gg
打个比喻,我们把这个过程想象成你在发朋友圈照片时,想屏蔽一些信息,所以使用“编辑”功能不断地对某些区域进行涂抹,直到这个区域看不清原本的内容了。
并且每一次的噪声迭代其实仅仅和上一次的状态相关联,所以这本质上也是一个马尔科夫链模型(简单理解为随机模型,细节可以移步google)。
此时,如果把这个过程倒过来,从左到右做处理,那么就是一步步把一个图片逐渐去除噪声,变清晰的过程。
也就是你的朋友圈照片马赛克越来越少,这个过程就是Diffusion Model的原理。
OK,看到这里,我们明白了大概流程和原理,接下来,我们来依次看五个核心问题。
第一个问题:如何理解文本信息
你输入的文字,AI是怎么知道你想要描述的是什么?
按照上面所说的原理,图片是被一点点抹去马赛克的,但是我写的文本信息是怎么匹配到某一个马赛克图片的呢?
我们都知道,目前AI绘画最主流的使用方式就是在模型或软件里,输入一句话(俗称Prompt),可以写主体、背景、人物、风格、参数等等,然后发送,就可以得到一张图。
比如,“一个穿背带裤打球的鸡”,效果如下:

图像绘制:Source: Designed byLiunn
AI绘画底层也是大模型,是一个图像模型。
最早的时候文本控制模型的做法是让模型生成一堆图片,然后再让分类器从中选出一个最符合的,这种方式没什么不好,唯一的缺点就是当数据量大到一定程度的时候,就会崩溃(想象一下,用excel处理上百亿行的数据,是不是负担很大)。
所以一方面需要非常多的图片数据来训练,另一方面又需要高效且快捷的处理,能承担这个任务的,就是Openai在21年推出的OpenCLIP。
CLIP的工作原理其实可以简单理解为:爬虫、文本+图片的信息对。
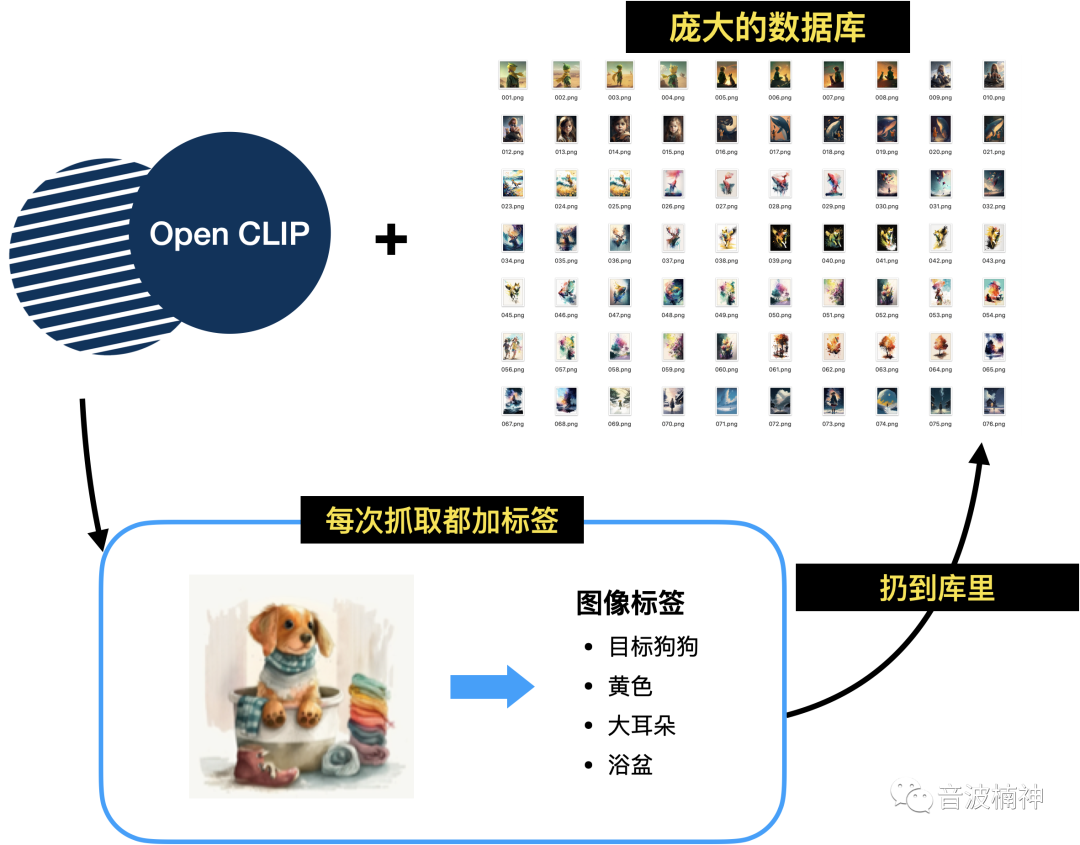
第一,先看CLIP的爬虫和数据库。
CLIP的最大亮点之一就是采用了非常多的数据,构成了一个庞大的数据库。
每次CLIP爬取到一张图片后,都会给图片打上对应的标签以及描述(实际CLIP 是根据从网络上抓取的图像以及其 “alt” 标签进行训练的)

Source:https://jalammar.github.io/illustrated-stable-diffusion/,引自Jay Alammar博客
然后从768个维度重新编码这些信息(你可以理解为从768个不同的角度来描述这个图)。
然后根据这些信息构建出一个超多维的数据库,每一个维度都会和其他维度交叉起来。
同时相似的维度会相对靠拢在一起,按照这种方式CLIP不断爬取,最终构建了一个大概4~5亿的数据库。
图像绘制:Source: Designed byLiunn
第二,再看CLIP的文本图像匹配能力。
OK,有了数据库,库里的图像怎么和输入的文字匹配呢?这里又分两个步骤:
步骤01,怎么具备文本-图像匹配的能力。
先看下图,是算法的原理图,看不懂没关系,我在下面重新绘制了一幅降维版的示意图。
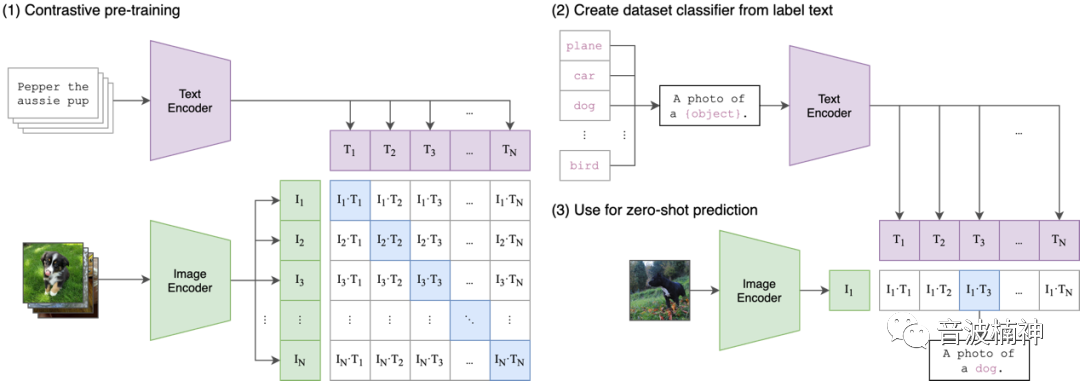
Source: https://github.com/openai/CLIP
我们来看下面这幅示意图,CLIP是如何识别文本和图像的关联。
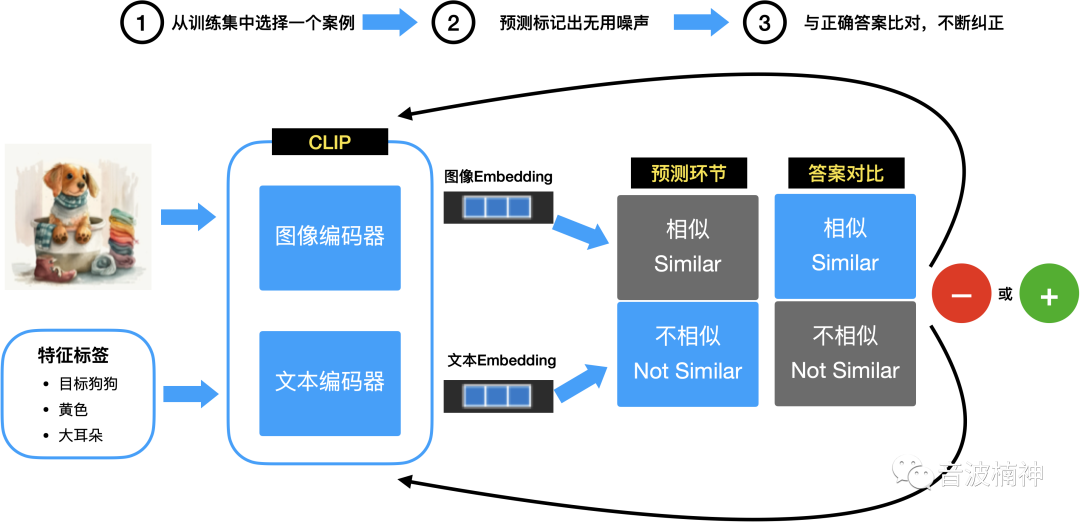
作图绘制参考Source: https://jalammar.github.io/illustrated-stable-diffusion/,Designed By Liunn
这里是一个简化的算法模型,其本质是不断地通过大量数据来训练CLIP去关联、认识图片和文字,并且根据和答案的比对,不断地矫正,最后达到精确匹配关键词和特征向量。
步骤02,如何去做文本-图像匹配的关联。
好了,我们再来看CLIP是如何做到文本图像的匹配的。
当我们开始作画时,会录入文本描述(即Prompt),CLIP模型就会根据Prompt去上面的数据库里从768个维度进行相似度的匹配,然后拿图像和文本编码后的特征去计算出一个相似性矩阵。
再根据最大化对角线元素同时最小化非对角线元素的约束,不断地优化和调整编码器,最终让文本和图片编码器的语义强关联起来。

图像绘制:Source: Designed byLiunn
最后,当找到最相似的维度描述后,把这些图像特征全部融合到一起,构建出本次要产出的图像的总图像特征向量集。
至此,输入的一段话,就转换成了这次生成图像所需要的全部特征向量,也就是AI所谓的已经“理解了你想画什么样的画了”。
这个跨越已经算是AI界的“登月一小步”了
有了CLIP的这个创新举措,基本上彻底打通了文字和图片之间的鸿沟,搭建了一个文本和图像之间关联的桥梁,再也不需要以前图像处理界的打标签的方式来不断堆人了。
第二个问题:原始噪声图的来源
上面讲到AI绘画是把“马赛克”一点点抹掉,那所谓的“马赛克”图,也就是噪声图是怎么来的呢?
噪声图的是扩散模型生成的,先记住这个概念“扩散模型”。
讲扩散模型之前,需要先讲另一个概念,AI生成图片的过程,其实是人工智能领域的一个分支,生成模型(Generative Model)。
生成模型主要是生成图像的,通过扔进去大量真实的图片让AI不断去了解、认识和学习,然后根据训练效果,自己生成图片。
在生成模型里,有个自动编码器的东西,它包含两个部分:编码器和解码器。
编码器可以把比较大的数据量压缩为较小的数据量,压缩的前提是这个较小的数据量是能够代表最开始的大数据量的;
解码器可以根据这个较小的数据量在适当的条件下,还原为最开始的的大数据量。
所以这个时候就有意思了:
能否直接给它一个较小的数据量,看看它自己能随机扩大成一个什么样的大数据量?
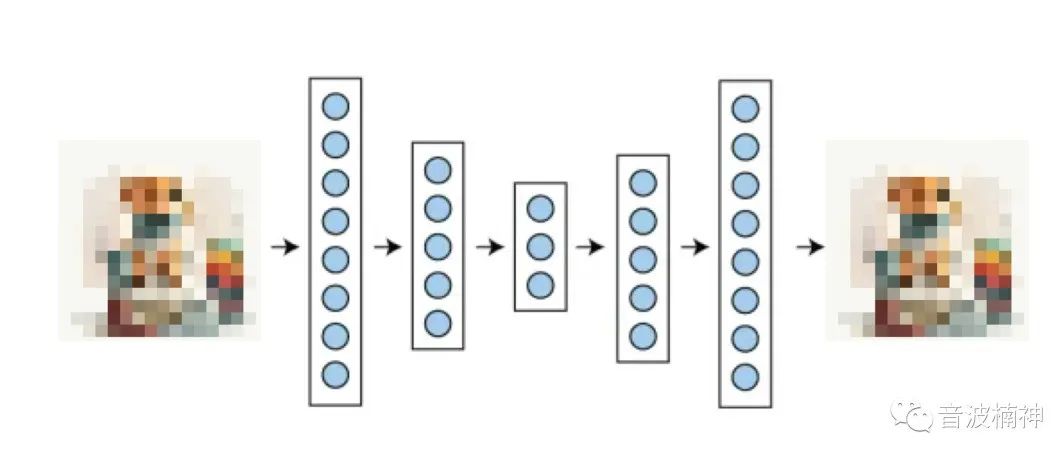
图像绘制:Source: Designed byLiunn
答案是可以的,但,测试效果很一般。
所以自动编码器不行了,怎么办呢,科学家发明了另一个东西,叫VAE(变分编码器,Variational Auto-encoder)。
VAE是做什么的,主要是把较小的数据量进行规律化,让其符合高斯分布的概率。
这样就可以依据这个,来调整一个图片信息按照概率的变化进行对应的改变,但是有个问题,这个太依赖概率了,大部分概率都是假设的理想情况,那怎么办呢?
所以这个时候科学家就想,能不能做两个AI,一个负责生成,一个负责检验它生成的行不行,也就是AI互相评估真假,这就是GAN,对抗神经网络诞生了。
GAN一方面生成图片,一方面自己检测行不行,比如有时候有些图片细节没有按照要求生成,检测的时候GAN发现了,它后面就会不断加强这块,最终让自己觉得结果可以,这样不断地迭代成千上亿次,最终生成的结果,检测也OK的时候,就是生成了一个AI的图片了。
但问题又来了
GAN一方面自己做运动员,一方面自己做裁判,太忙了,不仅消耗大量的计算资源,同时也容易出错,稳定性也不好,那怎么办呢?能不能让AI别搞这么复杂,用一套流程完成呢?
答案是肯定的,这就是跨越了生成模型时代后,扩散模型的时代到来了。
话题回到扩散模型这里。
扩散模型最早是由斯坦福和伯克利学术专家,在2015年相关论文里提出的,依据正态分布给图像逐步增加噪声,到了2020年加噪声的过程被改为根据余弦相似度的规律来处理。(文末附上了15年和20年的原始学术论文链接,感兴趣可以自行阅读)
根据余弦调度逐渐正向扩散原始图,就像把一个完整的拼图一步一步拆开,直至完全打乱。

图像绘制:Source:Designed byLiunn
到这里,第二个问题也解决了。当你看到这里的时候,AI绘画的输入信息基本Ready了。
第三个问题:模型如何去除噪声
AI把文字转成了特征向量了,也拿到噪声图片了,但噪声图是怎么一点点被去除“马赛克”的呢?
它是怎么消除掉马赛克的呢?这里面分为两个步骤:
步骤一,降维数据运算,提升运算效率;
步骤二,设计降噪网络,识别无用噪声,精准降噪。
先看步骤一:还记得上文提到的自动编码器么?
图像特征向量和噪声图,会一起扔到编码器里进行降噪,也就是去除马赛克的过程。
但是这里有个问题,就是一张512*512的RGB图片就需要运算786432次,即512*512*3=786432条数据,这个运算量太大了
所以在这些数据在进入到编码器之前,都会被压缩到潜空间里去,降维到64*64*4=16384条数据(不知道你有没有用SD的时候注意到,我们在Stable Diffusion里调整图像大小的时候,最小只能拖到64px,这就是其中的原因)。
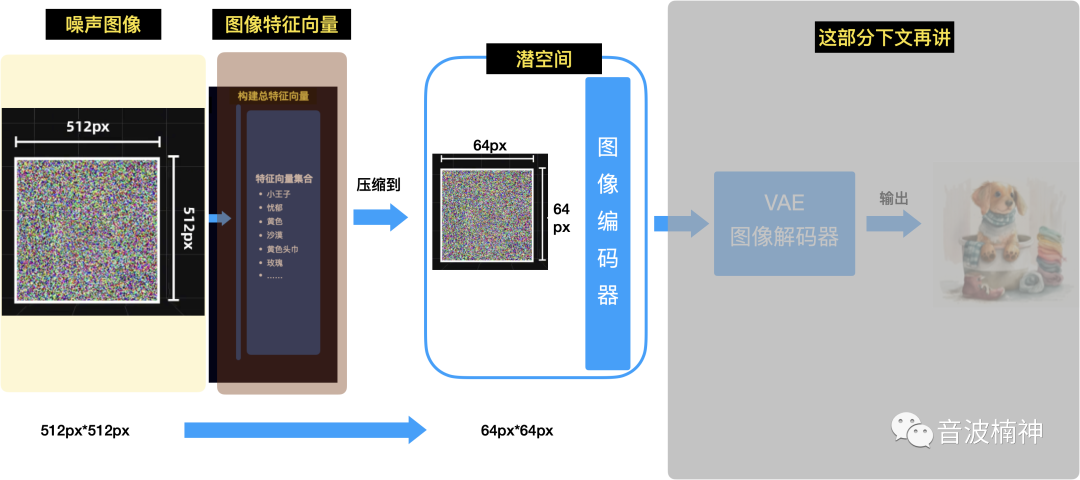
Source:https://jalammar.github.io/illustrated-stable-diffusion,Designed byLiunn
这样的话,整个文生图的任务就能够降维到消费级的GPU上运算(虽然现在算力依然是个问题,A100都没有吧?有的话 私我!)
降低了落地门槛,运算和配置效率都得到了极大的提升。
再看步骤二:设计一个降噪网络。
明白了数据降维的问题,我们继续看,AI怎么逐步去除噪声生成新图呢,图像编码器又是如何给图像降噪,从而生成一张全新的图片的呢?

图像绘制:Designed byLiunn
关于降噪方式,ddpm在2020年年底的相关论文预测了三件事:
- 噪声均值(mean of noise):预测每个时间步长的噪声均值。
- 原始图像(original image):直接预测原始图像,一步到位。
- 图像噪声(noise of image):直接预测图像中的噪声,以获得噪声更少的图像。
现在的模型,大部分都是采用了第三种方式。
这个去除噪声的网络是怎么设计的呢?
这个主要归功于编码器中的U-Net(卷积神经网络-图像分割)了。
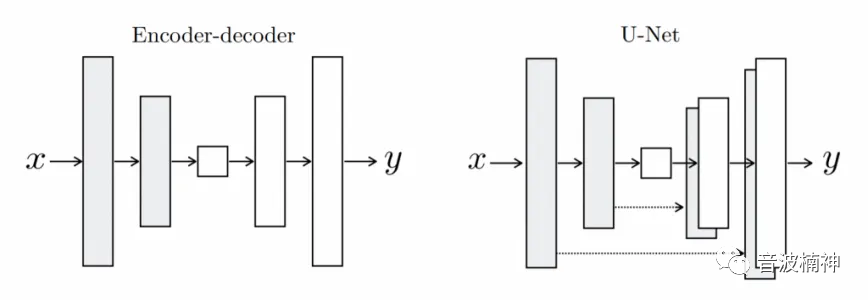
Source:https://jalammar.github.io/illustrated-stable-diffusion/
U-Net是一个类似于编码-解码器的漏斗形状的网络(上图左),不同点在于U-Net在相同层级的编码、解码层增加了直连通道(你可以理解为两栋大楼之间,同一楼层之间加了连桥,可以走动)
这样好处在于处理图片时,相同位置的信息在编码、解码过程中可以方便快捷的进行信息传输。
那它是怎么工作的呢?
刚才我们说了,DDPM提到,目前基本上所有的模型都采用直接预测图像中的噪声,以便于获得一张噪声更少的图片。
U-Net也是如此。
U-Net根据拿到第一节里提到的图像的全部特征向量集合后,从向量集合里通过采样的方式抽取一部分特征向量,再根据这些向量识别出其中的无用的噪声
然后用最开始的全噪声图和当前这次预测的噪声做减法(实际处理过程比这会复杂一些),然后得到一个比最开始噪声少一些的图,然后再拿这个图,重复上述流程,再次通过采样的方式抽取一部分特征向量,再去做噪声预测,然后再拿N-2次的图像和N-1次的图像相减,拿到N-3次的图像
继续重复上述流程,直至最终图像清晰,没有噪声或没有识别出无用的噪声为止,最终生成一张符合要求的图像。
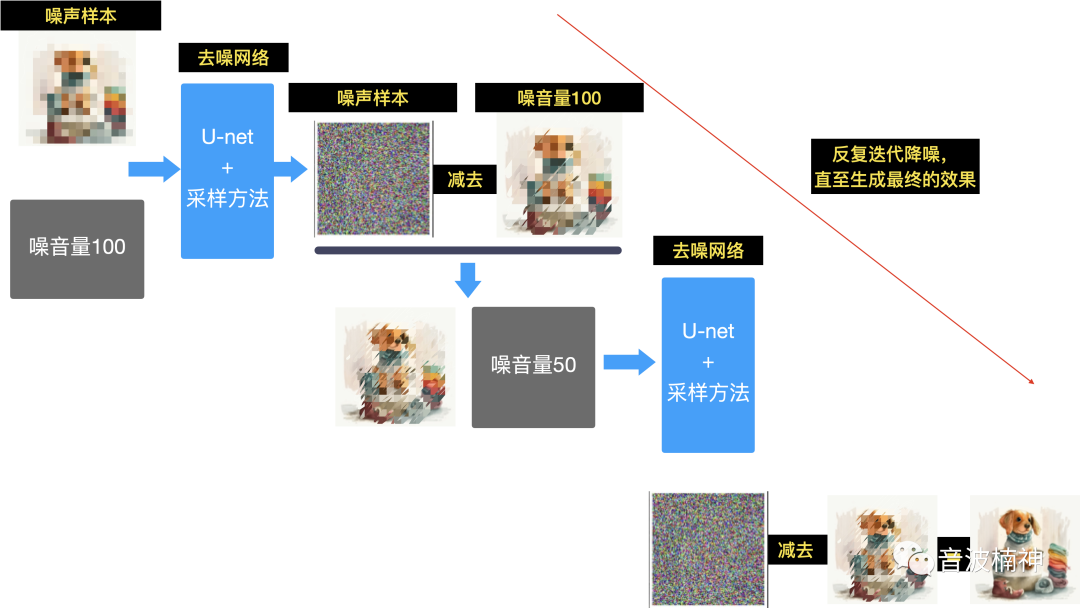
图像绘制思路:Source:https://jalammar.github.io/illustrated-stable-diffusion/,Designed byLiunn
这里面,有的同学注意到了,还涉及到一个采样方法的环节。
每一次的采样,根据不同的采样方法,可以用同样的方式,也可以用不同的采样方式。不同的采样方法会抽取出不同维度、不同特质、不同规模的特征向量,最终确实会对输出结果有影响(这也是影响AI绘画可控性的因素之一)。
最后,还记得刚刚提到的数据降维吗?
降维是为了降低运算量,加快速度,降维后其实是进入到一个潜空间里,那么图像全部降噪完成后,会通过图像解压器也就是VAE模型,重新还原回来,被重新释放到像素空间里(可以理解为IPhone里云端存储的照片,你最开始看的是缩略图,当你点开大图想看的时候,会慢慢从云端下载,变成高清的)。
以上,就是噪声模型网络去噪的简易过程。
第四个问题:应该去除哪些无用的噪声
AI是怎么能够按照我描述的来去除特定的马赛克,而不是我写了“狗狗”,画出来一只“猫咪”呢?
U-Net模型如何识别应该去除哪些噪声呢?其实这就是一个模型训练的过程。
讲解模型训练之前,需要先普及几个概念:
- 训练集:用来不断让AI学习和纠错的,让AI可以不断成长的一个数据集合,你可以理解为打篮球时教练带你在训练场训练。
- 强化学习:当AI犯错的时候,告诉它错了;当AI正确的时候,告诉他对了;你可以理解为篮球教练在不断纠正你的投篮姿势,让你训练的更快更强。
- 测试集:用训练集训练一段时间后,看看AI能力如何的一个数据集合,你可以理解为打篮球时训练半年,组织了一场友谊赛。
先看U-Net的训练集是怎么构建的,主要分为四个步骤:
- 从图文数据集中随机选择照片;
- 生产不同强度的噪声,顺次排列;
- 随机选择某个强度的噪声;
- 将该噪声加到图片里。
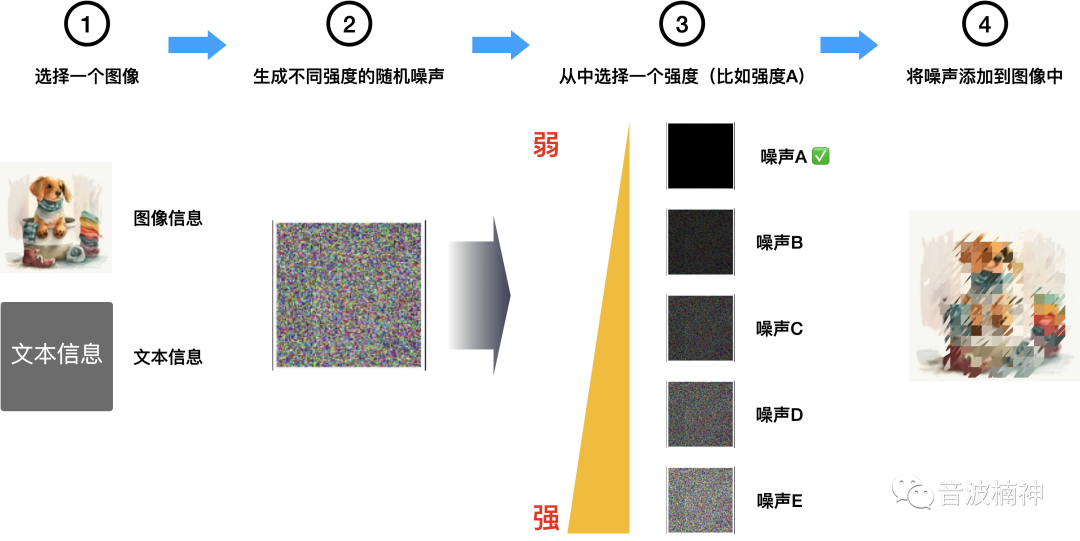
图像绘制思路:Source:https://jalammar.github.io/illustrated-stable-diffusion/,Designed byLiunn
再来看U-net是怎么处理的。
U-Net的训练集是很多张已经叠加了随机噪声的数据库,可以理解为很多添加了马赛克的图片(篮球训练场地),然后让AI不断地从这个数据库里抽取图片出来,自己尝试抹去噪声,全部抹掉后再来和这张图的原图做比对,看看差别多大。
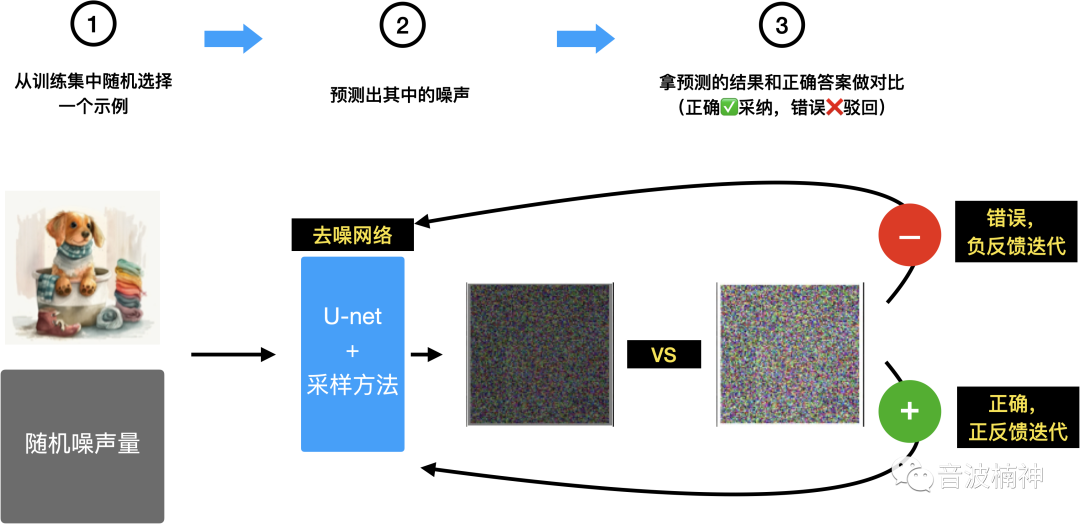
图像绘制思路:Source:https://jalammar.github.io/illustrated-stable-diffusion/,Designed byLiunn
计算出这个差距,然后重新去库里抽取,再尝试抹去噪声(强化学习),循环无数次,最终实现的效果是,无论怎么随机抽,并且换一个新的噪声图片库(测试集),AI抹掉的噪声后的图像也能和原图很像(风格都类似,不一定是原图,这也就是为什么AI每次出图都不一样)。
这样的话就算通过了,这个模型就算Ready了(可以上线了)。
以上就是U-Net识别且去除无用噪声的过程。
第五个问题(稳定性控制),我应该如何控制出图效果?
经常玩AI绘画的小伙伴会发现,其实目前大模型最不可控的地方就是它的不稳定性。
那么如果想要稍微控制下AI绘画的效果,有什么好的方法吗?
这里给出四种方式,供大家参考。
first:调整Prompt(也就是改描述语,本质是调整图片的CLIP特征)
通过输入不同的描述词,以及更改局部Prompt,一步步引导AI模型输出不同的图像,其本质就是更改了匹配到的CLIP对应的待处理的图像特征向量集合,所以最终的出图会不断地调整、优化(这里还有一些玄学技巧,比如给某些Prompt里的部分起名字,也可以获得稳定性,本质是给部分Prompt结构打标记,便于AI算法识别…)。
Second:垫图(也就是俗称的img2img,本质是加噪声)
现在主流的AI绘画软件和模型都支持垫图功能,也就是你上传一张图,然后根据你这张图的轮廓或者大概样式,再生成一张图。
其本质就是将你上传的图叠加几层噪声,然后拿这个叠噪后的图片作为基础再让AI进行去噪操作,后续流程不变,所以最终风格、结构和原图相似的概率很大。
不过值得一提的是,现在很多Webui还支持选择和原图相似度多少的操作,对应到算法上其实就是在问你要叠加多少层噪声,当然是叠加的噪声越少,越和原图相似,反之可能越不像(不过这也是概率问题,也会存在叠加的多的时候生成的图也比叠加的少的时候更像)。
Third,插件(通过第三方插件/工具辅助控制,本质是训练模型)
拿最典型、最经典的ControlNet来说,可以通过任意条件或要求来控制生成的效果,基本上可以说是指哪打哪的效果了。
其本质你可以理解为是通过一张图来训练模型,达到自己想要的效果。
它把去噪模型整个复制了一遍,然后两个模型并行处理,一个做常态去噪,一个做条件去噪,最后再合并,达到稳定控制的效果。
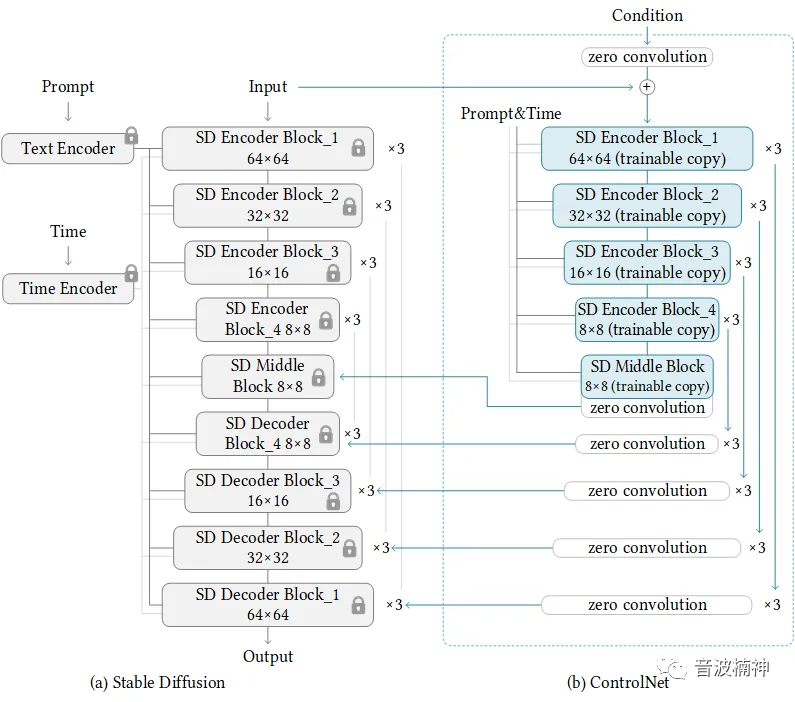
Fourth,训练模型(自己拿大量数据单独训练,本质是Finetune)
这个不解释了吧,就是你自己有很多图,自己建个图像库,然后不断地训练大模型去识别这些图像,最终给模型一两个词,大模型就能识别且生成相似的图像,这样就实现了Finetune一个自己的小模型的效果。
注意:Finetune需要注意边界和用力程度,测试集的效果的评判指标要做好,否则训练时间很久的时候,就会对小样本数据过拟合,这样会失去大模型的泛化性,可能得不偿失(也有解决方案,比如Reply,让大模型重新学一遍,或者正则化模型,或者做并行模型,细节不展开)。
恭喜,当你阅读到这里的时候,基本上应该已经了解了AI绘画的前龙去脉了,由于是把很多算法文章抽象为了白话文,所以很多细节也都略去了,抛砖引玉,有遗漏或不当的地方,欢迎和大家交流、互相学习。
说好的福利来了,相信AIGC死忠粉会喜欢。
惊喜:分享7个常见的文图生成的数据集
COCO(COCO Captions)
COCO Captions是一个字幕数据集,它以场景理解为目标,从日常生活场景中捕获图片数据,通过人工生成图片描述。该数据集包含330K个图文对。
数据集下载链接:https://cocodataset.org/
Visual Genome
Visual Genome是李飞飞在2016年发布的大规模图片语义理解数据集,含图像和问答数据。标注密集,语义多样。该数据集包含5M个图文对。
数据集下载链接:http://visualgenome.org/
Conceptual Captions(CC)
Conceptual Captions(CC)是一个非人工注释的多模态数据,包含图像URL以及字幕。对应的字幕描述是从网站的alt-text属性过滤而来。CC数据集因为数据量的不同分为CC3M(约330万对图文对)以及CC12M(约1200万对图文对)两个版本。
数据集下载链接:https: //ai.google.com/research/ConceptualCaptions/
YFCC100M
YFCC100M数据库是2014年来基于雅虎Flickr的影像数据库。该库由一亿条产生于2004年至2014年间的多条媒体数据组成,其中包含了9920万张的照片数据以及80万条视频数据。YFCC100M数据集是在数据库的基础之上建立了一个文本数据文档,文档中每一行都是一条照片或视频的元数据。
数据集下载链接:http://projects.dfki.uni-kl.de/yfcc100m/
ALT200M
ALT200M是微软团队为了研究缩放趋势在描述任务上的特点而构建的一个大规模图像-文本数据集。该数据集包含200M个图像-文本对。对应的文本描述是从网站的alt-text属性过滤而来。(私有数据集,无数据集链接)
LAION-400M
LAION-400M通过CommonCrwal获取2014-2021年网页中的文本和图片,然后使用CLIP过滤掉图像和文本嵌入相似度低于0.3的图文对,最终保留4亿个图像-文本对。然而,LAION-400M含有大量令人不适的图片,对文图生成任务影响较大。很多人用该数据集来生成色情图片,产生不好的影响。因此,更大更干净的数据集成为需求。
数据集下载链接:https://laion.ai/blog/laion-400-open-dataset/
LAION-5B
LAION-5B是目前已知且开源的最大规模的多模态数据集。它通过CommonCrawl获取文本和图片,然后使用CLIP过滤掉图像和文本嵌入相似度低于0.28的图文对,最终保留下来50亿个图像-文本对。该数据集包含23.2亿的英文描述,22.6亿个100+其他语言以及12.7亿的未知语。
数据集下载链接:https://laion.ai/blog/laion-5b/
最后,一些题外话:
AIGC技术的发展,除了数据突破、算力突破、算法突破等等之外。
我觉得最重要的一点是:开源。
开源,代表的是公开、透明、分享、共同进步,期待共创。
包括像上面提到的CLIP(OpenAI共享了模型权重),不可否认有些国家核心技术不能开源可以理解,但是AI开源这事,确实可以让众多研究人员、科学家、学者甚至野生的爱好者获得最大的信息量和透明度。
以此;
在该基础上快速、健康、多样化的进行衍生和发展,这是极其有利于整个AI生态的长期、可持续、良性发展的。
分享即学习,AI的新时代,永远是共享、透明的主旋律。
尽量抛弃有个好想法,闭门造车的状态,共同打造一个AIGC环境和氛围。
这样当你坐在波音飞机上的时候,就可以不用太纠结坐前排还是坐后排了,因为你本身已经在超速前进了……
附部分参考资料和CLIP源文档:
- OpenCLIP 的 GitHub 网址:https://github.com/mlfoundations/open_clip
- 15年的扩散模型论文:《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》https://arxiv.org/abs/1503.03585
- 20年的DDPM论文:《Denoising Diffusion Probabilistic Models》https://arxiv.org/abs/2006.11239
- 《High-Resolution Image Synthesis with Latent Diffusion Models》:https://arxiv.org/abs/2112.10752
- 《Hierarchical Text-Conditional Image Generation with CLIP Latents》:https://arxiv.org/pdf/2204.06125.pdf
- 《Adding Conditional Control to Text-to-Image Diffusion Models》:https://arxiv.org/abs/2302.05543
- 文末惊喜一的7个数据集的原始出处:引自 整数智能AI研究院《从文本创建艺术,AI图像生成器的数据集是如果构建的》
- 部分绘图参考思路出处:引自亚马逊云开发者《Generative AI新世界 | 走进文生图(Text-to-Image)领域》
- 部分思路参考出处:引自腾讯云开发者《【白话科普】10分钟从零看懂AI绘画原理》
- 【科普】你的文字是怎么变成图片的?https://v.douyin.com/iemGnE9L/
- 以及部分博客作者的博文
专栏作家
楠神,公众号:音波楠神,人人都是产品经理专栏作家。大厂AI高级产品经理,AIGC商业模式探索家,长期探索AI行业机会,擅长AI+行业的解决方案设计及AIGC风口、流量感知。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









这么有水平的大佬,竟然也露出了鸡脚。
原来你也🐔你太美嘛
AI画图出来这么久,总算有大神把这事说明白了。
非技术人员,看的还是似懂非懂的,哈哈。点赞作者分享!