
 起点课堂会员权益
起点课堂会员权益人工智能之金融量化分析实战
金融是一个相对复杂的体系,而人工智能金融量化分析,更是一个复杂的系统工程。怎么解读这项工程呢?这篇文章里,作者尝试总结了金融资产进行量化分析的一套方法,以真实数据作为实战的基础数据进行模型搭建,一起来看。

金融是一个非常复杂的体系,客观反映了社会运行的状况,金融市场的数据指标也是社会经济的晴雨表。对于金融的量化分析,可以从微观和宏观两个方面进行。微观注重个体,宏观代表趋势。
本文主要是通过对金融领域中某种资产数据指标进行汇总,从宏观上探究其规律,从而实现计算机对资产价格进行智能预测。
既然是实战,本文采用资本二级市场公开的真实数据作为实战的基础数据进行模型搭建。对于实战结果,仅作为分析参考,并不构成投资建议。
对于AI(ArtificialIntelligence,人工智能)领域而言,是个非常庞大且复杂的系统工程,涉及非常多的基础知识,人工智能离不开数据标注,也离不开特征工程,依赖于机器学习,又依赖于深度学习,同时又涉及非常多的人工智能工具和机器学习的框架。
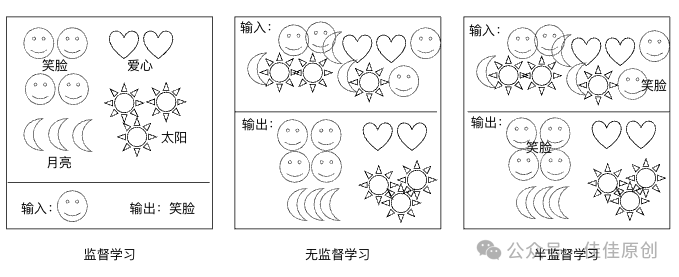
我们知道,机器学习最常见最基础的的分类是监督学习(SupervisedLearning)、无监督学习(UnsupervisedLearning)和半监督学习(Semi-SupervisedLearning)。
- 监督学习:在给定的数据标签中给新数据打标。
- 无监督学习:给定数据类别未知,通过机器自动分类,进行标注。
- 半监督学习:有些数据有标签,有些数据无标签,机器进行分类。
实现人工智能的前提,在于能将场景数字化,从而可以进行量化分析,并智能执行某些策略。可以简单理解为给定若干输出,让计算机给出输出,以数学的视角进行观测,其实是在事物与机器之间建立一个函数关系。
我们看到一个小孩,预测这个小孩将来能长多高,通过经验判断,往往是看小孩子的父母身是多少。父母的身高,其实就是一个输入的指标,对小孩身高的预测,就是输出的结果。
为了提高预测的准确性,我们可以增加多个输入的指标,例如:小孩的营养状况,体育锻炼情况,小孩家族其他长辈们的身高等指标。
人工智能对于金融的量化分析,我们也可以采用这种思路,将金融资产的各项指标进行定义,通过对现有数据多维度的指标作为输入条件,现有数据多维度指标对应的输出结果进行机器学习,建立数据模型,然后将新的金融多维数据作为参数输入,由人工智能引擎结合数据模型给出相应的结果输出。
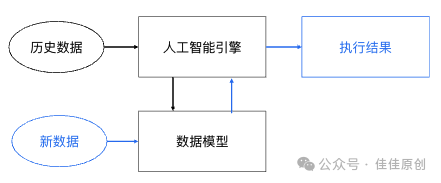
金融量化模型构建基础逻辑,就是选取相近的金融资产,根据这些相近的金融资产各项基础数据为机器学习样本,最后通过输入一个新的金融资产,来通过其各项指标预测输入金融资产具备的价值。主要过程如下。
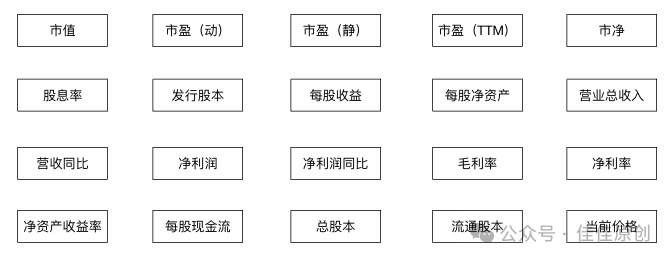
1)建立指标。我们首先建立对金融资产进行量化分析的指标,本文中,我们可以建立的指标主要如下。当然实际分析中,我们也可以选择其他维度的指标进行补充。通过对机器学习结果的评价,以及模型的不断调整,从而选取更优秀的指标,从而提升机器学习的质量。
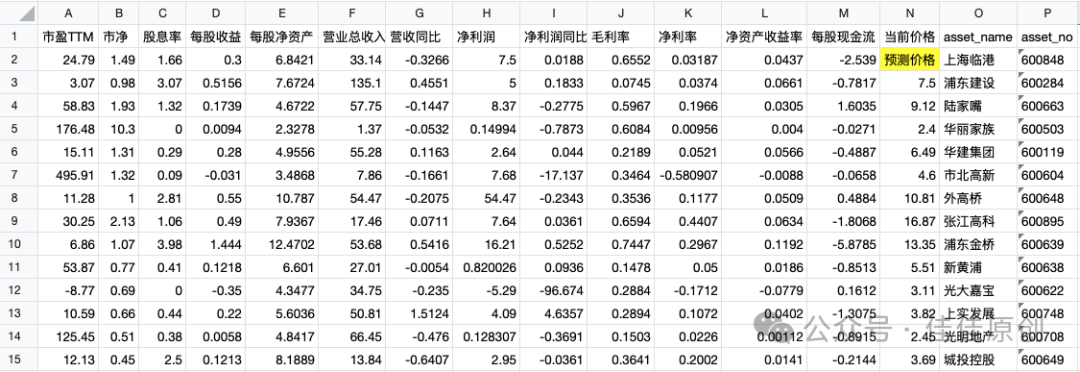
2)数据准备。有了以上指标,我们对相似的资产进行数据准备。考虑到篇幅限制,为了在一个页面中显示的数据清晰些,指标我们做一些精减,精减后的数据样例如下。机器学习的基础数据是第2行之后的数据,之后我们通过输入第2行的参数,来预测【上海临港】的资产价格。
在选取机器学习数据时,我们尽可能的选择量化分析同类型的资产数据,例如本文的实战中想预测【上海临港】资产的价格,我们要找同【上海临港】相近的资产标的。【上海临港】属于房地产业,而且又属于国资改革、园区开发、创投等概念题材。
我们可以根据策略,获取彼此相近的全量数据,之后我们再对全是数据进行优选,这个评价的过程,类似于比赛中的评委评分,去掉一个最高分,去掉一个最低分,例如,我们选取的数据中,市盈率和其他数据的市盈率偏差非常大的,我们也可以舍去。当然实际过程还有很多影响因子,需要具体情况具体分析。
3)工具准备。本次机器学习使用的工具是Spyder,通过Python语言实现。Python相关环境的搭建比较基础,在这里不做太多讲解,大家直接下载一个ANACONDA开发工具即可。
当然,大家如果习惯使用其他机器学习的工具,也可以采用其他的,只要方便的就可以,基础原理其实都是一样的。
4)数据整理。我们开始以准备好的数据文件为样例读入,并进行数据整理,为后续机器学习做准备。
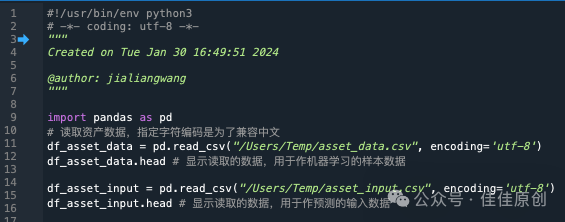
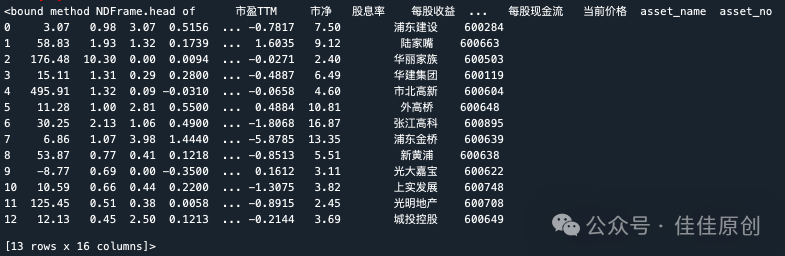
我们可以查看导入的数据,来检查导入的数据是否有遗漏。
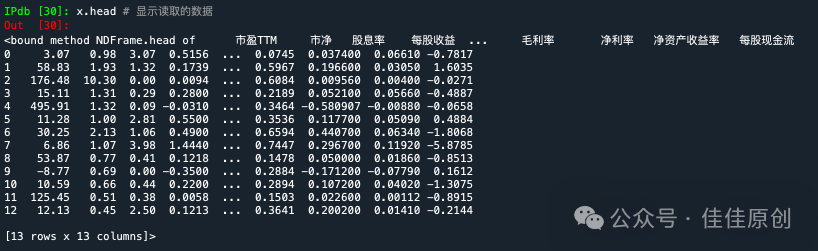
之后,我们将导入的数据进行整理,去掉【资产名称】和【资产代码】,因为这些数据在我们的机器学习过程中无使用价值。整理后的数据,如下所示。
5)机器学习。接下来我们对已有的样本数据进行机器学习,机器学习模型有很多,本文使用比较简单的线性回归模型进行机器学习。在项目中引入Sklearn,受于篇幅限制Sklearn详细用法,大家可以在网上查阅相关资料。

6)结果预测。我们将对【上海临港】资产价格进行预测,其基本的指标如下。

将以上指标作为输入条件录入机器学习模型中,生成结果。

预测结果:

根据机器学习相当数据后,对【上海临港】资产预测是【13.19元】,也就意味着结合与其相似的资产的现状,给出【上海临港】在当前背景下,资金价格应该值【13.19元】。
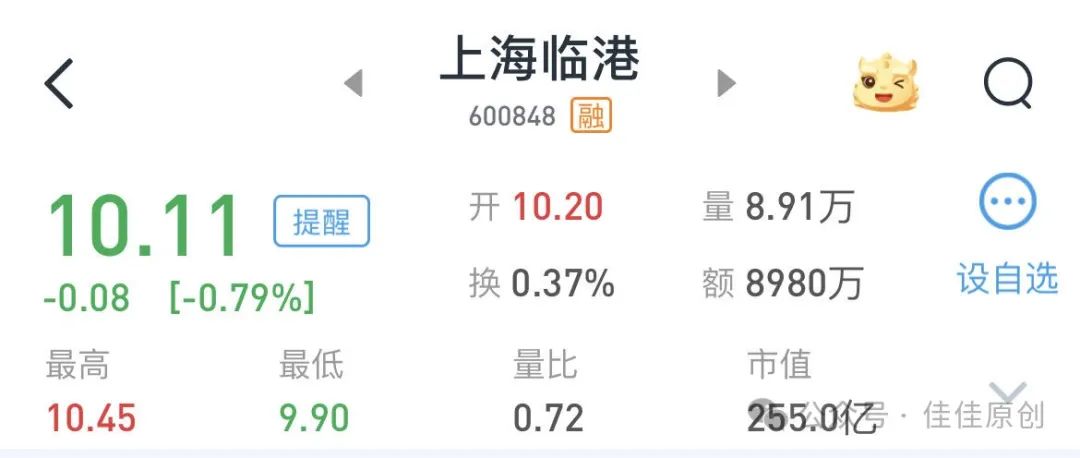
我们看了一下【2024年1月31日11:30】这个时点的【上海临港】的价格为【10.11元】,这说明在当前背景下,【上海临港】的价格相对于同类资产,其实是低估的,仍然有一定的增长空间。
虽然我们在本次人工智能金融量化分析实战使用的是真实的金融数据,但是由于数据样本量太少,机器学习的结论可能精度不够。我们使用的机器学习模型也比较单一,我们可以结合更多的机器学习模型,来提升机器学习的质量。
机器学习的过程也需要依赖非常多的基础条件才能不断提升机器学习效果,需要海量的数据,也需要不断对指标和模型进行调优,以及结合各种评价方法,使得机器学习的结论可以逻辑自洽。
对于本文而言,最大的价值在于我们建立了一个对金融资产进行量化分析的简单方法。在此方法基础上,我们可以结合更多的数据以及指标,来使得机器学习的结果更为精准。
在此基础上,构建一个金融人工智能的平台,对其他资产进行实时快速预测从而判断当前的资产价格是高估还是低估,以及是否有投资的空间。从而进一步作为计算机交易的参考因子,结合其他量化模型,给出决策参考或是智能投资。
另外我们在基础的金融量化分析模型的基础上,还可以升级为量化分析引擎,作为金融大模型的基础服务之一,使用ChatGPT或是其他嵌入式的工具,快速为用户或是机构提供便捷准确的金融服务,进而提升整个社会的金融运行效率以及质量。
人工智能金融量化分析,是一个非常复杂的系统工程,受限于作者水平,不能面面俱到,如果有不足之处,请大家指正!也非常欢迎朋友们随时交流。感谢大家阅读!
专栏作家
王佳亮,微信公众号:佳佳原创。人人都是产品经理专栏作家,年度优秀作者。《产品经理知识栈》作者。中国计算机学会高级会员(CCF Senior Member)。专注于互联网产品、金融产品、人工智能产品的设计理念分享。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


