
 起点课堂会员权益
起点课堂会员权益解码分类的超级英雄——支持向量机(SVM)
SVM模型可能会被不少企业弃用,但实际上,在中等数据集的分类算法,SVM模型的作用可能是优于其他算法的。这篇文章里,作者分享了SVM模型的应用步骤和优劣势等方面,一起来看一下。

很久没有聊算法了,我们来聊一个比较特殊的一个算法——支持向量机。
由于它在金融市场预测,图像识别太过于实用,但不太好理解,一两句话不太好概括,我们先用一个很简单的故事来开头吧~
一、趣解SVM
想象一下,你在一个聚会中,需要将爱喝茶的人和爱喝咖啡的人分成两个不同的小组。
支持向量机的工作就像是找到最好的一条线或者路径,将两种不同口味的人群尽可能准确和公平地分开。
而这条线或者路径是这样选出来的:它不仅要分开这两伙人,还要尽可能远离每一边最靠近中间的“关键”人物,也就是“支持向量”。
因为这样即使有些人稍微改变了一点位置(也就是数据的变化),这条分界线依然稳健地把大家分开,不会因为一点小小的变化就混乱。
在真实的数据分析中,这种情况可能会更加复杂,因为人们的口味可能不只是茶和咖啡那么简单,还有时候人群分布可能在空间中是弯弯曲曲,不是一条直线就能简单分隔的。
这时,SVM展现出了它的魔法——它能通过数学的手段把这些复杂的群体“提升”到另一个看起来我们头发都要乱了的空间(所谓的高维空间),然后在那里找到一种看似复杂实则有序的方法,把它们分开。
之后,SVM又能把这种分法“还原”回我们的正常视角,让我们看到一个在我们这个空间也能工作的聪明分法。
总而言之,支持向量机就是一个用来分类的超级英雄,它能够找到一种即使在很多复杂情况下也能表现得很好的方法,将不同类型的数据分隔开来。
二、支持向量机的算法原理
支持向量机(SVM)是基于统计学习理论中的结构风险最小化原则设计的,目的是寻找到最佳的泛化能力。
SVM在训练时提取数据中的支持向量,即距决策界限最近的几个数据点,用这些点来确定最终的决策函数。
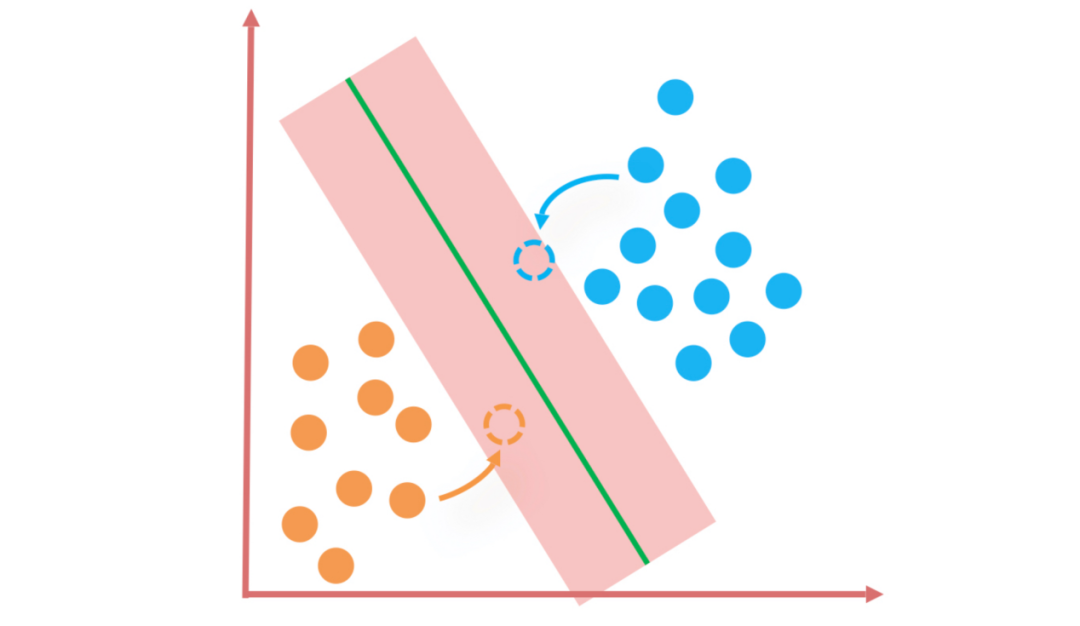
核心问题在于如何确定最佳的划分超平面。SVM通过引入拉格朗日乘子法转化问题,将其变成一个优化问题,使得分类间隔最大化。
这样做的直观理解是最大化分类边界附近无数据区域的宽度,以冗余的方式增强模型的泛化能力,减小在未见实例上出错的概率。
关键的创新之处在于:
- 最大化决策边界的间距:寻找分隔数据集中的不同类别的决策边界时,SVM试图最大化最近的点到边界的距离,以提高新数据点分类的准确性。
- 支持向量:决策边界的位置由距离边界最近的数据点决定,这些点称为支持向量,它们是构建SVM模型的关键。
- 核技巧:当数据无法被直线(或平面)分隔时,SVM利用核技巧将数据映射到更高的维度,使其分割变得可能。
总之,支持向量机也可以被理解为一种找到数据间最大间隔的方法,它具有不仅分隔数据还能够优雅地处理数据中的微小变动的能力。
通过核技巧和支持向量,它可以处理高度复杂和非线性的数据集,使其成为应对现实世界数据挑战的强有力的工具。
三、支持向量机算法的应用步骤
在将SVM应用于实际问题解决时,一系列的步骤需要被仔细执行以保证模型表现的优越性。下面是SVM算法应用过程中的关键步骤:
第一步:数据准备与预处理(通用)
在应用SVM前,首先需要收集并准备相关数据。数据预处理步骤可能包括数据清洗(去除噪声和不相关的数据点),数据转换(如特征缩放确保不同特征在相近的数值范围),以及数据标准化处理。
第二步:选择核函数
根据数据集的特性选择合适的核函数,是SVM核心的步骤之一。如果数据集线性可分,可以选择线性核;对于非线性数据,可以选择如径向基函数(RBF)核或多项式核来增加数据维度并发掘复杂的数据关系。
第三步:参数优化
优化SVM的参数(例如C参数和核参数)对模型的性能有着直接的影响。C参数决定数据点违反间隔的程度的容忍性,而核参数(如RBF核的γ参数)控制了数据映射到高维空间后的分布。
第四步:训练SVM模型
使用选定的核函数和优化后的参数,利用训练数据来训练SVM模型。在这个阶段,算法将学习划分不同类别的最佳超平面,并确定支持向量。
第五步:模型评估(通用)
利用测试集来评估SVM模型的表现。常见的评估指标包括准确率、召回率、F1分数等。评估结果可以帮助我们了解模型在未知数据上的泛化能力。
第六步:模型部署与监控(通用)
最后一步是将训练好的SVM模型部署到生产环境中,并实施持续监控。在模型部署过程中,需要确保实时数据的格式与训练时一致,并对模型进行定期评估以适应可能的数据或环境变化。
四、支持向量机算法的优缺点
优点:
有效性:对于中等大小的数据集,SVM通常能够提供高精度的解决方案,尤其是在处理高维度数据时。它对于特征的数量比样本数量多的情况下仍然表现良好。
灵活性:凭借核技巧,SVM能够通过合适的核函数解决各种类型的数据关系,并且可以进行复杂的非线性分类。
泛化能力:SVM旨在最大化决策边界的边缘,这往往导致更好的泛化,减少了过拟合的风险。
鲁棒性:通过适当选择正则化参数C,SVM能够处理存在噪声的数据并忽略掉离群点的影响。
缺点:
- 训练时间:当数据集非常大时,训练SVM模型需要的时间可能会比较长,这主要是因为SVM需要解决优化问题来确定支持向量。
- 参数调整:SVM的性能在很大程度上依赖于核函数的选择和参数的设定(如C和γ)。
- 结果解释性:与决策树和贝叶斯分类器等算法相比,SVM模型并不那么直观易懂。它作为一个黑箱模型,解释性受限。
最后的话
SVM模型分类的解释性差和不可控性较大,被很多公司弃用,但实际在中等数据集的分类算法中,它的作用要优于逻辑回归和KNN算法。
希望带给你一些启发,加油。
作者:柳星聊产品,公众号:柳星聊产品
本文由 @柳星聊产品 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


