
 起点课堂会员权益
起点课堂会员权益当说谎时人们在想什么?浅析深度学习在微表情测谎中的工作原理
[1]2009年美剧《LIE TO ME》播出后,很多人都对微表情产生了兴趣。大家惊叹于电视剧的剧情:一个人表情的破绽里总能暴露出真相。于是大家理所应当地认为:通过一个人表情、肢体就可以直接判断他有没有在说谎。
作为微表情研究者,我从2011年开始参与过一些刑事案件的侦查。为了验证现实情况中微表情会不会像电视剧中的那么神奇,我来简单模拟一个犯罪情况:一个盗窃案,假如你们是公安,我是嫌疑人。你们问我:“你有没有偷钱?”“唉,警官你怎么这样办呢?你说我偷钱我就偷钱了!你在大街上随便拉个人说偷钱了,他就能坐到这儿来了?你们办案要讲证据好不好!”大家看到我的表情了吗?一脸嫌弃、厌恶、不屑。另外一种情况是:“我没有,警官你们为什么会怀疑我,我是一个老实巴交的出租司机,我家里还有老婆孩子,我…我…我不可能偷钱。我…我是老实人。”看到我的表情是什么样了吗?愁苦、悲悯、可怜。你相信哪一个呢?
我们前面铺垫这么多的开场只为说明一个事情:你看到的那些可见的表现很可能都是演的。

众所周知,在刑侦的一些案件中,测谎仪起到侦查的重要作用。
现在人工智能微表情的识别也多用户辅助测谎的工作之中,而深度学习算法在微表情识别的程序工作中起到很重要的作用。
那么笔者就在本文中简述深度学习算法对微表情识别的工作原理是怎样的。
一、什么是深度学习
在讨论什么是深度学习的概念前,我们首先需要整理清楚人工智能的整体范围框架,而深度学习在人工智能整体知识领域的第几圈层?
通过下图,我们首先来看一下大致的圈层有情况:
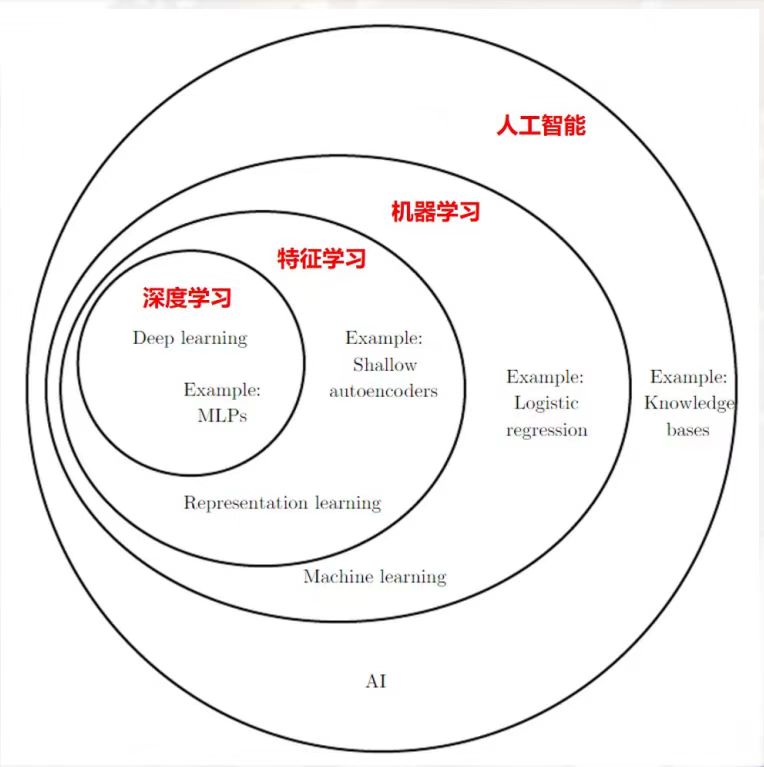
图注:人工智能整体的圈层范围
图中术语解释:
人工智能 Artificial Intelligence
AI 的初衷及最终理想是通过逻辑、推理、演绎来实现智慧。 在发展的过程中为了解决实际问题,纳入了很多经验主义的 方法论,当今的“AI”实际上是 大数据 加 深度学习 。
机器学习 Machine Learning
最早是使用经验学习研究人工智能的方法,后来纳入很多统 计学的思想和方法,并在计算机算法方面取得了很大进展。 是数据挖掘的主要方法来源,在行业里可以简单地认为“使 用机器学习方法、遵循数据挖掘流程”来进行数据分析。
深度学习 Deep Learning
机器学习中的一个分支,使用神经网络技术,在大数据的基 础上,结合 GPU 计算实现深层次的网络结构。
通过图中示例,我们可以看到:深度学习是机器学习研究的一个重要领域。与传统的机器学习相比,深度学习是一种多层学习方法。
数据的抽象和提取,从低层到高层是通过非线性规则完成的;目前的深度学习多采用深度神经网络(DNN)来构建。通过各层次非线性模块的堆叠传递输入数据的层与层之间的映射关系降维,并通过提取数据的关键特征依靠深度卷积神经网络(DCNN),提供端到端的机器学习。无需人工设计的干预,即可自动提取图像特征的模型。
与传统方法相比,深度学习完全是数据驱动的,而这些自主学习的算法可以自动匹配到最佳的路径来学习图形特征的匹配。
二、深度学习在微表情识别中的工作原理
首先当我们使用一项技术原理的时候,我们就要分析这项技术的落地应用将会给我们带来什么目标。所以我们通过解析微表情的变化可以判断是否被询问人在撒谎就成为了主要的目标因素。
目前研究表明,当一个人撒谎时,他或她会试图抑制面部表情从而欺骗别人不让别人发现其心理动态和心虚的表现。
根据 达尔文的名著《物种源始》On the Origin of Species (1859),面核传递对特定面部肌肉的脉冲接收来自不同部位的大脑脉冲传递。换句话说,大脑向面部肌肉发出信号,当有人说谎时,他或她也必须抑制自己的面部表情——当肌肉被不由自主地激活,人无法阻止它收缩时就会出现肌肉信号。因此,一个人在撒谎时不给出任何暗示是极其困难的。
但是,某些情绪,如悲伤、厌恶、愤怒和恐惧,是很难控制的。因此,他们背叛了一个人的感受,即使他或她试图欺骗从而隐瞒这些面部信息。然而,通过观察撒谎的人,不管怎样这些情绪都会在脸上反映出来。这些短暂闪现的悲伤、厌恶、愤怒和恐惧是肌肉表现是无法避免的。
所以,通过微表情判断这个人是否撒谎有据可依。
那么,深度学习又是如何匹敌肉眼而检测微表情的变化呢?
首先我们使用深度学习中的卷积神经网络(CNN)模型,通过嫌疑人的面部表情的检测。从图像中检测人脸通过灰度、直方图进行预处理均衡化,人脸检测,图像裁剪,均值滤波和归一化。
然后,将预处理后的图像输入到建立的CNN模型中,从而识别微表情的变化情况是否符合测谎的曲线维度从而进行识别。
三、应用案例简述

图注:网图-侵删 摘自小红书作者孔孔
为避免真人网图侵权,我们通过动画头像表情来略作阐述。
现实世界的数据经常受到误差、噪声和异常值的影响。在进行可视化或加工之前,需要对其进行预处理和清洗。
预处理是一个数据分析的关键阶段,通过预处理进行数据质量评估从而解决所有可能影响模型性能的问题。
大致可以通过数据预处理来评估以下常用数据维度:
- 完整性,检查是否有缺失值。
- 一致性,验证所有值是否以通用格式存储。
- 一致性,检查是否有冲突的值。
- 准确性,用于检查是否存在不正确、超时或过期的值。
- 图形处理:过滤,裁剪,调整大小,颜色分级,定位和镜像,主要是为了更快的处理而简化格式来适应机器学习算法。
我们将预处理过后的图像进行演示:
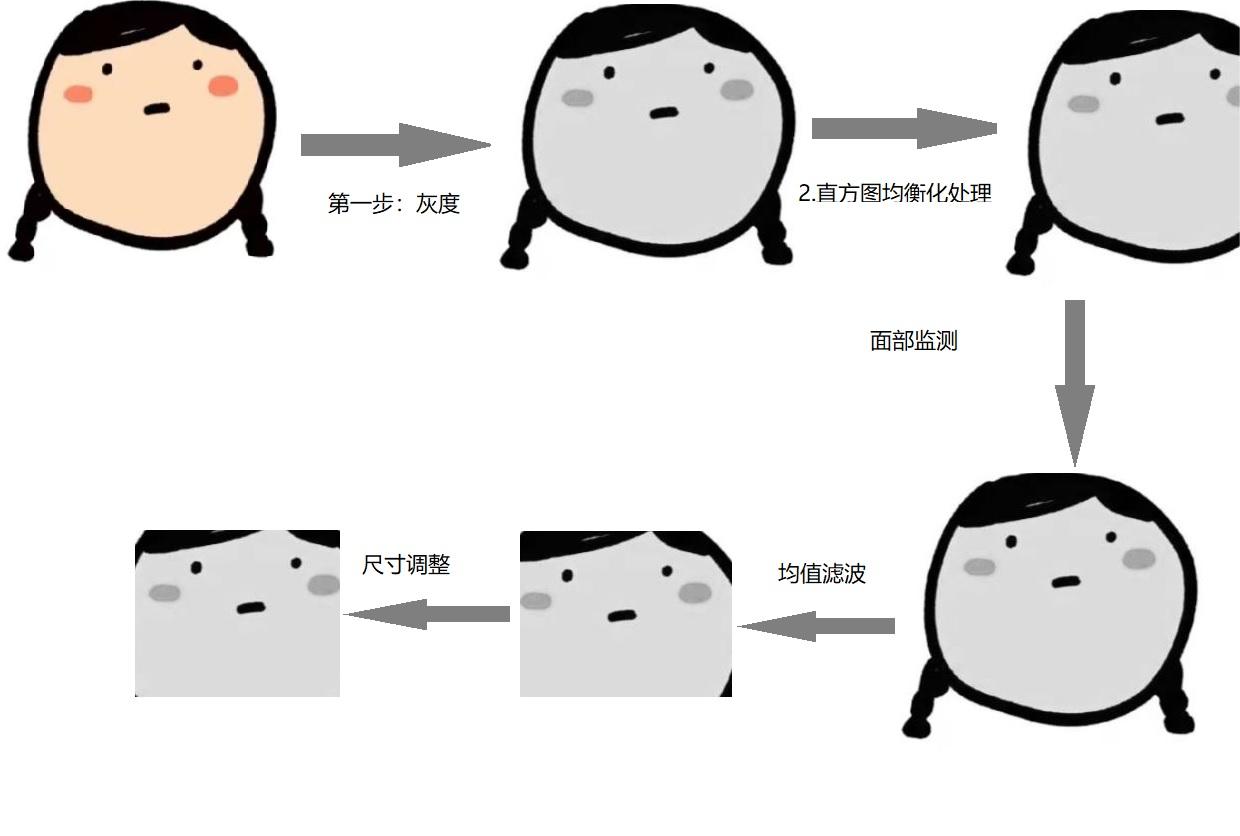
图注:预处理过程的图片演示(采用网图进行像素处理)
从演示图中我们可以看到有这些步骤:
- 灰度缩放,以保持一个通道在每个图像和简化卷积操作。
- 直方图均衡化,统一和提高每张图像的对比度更好的边缘检测。因此,图像既不会太亮也不会太暗太黑了。
- 面部检测,使用正面人脸检测器。
- 图像裁剪,只保留人脸的正面。
- 平均滤波,消除不具代表性的像素。在这一步中,每个像素都是替换为其邻居的平均值,包括其自身的像素值。
- 正常化/标准化,使像素强度保持在[−1,1],标准化值较小。
- 调整大小,以适应CNN架构的大小。
CNN模型架构构建后。使用每批10张图像对每个类进行均匀分布的图像训练,并利用交叉熵损失和每个批次的准确率进行评价,在实际的实验中我们可以注意到精度的随机变化,对每个批次进行模型训练。直至训练到可靠的置信度区间。这样就完成了一次CNN的实验训练。
四、结语
笔者今天谈论的微表情测谎,其实在生活的方方面面都具有实用价值。微表情本身源自心理学,在古代叫做“识人术”。
暂且抛开本文的人工智能微表情技术不谈。在社交媒介如此发达的今天,我们人际交往中更不能缺少对他人的基础判断。比如在团队中,如有人说谎成性,行为不检点。那么更应该多学微表情知识早日识破时机一到就远离。
再说回到本文,技术的革新虽然不能马上与人的肉眼识别来匹敌,但是随着科学的进步,相信微表情测谎也会有更高的使用价值。并且作者也要再次提醒说谎成性之人,正所谓“小恶不惩,必成大恶”。我们务必要恪守自己的本分,不要随意损人不利己,否则嚣张的尽头必将是“踩上缝纫机”。
参考
姜振宇《别撒谎,微表情会出卖你》
https://baijiahao.baidu.com/s?id=1612774886735912081&wfr=spider&for=pc
本文由 @kingwu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


