
 起点课堂会员权益
起点课堂会员权益循环神经网络(RNN):如何处理自然语言?
上文介绍了卷积神经网络(CNN)的基础概念,今天我们来介绍可以处理自然语言等序列数据的循环神经网络。

循环神经网络(RNN)是一种强大的神经网络模型,它能够处理序列数据,如时间序列数据或自然语言。
当然传统的RNN同样存在梯度消失和梯度爆炸的问题,这限制了其在处理长序列时的性能,而优化后的长短期记忆(LSTM)和门控循环单元(GRU)可以有效的解决这些问题。
一、基本原理
在处理序列数据时,我们通常希望能够考虑到序列中的元素之间的依赖关系。例如,在处理自然语言时,一个词的含义可能依赖于它前面的词。传统的神经网络无法处理这种依赖关系,因为它们在处理每个元素时都是独立的。这就是我们需要RNN的原因。
RNN是一种递归的神经网络,它的输出不仅取决于当前输入,还取决于过去的输入。这是通过在网络中添加循环连接来实现的,使得信息可以在网络中流动。
这种结构让RNN能够处理序列数据,并考虑到序列中的元素之间的依赖关系。
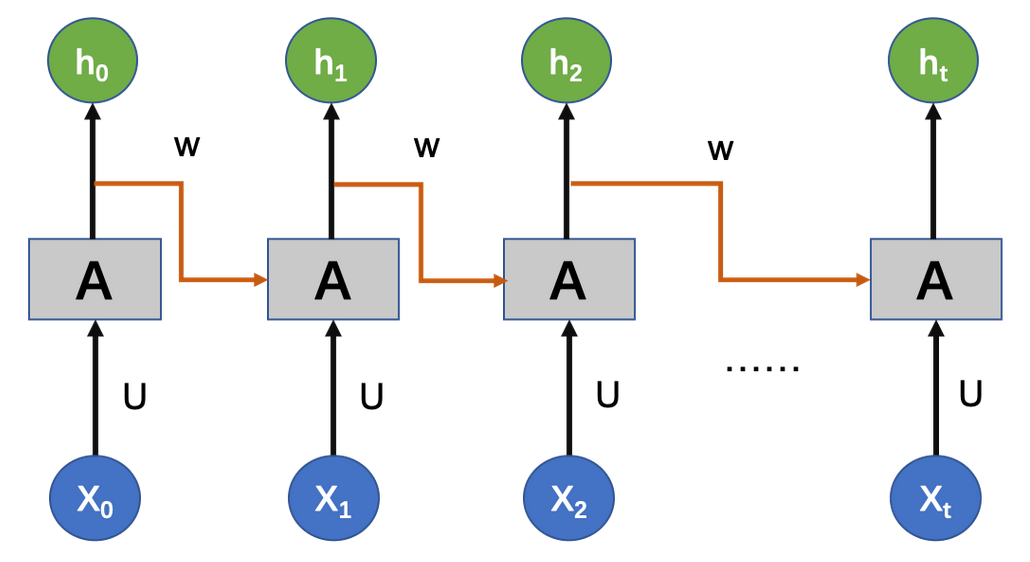
具体来说,假设我们有一个序列$x_0, x_1, …, x_t$,RNN会在每个时间步$t$接收当前的输入$x_t$和前一时间步的隐藏状态$h_{t-1}$,然后计算出当前的隐藏状态$h_t$和输出$y_t$。
这个过程可以用以下公式表示:
$h_t = f(W_{hh}h_{t-1} + W_{xh}x_t)$
$y_t = W_{hy}h_t$
其中,$W_{hh}$, $W_{xh}$和$W_{hy}$是网络的权重,$f$是激活函数。
这个过程会在整个序列上重复,每个时间步都会更新隐藏状态和输出。这样,每个时间步的输出都会考虑到当前输入和所有过去的输入,从而能够捕捉到序列中的依赖关系。
映射到一个自然语言句子,每个时间步的输入是句子中的一个词。在处理每个词时,RNN不仅会考虑到这个词,还会考虑到这个词前面的所有词。这样,RNN就能够理解句子的语义,从而能够进行诸如情感分析或机器翻译等任务。
假设我们正在处理一个情感分析任务,我们的目标是根据电影评论的文本来判断评论的情感是正面的还是负面的。我们的输入是一个词序列,例如 “这部电影不好看”。
在使用RNN处理这个任务时,我们首先会将每个词编码成一个向量,然后按照序列的顺序,依次将每个词的向量输入到RNN中:
- 在第一个时间步,我们将 “这部” 的向量输入到RNN,RNN会计算出一个隐藏状态和一个输出。这个输出是基于 “这部” 的情感预测。
- 在第二个时间步,我们将 “电影” 的向量和第一个时间步的隐藏状态一起输入到RNN,RNN会计算出一个新的隐藏状态和一个输出。这个输出是基于 “这部电影” 的情感预测。
- 这个过程会在整个序列上重复,每个时间步都会更新隐藏状态和输出。在最后一个时间步,我们将 “好看” 的向量和前一个时间步的隐藏状态一起输入到RNN,RNN会计算出一个隐藏状态和一个输出。这个输出是基于整个序列 “这部电影不好看” 的情感预测。
通过这种方式,RNN能够考虑到整个序列的信息,从而做出更准确的情感预测。
例如,虽然 “好看” 是一个正面的词,但由于前面有一个 “不”,所以整个序列的情感应该是负面的。RNN能够捕捉到这种依赖关系,因此能够正确地预测出这个序列的情感是负面的。
总的来说,RNN的基本原理是通过在网络中添加循环连接,使得信息可以在网络中流动,从而能够处理序列数据,并考虑到序列中的元素之间的依赖关系。
二、传统RNN存在的问题
梯度消失问题:梯度消失问题的具体表现就是RNN只能处理“短期记忆”,无法处理很长的输入序列。当网络的深度增加时,通过反向传播计算的梯度可能会变得非常小。这意味着网络的权重更新将会非常慢,导致训练过程非常困难。在RNN中,由于每个时间步的输出都依赖于前一时间步的隐藏状态,因此这个问题会更加严重。
具体来说,如果序列很长,那么在反向传播过程中,梯度需要经过很多步的乘法运算,这可能导致梯度变得非常小,从而使得权重更新非常慢。
梯度爆炸问题:与梯度消失问题相反,梯度爆炸是指在训练过程中,梯度可能会变得非常大,导致权重更新过大,使得网络无法收敛。在RNN中,如果序列很长,那么在反向传播过程中,梯度可能需要经过很多步的乘法运算,这可能导致梯度变得非常大,从而使得权重更新过大,导致网络无法收敛。
三、优化算法
3.1 长短期记忆(LSTM,Long Short-Term Memory)
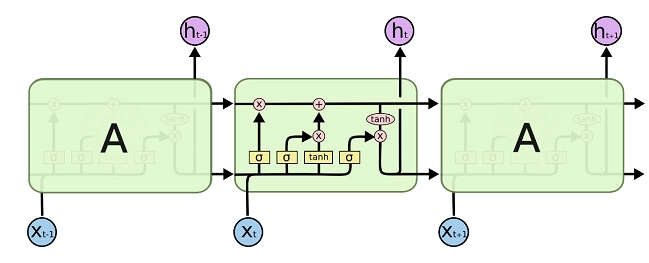
LSTM是一种特殊的RNN,它通过引入门控机制来解决梯度消失和爆炸问题,门控机制是LSTM用来控制信息流的一种方式。
在LSTM中,每个单元有一个记忆细胞和三种类型的门:
- 遗忘门(Forget Gate):决定了哪些信息应该被遗忘或者抛弃。
- 输入门(Input Gate):决定了哪些新的信息应该被存储在细胞状态中。
- 输出门(Output Gate):决定了细胞状态中的哪些信息应该被读取和输出。
每个门都有一个sigmoid神经网络层和一个点积操作。sigmoid层输出数字介于0和1之间,决定了多少量的信息应该通过。0表示“让所有信息都不通过”,1表示“让所有信息都通过”。
LSTM通过其门控机制解决了传统RNN的梯度消失和爆炸问题,使得LSTM能够在处理长序列时,避免了梯度消失和梯度爆炸的问题,从而能够学习到长距离的依赖关系。
下图是LSTM的原理示意图,具体原理不在此详述,感兴趣的同学可以自行查询一下。
3.2 门控循环单元(GRU,Gated Recurrent Unit)
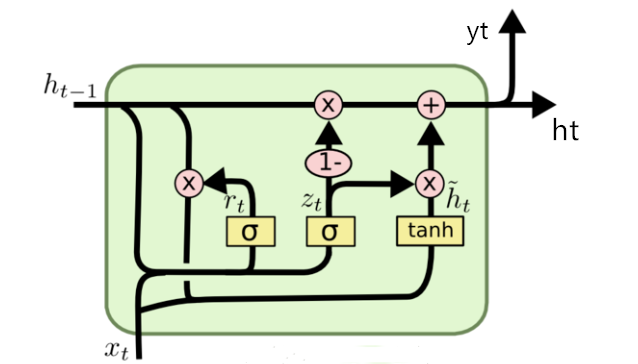
GRU是另一种高级的RNN,与LSTM相比,GRU的结构更简单,只有两种类型的门:
- 更新门(Update Gate):决定了在生成新的隐藏状态时,应该保留多少旧的隐藏状态的信息。
- 重置门(Reset Gate):决定了在生成新的隐藏状态时,应该忽略多少旧的隐藏状态的信息。
GRU的门机制使得它在处理长序列时,也能够学习到长距离的依赖关系。同时,由于它的结构比LSTM更简单,所以在某些任务上,GRU可能会比LSTM训练得更快,效果也更好。
下图是LSTM的原理示意图,具体原理不在此详述,感兴趣的同学可以自行查询一下。
3.3 LSTM和GRU的区别
LSTM和GRU都是RNN的变体,它们都使用了门机制来控制信息流,但是它们之间还是存在一些区别的:
- 门的数量:LSTM有三个门(遗忘门,输入门,输出门),而GRU只有两个门(更新门和重置门)。
- 状态的数量:LSTM维护了两个状态,一个是细胞状态,一个是隐藏状态。而GRU只有一个隐藏状态。
- 复杂性:由于LSTM有更多的门和状态,所以它的结构比GRU更复杂。这可能使得LSTM在训练时需要更多的计算资源。
- 性能:在某些任务和数据集上,GRU可能会比LSTM训练得更快,效果也更好。
- 记忆能力:理论上,基于LSTM的设计原理,应该能够更好地处理长期依赖问题。
四、应用场景
RNN由于其独特的循环结构,使其在处理序列数据上有着天然的优势,因此被广泛应用于各种序列数据的处理。
以下是一些常见的应用场景:
- 语音识别:用于建模音频信号的时间序列,从而实现语音识别。
- 语言模型:用于预测下一个词,从而实现语言模型。这在机器翻译,文本生成等任务中非常有用。
- 机器翻译:用于编码源语言序列和解码目标语言序列,从而实现机器翻译。
- 情感分析:用于分析文本的情感,如正面或负面。
- 视频处理:用于处理视频序列,如动作识别或视频标注。
五、总结
本文介绍了RNN的基本原理和应用场景,它能处理各种序列数据,同时也存在梯度消失和爆炸问题,而优化后的长短期记忆(LSTM)和门控循环单元(GRU)可以有效的解决这些问题。
下篇文章,我们会介绍对抗神经网络(GAN),敬请期待。
本文由 @AI小当家 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


