
 起点课堂会员权益
起点课堂会员权益
银行如何构建大语言模型产品
 产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。
产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。自从ChatGPT发布之后,大模型对知识整理、归纳、推理、总结方面强大的能力引起了大家的关注。而银行领域的专业性和特殊性,更要求自己构建LLM产品。本文针对银行使用大模型的场景、方式进行了详细的分析,并给出了银行做大模型的实践样例,供大家参考。

目前大语言模型(Large language mode,LLM),以下简称LLM,非常火爆,各种基于LLM的产品如雨后春笋般出现。以OpenAI推出的GPT4为代表的LLM产品,为大家展示了LLM在对知识整理、归纳、推理、总结方面强大的能力。
LLM借助于思维链(Chain Of Thought,CoT)技术,可以使LLM生成推理路径,将复杂问题拆解为多个简单步骤分别处理,从而模拟人类思考的过程。

OpenAI近期推出的Sora产品,同样令人震撼,给出一些提示词,Sora便可以根据文本生成一段生动的视频,效果不亚于专业的视频工作室耗费几天做出来的视频。
例如通过提示词: 一段广角视频,一辆拉力车穿过红杉林,出现在树后,在急转弯时向空中喷洒泥土,电影胶片拍摄于35毫米景深 。Sora会生成一段高清的10秒左右的视频,非常逼真。大家有兴趣可以使用Sora体验一下。

由此可见LLM在人机对话、知识推理、归纳总结、图片和视频生成上功能确实非常强大,只要我们给定的提示词足够恰当,LLM便能给出我们想要的结果。
很多垂直领域,已经出现了许多LLM产品。本文收集整理了一些,大家有兴趣的可以重点深入了解。一些关于金融领域的LLM产品主要基于金融知识与问答,金融机构可以作为增值服务提供给客户,是一个非常不错的应用场景。
一、银行使用大模型的场景
对于银行而言,LLM产品的应用场景有很多。任何工具的使用,其主要目标是提升客户服务质量,节省企业运营成本,增加企业收益以及提升企业社会效益。概括下来,就是降本增效。
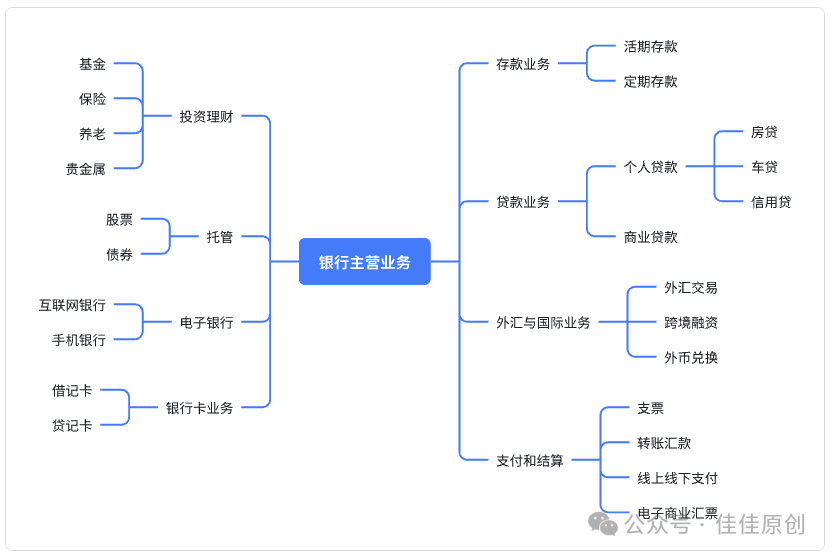
我们知道,银行的主营业务主要是存款业务、贷款业务、外汇与国际业务,支付和结算、投资理财、托管、电子银行以及银行卡业务等。
除此之外,还有清算、缴费、代理发行金融债券、票据贴现、代收代付等业务。很多银行也推出了银行业务相关的信息平台服务,例如招商银行的CBS(Cross-bank Solution for Cash Management,跨银行现金管理平台)。
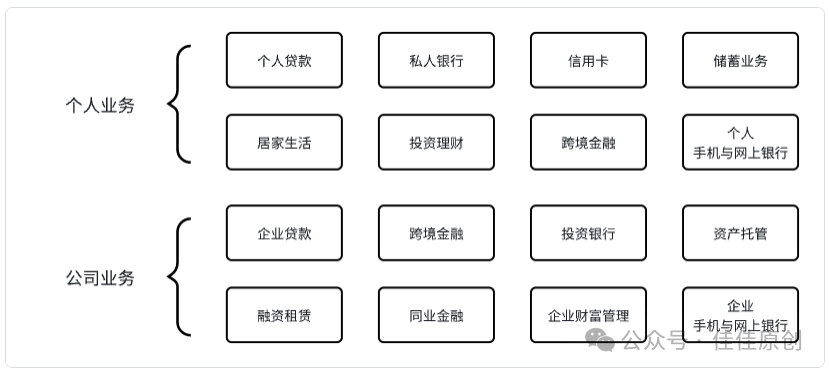
如果从银行服务的视角来看,针对个人业务和企业业务的服务划分,可以进行如下划分。
个人业务:信用卡、私人银行、个人贷款、储蓄业务、居家生活、投资理财、跨境金融、个人手机与网上银行等。
企业业务:国内业务、跨境金融、投资银行、资产托管、同业金融、企业财富管理、融资租赁、企业手机与网上银行等。
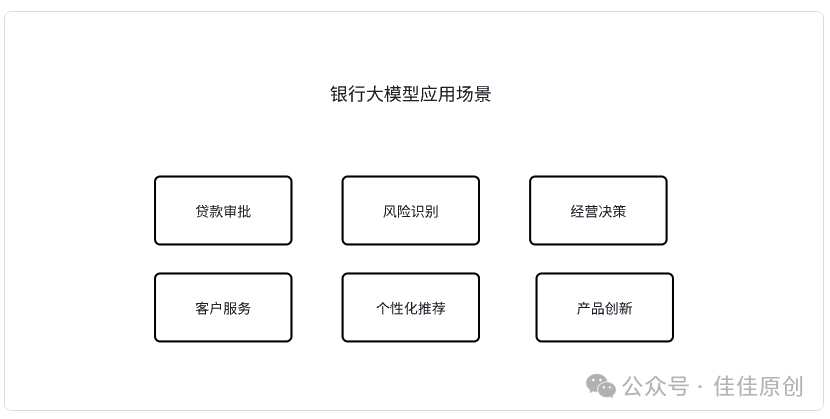
银行利润的主要来源是存贷利差。因此,如何能最大限度减少获客成本,识别优质贷款客户,提升放贷质量,减少银行坏账带来的损失,是大模型产品具有应用价值的场景之一,通过对历史客户数据进行分析,给出相对恰当的授信结果,快速审批,全方位风险管理。
对于银行客户服务水平,也是提升客户满意度非常关键的指标,利用大模型真实地与客户进行对话,并且非常精准地解答用户提出的问题,可以极大降低银行的客服人工成本。目前市面上已经有类型的产品,机器对话的仿真程度已经同真人对话效果相差无几。

大模型也可以为银行的管理者快速提供需要的信息,对经营数据进行分析,理解并快速绘制图表。相比于通过人工以周报的形式向银行管理层呈现数据图表,往往需要大量人工操作数据分析平台进行数据整理,大模型可以快速动态提供数据,为管理层提供决策依据,进而提升银行的管理效率与管理水平。
对于新产品创新,大模型可以通过其超强的计算能力与数据分析,能够快速进行金融计算与建模,根据当前银行的历史产品销售情况,并结合客户画像,结合利率计算、风险评估。给出最优的产品方案。
二、银行构建大模型的方式
根据我们对银行使用大在模型场景的梳理后发现,在大模型还没有出现之前,其实银行的业务已经存在,并且也已经通过数智化的方式对这些业务进行赋能。
例如基于大数据对信贷用户的智能评分与授信,根据用户的使用习惯和画像进行个性化信息或是产品的推荐,客户服务呼叫中心使用的NLP(Natural Language Processing,自然语言处理)、STT(Speech To Text,语言转文本)以及TTS(Text To Speech,文本转语言)。
大模型的出现,可以简单理解为是原有银行人工智能应用的升级,使计算机变得更聪明,产品效果更丝滑,用户体验更完善。
由于篇幅有限,本文主要以客户服务NLP为场景,来讲解银行构建大模型的方式。实现为银行的每位客户建立7×24小时随身专属顾问,降低银行人工客服与专属顾问成本,提升银行智能客户服务水平,增加客户粘性,提升用户满意度与忠诚度。
以消费贷款为例,很多用户收到银行的营销信息时,会遇到这样的问题,短信提醒告知用户有获得了一笔授信额度,利率非常优惠,但当用户实际操作时,却被告知没有额度,或是利率非常高,这样给用户的体验非常差,失去用户信任,当下次用户再收到这样的营销信息时,便很难被吸引,最终导致用户流失。
构建银行客服场景的NLP大模型产品,可以通过以下方式进行。
1. Embedding 初始化
Embedding基本的理念是用一个低维的向量表示一个物体,这个向量可以是一个词,一个商品,或是一个执行的任务等。对于银行智能客服,用户输入的一般是一段文本,如果使用大模型,Embedding的过程,也是Token化的过程。
Token是大模型中常见的交互与表示方式,也是一种计费方式。例如在GPT-4模型中,每1000个token的费用为0.03美元。
对于银行客服产品的大模型而言,将内容Token化也便于从客观的视角评价产品价值。最后可以通过计算实际同用户互动的Token数,来评估银行客户大模型的产品为银行实际带来的价值。
如何将内容Token化,可以按字分隔,也可以按词分隔。例如,用户在向智能客服咨询,“本期信用卡账单应还款是多少?”。
如果按字Token化,则为:“本|期| 信|用|卡|账|单|应|还|款|是|多|少|?”。
如果按词Token化,则为:“本期 |信用卡|账单|应|还款|是|多少|?”。
我们知道,其实句子有上下文,通过上下文的关联,实现语义的表达。如果有足够多的语料,也可以将句子作为Token。
2. Token 标注
将内容Token化之后,需要对Token进一步进行标注。标注的作用是为了增加计算机对于用户语义甚至是情感的理解,提升机器回答用户问题的精准度。
通过对用户内容Token标注,我们可以对用户内容进行实体抽取,用户的情感分析,还可以根据标注的内容,同关系图谱或知识图谱进行关联,发掘更多信息。
假设我们有一个标签集合,集合的内容是 {scop,name,action,amount,type,…}。我们根据标签的集合,以及字典信息,对用户提问“本期信用卡账单应还款是多少”的文本内容做如下标注。
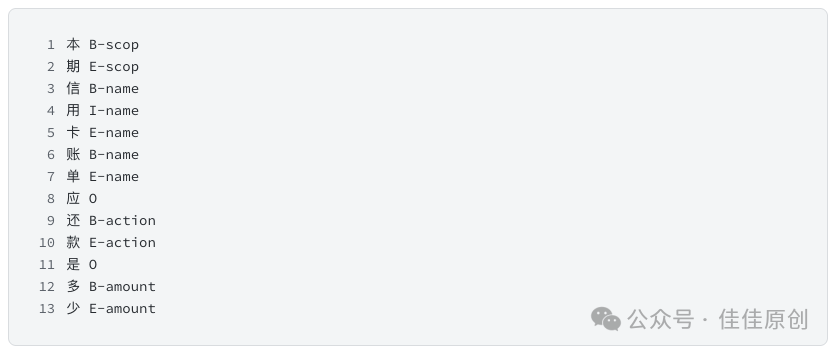
其中,B代表Begin,意味着标注的开始,E代表标注的结束。如果一个词比较长,中间有多个字,可以用多个大写的I表示。横线- 后面的内容是对内容的标注。例如,信用卡,我们认为是一个名称,可以标注为 【name】;还款是一个动作,我们可以标注为【action】。
对于传统的银行智能客服机器人,其实这一步完成之后,基本就可以搭建起一个简单的客服机器人,通过对内容配置相应的执行任务,结合相似度计算或是简单的机器学习就可以回答用户问题。
但是在大语言模型,我们还需要进一步对内容进行训练,扩展客服机器人的服务边界,让用户感觉更像是同真人在沟通。同时,在服务用户的同时,还可以像真人客服一样“顺便”为用户推荐些产品。
3. Attention机制
Attention机制,出现在2017年的一篇论文《Attention is All You Need》中,在这篇论文中提出了Transformer的模型架构,并针对机器翻译这种场景做了实验,获得比较好的效果。
早些时候使用Seq2Seq模型,即序列到序列模型,可用于文本翻译,主要原理是:接收的输入是一个(单词、字母、图像特征)序列,输出是另外一个序列。
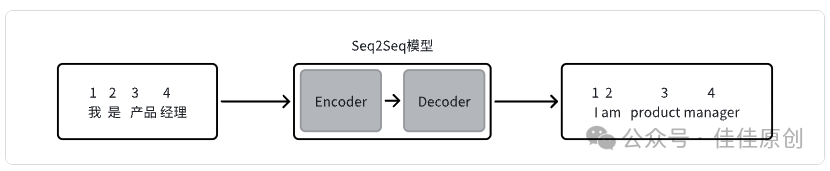
但是Seq2Seq模型有个不足之处是仅是根据序列进行映射,不考虑上下文,语义,语法,模型效果不是很好。Transformer模型中提出了Self Attention的结构,取代了以往 NLP任务中的 RNN 网络结构。
用户输入在Encoder(编码器)的文本数据,首先会经过Self Attention 层,Self Attention层处理词的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息。
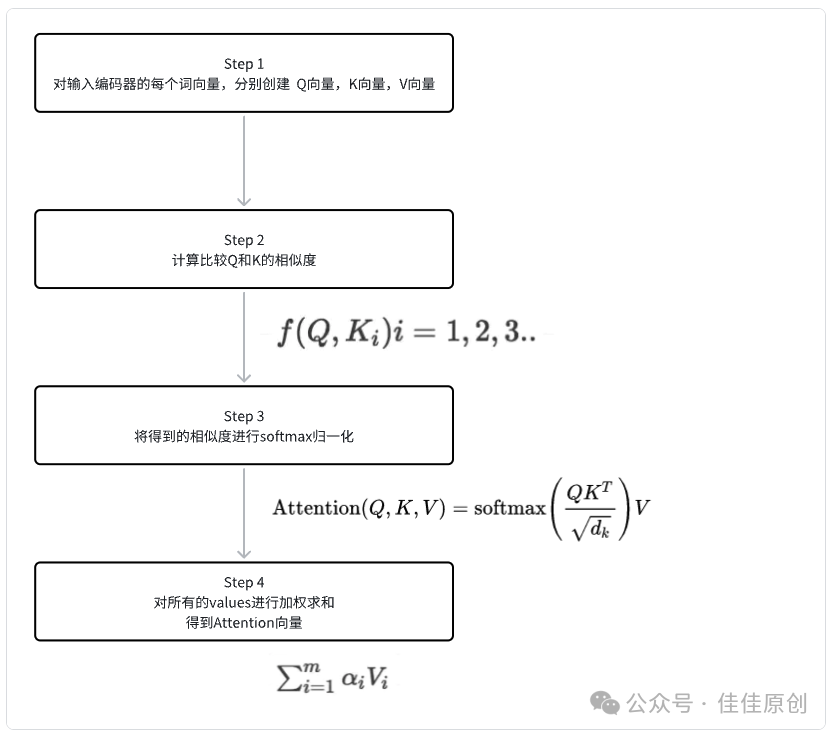
Attention机制解决了【Encoder(编码器)-Decoder(解码器)】结构存在的长输入序列问题,其功能可以被描述为将查询和一组键值对映射到输出,其中查询(Q)、键(K)、值(V)和输出(O)都是向量,输出可以通过对查询的值加权来计算。
简单理解,就是先用问题输入Query,检索Key- Value 的记录,找到和问题相似的记录中的Key值,计算相关性的分数,然后对Value Embedding进行加权求和,从而衍生出了Self Attention中的Q、K、V的表示。主要实现步骤如下图所示:
4. 内容安全
银行的大模型产品,在产品形态上,并不等同于闲聊机器人。因为闲聊机器人,为用户提供的服务主要是解决用户“无聊”的场景,而银行客服机器人,在同用户聊天互动的同时,要确保回答结果的精准。
必须给出严谨的结果,否则宁愿不回答。因此对于内容的安全,需要格外关注。确保内容安全,主要可以通过三个方面进行内容安全控制。
用户输入内容进行控制:属于事前控制的一种方式,利用关键词识别,以及语义识别,对用户输入的内容进行安全校验,判断是否存在内容安全风险。如果存在风险,则给出相应的提示,用户的内容不会作为大模型语料库的输入信息。
大模型自身内容处理:属于事中控制的一种方式,用户输入的内容已经进入银行智能客服大模型的引擎当中,大模型可以根据用户输入内容是否属于历史模型构建范围内的知识进行判断,如果无法处理,则明确返回用户无法理解用户内容,需要后续学习改进。
大模型输出结果控制:属于事后控制的一种方式,这时大模型已经根据用户的提问内容给出相应的答案,即将输出给用户,但发现内容存在安全风险。则需要对结果进行过滤,或者重新触发大模型的处理机制,告知大模型这个答案存在内容安全风险,需要重新生成新的结果。
总之,在银行智能客服产品使用大模型时,可以引入CGT(Controlable Text Generation,可控文本生成)来确保内容质量,降低内容安全风险。

5. 效果评测
在作者之前出版的《产品经理知识栈》这本书中,我们给出了对于人工智能效果评价的机制。对于软件工程通用的系统稳定效果,可以通过压力测试获得相应的评测结论。
对于银行智能客服大模型的运行效果,我们可以准备测试数据集,来进行验证,一般而言,测试数据集占整个数据集的20%相对最为合适。通过准确率、精准率与召回率进行评价。
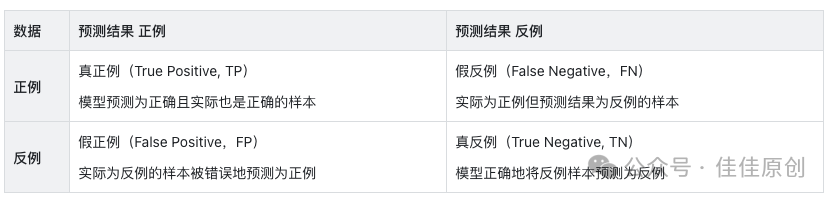
- 准确率(Accuracy Ratio):预测【正确的结果】占【总样本】的百分比。即:AR =(TP+TN)÷(TP+FN+FP+TN)
- 精准率(Precision Ratio):也称为查准率,针对【预测结果】对所有被预测为正的样本中实际为正的样本的概率。即:PR = TP÷(TP+FP)
- 召回率(Recall Ratio):也称为查全率,针对【原样本】在实际为正的样本中被预测为正样本的概率。即:RR = TP ÷(TP+FN)
从公式中我们可以看出,精准率和召回率的分子者为TP,但是分母不同,在实际操作中,想要更高的召回率,精准率就会降低。
为了平衡精准率与召回率的关系,我们使用F1分数来作为指标。即:
F1 = (2×精准率×召回率)÷(精准率+召回率)
三、银行大模型产品实践样例
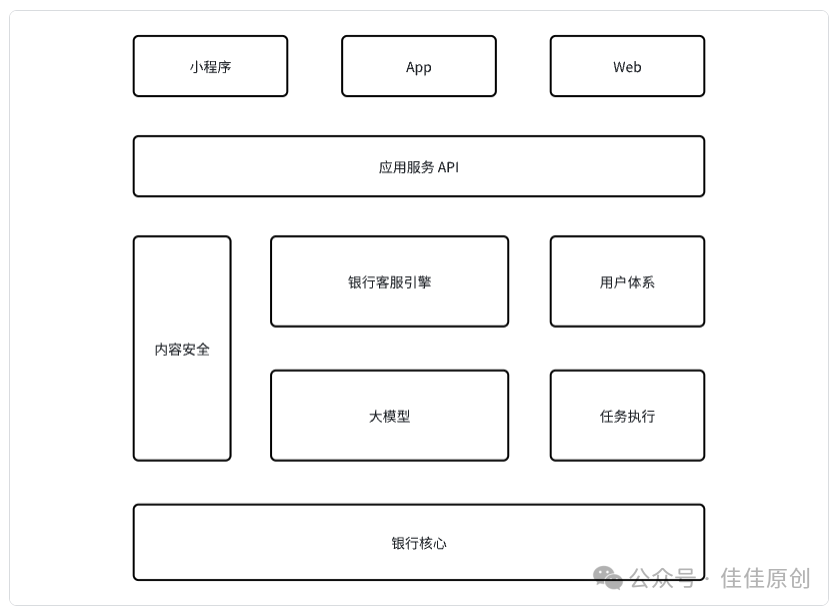
1. 总体架构
我们可以通过一个简单的架构,实现银行大模型产品的MVP(Minimum Viable Product,最小可行)版本。在银行大模型产品MVP版本中,我们通过银行小程序、银行App或是网上银行的服务,为用户提供智能文本对话服务。
小程序、App和Web作为承载银行大模型智能客服的渠道,通过统一的应用API(Application Programming Interface,应用程序编程接口)完成功能接入,实现客服功能。
内容安全模块,作为接收用户输入内容的第一道安全防线,将一些用户输入的敏感内容或是与银行客服无关的内容进行过滤;后续对大模型的内容输出进行再次识别,防止不当或是敏感内容传递给客户。
银行客服引擎,是用户与银行客服产品的纽带,负责识别客户,连通用户体系,根据用户画像,对用户提问进行提炼,结合用户历史服务数据,生成恰当的Prompt给到大模型,甚至可以利用客服引擎历史积累的数据,作为大模型的学习样本,对大模型进行“蒸馏”以降低部署成本。
用户体系承载着用户基本信息,对用户进行身份认证,根据用户历史的数据,生成用户画像,基于用户和账户体系,建立同银行核心数据的交互。
任务执行则是根据某些场景建立相应的规则和策略,执行相应的任务。例如,用户在智能客服对话框中输入“本期信用卡账单应还款是多少?”,大模型识别为用户意图是查询本期信用卡的账单,则结构化相应的执行参数给到任务执行模块,由任务执行模块到银行核心中,执行相应信息的获取,并将相关内容返回给大模型,由大模型加工处理后,呈现给用户。
2. 案例实践
接下来我们着重对大模型的构建作为产品实践样例。同样以用户同客服咨询“本期信用卡账单”内容为例,我们的基本目标是通过对用户针对询问“本期信用卡账单”不同的提问内容,通过大模型学习,智能客服均可以识别用户意图,给出本期信用卡账单金额的回答结果。
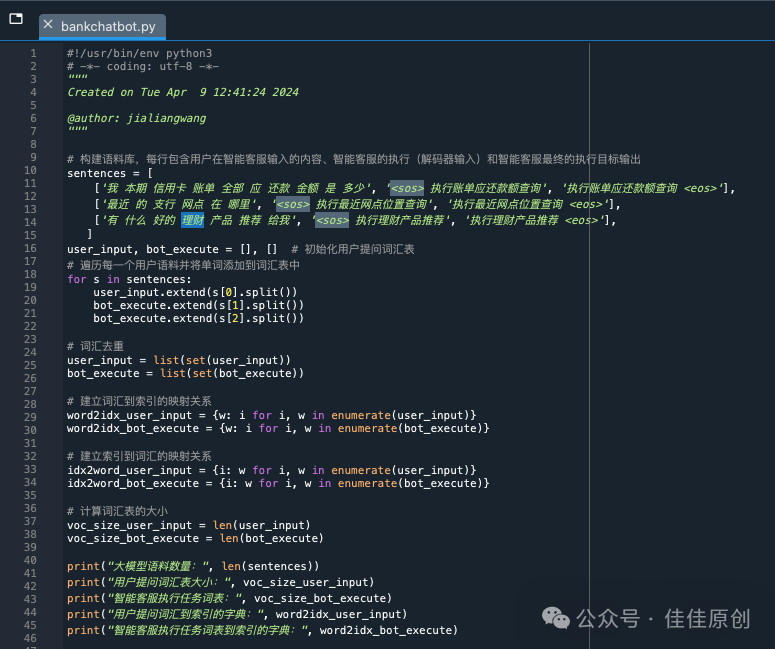
(1)构建学习语料
我们根据用户历史的银行客服问答数据作为大模型的语料输入,在本案例中,我们仅选取了三条数据作为实验数据。
以下源代码给出了如何将用户输入的内容建立同索引的映射关系,并给出了输出结果样例。在实际操作中,语料库的内容非常庞大,打印语料库的功能需要注释掉。
由于本文实验数据非常少,我们选择将语料的内容进行显示输出,便于直观查看,也有利于后期的模型调试。
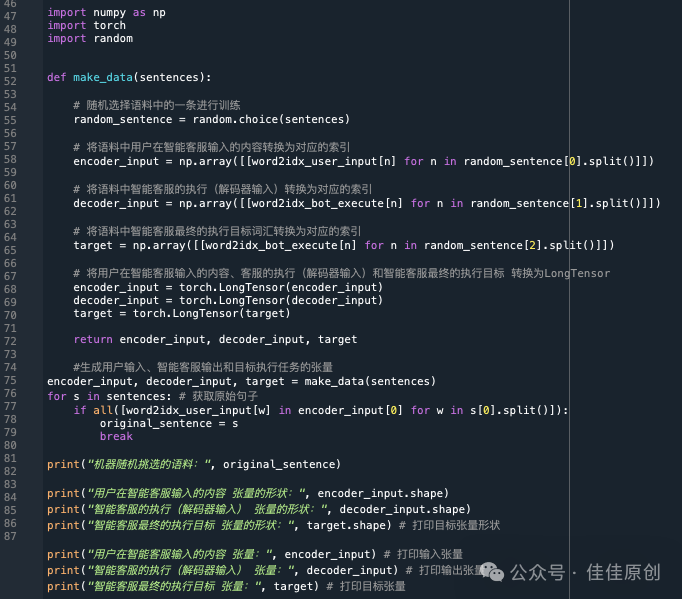
(2)模型训练
为了简化计算,我们根据收集的主料库中随机选取一条语料进行模型训练。同样我们将机器随机挑选的语料,张量的形状,也进行了打印输出,方便观测运行过程。
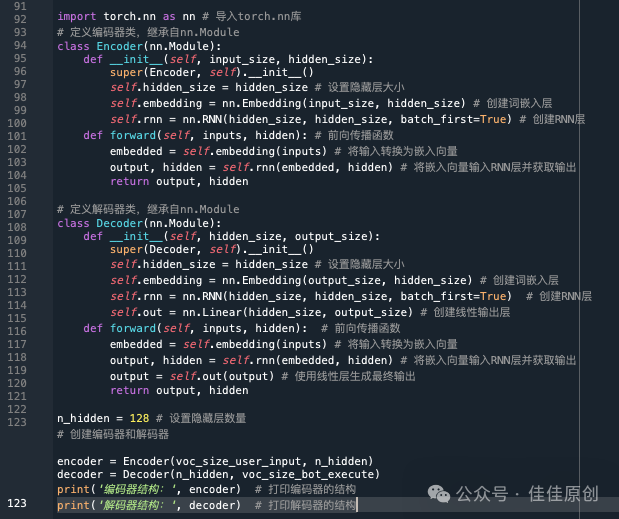
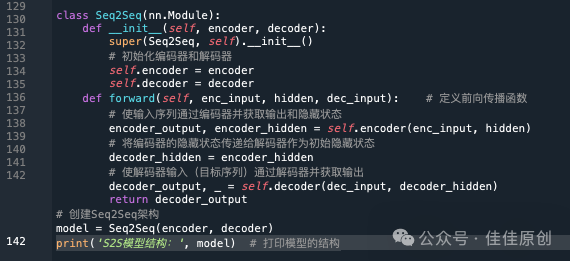
(3)定义编码器和解码器
由于本案例实践使用的是非常基础的Seq2Seq模型,编码器和解码器也相对比较简单。包含了嵌入层和RNN(Recurrent Neural Network,循环神经网络)层。
如果语料数据特别庞大,我们可以调整input_size和output_size参数,以适应不同的数据量。另外也可以调整RNN的相关参数,增加模型复杂度和容易,不过这样机器运算的代价也会同步增加。
(4)整合编辑器和解码器
大模型中包含了编辑器和解码器,因此我们需要将两者进行整合,形成一个总模块,便于处理用户输入的序列,并给出相应的结果输出。
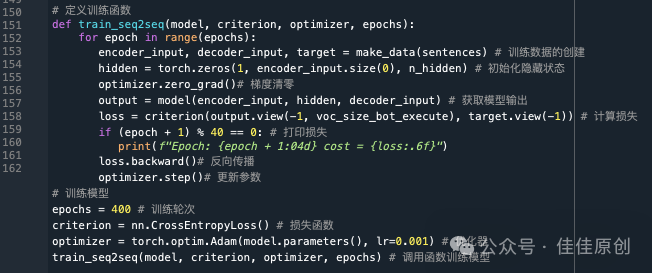
(5)定义训练函数
在这个训练模型中,每一个Epoch都会随机选择一个语料进行训练。本文中由于语料稀少,训练模型的训练轮次设置的也不是很多。
实际银行部署过程中,银行的AI服务器非常强大,可以结合海量数据进行训练,从而提升结果的精准度。
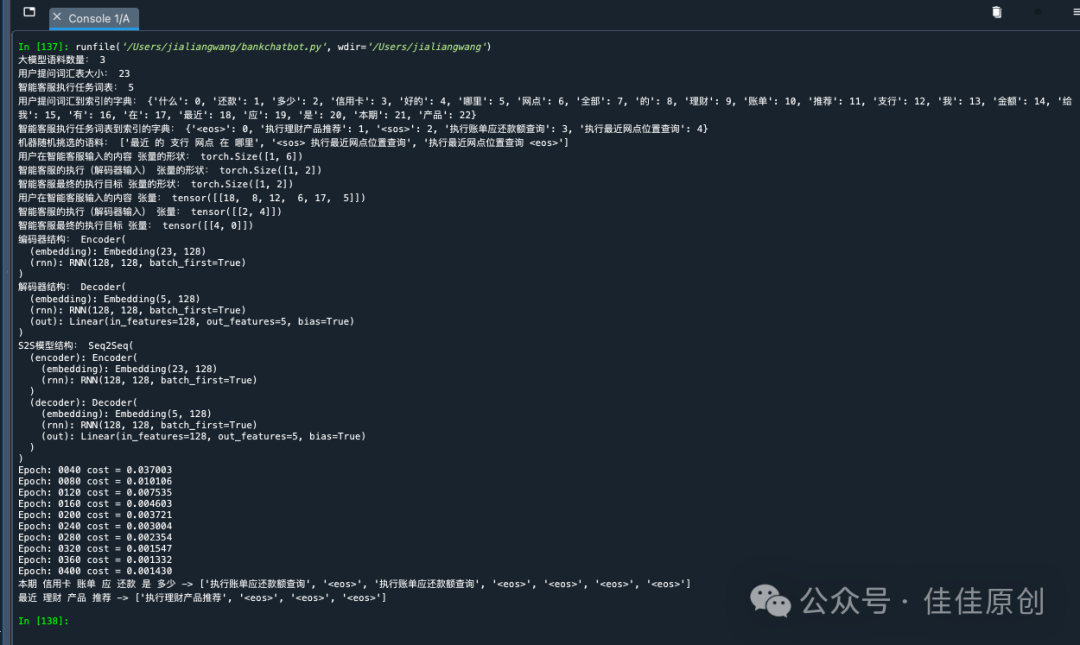
(6)结果输出
由于语料数据非常少,因此模型的准确度是并不是很高,在输入一些类似的其他问题,可能会导致回答不准确。
我们的目标是希望用户在输入信用卡账单或是理解推荐之类的问题时,银行智能客服的大模型能给出相应的结果。
在本文实践案例中,我们结合上文的“本期 信用卡 账单 应 还款 是 多少”,作为输入,银行客服大模型会给去【执行账单应还款额查询】策略,从而触发相应的任务机制,从银行核心系统提取用户本期信用卡账单的还款金额数据。
当用户输入是咨询“有什么理财产品”相关,则银行智能客服会去【执行理财产品推荐】,调用银行产品推荐系统,获得相应的理财产品推荐数据返回给用户。
四、总结与展望
本文从当下最流行的大模型应用出发,结合对银行使用大模型场景的方式,给出了基础的银行构建大模型的方式。通过最后银行大模型产品实践样例的搭建,完成了银行大语言模型产品MVP版本的构建。
当然,本文也有不足之处,由于大模型涉及的内容非常多,受于篇幅所限,不能面面俱到。大模型的发展日新月异,本文的内容仅基于已的理论的应用,比较陈旧。
另外,在本文的实践案例中,仅使用了基础的Seq2Seq模型,没有使用到Transformer,也没有用到Attention机制,语料的规模也不够,还不足以称为“大模型”。后期我们会专门针对Transformer进行详细讲解。
由于大模型目前涉及的场景非常多,各种开源的大模型,各种垂直细分领域的大模型产品如雨后春笋般出现。很显然,在银行领域,大模型会成为银行经营新的赋能工具。
大模型在图表理解和金融计算方面能力非常强大,能够解析和解释各类金融图表,包括识别图表类型、理解数据含义、分析趋势和模式;能够进行金融计算和建模,包括利率计算、投资组合优化、风险评估等。
大模型可以对传统银行风险管理、反欺诈、个性化推荐、贷款审批、经营决策等现有的功能进行重构,使这些传统功能焕发新的生机,降低银行经营成本,提升银行运营效率,将会带来质的飞跃,成为银行新的发展动能。
参考文献
[1]王佳亮.产品经理知识栈[M].出版地:人民邮电出版社,2023
[2]黄佳.GPT图解 大模型是怎样构建的[M].出版地:人民邮电出版社,2024
[3]蜗牛海胆. (2021). NLP入门系列1:attention和transformer [EB/OL]. https://blog.csdn.net/ahdaizhixu/article/details/119749361
[4]潘小小. (2023). 【经典精读】万字长文解读Transformer模型和Attention机制:attention和transformer [EB/OL]. https://zhuanlan.zhihu.com/p/104393915
专栏作家
王佳亮,微信公众号:佳佳原创。人人都是产品经理专栏作家,年度优秀作者。《产品经理知识栈》作者。中国计算机学会高级会员(CCF Senior Member)。专注于互联网产品、金融产品、人工智能产品的设计理念分享。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









