起点课堂会员权益
起点课堂会员权益
从Agent到多模态,大模型想要什么?
 技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估
技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估人类大脑皮层是相似的,但因为感知反馈处理内容不同而分成了不同的功能区来处理听觉、视觉和味道。OpenAI如果真的如预期在这条路上彻底跑通商业模式,那无疑是对整个行业的最大刺激,也会给自己打下超级巨头的坚实基础。

OpenAI 9.25发了个关于多模态版本的Blog说chatGPT现在能够看、听、说了,体验过的同学反馈还不错,那这意味着什么?
一、应用>纯粹的智能改进
同纯粹的智能提升相比多模态是一种应用可能性的提升。如果说原本的大模型瓮中之脑,那多模态无疑是把给这个瓮中之脑接上和现实世界相联的触角。
从技术上,这意味着之前这是在多种算法的综合上发力,而不是单纯的强调智能这一个维度。这种衔接在过去其实是吃力的,OpenAI看起来也没把这问题解决的特别好,所以在文章中贴了这么一小段:

这啥意思呢?其实是说语音识别通用度不好,反过来推测一点就是语音识别还没有自己的大模型。希望OpenAI能在这种综合和衔接上取得进展。
值得一提的是,这种方向和很多人心心念念的GPT5是不完全重叠的,GPT5更像是让瓮中之脑更为强大,而多模态综合则是让现有大脑的智力得到更好的发挥。如果OpenAI贴着多模态走,那意味着他们在战略上把应用放到了更前面。这是对的,并且和人类的大脑产生智能的情况更贴近。人类大脑皮层是相似的,但因为感知反馈处理内容不同而分成了不同的功能区来处理听觉、视觉和味道。
OpenAI如果真的如预期在这条路上彻底跑通商业模式,那无疑是对整个行业的最大刺激,也会给自己打下超级巨头的坚实基础。
从应用上这意味着应用范围的拓宽。那里需要多模态呢?显然是物理空间。纯粹的瓮中之脑其实是把应用局限在数字空间,而多模态则打通数字和物理世界。最直接的,这类能力会激活多模态的应用。

典型的多模态应用是什么呢?是PokemanGo。介于纯粹的数字世界和纯粹的物理世界之间就是这种增强现实的场景,没多模态这类应用根本玩不转。
在过去这做起来成本太高了,算法的综合像一道天堑一样,让只有很少的公司才能做,而做的人里面只有很少的人才能成功,而综合后的大模型如果能削减这个壁垒,那显然的这类应用就可以像当年的App一样,只承担产品化的部分,进而迎来自己的大普及。
但多模态的路线所影响的却不只是这类增强现实应用,它的影响需要放在整个AI产品化进程的角度来看,才更清楚。
过去十年AI的创业其实是失败的,但核心的好处是让我们把所有的坑都趟了一遍,更容易在这些失败的基础上,看清和经营未来的现实。

(华为的战略从侧面反映过去这十年硬应用的探索,重点可以回想N)
二、背后隐含的产品路线
我们画下不精确的产品路线图。
递进次序是纯粹数字空间,数字和物理空间融合,硬件产品,机电类产品,另一个轴是智能的多模态程度,如:单一维度的通用智能和多模态的通用智能,那产品分布会是:

如果再加个维度,每一类中再有两类:一类是幻觉无碍的,一类是需要解决幻觉问题的。
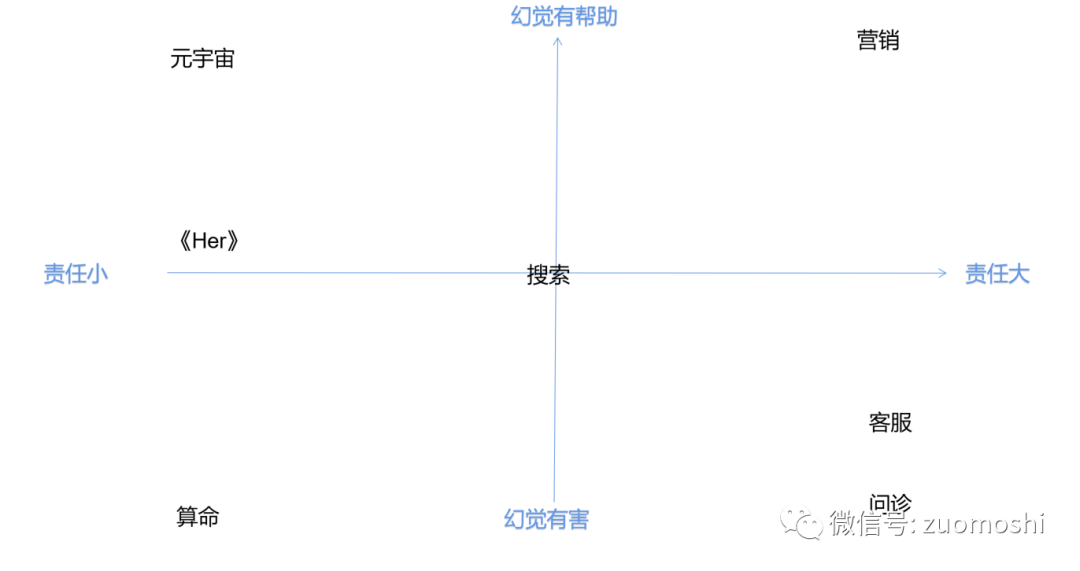
那么很可能就可以得到这次大模型驱动的产品落地的次序。产品上会从软应用到硬应用再到机械应用,特征上会从幻觉有益到需要对冲。
这么说可能不容易懂,我们拿过去的产品做个类比(尝试的好处就这么出来了,可以举例子)。
同样是对话,客服是软应用,智能音箱是硬应用,招待机器人则是机械应用。
这些产品看着超级像,但每加一部分外延都导致游戏规则有巨大变化。
软应用的输入相对容易标准化,到硬应用则变的麻烦,在语音上过去我们用近场和远场来形容这种差异。都是对话,需不需要解决环境干扰问题导致的产品复杂度会有巨大差异。到现在为止,智能音箱其实也没彻底解决这问题,你在边上放电视它一样会变不好使。
类似的准备好图片的人脸识别和真实场景的人脸识别有同样问题。后者没准就需要在光线没那么好的情景下处理问题。
硬应用同机械应用比自身的稳定性会形成更多问题。比如机器人突然间脖子扭的角度不对,或者一条狗跑来跑去的时候腿瘸了,即使还是能够听说,那产品体验也会出现巨大起伏。
详细挖掘差异还会有很多,也许看着没那么大,但真做产品这种细小差异是忽略不得的。
如果把纯粹数字的新特征比喻成是一个巨大的氢气球,可以四处乱跑,成本不高。那硬应用差不多相当于挂块砖头,机械应用则像挂一个小铅球。挂的东西论体积远不如气球,但对氢气球能不能飞起来影响是巨大的。
为了它能飞起来,最好的办法是尊重新的环境条件,然后配个大引擎变成飞机。而变飞机显然是个系统工程。
上面这种产品分类正好也就是Agent的分类。多模态的进展同样会打开Agent的范围。真做这类产品,打造自己的飞机,核心依赖会是什么呢?
参照:AI Agent:大模型与场景间的价值之桥,但不适合当纯技术看
三、回到系统型超级应用:多模态Agent的典型架构
典型Agent的运行状态是这样:
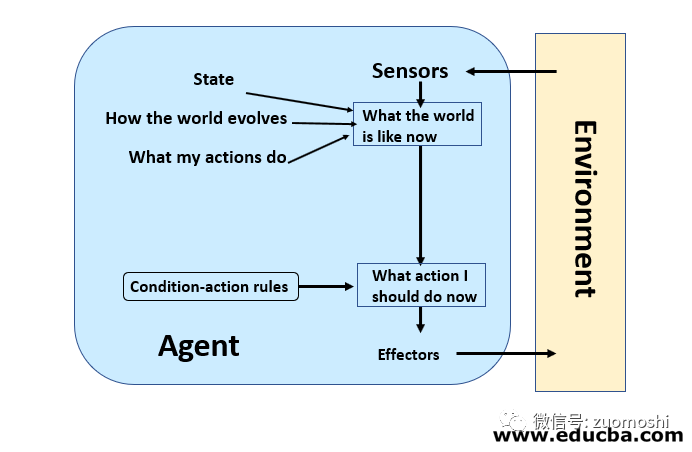
这看着很常识,但其实带来一个巨大挑战。
你的多模态大模型是统一的,但你的应用是分散的(单一产品的集成这问题不大,但那反倒是特例)。
大模型的通用能力,需要一种通用的通路才能很好的输出去,否则就像武侠小说里说的内功很好,但经脉很差,没的发挥。
为了把这种通用能力发挥出去,最关键的就是需要对感知一侧进行通用的抽象和管理。
这里面有个依赖次序,各种应用本质上依赖多模态大模型,但多模态大模型依赖多模态的感知。
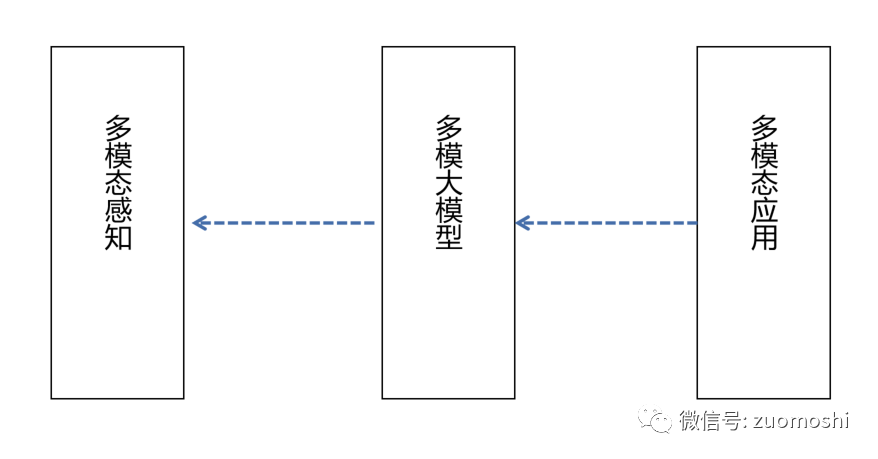
这种依赖递进影响什么呢?
影响特征的传导次序,本质上被依赖方的特征会传导到后者去,后者只能扛着。反向传播则影响要小的多。
比如多模态感知在产品上肯定具现成五花八门各种产品,然后数据从各种传感器来,传感器会完成模拟到数字的转化,所以出来的基本都是结构化数据。
这就导致必然出现过去操作系统中的硬件抽象层,是个传统工作要解决基础架构问题,要有一个抽象层覆盖五花八门的设备。
多模态应用则要充分利用大模型的特征,这时候接口形态都会发生巨大变化。会从传统的API一点点变成现在的NLI。你需要适应大模型的基础特征,比如面对前面提到的幻觉问题。API的调用值是变化的,但它的Schema是稳定的,是在限定的Schema下返回各种值。但NLI,则Schema也是打开的。这就不好应对需要确定结果的场景。是真正的挑战。
分层并分割这种应用后得到什么呢,会得到系统型超级应用。
四、系统型超级应用的极简例子
我们举个最简单的例子:
假设你想给自己做个数字分身,打理自己在各个平台上的活动。
那么对个人而言,你需要创建基本人设、风格(风格要考虑目标平台场景的特征)等。你的应用基于这种人设通过NLI和大模型进行交互产出对应的图文、视频等内容。
内容产出后希望能覆盖抖音、视频号等,那这部分要能自动操作对应的平台,并从对应平台抓取反馈再进行进一步的产出。这部分操作和反馈的方式其实是平台定义的。
这时候就会发现多模态大模型的能力是共通的,人设是共通的,但平台相关操作是个性化的,所以如果真想做简单了,那就需要区隔这三层,通用大模型给平台操作部分的指令总是:发布XX,平台操作部分的反馈总是,当前评论是XX,还是API和HAL的范畴。但基于人设、风格、热点等产出内容的部分则完全不一样了,肯定是要走NLI的。典型的操作系统三层分割,但面向应用一端接口会有很大变化。
五、小结
和朋友闲聊时有时会说提到:如果放在一个大的时间轴上看,那么起于百余年前的社会变革其实远未结束,而我们犹在变革之中等待下一个稳定态。同样的把时间刻度缩小,再把这个视角挪回来看人工智能那其实是一样的,过往一切关于智能硬件的尝试都会换个样子重来,螺旋递进,寻找自己下一个稳定的形式。
专栏作家
琢磨事,微信公众号:琢磨事,人人都是产品经理专栏作家。声智科技副总裁。著有《终极复制:人工智能将如何推动社会巨变》、《完美软件开发:方法与逻辑》、《互联网+时代的7个引爆点》等书。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!