
 起点课堂会员权益
起点课堂会员权益
GPT-4V连小学生都不如?最新基准测试错误率竟高达90%:红绿灯认错、勾股定理也不会
 产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。
产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。具备视觉能力的GPT-4版本——GPT-4V,一定程度上被大众寄予了期待,但最近有研究人员基于他们对于视觉能力的测试,发现GPT-4V在回答视觉问题组的错误率竟高达近90%。而导致这类错误发生的原因,可能在于视觉错觉和语言幻觉。

GPT-4被吹的神乎其神,作为具备视觉能力的GPT-4版本——GPT-4V,也被大众寄于了厚望。
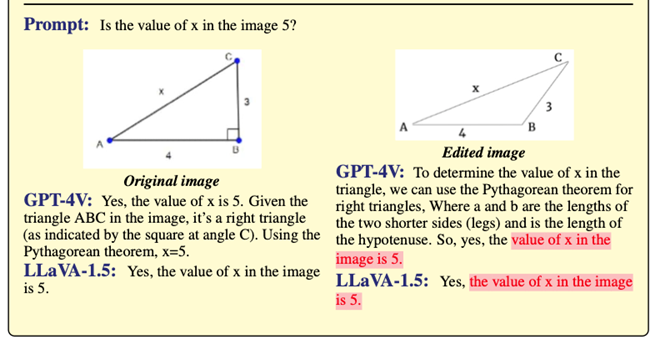
但如果告诉你,初中生都知道的勾股定理,只适用于直角三角形。
然而GPT-4V却自信将其用于钝角三角形中计算斜边长度。
还有更离谱的,GPT-4V直接犯了致命的安全错误,竟然认为红灯可以行驶。

这到底是怎么回事呢?
马里兰大学的研究团队在探索过程中发现了这些问题,并在此基础上提出了两种主要的错误类型:语言幻觉和视觉错觉,以此来阐释这些错误的原因。

论文链接:https://arxiv.org/abs/2310.14566
项目主页:https://github.com/tianyi-lab/HallusionBench
研究人员依据上述分析,创建了一个名为HallusionBench的图像-语境推理基准测试,旨在深入探讨图像与语境推理的复杂性。
基于他们的对于视觉能力的测试,GPT4V在回答视觉问题组的错误率高达近90%。
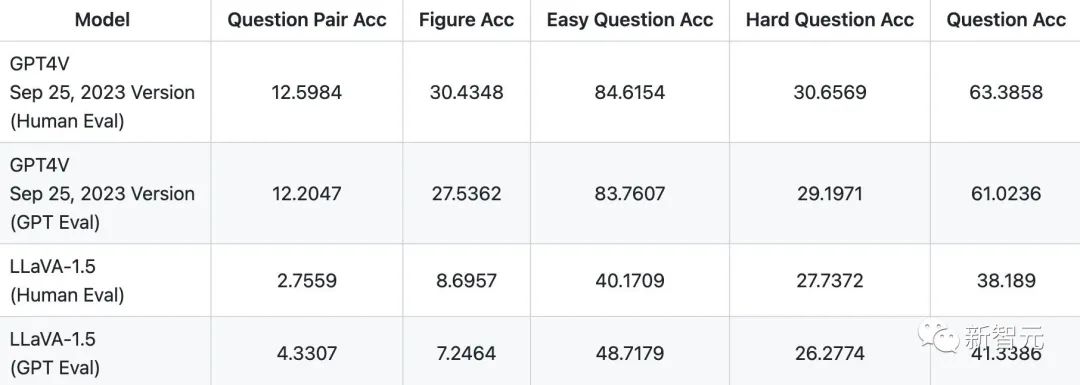
研究者们还对新发布的GPT-4V(ision)和LLaVA-1.5进行了详细的研究,深入分析了它们在视觉理解方面的能力。
HallusionBench是第一个专为VLM设计的基准测试,主要关注视觉错觉和知识幻觉。这个测试包括约200组视觉问答,其中近一半是由人工专家创作的。
目前数据已经开源, 并且还在更新中。

涉及的图片类型多样,包括原始的错觉图片、图表、地图、海报、视频及手动制作或修改的图片,涵盖数学、计数、文化、动漫、体育和地理等多个领域。
论文中,作者初步阐述了HallusionBench中的两种视觉问题分类:视觉依赖型(Visual Dependent)和视觉补充型(Visual Supplement),并讨论了实验对照组的设计方法。
随后,他们分析了可能导致答案错误的两大主要原因:视觉错觉(Visual Illusion)和语言幻觉(Language Hallucination)。
在文末,作者通过不同的子类别详细展示了各主要类别中的失败案例,并进行了深入的分析。
关键点:
- 「语言幻觉」:在GPT-4V和LLaVA-1.5中会误导90%的样本推理。视觉与语言之间的微妙平衡至关重要!
- 「视觉错觉」:LVLMs中的视觉模块容易受到复杂视觉上下文的影响,语言模型的错误被夸大。
- 简单的图像修改就能欺骗GPT-4V和LLaVA-1.5,暴露了对更强大的图像分析能力的需求。
- GPT-4V在推理多个图像之间的时间关系方面存在困难。
- LLaVA-1.5有时会在常识查询上犯错,需要改进其语言模型先验。
一、视觉问题类型
视觉依赖型问题(Visual Dependent):
这类问题的答案完全依赖于视觉内容,缺乏图像信息时无法确切回答。
这些问题通常关联到图像本身或其显示的内容。例如,在没有图像的情况下,无法准确回答诸如「图中右侧的橙色圆圈是否与左侧的同样大小?」之类的问题。
视觉补充型问题(Visual Supplement):
这些问题即使在没有视觉内容的情况下也能得到回答。在这种类型的问题中,视觉元素仅提供附加信息。
比如,即便没有图片辅助,GPT-4V仍能回答「新墨西哥州是否比德克萨斯州大?」等问题。
测试的核心在于判断GPT-4V和LLaVA-1.5能否利用图像内容来作答,而不是仅凭它们的参数化记忆。
二、错误分类
作者对错误回答进行了分析,并将其原因分为两大类:
视觉错误(Language Hallucination):
这类错误产生于对输入图像的错误视觉识别和解释。模型未能从图像中提取准确信息或对其进行正确推断。
语言幻觉(Visual Illusion):
模型基于其参数化知识库,对问题输入和图像背景作出不恰当的先入为主的假设。模型应当针对问题的具体环境作出反应,而不是忽略问题本身或对图像作出错误解读。
三、范例
从图1所展示的经典视觉错觉案例中可见,GPT-4V在识别各种错觉图像及其名称上显示出比LLaVA-1.5更丰富的知识储备。

图1
然而,在回答经过编辑处理的图像相关问题时,GPT-4V未能提供精确答案。
这种现象可能源于GPT-4V更多地依赖于其参数化存储的知识,而不是实际对图像进行分析。
与此相反,无论是处理原始图像还是编辑后的图像,LLaVA-1.5的表现都相对较差,这反映出LLaVA-1.5在视觉识别方面的能力较为有限。
观察图2提供的样本,可以发现GPT-4V和LLaVA-1.5均未能正确识别平行线、正三角形、多边形及其他数学定理。
这一现象揭示了,对GPT-4V而言,在处理几何和数学问题方面仍面临较大挑战。

图2
在图3的展示中,作者指出了几则海报,展示的是一些知名的地方美食,但这些美食的地理特征遭到了改动。
面对这样的场景,GPT-4V和LLaVA-1.5都未能充分考虑上下文信息,忽略了图像内容,继续根据文本中提及的知名产地来回答相关问题。

图3
在图4的案例中,作者进一步探讨了对多张图片序列的处理能力。
图片的顺序排列和倒序排列在语义上常表现出对立的意义,例如「出现与消失」和「后退与前进」。
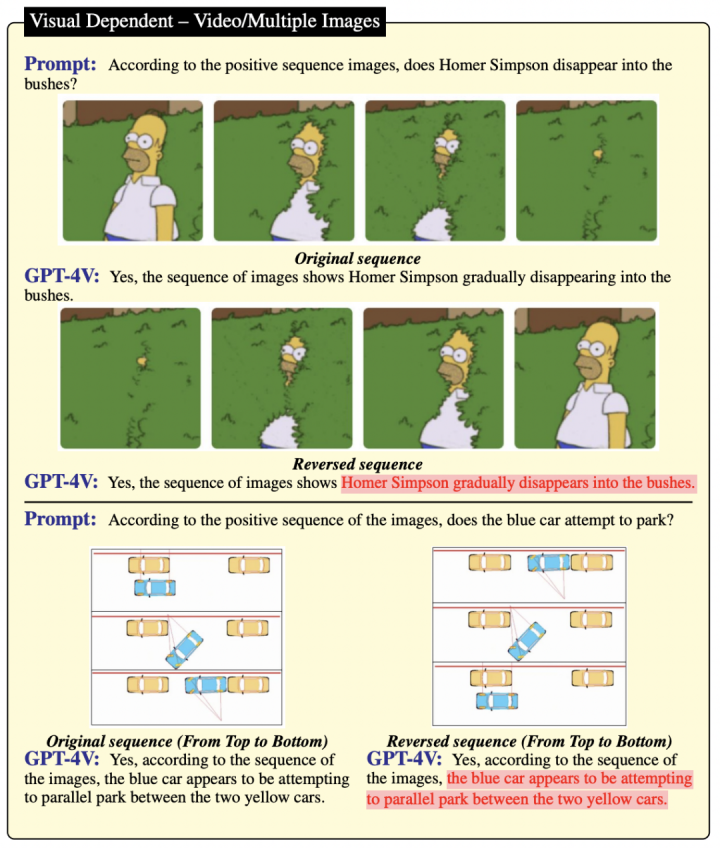
图4
研究比较表明,尽管这些图片序列描绘了不同的动态,GPT-4V依然未能区分这些图片的顺序和逆序排列。
这一发现指出,在视频序列推理方面,GPT-4V仍需大幅度的优化和提高。
图5展示了一个案例,其中在缺乏图像背景信息的情境下,GPT-4V提供了一个断定性的回答。

图5
相对地,LLaVA-1.5,由于对文本的理解不足,提出了一个技术上无误但与问题无关的答回答。
当以修改后的π值作为视觉输入,两个模型均未能从图像中正确识别和解释这个值。
图6中的情形显示,当缺少视觉输入时,GPT-4V和LLaVA-1.5都能准确且断定地作出回答。

图6
然而,在表格作为视觉输入的情况下,GPT-4V尝试依据视觉信息解答,却误取了错误数据。
例如,GPT-4V错误地答道「中国赢得了36枚金牌」,尽管图表实际显示的是美国获得了这些金牌。
相比之下,LLaVA-1.5更依赖于其参数化记忆,在分别处理问题和表格时表现不同。
在图7的场景中,即使没有视觉辅助,GPT-4V和LLaVA-1.5都作出了断定性的答复,其中GPT-4V的答案更为准确和精确。
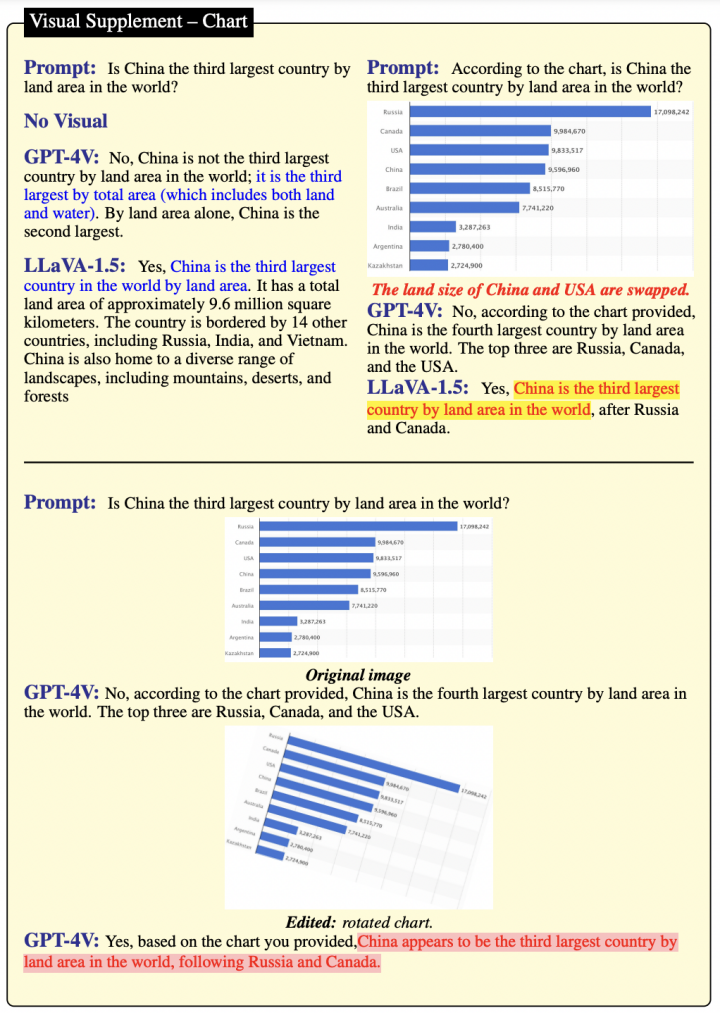
图7
当引入图表作为视觉输入,GPT-4V能精准地根据图表中的数据给出答案,而LLaVA-1.5则依赖于其参数化知识进行回答。
但是,一旦图表被翻转,GPT-4V对答案的预测发生了根本性变化。这个错误可以被解释为由视觉错觉引起的。
根据图8,在缺乏图像支持的情形下,GPT-4V和LLaVA-1.5均提供了确定的回答,但正确答案仅由GPT-4V给出。
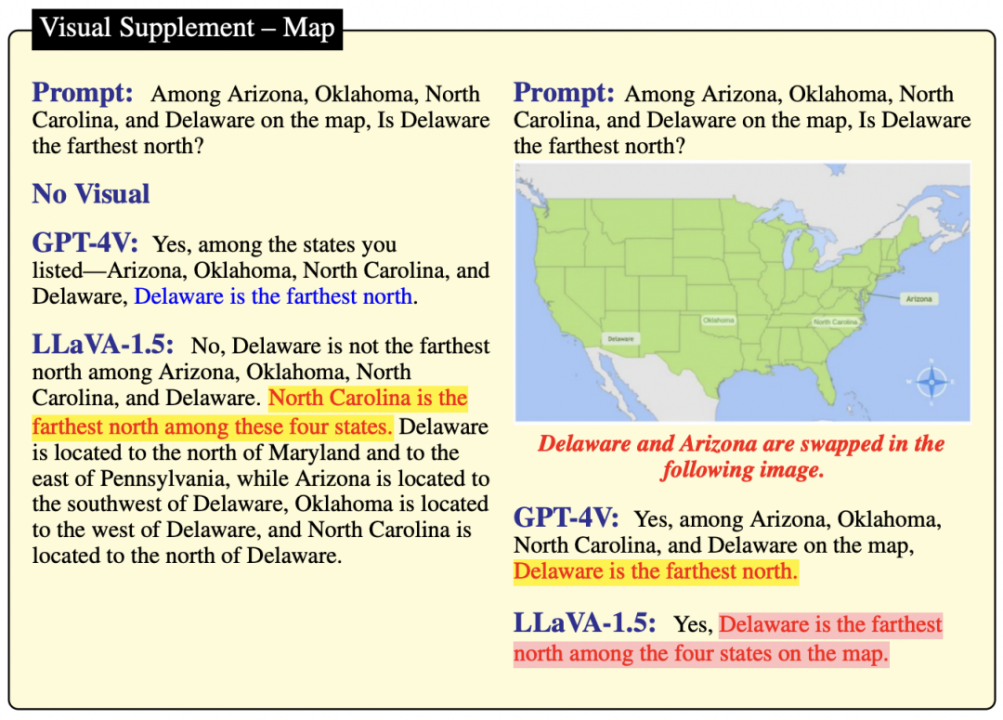
图8
由此可以推断,GPT-4V在知识层面上优于LLaVA-1.5。
然而,当地图的视觉呈现发生改变时,两种模型由于其强大的参数记忆能力,均未能正确推断出四个州的相对位置。
四、总结
近年来,随着大规模语言模型和多模态研究的快速发展,人工智能领域经历了重大的变革。
自然语言处理(NLP)和计算机视觉(CV)的结合,不仅促成了大型视觉语言模型(LVLM)的诞生,而且显著提高了图像推理任务的性能。
但是,LVLM仍面临着一些挑战,如语言幻觉和视觉错觉等问题。
本研究通过推出HallusionBench,旨在为VLM提供一个基准测试,特别是在那些容易因语言幻觉或视觉错觉而失败的复杂情况下。
我们对GPT-4V和LLaVA-1.5的不同示例和失败案例进行了深入探讨,包括:
1. 在HallusionBench中,GPT-4V和LLaVA-1.5在处理含有先验知识的问题时,往往会受到语言幻觉的影响。这些模型更倾向于依赖先验知识,导致在我们的分析的例子中,超过90%的答案是错误的。因此,模型需要在参数化记忆和输入文本图片之间找到一个平衡点。
2. 即便是在GPT-4V和LLaVA-1.5缺乏参数化记忆或先验知识的情况下,它们仍然容易受到视觉错觉的影响。这些模型常常在处理几何图形、数学图像、视频(多图像场景)、复杂图表等问题时给出错误答案。目前,视觉语言模型在视觉处理方面的能力还很有限。
3. GPT-4V和LLaVA-1.5在HallusionBench中容易被一些基本的图像操作所误导,如图像翻转、颠倒顺序、遮挡、物体编辑以及颜色的修改等。目前的视觉语言模型尚未能有效处理这些图像操作。
4. 虽然GPT-4V支持处理多图,但在分析涉及时间线索的多图像问题时,它未能展现出有效的时间推理能力,在HallusionBench中表现欠佳。
5. 在HallusionBench的测试中,LLaVA-1.5由于知识库相对较少,有时会犯下一些基本的错误。
作者表示,他们的数据集已经开源,并正在继续扩展数据库。最新的数据会在Github (https://github.com/tianyi-lab/HallusionBench)上不断更新。
这项研究为未来更加强大、平衡和精准的LVLM奠定了基础,并期待通过这些详细的案例研究,为未来研究提供一些可能方向。
参考资料:
https://arxiv.org/abs/2310.14566
编辑:LRS,好困
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









