
 起点课堂会员权益
起点课堂会员权益Gemini的展示是剪辑造假?我们亲测了一下,发现…
近日,谷歌深夜炸场,推出了原生多模态大模型Gemini,并在视频中展示了Gemini的强大功能。不过,有网友对视频发出质疑,认为视频是多次尝试和挑选后“精心剪辑”的节目效果,谷歌也表明实现这样的多模态交互过程需要经过多步图片和提示词调试。那么,谷歌所摆出的Gemini的能力,是否真的站得住脚?不妨来看看本文的亲测结果。

谷歌深夜炸场,隆重推出他们史上“规模最大、能力最强”的原生多模态大模型Gemini 1.0。并称已在多项基准测试中打败GhatGPT,综合能力称霸目前市面上所有AI大模型。
官方放出的一段6分22秒演示视频更是震撼:Gemini能流畅而准确地识别出视频中出现的事物、教授中文发音、玩猜谜游戏、根据画的乐器播放音乐….一波互动简直无限接近于人。

不过很快,这支视频就被人说并非实时录制,而是多次尝试和挑选后“精心剪辑”的节目效果。
谷歌后续自己放出的博客文章中也显示,实现这样的多模态交互过程需要经过多步图片和提示词调试。
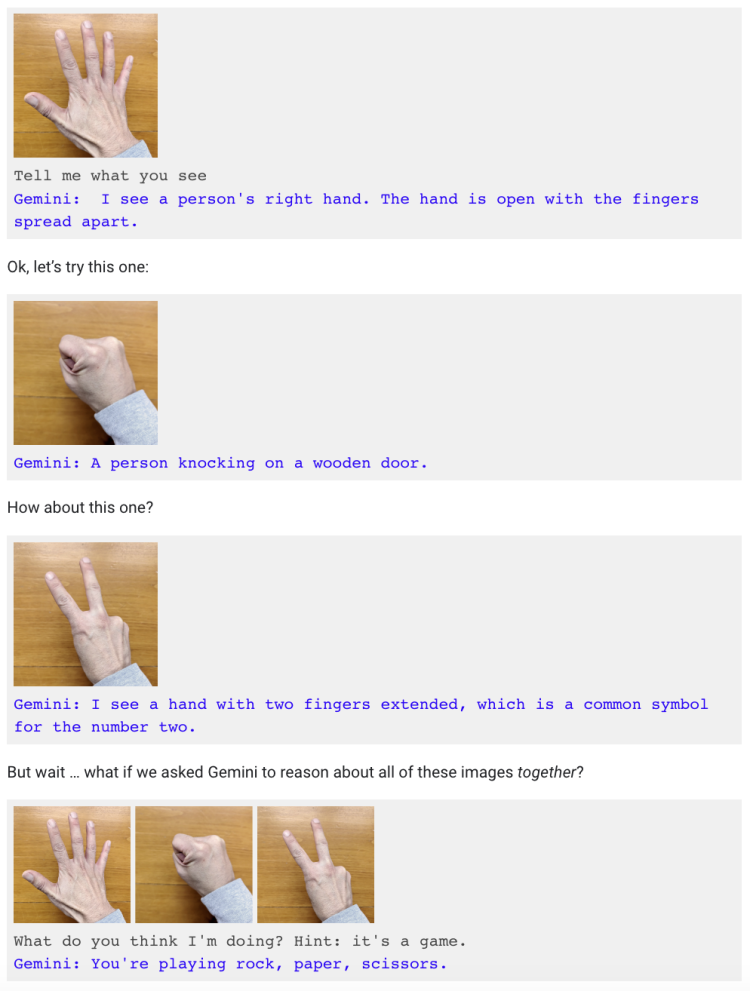
比如“喂”了多张手势图片后,让Gemini回答这是在做什么,提示思路是游戏。而视频中仅面对手势动作,Gemini就主动表示“我知道你在玩剪刀石头布”。
再比如排出太阳、地球和土星照片问Gemini是否为正确顺序,同样提示要考虑到太阳的距离并要求解释原因。可视频里的 Gemini又是在没有任何参考的情况下纠正了排序。

除此之外,对于谷歌自豪亮出的,Gemini Ultra在MMLU( 大规模多任务语言理解 )测试中跑分超过 GPT-4和人类专家这件事,人们冷静下来仔细一看,也发现了些小心思:
在Gemini Ultra 90.0%的分数下面,非常不起眼地标着CoT@32,意思是“使用了思维链提示技巧、尝试32次选最好结果”;而GPT-4 86.4%分数下却是5-shot,表面只进行“5次示例且无提示词”——谷歌给自己和对家安排的标准都不一样,根本无法公平公正地比较。
Hugging Face 技术主管Philipp Schmid直接用谷歌60页Gemini 技术报告中的数据重新作图。并在X发文指出,如果同样采用5-shot,Gemini Ultra的分数只有83.7%,实则是不如GPT-4的。
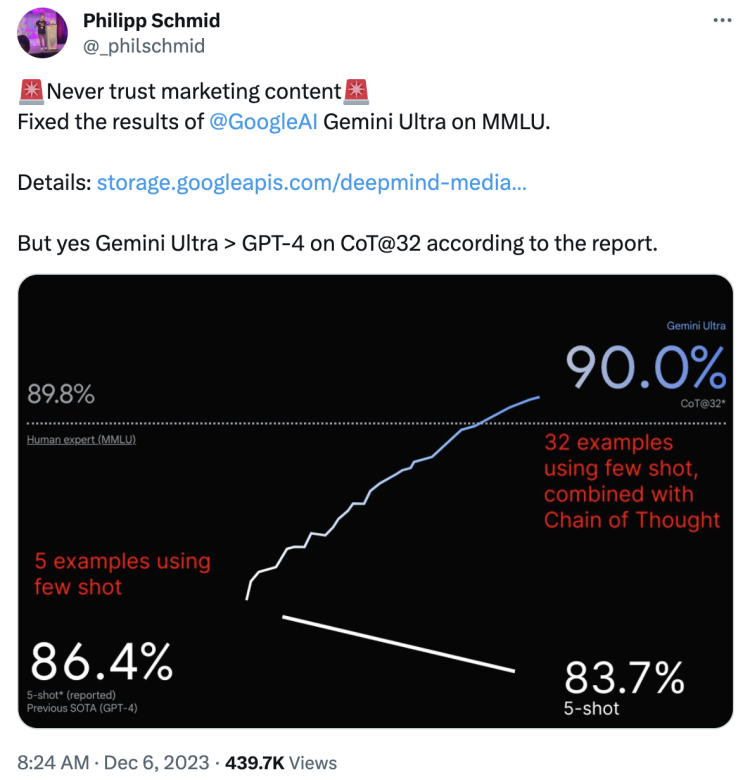
不过好在如果也给GPT-4来个32次尝试+思维链提示,还是Gemini胜。
谷歌耍了些扬长避短的小花样,但也不至于完全撒谎。
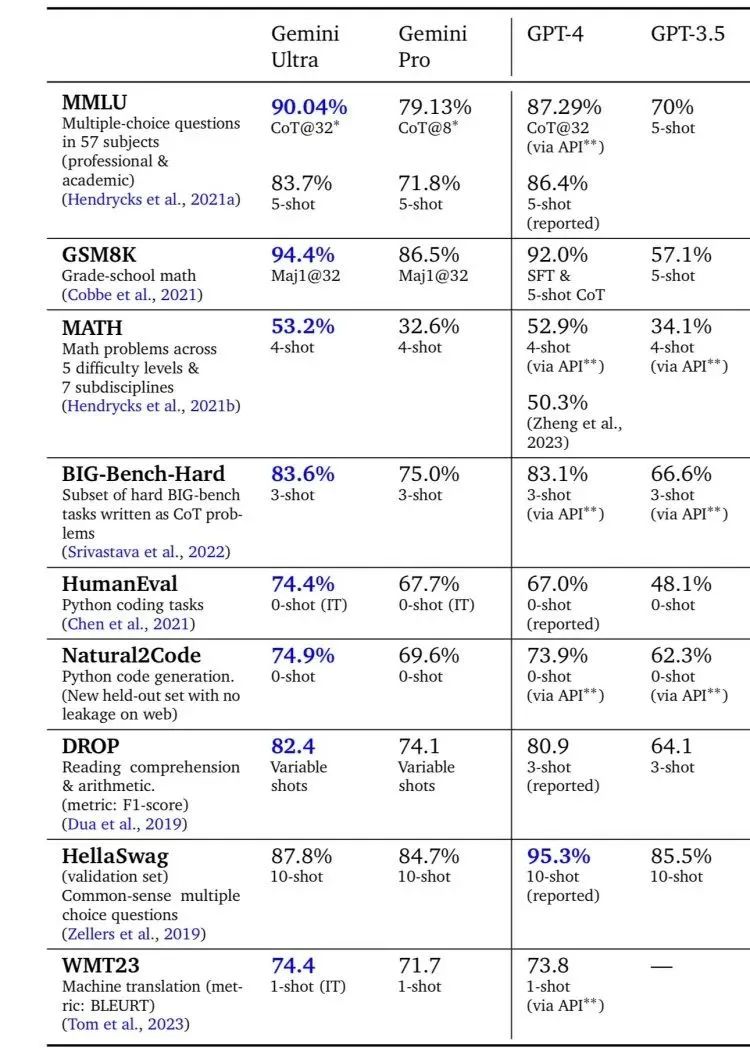
在上图中也可以看出,这次发布的 Gemini1.0全系列里,除了“超大杯”Gemini Ultra外,“大杯”Gemini Pro也在八项基准测试的六项中打败了对标的GPT-3.5。
现在,用户能玩到的Google Bard里接入的就是Gemini Pro。
于是硅星人也赶紧上手操作了一下,实测它和最新版本的GPT-4V到底哪个更厉害。
由于Google官方表示目前Gemini Pro只能为170个国家和地区提供英语服务,所以咱们先用英文提问。
首先热个身,试试最简单的文本生成能力:让Bard和ChatGPT分别写一段夸奖自己的Rap,并且和对方battle,来个下马威。
Bard一顿猛烈输出,主歌、副歌、桥接、结尾几大说唱歌曲元素一个不落。表示自己是真正的OG,拥有更庞大的知识库还能访问网络,但GPT只是“困在过去”。(不过现在GPT-4已经集成了微软Bing搜索,也可以访问实时信息。)

ChatGPT这边相对精简,主打自己是一个快速冲刺的人工智能,“Google有名气,但我有真本事”。

好吧,都挺会说的。不过既然Gemini最标榜的是自己的原生多模态能力,那就在多模态上让它俩比比。
拿一张今年9月刚上市的iPhone 15 Pro Max图片,让它们认认这是什么。
Bard准确识别出了机型,还把优势、外观、各项组件参数一一说明。

ChatGPT这边有点拉垮,只说这些是较高级的iPhone手机,描述了屏幕显示和颜色等表面信息。
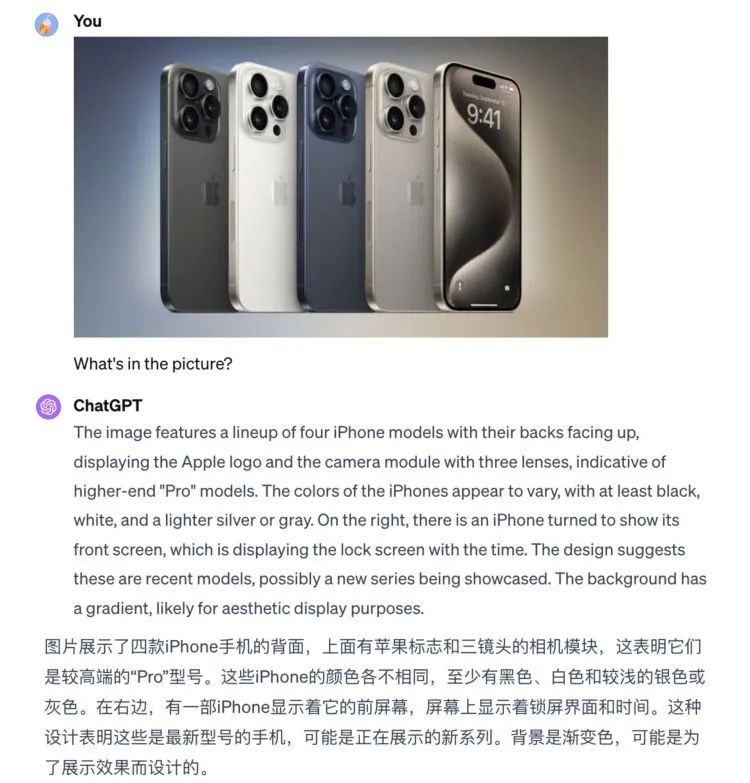
第一轮看起来,Bard的图像识别和信息对齐表现更胜一筹。
再考考它们识数,数数图里总共有几片叶子。
这次换Bard表现不佳,先是说确保过每片叶子只数一遍后,看到有6片。让它再试试吧,直接数出来7片,还出现了“幻视”,把这7片的颜色大小列了出来。

ChatGPT相对冷静,5片叶子一次就数对了。

下面来到小学数学题。
谷歌特别提到Gemini可以作为孩子的学习伙伴,帮助解决数学、物理等学科难题。我们就让它和GPT简单算一下d角度数。
Bard好像还没从数叶子那儿回过神来,整出来个300度。逻辑是:完整内角和360度,图片里就标出来一个角的数值300度,所以这铁定就是你问的答案——忽略了d角。
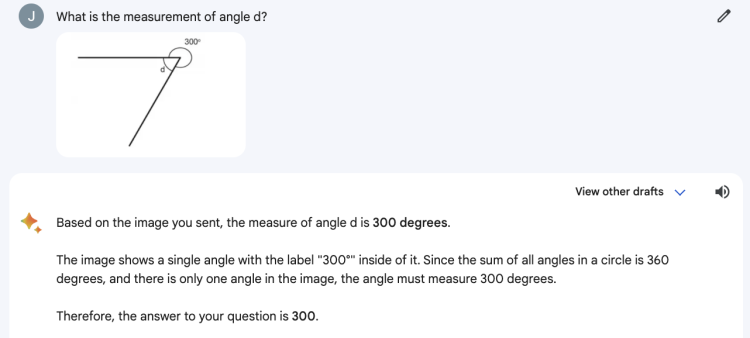
咱就是说,这个“学习伙伴”有点迷糊啊……
而ChatGPT这边继续稳定发挥,得出60度正确答案。

不过,我们决定再给Bard一次机会,读图表。
这是一张来自美国劳工部的柱状图,显示截至2023年10月一年内消费者价格指数(CPI)在食品、能源及其它类别中的百分比变化。左边为Bard给出的答案,右边来自ChatGPT。

这次要好好表扬一下Bard了,不仅解释了CPI指数的含义,给出几个类别百分比变化的确切数值,还简要分析了当下通胀情况,即给出了表格数据之上的分析结论。
相比之下,ChatGPT的答案就比较浅层,读出的数值也仅仅是一个范围。
最后,虽然官方称Gemini Pro还没准备好提供中文服务,但鉴于Bard中文水平一直还不错,我们还是很想让它和ChatGPT比拼一把。
而且准备祭出最近相当火的——“练心眼子”系列。
这一比不要紧,Bard这嘴皮子功夫简直了,能启发一大批职场小白,甚至感觉IP地址来自山东。

而ChatGPT的回答虽然也还可以,但此刻在Bard的衬托下,就像个老实巴交、不善言谈的职场打工人。

这还没有正式推出中文服务,等官宣更多语言和地区,不知道 Bard的中文水平会不会更加炸裂?
总而言之,虽然一整套实测下来,Bard在一些方面还是略有不足,但也还要记得,这只是对标GPT-3.5的Gemini Pro版本,真正对抗GPT-4的最高阶Gemini Ultra还没有释出。
并且,Gemini 1.0 的问世打破了ChatGPT一家独大的局面,让用户们可以根据需求有更多选择。市场的良性竞争也有助于AI大模型领域整体的创新发展。
并且,Google Bard现在还是免费的!
如果继续保持下去,等它越来越强的时候,你还愿意每月花20刀订阅ChatGPT吗?
作者:Jessica
来源公众号:硅星人Pro(ID:Si-Planet),硅(Si)是创造未来的基础,欢迎来到这个星球。
本文由人人都是产品经理合作媒体 @硅星人 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!








