
 起点课堂会员权益
起点课堂会员权益
估值20亿的kimi-Chat真香
 产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..
产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..估值20亿的kimi-Chat是什么,它的出现又会带来什么影响呢?大家一起接着往下看,下边笔者整理分享的关于kimi-Chat的相关内容,或许会收获更多内容哦!

我每天都写文章,并不稀奇。
然而,当涉及商业分析、数据处理相关问题时,不能马虎处理;这些情况下,必须深入调查。 搜集公开网络上的分析和财务报告,是一项艰巨的挑战。
为什么?
准确性至关重要。 如果信源不准,会直接导致分析结论偏差。想必前段时间某大V翻车的事件,给大家诸多启发。
避免信息过时。 今天的新闻,明天可能就过时了。所以,不停地搜索最新信息、数据,能确保分析、决策不会基于过时的情况发生。
真正了解市场。 光看数据还不够,市场比较复杂,得深入挖掘才能看到有哪些潜在风险,这也能找到隐藏的不同角度。
所以,我最头疼的一件事是 看报告、看财报、看数据。
怎么办?我打算让AI帮我处理,也遇到一些挑战。在国内,很难找到有效阅读PDF和其他文档格式的高效AI大模型。
于是,我转向ChatGPT-4。
用近四个月,最大问题是经常遇到长度限制,较大文档你得切两半才能上传,要么,上传文档后解析结果不尽人意,这些问题非常困扰,比直接阅读报告还头疼。
直到前段时间遇到Kimi-chat,极大减轻了我的分析负担,仿佛找到一个能理解复杂报告的助手。
一、Kimi-chat是什么呢?
如此卡哇伊的名字,这个答案隐藏在它的口号中: 别焦虑,Kimi帮你整理资料,文件,拖进来;网址,发出来。 一看就是一个有效整理、处理资料的工具;网址是: https://kimi.moonshot.cn。
打开网址,非常简洁,对话框呈现在眼前,人工智能小人告诉你,可以把网址、文件发给它,可以帮你看看,既然是这样,我们就一个一个测。
1. 读文件
根据Kimi-chat官方宣传,它最多支持20W字上下文输入,也就是说,我把一篇PDF小说、书籍塞进去都没问题。
我就试了一下,把自己2021年写的《复利思维》.PDF塞给它,完全没问题,这本书共计12万字。
然而,当我尝试输入《信息论40讲》时,系统提示我超过了对话长度的175%;而《被讨厌的勇气》这本书,则超出20%。
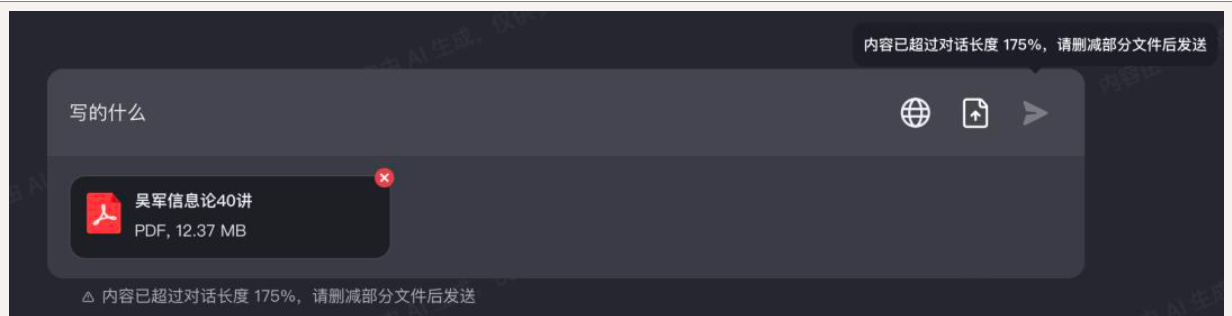
我轮番测试,把我第二本即将要出的书14万字world塞给它,它显示超出36%。 14万字的百分之36%大约是5万字; 换句话说,它支持一口气10万字以内的内容处理。
为绕过字符限制,我换了方法。
将一份10万字的文档分成两半,分别输入到Kimi-chat中,结果显示系统能够无障碍处理。但是,我注意到处理PDF文档有个要求:扫描件不行。
我还发了两篇大约3万字的文档给它,也没问题。
比较惊讶的是,它能够根据之前我发给它的信息来回答我的问题;也就是说, 不管我问什么,只要在这个对话框里说过,它都能记住,回答得更准确、更有条理。

这个功能对我来说特别有用,尤其是处理长篇大论的时候。
我还测试了表格总结能力,给它多个表格,让它把重点罗列出来。 它能清楚地按逻辑顺序归纳,还能基于提炼的内容,再做成表格,复制到Word、Markdown里都能用。
为了方便,我还让它帮我基于PDF、Word资料提出50个问题,并把问题做成表格。这也都没难倒它,真是挺强大的。
话说回来,即使是付费版的GPT-4,它处理上下文时的token数量上限也只是32K。
虽然根据我自己的测试,似乎只能处理大约10万字。不过,实际上10万字的处理能力,对于大多数情况来说,也已经足够了。
2. 读网页
我先试了Kimi Chat给的一个示例,就是总结一篇大概3.6万字的文章,并让它像个AI专家似得提出三个问题。 Kimi Chat给我找了一篇关于人工智能的文献,10几秒分析完,速度挺快。
我分别将虎嗅、36氪、百度、豆瓣等多个网站的链接发送给Kimi Chat。它不仅能够读取这些链接中的内容,还能够概括出各篇文章主旨,当我需要更深入的细节时,它也能提供。
比如:
我问它,某个文章第一段主要讲啥?核心观点是什么?
它能快速给我总结出来。这样我就不用自己费劲去翻找了,直接知道文章的要点。特别是我有一堆东西要看的时候,这个功能真的挺省事。
我对Kimi Chat进行了连贯性测试。
先把三篇讲差不多东西的文章的链接,扔到同一个聊天窗口里,一块儿发过去,然后问它一些问题。它回答得挺好的,一点儿都不乱。
后来我又换了个招,发三篇完全不同主题的文章,还来自不同网站,结果它照样能处理得挺顺利。

总之,在处理文件和网页内容方面, Kimi Chat的一个大优点是能上传多种类型、来自不同网站的内容。 它甚至可以将您的问题和答案整理成表格,方便查看和理解,分析能力很强。
但也有些局限。
比如,它不支持在一个对话框里同时上传网页和文件。 而且,尽管官方宣称它能一次性处理20万字,实际上我发现它并没有达到这个标准,也可能是我人工测试的不精准。
说实在,就读网页、读文档方面,这些功能足够使用了。
3. 文本搜索
文本搜索,对一个内容创作者,最重要的能力是什么? 答案是准确性、相关性。
举个例子:
最近各家都在频繁出Q3财报,财经类作者需要迅速获取这些财报的详细信息,来进行分析; 这种情况下,他们可能会用关键词,如“网易2023Q3财报”进行搜索。
搜索出来后,基于财报简要、主要财务指标、市场分析的评论、以及其他媒体的报道,然后结合自己的观点提出不同角度。
那么,大家常规怎么操作的呢?
基于某度、某乎、某氪、或者微信搜索进行搜索,这非常麻烦。我把这个问题,交给了Kimi Chat。
它直接给我事实搜索出,2023年11月16日网易发布的第三季财报内容,并且指出该季度增长如何、业绩如何;毛利多少、实现毛利润多少。
…..
为了更深入了解网易。我让它给出(资产负债表状况)公司的资产、负债和股东权益的状态如何?是否显示出财务健康和稳定性?
它迅速给我找出5篇资料。
但由于分析过程比较复杂,它没办法直接给出结论,最后,它建议我关注流动比率、负债占资产比率、净资产收益率。

我问它你能帮我找到吗?
它无法直接找到三个问题同样的内容,但为我提供了关于负债占资产比率的5篇文章。后来,我把5篇链接复制下来给它,让它分析,它也无法给出占资产比率。
也就是说,
第一,这个工具能提供实时搜索,但它的功能有限。
比如,如果您需要了解占资产比率,但这个信息没有直接提及在内容中,工具就不能自动计算、提供数据。它不能基于财报进行额外的计算。
第二,联网搜索和文档(链接)分析是分开的。
如果你已经向它发送任何链接、文档,那么,它就无法再帮您搜索网络上的内容,不过,要是开启一个新的对话,它就可以再次联网搜索;
其三,未联网下,它的知识库训练截止到2021年11月,和ChatGPT-4时间相似。
4. 找资料
文本搜索,就像在网上快速找东西,输入你想知道的关键词,然后它会给你一堆信息; 但找资料不一样,它更像你已经知道什么,然后去挖掘背后的故事。
这个观点谁提出的,什么时候提出。不是简单搜搜看,更像深入地去研究背后的信息。
举个例子:
我平时写认知心理学的内容比较多,所以经常得翻翻谁最先提出某个概念,或者找找相关的学术研究之类的。
于是,我针对“焦虑”一词,提出了几个问题,让它帮我找出来。结果挺让我吃惊的。
它给我抓取了百度知道、头条百科、以及学术方面的内容,并且对这些内容进行了详细的解释。

继续我的实验。
我对它引用的资料:[(1917)焦虑(《精神分析引论》第25讲)提出新的问题。我想知道里面提到焦虑分为几个部分,但它告诉我,对这个知识领域不够了解,无法给我想要的答案。
于是,我尝试了另一种方法。
我把它提供的链接复制下来,开启了一个新的对话框,并再次提问焦虑分为哪几个部分。这次它给了我答案,告诉我焦虑可以分为:
- 现实焦虑(Realangst)
- 神经性焦虑(Neurotischer Angst)
- 道德焦虑(与超我相关)
也就是说, 这个工具自己不能从它给你的链接里,再挖东西出来。 如果你想知道更多,得自己复制它给的那个链接,再发回去给它,这样它才能根据这个链接找出你要的详细信息,ChatGPT-4至今也无法做到。
最后,我又测试了一下它的自语言处理能力(NLP)。
什么是自语言?
简单来说,个人在不太正式的情况下,用最自然、最习惯的方式表达的语言,这包括用方言、非常口语化的方式表达出来的想法。
它实际反应一个人的思考模式和内心状态。
比如:
一个人面对困难时,可能会对自己说,加油,你能行;这种语言往往非常直接、真实,并且表达用词非常个人化,有口头禅、自创词汇。
这种在没有旁听者的情况下,用来鼓励自己的言行,就是一种自语言。
日常我和客户访谈居多。最近,尝试了一个新方法:
将我和一位高管的访谈对话转录成文字,然后交给了Kimi-chat,看看它能否理解这些内容,并生成一个剔除那些非正式或口语化表达(俗称“口水话”)的文本。
结果,它的能力还是令我挺吃惊地。 我能完全理解采访的实质内容,还能生成更加有逻辑、清晰的形式,这对于整理采访记录、提炼重点信息来说,非常有帮助。
综合来看,我总结了它的4个优点:
- 快速享应
- 高可用性
- 不漏信息
- 学习长文本
它用来起挺方便的,不需要代理。而且给它一大堆文字也不用怕丢失,回答快,准确性高,就算你丢给它一个超大文件,也能把里面所有信息炒出来,一个不漏。
讲真,国产大模型我也测试了很多,目前能做到这个地步,还算不容易;当然,评价一款软件,首先看它好不好用,长期坚持使用一款软件,我更关心它会不会跑路。
二、该公司背景
该公司创始人叫,杨植麟。他是一位90后的AI天才,曾是清华大学的学生,师从IEEE Fellow唐杰。
本科毕业后,他就去了自语言处理(NLP)研究全球排名第一的卡耐基基梅隆大学攻读博士学位。攻读期间发表关于Transformer-XL和XLNet的两篇论文,主要给AI大模型技术提供了突破性基础。
后来自己创立名叫“月之暗面”(MoonShot AI)公司,发布一款千亿参数的大模型moonshot,用来承载Kimi Chat,至今估值20亿美金。
这个公司有两位联合创始人,分别为周昕宇、吴育昕,他们在大模型的工程、算法开发方面都有丰富的经验。目前公司的团队规模超过50人,成员多来自于谷歌、Meta、亚马逊等全球科技巨头,是一个国际化的团队。
我比较好奇,为什么叫月之暗面?
于是,我就去找了找原因。这个名字来源于创始人个人喜欢的一张专辑Pink Floyd的《Dark Side of the Moon》。
意思是,月球的暗面始终背对地球,处在地球人的视线外,象征神秘与未知。
公司想在人工智能领域探索这种未知,就像月球暗面一样,充满神秘和挑战;因此,他将公司民命为月之暗面。
这个软件为什么内容比较精准、且处理长文本呢?杨植麟认为市场的大模型有三种:
- 金鱼型
- 蜜蜂型
- 蝌蚪型
金鱼比较健忘,就像滑动手机窗口一样,模型会基于窗口,自动把之前的内容扔掉,只关注最新输入的东西,所以它没法完全懂整篇文章的意思,处理不了跨好几篇文档的对比。
好比,我有10万字访谈记录,它就不一定能从里面找出来最重要的10个观点、问题是什么。
蜜蜂型处理方式,像蜜蜂采花那样,只关注一小块,不管整体。它会在给的文本里搜寻、增强信息,但只专注于其中一部分。
就好比,假设你给它10份简历,它能帮你找出每份简历的重点,但就做不到更深入地挖掘每个细节。
蝌蚪型,就像是个还没长大的小蝌蚪,能力还没完全长成。为了让它处理更长的文字,就得减少一些参数,比如只用百亿个。
这就像是,想让一个人走更远的路,就让他的背包轻一些,因为书少了,做的事情也就少了。
因此,杨植麟认为,对于‘月之暗面’这个项目来说,成功的第一步是解决‘长文本’处理的挑战。
例如,要通过分析多篇财务报告、处理多份法律合同、或者汇总多篇文章,才能有效地找到关键信息。这种能力对于深入理解、处理大量复杂数据至关重要。
话说回来,长文本能力的提升,不仅让AI工具在日常工作流中更好用,还能更好地辅助人类进行跨领域、跨学科主题发散思考。这难道不是好事吗?
嗯,至少从我的角度来说,挺好的,你可以试试。
三、总结
AI的记忆力,越来越好了。
估值20亿的kimi-Chat真香,这家年轻的公司已经展现出巨大潜在价值, 它能否像open-AI一样,成为国内的巨头,就看如何把握机遇,应对挑战了。
专栏作家
王智远,公众号:王智远,人人都是产品经理专栏作家。畅销书《复利思维》作者,互联网学者,左手科技互联网,右手个体认知成长。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

















昨天刚用了,很不错