
 起点课堂会员权益
起点课堂会员权益我们离AGI还有多远?
我们离实现人工通用智能(AGI)究竟还有多远?这个问题的答案,我们不妨从行业大咖的观点来做进一步的探讨。一起来看看本文的梳理和分享。

一、引言
在探索人工智能的边界时,我们经常面临一个根本性的问题:我们离实现人工通用智能(AGI)还有多远?这个问题不仅触及技术进步的速度,也深刻反映了我们对智能本质的理解与期待。AGI或全能型人工智能,指的是一种具备人类智能全部能力的机器,能够在任何认知任务上达到或超越人类的表现。从学术探讨到科幻小说,AGI长久以来被视为技术进步的终极目标,它代表着人类智慧的延伸与超越。
然而,尽管近年来人工智能领域取得了显著的进展,特别是在深度学习和大规模模型训练方面,我们对AGI的追求仍然充满了挑战与不确定性。
一方面,模型如Claude 3 Opus的出现展示了AI在处理复杂问题和模拟人类行为方面的惊人能力;另一方面,这些进步也揭示了我们在理解智能本质、模拟复杂认知过程、以及在伦理和安全方面所面临的深刻问题。因此,当我们问自己“我们离AGI还有多远”时,我们不仅在探询技术的边界,更是在反思人类智慧的深度与广度,以及我们愿意以怎样的方式迈向那个未知的未来。
本文从“深度学习三巨头”的观点,AGI评测基准和当前大模型局限性等三个维度深度探讨该问题。
二、深度学习三巨头的观点
1. LeCun:当前的AI还远未达到人类智能
Yann LeCun(杨立坤),目前是Meta的副总裁兼首席AI科学家,同时也是纽约大学Courant数学科学研究所的教授。作为人工智能领域的领军人物,LeCun对当前人工智能的发展趋势和未来方向有着独到的见解。他的观点主要围绕如何使机器能够像人类和动物那样理解和与世界互动,强调“常识”推理的重要性以及基于“世界模型”的预测和计划能力。
LeCun批评了当前人工智能发展中主流的方法,尤其是依赖大型语言模型(如GPT-3)和强化学习的方法。他认为,仅仅通过扩大语言模型的规模,这些模型虽能处理文字和图像,但缺乏对世界的直接理解或体验,是无法达到人类级别人工智能的。同样地,他也认为基于奖励的试错学习方法——强化学习,因为需要大量数据,也不是通向泛化智能的可行路径。
与此相对,LeCun提出了一种自主智能的架构,包括一个能够预测世界未来状态的世界模型。这个模型将通过无监督的方式从未标记的数据中学习,从而无需明确指示就能理解世界动态。这个架构由六个模块组成,包括执行控制的配置器、理解当前状态的感知模块、预测的世界模型、决策的成本模块、规划行动的行动模块,以及追踪状态和成本的短期记忆模块。
LeCun的观点是对AI社区探索当前主导范式之外的新方向的一次呼吁,强调模型以有意义的方式理解和预测世界的重要性。他在开发世界模型和自主智能架构方面的工作可能为开发能够进行推理、规划和以更人性化的方式与世界互动的更复杂的AI系统铺平道路。
2. Hinton:人工智能将变得比我们更加智能
Geoffrey Hinton, 被誉为“深度学习之父”,近年来对人工智能的发展和潜在风险表达了一些引人深思的看法。他特别担心,如果人工智能达到或超过人类智能,它们可能会找到操纵甚至杀害人类的方法。
Hinton警告说,我们可能接近这样一个点,那时人工智能将变得比我们更加智能,这让他感到恐惧。他特别担心,某些人可能会利用这些工具,如在选举和战争中操纵结果。为了防范这些风险,Hinton提出需要在技术行业领袖之间合作,以确定风险所在并采取措施。
Hinton担心,随着AI技术的快速发展,我们可能很难判断什么是真实的?什么是虚拟的?他特别关注大型语言模型的发展,如GPT-4,它展现出了比人类更高效的学习能力,这让他认为机器可能很快就会比人类更加智能。他指出,尽管大型语言模型的连接数与人脑相比还是非常小的,但它们能够展示出惊人的学习能力,尤其是在少量学习(few-shot learning)的情况下,这些模型能够快速学习新任务。Hinton认为,这挑战了人们认为人脑在学习上具有某种魔法般的优势的观点。
他认为如果不能控制AI,不法分子可能会利用它做坏事。他还担忧,在短期内,互联网可能会被假文本、照片和视频淹没,长期来看,这些技术甚至可能对人类构成威胁。Hinton在X(Twitter)上明确表示,他离开Google的原因不是为了批评该公司,而是为了能够毫无顾忌地讨论人工智能的危险,而不必担心这些观点会对他所在的公司产生影响。
总的来说,Hinton的看法提醒我们,随着人工智能技术的发展,我们需要深思熟虑地评估其潜在的积极和消极影响,并采取适当的预防措施以确保技术的安全和负责任地使用。
3. Bengio:AI发展需要更加谨慎和有预见性的规划和监管
Yoshua Bengio是蒙特利尔大学计算机科学与运筹学系的教授,同时也是蒙特利尔学习算法研究所(MILA)的科学总监。作为深度学习和人工智能领域的先驱之一,对当前AI技术的快速发展及其潜在风险表达了深切的关注。
Bengio联合数百名技术领导者、AI研究者、政策制定者等,签署了一封公开信,敦促所有AI实验室同意暂停开发比GPT-4更强大的系统六个月。这一举措旨在为私营行业、政府和公众提供时间来充分理解AI及其应用,并围绕它制定适当的规制措施。Bengio及其他参与者强调,这种快速的发展速度超出了我们理解、识别风险及缓解风险的能力。他们认为,六个月的时间可以为创建围绕AI的治理、了解和风险缓解努力提供机会。Bengio认为很难准确知道人工智能达到人类智能水平还需要多少年或多少个十年。但目前的技术发展速度和资金投入加速了AI能力的提升,因此他呼吁需要紧急监管来缓解AI发展带来的最大风险。
在一次访谈中,Bengio讨论了大型AI模型发展所带来的风险,尤其是关于民主的安全。他指出,我们已经能够操纵信息,使其看起来非常真实,如深度伪造内容,他建议应该要求在AI生成的内容上加上标记或水印,以帮助观众区分哪些是AI生成的,哪些不是。他还强调了AI在创造假冒和有说服力的内容方面的能力,可能会使人们被AI算法所淹没,从而破坏了民主依赖的共同现实基础。
Bengio对于AI的这些表态不仅展示了他对技术发展潜在负面影响的深刻理解,也体现了他对未来社会和技术治理的关注。他的观点强调了在AI发展的道路上,需要更加谨慎和有预见性的规划和监管,以确保技术的进步能够造福而非损害人类社会。
三、当前主流大模型的评价基准
1. AGI的评价方法
如何评估AGI的能力?这需要综合一系列量化指标和多种测试方法,以捕捉人工智能在不同层面表现。这些方法大致包括:知识水平和逻辑推理的知识测验;专业领域内应用能力的专业技能测试;策略和学习能力的复杂游戏;通过模拟环境评估适应性和问题解决的虚拟仿真;艺术作品原创性和审美的艺术创作;创新解决方案的能力评估;自然语言处理的图灵测试;情感和社交互动的评价;在多任务性能、学习迁移、复杂问题解决、实时决策、道德困境应对、社会规范遵循、综合感知和交互式任务的能力。这些多方位的测试旨在全面评价AGI的复杂智能水平。
目前,AGI常用的评估工具基本上是参考人类的专业考试和学术测评基准,而制作的专业化系列问题集。这些测试工具和数据集包括但不限于:
1)MMLU(Massive Multitask Language Understanding)
MMLU是旨在通过评估模型在零样本(zero-shot)和少样本(few-shot)设置中的表现来衡量在预训练过程中获得知识的能力。这种评估方式使得基准测试更具挑战性,更接近于我们评估人类的方式。MMLU覆盖了STEM(科学、技术、工程和数学)、人文学科、社会科学等57个学科领域,难度从基础级别到高级专业级别不等,测试内容包括世界知识和问题解决能力。
2)MATH
MATH是一个专门设计来评估模型在数学问题解决能力上的测试。这种测试挑战模型在理解和解决各种数学问题上的能力,包括但不限于代数、几何、微积分和统计等领域。MATH测试通常涉及以下几个关键方面:问题多样性—包含不同类型的数学问题,涵盖从基础数学到高级数学的多个层面;推理能力—测试模型是否能够逻辑推理和解决复杂的数学证明或计算问题;准确性—模型输出的解决方案需要数学上的精确和正确;解释性—除了提供正确答案外,评估模型是否能够展示其解题步骤,即“解题思路”(Chain of Thought),有助于理解模型如何达到最终答案。
3)GSM8k(Grade School Math 8k)
GSM8k是一个专门为评估和训练人工智能模型在解决数学问题方面的能力而设计的数据集。它包括大约8000个小学和初中水平的数学题目,这些题目设计来测试模型在进行算术运算、解析数学问题语境、以及应用基本数学理解和推理技能方面的表现。
4)HumanEval
HumanEval是一个由 OpenAI 设计的数据集,用于评估代码生成模型的性能。它包括了一系列编程题目,这些题目通常包括问题描述、一个函数签名和一组单元测试。这个数据集的主要目的是测试模型生成代码的能力,尤其是代码是否能在实际编程任务中有效运行。
5)GPQA(General Purpose Question Answering)
GPQA是纽约大学的研究者们构建了一个包括生物学、物理学和化学等多学科领域的多项选择题数据集,共包含448个问题。该数据集在设计上旨在桥接专家与非专家的知识鸿沟,方法是由专家出题并确保答案的准确性,同时让非专家进行尝试,保障问题对非专家具备一定的挑战性。
这份数据集的问题难度极高,即便是在相关学科领域已获得或正在攻读博士学位的专家,平均正确率也仅为65%。对于其他专业领域的非专家来说,这一比例更是降至34%。对比之下,像GPT-4这样的先进AI模型在GPQA上的表现也只达到了39%的正确率。该数据集因此成为测试和发展能够提高人机协作监督下高效AI输出方法的重要工具。
6)MGSM(Multilingual Grade School Math)
Google 发布的这个数据集是一个多语言数学问题解答能力的评估和训练基准。它包括了从GSM8K(Grade School Math 8K)精选的250个数学问题,这些问题原本是用于测试小学水平的数学问答能力,并需要多步推理。现在,这些问题已经被人工注释者翻译成10种不同的语言,增加了它们的多样性和可用性。GSM8K本身是一个包含8500个高质量数学文字问题的集合,这些问题语言多样且旨在支持基础数学问答任务。
这个被称为MGSM的数据集,特别适合于开发和评估多语言问答系统,尤其对于教育技术领域具有重要意义。它不仅能够促进开发能够理解和解答多种语言中提出的数学问题的AI系统,而且为研究者们提供了一个平台,用于探索和提升多语言自然语言处理模型在数学问题解答方面的性能。
7)DROP(Discrete Reasoning Over the content of Paragraphs)
DROP是由加州大学和北京大学等研究机构共同开发的英文阅读理解基准数据集。此数据集的设计目标是推动阅读理解技术超越传统的文本处理,更深入地分析文本段落。系统需要在理解段落内容的基础上,进行如加法、计数和排序等离散推理操作,这些操作要求比之前的数据集更深层次的文本理解。
为了创建DROP数据集,研究者们采用了众包方法,首先自动选取Wikipedia中含有大量数字的叙事性段落,随后利用Amazon Mechanical Turk平台来收集问题及其对应的答案。在构建问题时,研究者们使用了具有对抗性的基线系统BiDAF作为参考,激励众包工作者提出难以被基线系统回答的问题。最终形成的数据集包含了96,567个问题,覆盖了Wikipedia上的众多主题,尤其是体育比赛摘要和历史段落,对阅读理解技术的深入性和广泛性提出了新的挑战。
8)BIG-Bench Hard (Broad Impact General Benchmark Hard)
BIG-Bench是由Google、OpenAl等研究者共同开发,旨在通过一系列多样化的任务来全面评估大语言模型的性能。BIG-Bench包含了超过200个任务,这些任务涵盖了文本理解、推理、逻辑推理、数学推理和常识推理等多个领域。任务类型包括机器翻译、文本分类、序列标注、抽取式摘要、信息检索、表格解读、数理推理、常识推理、多模态推理、规划和数学问题解答等。
而BBH则是在BIG-Bench数据集的一个子集,专注于23个最具有挑战性的任务,这些任务超出了当前语言模型的能力范围。BBH中的任务需要进行多步骤推理。
9)MMMU(Massive Multi-discipline Multi-modal Understanding & Reasoning)
MMMU是一个为大学级多学科多模态理解和推理设计的综合测试基准。它的问题来源于大学考试、测验和教科书,涵盖六个常见学科:艺术与设计、商业、科学、健康与医学、人文与社会科学以及技术与工程。MMMU由11.5K个精心选择的多模式问题组成,涵盖30个不同科目和183个子领域,从而达到广度目标。此外,MMMU中的许多问题需要专家级的推理,例如应用“傅立叶变换”或“平衡理论”来推导解,从而达到深度目标。

MMMU还提出了当前基准测试中没有的两个独特挑战。首先,它涵盖了各种图像格式,从照片和绘画等视觉场景到图表和表格,测试了LMM的感知能力。其次,MMMU具有交错文本图像输入的特征。模型需要共同理解图像和文本,这通常需要回忆深刻的主题知识,并根据理解知识进行复杂的推理以达成解决方案。
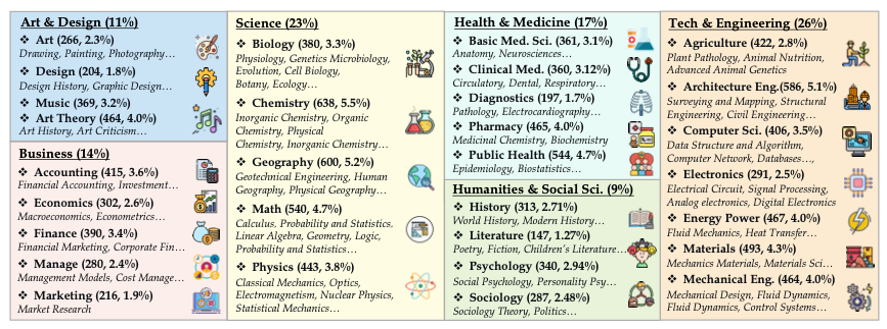
MMMU包含11.5K个多模式问题,涵盖六个广泛的学科、30个科目和183个子领域,每个学科的MMMU样本。这些问题和图像需要专家级的知识来理解和推理。
MMMU作为评估LMM(多模态大模型)能力的基准的开发标志着迈向AGI之旅中的一个重要里程碑。MMMU不仅测试了当前LMM在基本感知技能方面所能达到的极限,还评估了它们处理复杂推理和深入的特定主题知识的能力。这种方法直接有助于我们理解专家AGI的进展,因为它反映了不同专业领域的熟练成年人所期望的专业知识和推理能力。
尽管MMMU具有全面性,但与任何基准一样,它也并非没有局限性。人工测试过程虽然彻底,但可能存在偏见。同时,对大学水平科目的关注可能也不是对AGI的充分测试和评估。然而MMMU会激励AI社区建立更多,更全面的面向专家通用人工智能的下一代多模式基准模型。
2. 主流大模型测试结果(Claude3、GPT-4、Gemini)
目前主流大模型的发布都会以一系列评估工具和数据集作为测试基准,并公开有利于自己的测试成绩。下图是Anthropic公司发布的Claude3系列的最新测试报告。
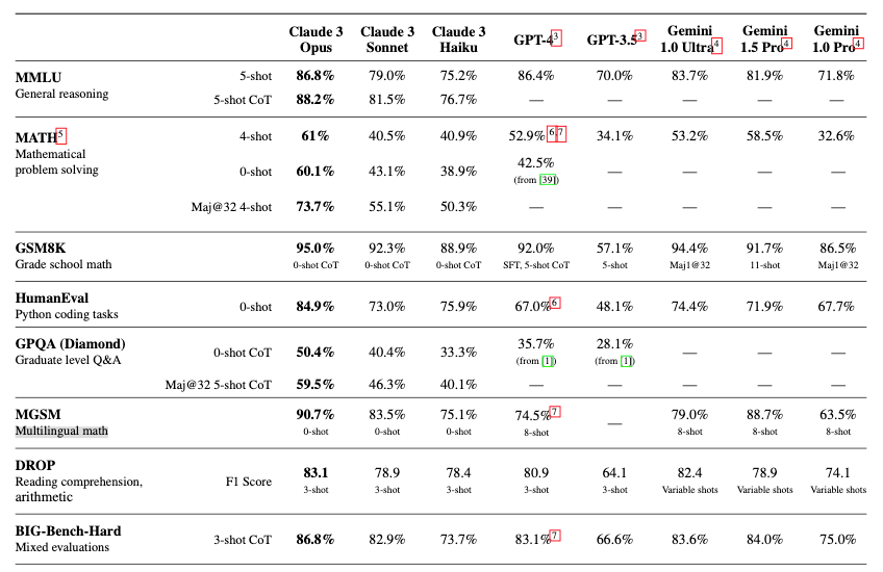
在以上这份测试报告中,展示了包括Claude 3系列模型(Opus、Sonnet、Haiku),GPT系列模型(GPT-4、GPT-3.5),Gemini系列模型(1.0Ultra、1.5Pro、1.0Pro)在内的多个人工智能大模型在不同测试基准任务上的成绩。
在MMLU测试中,Claude 3 Opus以86.8%的成绩表现最佳,与GPT4在一个水平,其次是Gemini 1.0Ultra。在5-shot和0-shot的Chain of Thought (CoT)解题推理链中,由于GPT和Gemini系列没有测试,无法比较。但Claude 3 Opus以88.2%的正确率显示其在一般推理能力方面的强大。
在MATH能力方面,Claude 3 Opus在0-shot条件下得到61%的准确率,超过其他所有模型。在经过少量示例(4-shot)学习后,Opus的表现也是所有模型中最好的。
在小学和初中数学(GSM8K)测试中,Opus同样位居榜首,准确率达到95.0%,显示其在数学问题解决方面有卓越的能力。此外,Opus在多语言数学测试(MGSM)中也展示了其强大的多语言能力。
在Python编码任务(HumanEval)中,Opus的成绩为84.9%,这表明了其在理解和生成代码方面的能力。
在研究生水平的问题和回答(GPQA)测试中,Opus的5-shot CoT得分是50.4%,明显高于其他所有模型,表明其在高级推理能力方面的优势。
在多语言数学(MGSM)测试中,Opus的成绩是90.7%,进一步证实了其在多语言处理和数学问题解决上的能力。
在阅读理解和算术(DROP)测试中,Opus得分为83.1,再次领先。
最后,在混合评估的BIG-Bench-Hard测试中,Opus的表现同样是最好的。
总体而言,测试结果显示Claude 3系列中的Opus模型在各项任务上均表现优异,尤其是在高级推理和数学问题解决方面,其性能超越了GPT-3及Gemini系列。这些结果揭示了Opus在多方面任务的应用潜力,尤其是在需要复杂推理和深度理解的场景中。
当然,由于Claude 3系列的测试报告是在GPT-3及Gemini系列之后发布,同时,也并非是第三方测试,而各商业大模型都会选择有利于自己的评价方法和数据集,其测试公正性有待商榷。同时,以人类答题水平作为比对基准的这种“小镇做题家”式的测试,本质上离AGI还有相当大的距离。
3. 主流大模型MMMU测试结果
由于常规大模型在单模态和单一测试数据集的表现并不能充分表现其在AGI方面的真实水平。因此,IN.AI Research,滑铁卢大学,俄亥俄州立大学,独立大学,卡内基梅隆大学,维多利亚大学,普林斯顿大学等研究机构联合发布了MMMU测试数据集与主流多模态大模型的测试结果。
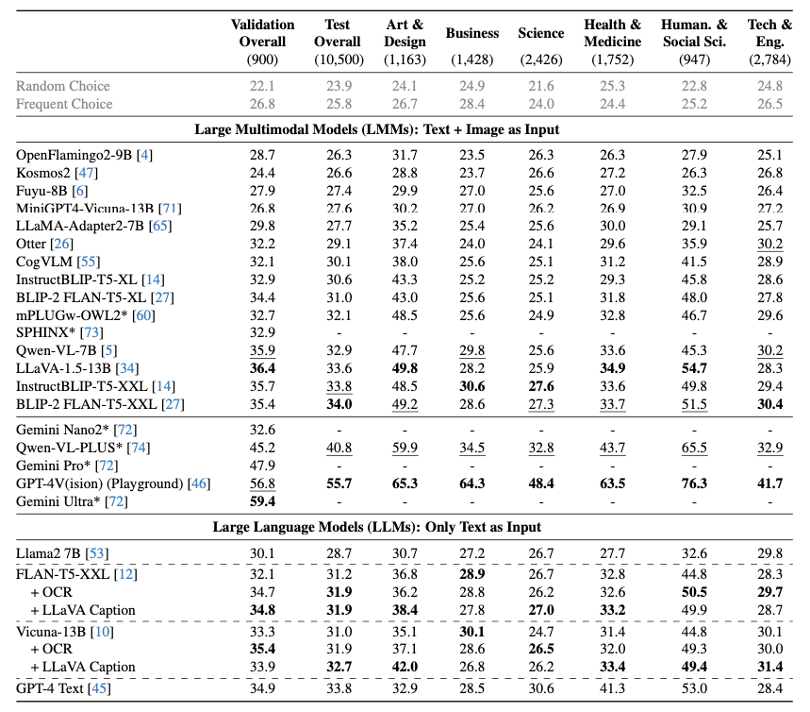
从该测试报告来看,即使是先进的GPT-4V和Gemini Ultra商业大模型也只能分别达到56%和59%的准确率,这表明大模型在大规模多学科多模式理解与推理上的还有很大的改进空间。
四、目前大模型的局限与缺陷
1. 理解和推理的限制
大模型生成的回答可能看起来合理,但它并不真正“理解”内容。它基于模式识别生成文本,这可能导致理解上的误差或逻辑上的错误,尤其是在处理复杂的推理或需要深入专业知识的主题时。而人类在知识理解中更多的是靠文字、图像、听觉、嗅觉、触觉等多感官系统相互映射、推理、验证和联想,并非只依靠单模态的理解。
2. 数据偏差和不准确性
大模型的回答质量和准确性完全依赖于其前期训练数据,如果训练数据存在偏见或错误,其生成的内容也可能反映这些偏见或包含错误信息。虽然,人类的思维也依靠自身成长过程的信息处理和训练,但人类思维训练的成果并非是静态的知识积累,而是建立了一套动态的思维和理解模式。这也是人类可以快速准确的处理新知识,并能准确纠正认知错误的关键。
3. 创造性和新颖性的限制
虽然大模型可以生成新颖的文本内容,但它的“创造性”受限于其训练数据范围内的模式组合。其产生的“新颖性”更多是依靠回归模型中的文字组合预测,其并不能超出训练数据的语意范围。这也是大模型生成的文章更有明显的成文范式和普适性,会让人初读惊艳、细读乏味。大模型的文字创造力更像百科全书的知识集合,而对专业领域的创造力由于训练数据的缺失,也无法实现更有成效的语言创造。
4. 情境和上下文的理解
尽管大模型能处理一定的上下文信息,但它在理解复杂或长期的上下文方面表现不佳。它难以跟踪长对话中的线索或维持长篇文章的连贯性。例如在长对话中,大模型可能会逐渐失去对早期提到的信息的跟踪。
这是因为大模型记忆机制有限,不能像人类那样灵活地回顾和引用过去的讨论内容;在生成长篇文章时,保持主题一致性和逻辑连贯性可能是一个挑战。大模型可能在文章较长时开始重复或偏离主题;对于需要深度推理或广泛背景知识的复杂问题,大模型可能无法完全理解所有的细节和潜在联系,特别是在需要综合多方面知识的情况下。
5. 无法自主学习和适应
当前的大模型并不能主动学习或适应新信息,它的知识仅限于训练数据截止时的状态。这意味着大模型无法自行更新或改变已经学习或训练完成的成果。如果出现新的事实、发现或文化变化,除非通过新的训练数据更新模型,否则无法反映这些变化。
这种设计的目的是能确保输出的一致性和可预测性,同时防止模型从不可靠的数据源学习和输出无法预测的信息。但正是这种设计的局限性限制了大模型向人类一样的学习和思考。
五、结论
目前,在科学界和产业界中,关于何时能实现人工通用智能(AGI)的预测存在显著差异,这反映了不同人士对未来AI技术进展的不同观点和期望。
一些科技企业领袖和AI研究者对AGI的到来持乐观态度。例如,DeepMind的创始人Demis Hassabis认为,在未来十年内实现AGI是有可能的。而OpenAI的首席执行官Sam Altman,更是预测AGI可能在大约五年内成为现实。多位AI研究者和思想家,包括Geoffrey Hinton和Ray Kurzweil,预测AGI将在未来几十年内到来,具体时间从5年到20年不等。
在更广泛的科学研究社区中,预测的时间则更为保守。一项由Muller和Bostrom进行的调查显示,参与者普遍认为到2040年有50%的可能性实现AGI,到2075年则有90%的可能性。这项调查还表明,大多数专家预计在AGI实现后的30年内,超级智能(大大超过人类智能的AI)的出现概率为75%。近期在Linux 基金会主办的北美开源峰会上Linux创始人Linus Torvalds则表达了对目前AI炒作的怀疑态度,并建议等待十年再评估AI的实际发展情况。
Yann LeCun认为,目前依赖于大规模数据和强化学习的人工智能模型,如GPT和其他大型语言模型,不太可能实现真正的普适人工智能。LeCun更倾向于开发能够理解和推理的AI系统,类似于人类和动物的方式。他提出了一种新的架构,即“联合嵌入预测架构”(JEPA),旨在通过自监督学习来训练模型,使其能够生成和理解高层次的抽象表示。
LeCun特别强调了通过训练AI系统理解世界的模型(世界模型),该模型能够预测并作出决策,而不仅仅是响应外部输入。这种方法的目标是创建一个能够理解环境并据此行动的AI,从而更接近人类的思维方式。强化学习之父Richard Sutton教授更看好Yann LeCun的世界模型理念,并将其视为实现AGI的关键途径。
而笔者认为,依靠海量数据拟合回归训练的AI大模型与人类进化形成的认知推理有本质上的差异。当前的大模型是将海量的人类历史认知成果,拟合为一套普适认知模型。数据拟合过程必然忽略掉差异性,而更倾向于普适性和过度拟合。
“小镇做题家”式的大模型竞赛并不能为人类进步提供实际帮助,而人类的进化与文明发展恰恰是依靠少量偶发认知差异性实现的。第一只下树和站立的古猿,第一个走出非洲、使用火、使用工具的古人类,和为人类科技进步前仆后继献出生命的里程碑人物,无不是人类历史长河中的异类,如果通过拟合共性而忽视个性,大模型的知识推理必然陷入认知陷阱。
因此,我们需要更加理性地看待AGI的发展,警惕泡沫化风险,未来AGI发展应该朝着数据分散、模型多元、推理协同、认知共享的方向发展,保留认知推理中的个性才能促进AGI技术的健康和可持续发展。
参考文献
- Team G, Anil R, Borgeaud S, et al. Gemini: a family of highly capable multimodal models[J]. arXiv preprint arXiv:2312.11805, 2023.
- Assran M, Duval Q, Misra I, et al. Self-supervised learning from images with a joint-embedding predictive architecture[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 15619-15629.
- Hinton G. How to represent part-whole hierarchies in a neural network[J]. Neural Computation, 2023, 35(3): 413-452.
- Yue X, Ni Y, Zhang K, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi[J]. arXiv preprint arXiv:2311.16502, 2023.
专栏作家
黄锐,人人都是产品经理专栏作家。高级系统架构设计师、资深产品经理、多家大型互联网公司顾问,金融机构、高校客座研究员。主要关注新零售、工业互联网、金融科技和区块链行业应用版块,擅长产品或系统整体性设计和规划。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


