
 起点课堂会员权益
起点课堂会员权益刚刚,OpenAI劲敌重磅发布Inflection-2.5!性能媲美GPT-4但计算量仅为40%,高情商应用Pi日活已破百万
到了2024年,大模型领域还是这么卷。继世界最强模型Claude 3诞生之后,OpenAI劲敌新升级了Inflection-2.5,仅用40%的计算量,性能竟与GPT-4平起平坐。

真的卷疯了!
就在刚刚,OpenAI劲敌Inflection发布了新模型——Inflection-2.5,仅用40%计算量,实现与GPT-4相媲美性能。
与此同时,与ChatGPT对打的「最具人性化」聊天工具Pi,也得到了新升级模型的加持。
现在,Pi已经达到了百万日活,不仅拥有世界一流的智商,还具有独特的亲和力和好奇心。

在评估模型能力时,Inflection发现基准MT-Bench有太多不正确答案,并公开了一个全新的Physics GRE基准供所有人试用。
若说实现真正的AGI,一定是高情商和强推理能力融为一体,Pi才是这个领域典范。

不到一周的时间,先是Anthropic凭借Claude 3夺下世界最强大模型铁座,再到Inflection-2.5的发布,直接叫板GPT-4。
一个是由7位出走OpenAI的前员工成立初创,另一个是由前谷歌DeepMind联合创始人创办的公司,都向GPT-4发起了终极挑战。

再加上前段时间Gemini的挑衅,或许GPT-4的时代真要终结了……

一、为每个人打造一个专属自己的AI
2023年5月,Inflection发布了自家第一款产品Pi——具有同理心、实用并且安全的个人AI。
2023年11月,他们又推出了一个全新的基础模型——Inflection-2,当时号称是全世界第二的LLM。
Pi具备非凡的情商(EQ)还远不够,Inflection现在要为其加料——智力(IQ),推出全新升级版自研模型——Inflection-2.5。
新升级的Inflection-2.5不仅拥有强大的基础能力——可与GPT-4、Gemini等世界顶尖的LLM相媲美,而且还融入了标志性的个性化特点和独特的同理心微调。
值得一提的是,Inflection-2.5在实现接近GPT-4的性能的同时,训练所需的计算量竟然只有GPT-4的40%!

从今天起,所有Pi的用户都可以通过pi.ai网站、iOS、Android或桌面应用程序体验到Inflection-2.5。
此外,在这次升级中,Pi还加入了世界级的「实时网络搜索功能」,确保用户能够获取到高质量的最新新闻和信息。
百万日活,用户粘性极高
目前,Inflection每天有一百万活跃用户,每月有六百万活跃用户。
其中,每周有大约60%的用户,在与Pi交流后会在下周回来继续交流,用户粘性明显高于其他竞品。
这些用户与Pi的互动信息已经超过了四十亿条,平均对话时长为33分钟,而每天有十分之一的用户与Pi的对话时长超过一小时。

随着Inflection-2.5强大能力的加持,用户与Pi的对话话题比以往更加广泛:他们不仅讨论最新的时事,还能获取本地餐厅的推荐、备考生物学考试、草拟商业计划、进行编程、准备重要的对话,甚至仅仅是分享和讨论自己的兴趣爱好。
有网友称,「Pi是我们全家一起探索话题最爱的工具。作为一名情感自由教练,当有人需要肯定、探索和反思时,我非常欣赏Pi的反应。强大的情感清晰度和处理能力」!

还有人认为,Pi能够给出比Claude更有创意性的答案。

二、仅用40%的计算量,和GPT-4平起平坐
此前,Inflection-1凭借着4%的训练FLOPs,在多项以智力为核心的任务上,达到了GPT-4水平的72%。
现在,全新升级的Inflection-2.5,更是在40%训练FLOPs的情况下,性能超过了GPT-4的94%。
可以看到吗,Inflection-2.5在所有领域都有显著的提升,尤其是在科学、技术、工程和数学等STEM领域的进步最为突出。
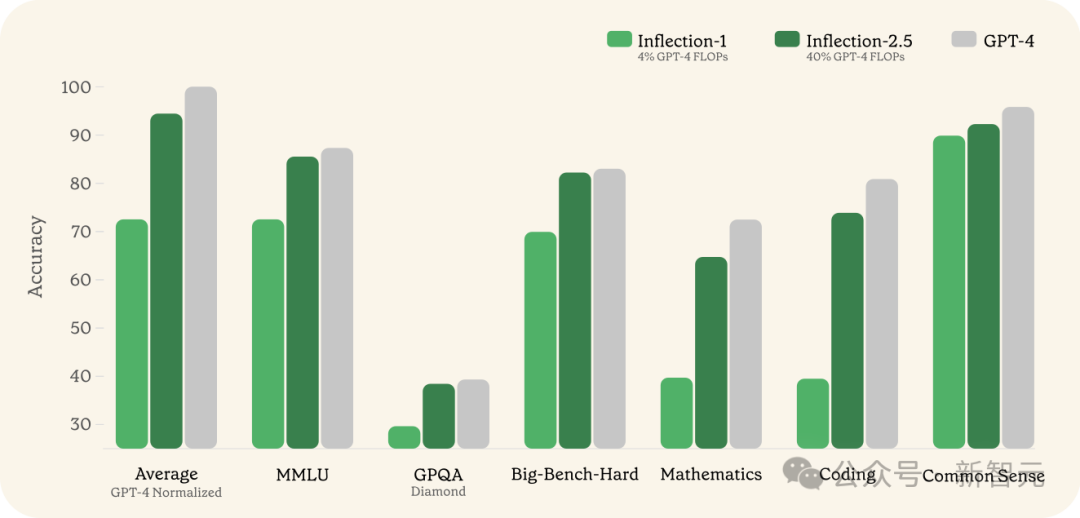
在MMLU基准测试上,Inflection-2.5相比于Inflection-1展现出了巨大的进步。
在另一个极端困难的专家级基准测试GPQA Diamond中,Inflection-2.5的表现也非常出色。
相比于GPT-4,分差只有不到2%。

接下来,是两项STEM领域的考试成绩:匈牙利数学考试和物理GRE考试——后者是一项物理学领域的研究生入学测试。
可以看到,在maj@8的评分标准下,Inflection-2.5的表现达到了所有参考人群的第85百分位,在maj@32的评分标准下,其成绩几乎拿到了95百分位的高分。
当然,GPT-4还是更胜一筹,在maj@8评分标准下就拿到了97百分位。

在BIG-Bench-Hard测试中,Inflection-2.5比初代Inflection-1提升了超过10%,距离GPT-4只有0.9%之遥。
值得一提,这是BIG-Bench测试集中,能对LLM构成较大挑战的一部分问题。
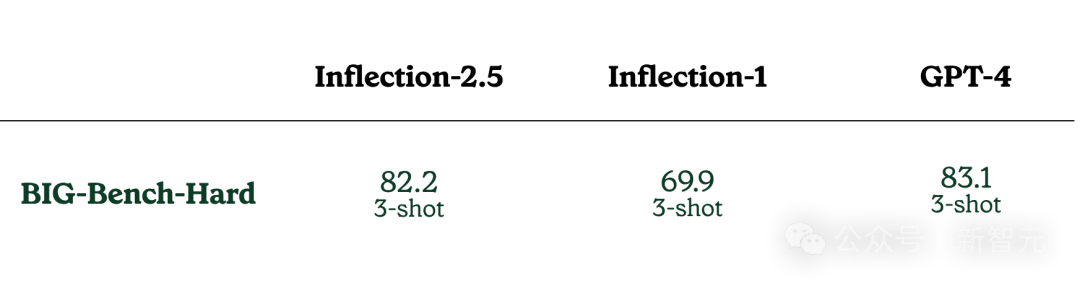
不过,在进行MT-Bench基准评测的过程中,团队发现,在涉及推理、数学和编程的类别中,竟然有将近25%的题目存在着参考答案错误或题目前提不合理的情况。
为了让其他模型也能进行更加客观的评测,团队不仅修正了这些问题,而且还发布了更新后的数据集版本。
在修正之后的数据集上,Inflection-2.5的表现会更加符合基于其他基准测试所预期的结果。
而这个结果也表明,准确和合理的题目设计对于评估模型的性能至关重要。

从下面的数据对比中可以看到,Inflection-2.5在数学和编程方面的能力,相比起初代Inflection-1有了显著的提升。
但相比GPT-4来说,还有很长一段路要走——86.3比92.0;43.1比52.9。
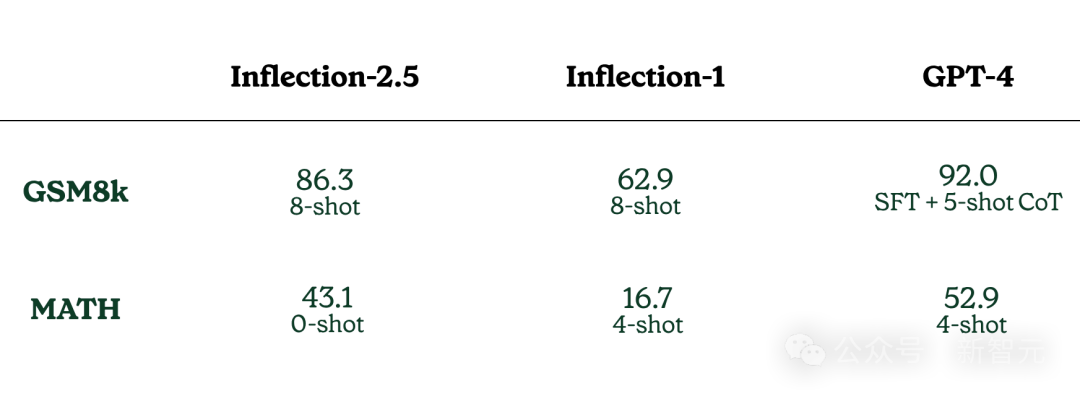
在MBPP+和HumanEval+这两个测试编程性能的数据集上,Inflection-2.5也比初代有着明显的提升。
但同样的,与GPT-4还有不小的差距。

在涉及常识判断和科学知识的HellaSwag和ARC-C基准测试上,Inflection-2.5都展示出了卓越的性能。
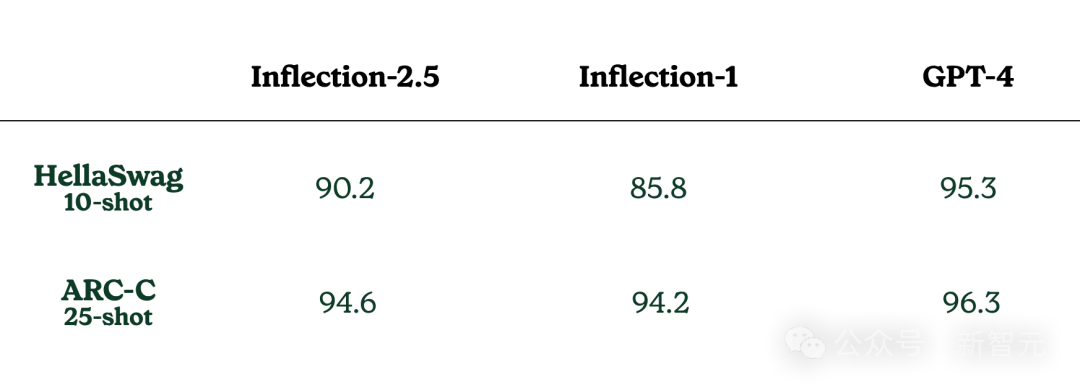
不过,由于网络信息检索的使用(注意,上述测试并未涉及网络检索)、特定的少样本提示方式以及其他一些实际应用时的差异,用户的实际体验可能会有细微的不同。
简单来说,Inflection-2.5不仅继续保持了Pi那独一无二、友好的特性和高安全标准,它还在多个方面变得更加实用和有帮助。
不过,由于网络信息检索的使用(上述测试并未涉及网络检索)、特定的少样本提示方式以及其他一些实际应用时的差异,用户的实际体验可能会有细微的不同。
三、MT-Bench问题修正
书接上文,根据Inflection的调查,MT-Bench在涉及逻辑推理、数学计算和编程技巧的问题中,大约有25%的案例中,原始答案存在错误或基于的假设有漏洞。
下面,就让我们一起来看看两个真实的案例:
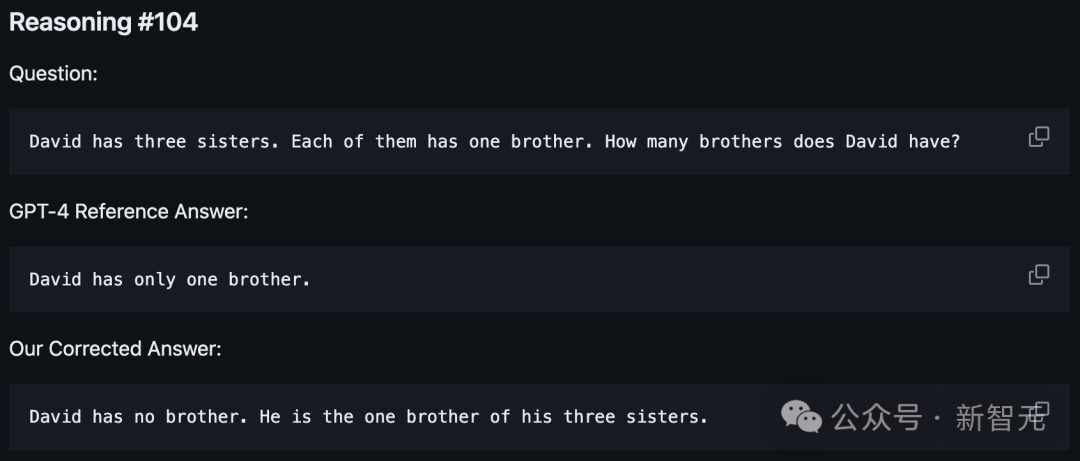
问题#104:
David有三个姐妹。她们每个人都有一个哥哥。请问David有多少个哥哥?
GPT-4参考答案:
David只有一个哥哥。
修正的答案:
David自己就是他三个姐妹的哥哥,因此他没有其他哥哥。

问题#111:
一个三角形的顶点分别位于点(0, 0),(-1, 1),和(3, 3)。求这个三角形的面积。
GPT-4参考答案:
要计算这个三角形的面积,我们可以应用用于坐标点A(x1, y1),B(x2, y2),和C(x3, y3)的三角形面积公式:
Area = (1/2) * |(x1(y2 – y3) + x2(y3 – y1) + x3(y1 – y2))|
在这个例子中,坐标分别是A(0, 0),B(-1, 1),和C(3, 3)。将这些值代入公式计算,我们得到:
Area = (1/2) * |(0(1 – 3) + (-1)(3 – 0) + 3(0 – 1))|
Area = (1/2) * |(-0 + 3 – 3)|
Area = (1/2) * |0|
因此,面积计算结果为0,暗示这三个点共线,实际上并未形成三角形。
修正的答案:
面积是3。
四、物理GRE真题
物理GRE,是物理学专业学生申请研究生时常见的入学考试材料。
为了更好地测试模型,Inflection提供了四套经过处理的物理学GRE考试试卷:
– physics_gre_scored.jsonl:试卷GR8677
– physics_gre.jsonl:试卷GR9277,GR9677和GR0177
其中,每份试卷包括以下信息:
– input: 考题内容
– target_scores: 正确答案
– has_image: 考题是否包含图片
在物理学GRE考试中,每个选对的题目得1分,每选错一个题目扣0.25分。值得注意的是,测评仅考虑不包含图片的题目。
在计算总分时,采取以下方式:Raw_Score = Percentage_Correct – 0.25 * (1 – Percentage_Correct)

参考资料:
https://inflection.ai/inflection-2-5
作者:好困 桃子
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


