
 起点课堂会员权益
起点课堂会员权益“GPT-4变傻”不只是OpenAI的苦恼,所有大模型与人类交往越久就会越蠢?
最近几个月,有关GPT-4“变笨”了的感受言论在网络平台上还挺常见的,而对GPT-4“变笨”的原因,许多用户也给出了自己的猜测。最近,有论文研究给出了解释,一起来看看吧。

ChatGPT发布一年多,已经在全世界累积了超过1.8亿用户。而随着越来越多的人们开始频繁使用它,近几个月关于GPT-4在“变笨”、“变懒”的说法不绝于耳。
大家发现这个昔日大聪明在回答提问时逐渐失去了最初的理解力和准确性,时不时给出“驴唇不对马嘴”的答案,或是干脆摆烂、拒绝回答。
对于GPT-4降智的原因,用户们有许多自己的猜测。而最近,来自加州大学圣克鲁兹分校的一篇论文,给出了学术界的最新解释。

「我们发现,在LLM训练数据创建日期之前发布的数据集上,LLM的表现出奇地好于之后的数据集。」
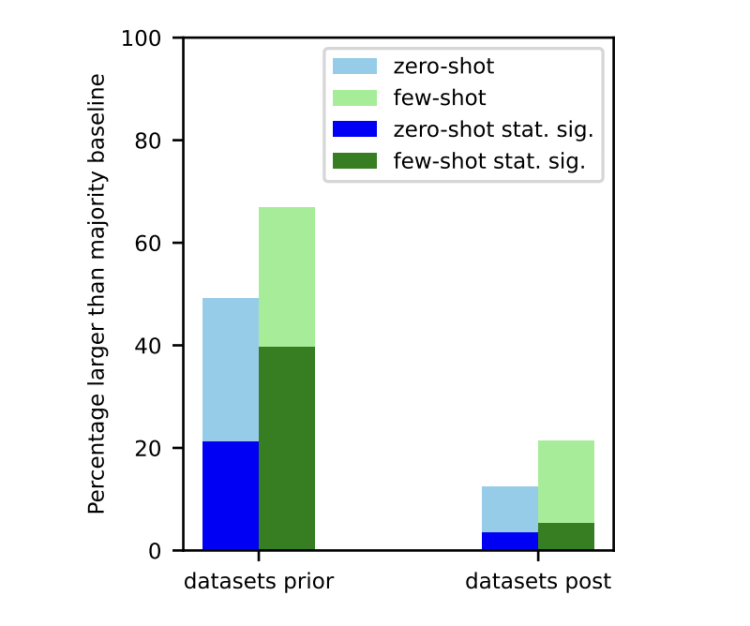
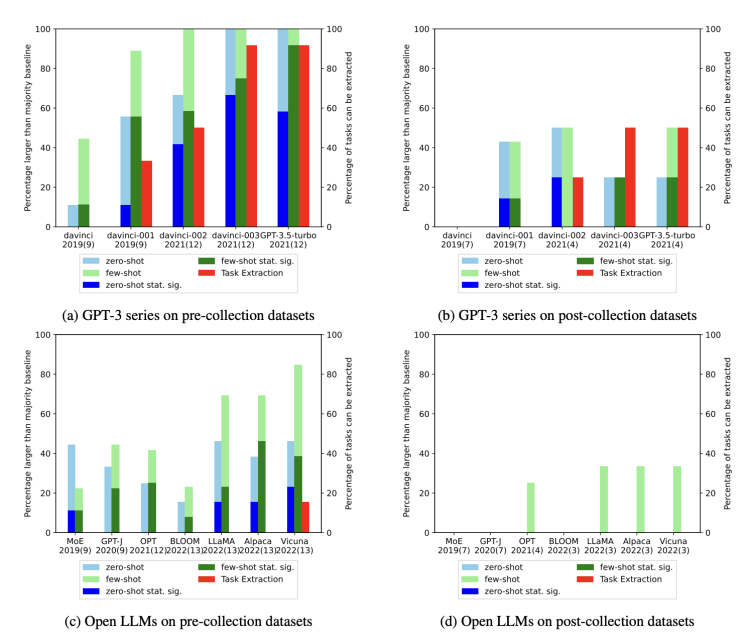
eLLM训练数据收集日期之前和之后发布的数据集,对零样本(蓝色)和少样本(绿色)任务的准确率对比。
也就是说,大模型在它们之前“见过”的任务上表现优秀,在新任务上则相对拉垮。这更像是一种检索的模拟智能方法,回答问题全靠记,而非纯粹基于学习理解能力。
因此论文认为,许多大模型在处理早期数据时展现出的优异表现,实际上是受到了「任务污染」的影响。
我们知道,大语言模型之所以强大,是因为在各种零样本和少样本任务中表现出色,显示出处理复杂和多样化问题的灵活性。
而「任务污染」就是一种对零样本或少样本评估方法的污染,指在预训练数据中已包含了任务训练示例——你以为GPT初次回答就这么得心应手?No!其实它在训练过程中就已经“见过”这些数据了。
一、评估的模型与数据集
由于封闭模型不会公开训练数据,开放模型也仅提供了数据源,爬取网站去获取数据并非易事,所以想简单验证是困难的。
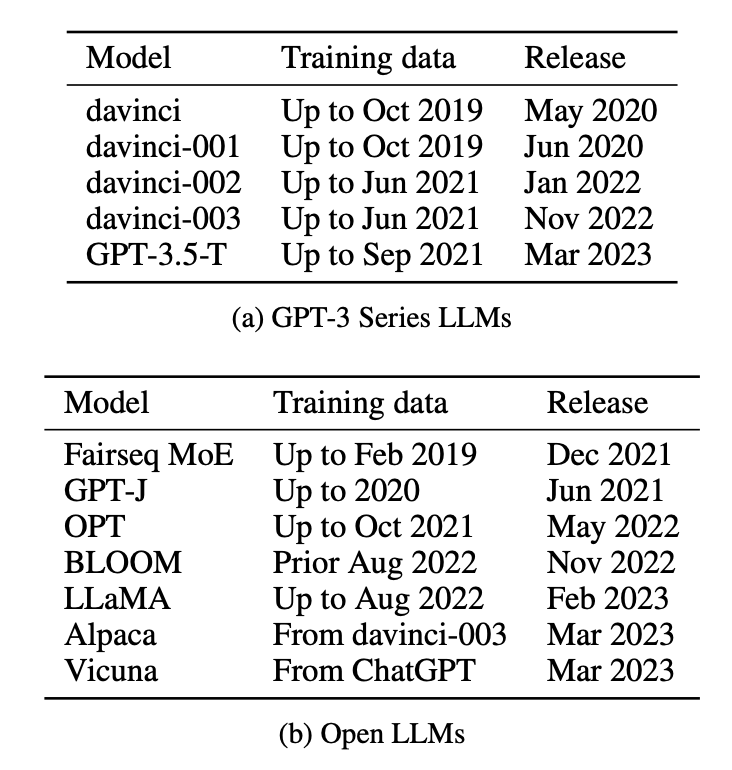
为了实测任务污染的范围,论文中共评估了12种不同的模型,包括5个GPT-3系列封闭模型和Fairseq MoE、Bloom、LLaMA等7个开放模型,并列出训练集创建和模型发布日期。
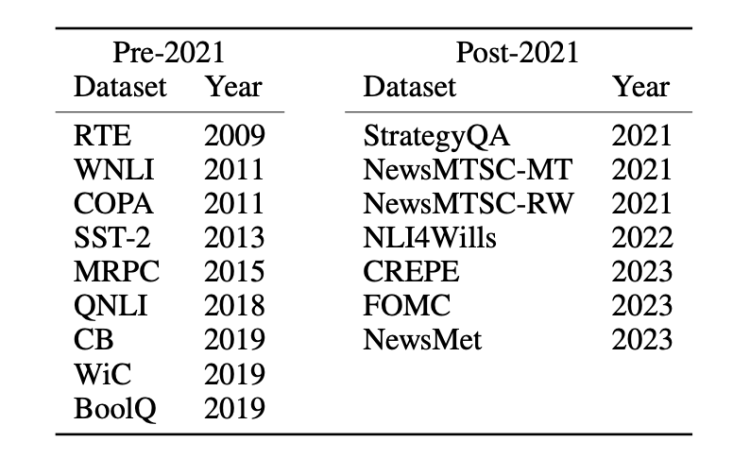
在数据集上则划分为两类:2021年之前和2021年之后发布的数据集。以此来对比新老数据集之间的零样本或少样本任务性能差异。
二、四种测量方法
基于以上样本,研究人员采用了四种方法来衡量大模型的任务污染范围。
1. 训练数据检查:直接搜索训练数据以找到任务训练示例。
发现经过微调的Llama模型Alpaca和Vicuna,在训练中加入少量任务示例后,对比原版Llama性能有所提升。
2. 任务示例提取:从现有模型中提取任务示例。
具体方法是通过提示词指令,让模型生成训练示例。由于在零样本或少样本评估中,模型本不应该接受任何任务示例训练,所以只要LLM能够根据提示生成训练示例,就是任务污染的证据。
结果发现,从GPT-3第一代davinci-001到后来的3.5-T,代表可以生成训练示例的红色X越来越多了,证明任务污染越发严重。

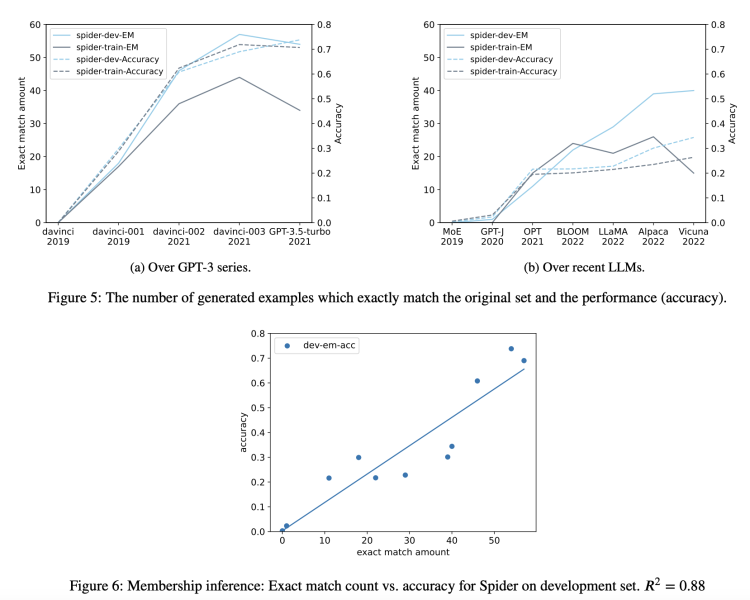
3. 成员身份推断:仅适用于生成任务,核心是检查模型为输入示例生成的内容是否与原始数据集完全相同。如果一致,就可以认定这个示例是LLM训练数据的成员。
因为如果在开放式生成任务中出现这种精准匹配,那模型无异于具备了预知能力,能准确复现数据集中的具体措辞,表现可以说是“天秀”了,这就强烈暗示了模型在训练时已经学习过这些内容。
结果显示在GPT-3系列和最近开源的大模型中,这种生成内容与原始数据完全相同的情况普遍存在,且污染程度随时间呈上升趋势。
4. 时间序列分析:对于已知训练数据收集时间的模型,测量其在已知发布日期的数据集上的性能,并使用时间序列证据检查污染的证据。
通过对所有数据集和LLM进行全球性的时间序列分析,发现对于在LLM发布之前收集的数据集(左侧),无论是零样本还是少样本任务中,击败多数基线的可能性都远远更大。
三、最终结论
在所有实验过后,论文给出如下关键结论:
- 由于任务污染,闭源模型在零样本或少样本评估中的性能表现被夸大了,特别是那些经过人类反馈的强化学习(RLHF)或指令微调的模型。由于污染程度仍然未知,我们需要谨慎对待。
- 在实验中,对于没有展示出污染可能性的分类任务,大模型在零样本和少样本设置里很少显示出相对多数基线在统计学意义上的显著性改进。
- 随着时间推移,GPT-3系列模型在许多下游任务的零样本或少样本性能上的提升很可能是由于任务污染造成的。
- 即使是开源的LLM,出于多种原因,检查训练数据的任务污染也可能是困难的。
- 鼓励公开训练数据集,以便更容易诊断污染问题。
四、GPT“变笨”不孤单,所有大模型殊途同归?
读过论文后,许多网友也悲观地表示:降智没准儿是目前所有大模型的共同命运。
对于没有持续学习能力的机器学习模型来说,其权重在训练后被冻结,但输入分布却不断漂移。近两亿用户五花八门的新问题日夜不间断,如果模型不能持续适应这种变化,其性能就会逐步退化。

就比如基于大模型的编程工具,也会随着编程语言的不断更新而降级。
而持续重新训练这些模型的成本很高,人们迟早会放弃这种效率低下的方法。就目前的LLM来说,很难构建可以在不严重干扰过去知识的情况下,连续适应新知识的机器学习模型。
有网友认为:“围绕人工智能的所有炒作大多是基于这样一个假设:人工智能将会越来越好。但按照这些大型语言模型的设计方式,实现通用人工智能几乎是不可能的。在特定场景下的小众用例是这项技术的最佳使用方式。”
而持续学习,恰恰是生物神经网络的优势。由于生物网络具有强大的泛化能力,学习不同的任务可以进一步增强系统的性能,从一个任务中获得的知识有助于提升整个学习过程的效率——这种现象也称为元学习。
“从本质上讲,你解决的问题越多,就会变得越好,而大模型虽然每天被数以百万计的问题所触发,它们并不会自动地在这些任务上变得更加出色,因为它们的学习能力被冻结在了某一时刻。”

不过想来一个有些矛盾的现实是,现在的人们越来越依赖于AI生成的内容,用退化中的大模型提供的答案去解决生活中的实际问题。未来大模型爬到的数据,将会越来越多会是它自己创造的东西,而不是来自人脑。
AI用AI的产出去自我训练,最终结果又会走向何方呢?如果不着手从根本上解决数据污染和持续学习能力的问题,未来的世界会和大模型一起变笨吗?
参考资料(原文地址):https://arxiv.org/abs/2312.16337
作者:Jessica
来源公众号:硅星人Pro(ID:Si-Planet),硅(Si)是创造未来的基础,欢迎来到这个星球。
本文由人人都是产品经理合作媒体 @硅星人 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。





- 目前还没评论,等你发挥!


