
 起点课堂会员权益
起点课堂会员权益文生视频,爆发在六月
文章主要介绍了上个月文生视频市场的一些动态和发展情况,其中包括国内外各大公司在这一领域的创新和突破,同时指出了当前文生视频技术存在的挑战和问题。

过去一个月,称得上文生视频大模型月。
爱诗科技PixVerse、快手可灵、Luma AI的Dream Machine、Runway的Gen-3 Alpha、开源项目Open-Sora、谷歌DeepMind的V2A,一众产品迎来发布更新潮。
令不少业内人士惊讶的是,国内企业在短短几个月时间中拿出了一些产品。快手可灵文生视频大模型,作为全球第一个可公开试用的生成时长超过1分钟的产品,节奏甚至走在了Sora的前面。
此前,Sora横空出世时,国内AI圈人士表现出了浓重的悲观情绪。当时他们认为Sora加剧了中外的差距,国内与海外有了明显代差,且国内形成Sora类的产品还遥遥无期。
现在,文生视频赛道国产AI正加速赶上来。人工智能企业精准学AI技术负责人张宁告诉数智前线,个中缘由在于现在技术路线已没有秘密,而视频生成赛道目前阶段对算力要求并不及大语言模型,可能在千卡集群规模,这对国内企业不构成掣肘。
数智前线还观察到,除了文生视频大模型领域,在非Sora路线的视频生成应用,国内有不少企业在产品化和价值验证上也迈开了步子,“应用驱动,非常有生机”。
行业很热闹,不过业内也坦言,文生视频大模型在产品一致性、生成时长等角度仍有待进步,行业仍未迎来ChatGPT时刻。
一、国内文生视频能力追赶海外
6月6日,快手的文生视频大模型可灵发布,一口气把视频生成的时长提到了2分钟级。
在线上开放版本里,用户输入开放式文本描述,等待几分钟就能生成时长5秒,帧率30fps,分辨率1080p,且支持多种宽高比的视频。21日,可灵的功能再度更新,上线了图生视频和视频时间延长功能,用户添加更多描述,据称最长能够生成长达3分钟的视频。
快手官方将可灵定义为“首个效果对标 Sora且面向用户开放的文生视频大模型”,对比今年2月引爆赛道的Sora,目前OpenAI仍没有推出公开可适用产品,目前对外展示的视频最长生成时间也仅为60秒水平。
快手可灵的能力,引发了业界的广泛关注。截至6月26日,有超过18万人在快影的排队列表里等待试用。这种热度可能快手官方也没有意料到。有一个插曲,快手视觉生成与互动中心负责人万鹏飞出席北京智源大会时说受到了不少关注,他看起来颇不习惯。论坛主持人打趣让他“尽快习惯”。
在社交媒体上,可灵收到了海内外的不少好评。“感觉无论是画质、运动幅度、人物、场景一致性上完全不输sora,可灵的生成质量是现在普通用户能接触到的天花板”,一位AI行业人士不吝称赞。
可灵的出现明显提振了国内文生视频赛道的士气。
实际上不止是可灵,过去几个月里,国内文生视频赛道上的进展不小,多家企业都推出了各类文生视频模型产品。
比如,爱诗科技的Pixverse也是国内出品,爱诗科技核心团队是此前的字节视觉技术团队而来。4月,生数科技发布文生视频大模型Vidu,可根据文本描述直接生成长达16秒、分辨率高达1080P的高清视频内容。一个月前,腾讯也发布混元最新一代基于DiT架构的视频生成模型,能生成16秒视频,预计今年第三季度将推出的下一代文生视频模型,可生成30秒以上视频。
在一众产品中,为什么国内大厂并不是特别有钱的快手能做到产品化?
一位资深人士认为,国内加速发展在于文生视频赛道自从Sora验证了Scalling Law之后,技术上已经没有了秘密。
爱诗科技创始人王长虎表示,Sora横空出世生成了新语言。Sora最重要的贡献是验证了视频生成的规模定律,模型越大,可用的优质数量数据越多,产生的效果更好。
过去十年,Diffusion技术支撑了AIGC图像视频生成的发展。此前视觉生成扩散模型主要基于 U-Net 架构,而Sora采取了Diffusion+Transformer架构(也即业界提出的DiT架构),去掉了U-NET架构,同时利用了大语言模型帮助增强,以及做训练数据的精细化达标。这个技术也使得众多视频生成能力进一步提升。
除此之外,精准学张宁告诉数智前线,训练文生视频大模型对算力的需求没有大语言模型那么大,也是国内在模型能力上快速追平的原因。“当下的生成时长和能力,需要的算力可能在千卡规模,比大语言模型小很多,现在GPT-4训练时需要的集群规模在3.2万张卡水平”。
二、应用驱动的另一股流向
视频生成领域,另一股趋势也颇为明显。在应用驱动下,不少企业已经把视频生成技术形成产品和解决方案,去解决行业问题。
6月21日,华为盘古大模型5.0发布,其中多模态能力里就包括了视频生成技术。华为一贯强调大模型技术要解决行业难题,在视频生成技术上也是如此。
华为常务董事、华为云CEO张平安介绍,视频生成技术应用到了自动驾驶的训练环节。自动驾驶应用里的视频生成,最怕天马行空。比如多个行驶视角的视频合并时,车子可能会莫名其妙消失,这样的视频明显不能用于自动驾驶算法训练。
盘古5.0基于自研的可控时空生成技术,能理解物理规律,大规模的生成和实际场景相一致的驾驶视频数据。像是生成的雨天的汽车行驶视频里,车子的尾灯都是开启的。这代表模型通过对海量视频数据的学习,学习到了雨天开车应该开车灯。目前华为没有透露这种生成能力的技术路线。
另一些企业,则集成了大模型的能力,根据文字组装视频,帮助一些B端企业实现更低门槛创作各类视频。
特看科技CEO乐乘告诉数智前线,他们推出视频AIGC生成平台,主要是想帮国内出海商家和海外本土企业降低B端广告营销视频制作门槛。这种做法与基于文字从0~1生成画面的类Sora产品不是一回事。
Sora基于文字凭空生成视频,而特看的文生视频工具,接入了海外主流的大语言模型和TTS及多模态大模型。大模型学习爆款视频的文本结构,生成适合商家产品的文案和脚本,之后自动与商家提供的产品素材匹配,一键生成视频。
这是在应用层的尝试。它的Know-How则在于,如何把不同的模型衔接在一起,并实现流畅工作的工程能力。比如在线合成、在线编辑的流畅程度,数字人的口型和内容的匹配吻合,动作和画面如何组合等。
另外面向B端可用的视频生成产品,也重视内容的可控性,特看的应用从脚本生成到素材匹配,每个环节都支持用户在线编辑调整,“Sora对我们是增强作用,比如视频某个镜头不行,我们未来可以接入它,用Sora生成片段去填充。”乐乘介绍。
魔珐科技创始人柴金祥则从培训、电商、金融、快消、广电等企业级场景里,企业对高质量、可编辑、且能精准传递信息的内容需求出发,推出有言AIGC一站式3D 视频创作平台。
“以往拍摄一条高质量3D动画产品,成本按照秒来计算,周期却要几个月,几十万成本也下不来。”柴金祥说,他们拆解了3D内容所包含的各类要素,将制作3D视频的流程固化成了软件化的工业产线。
比如面向产品发布会、汇报视频,知识分享等不同场景,需求方可以调整3D形象的性别、面部特征、头发颜色、外观、服饰、配饰等各种细节,搭配上不同的场景素材。大语言模型、TTS模型的能力被集成到系统里,与此前搭配的素材组合,生成符合需求、内容可控的高质量3D视频。
从应用层发力,产品在企业级场景应用和落地速度也推进很快。比如魔珐科技介绍,目前在教育、培训、文旅、政务、金融、3C、快消等多个行业都有头部企业在用他们的产品,已经完成了价值验证。而特看科技也透露,一些出海企业如安克等,已使用这款产品来做网页和社媒推广的视频。
基于大模型的能力往行业和应用层挖,“模型崩了应用也不能用了,大模型升级后应用的效果也会增强,比如随着模型推理的能力增强,生成的速度会越来越快,价格可能也会变便宜,文案质量和视频的质量也越来越高。”乐乘说。
三、热闹之下,行业仍需跨越鸿沟
国产AI能力加速追赶之外,不得不说整个6月里赛道的另一个特征——产品井喷潮。巨头谷歌、明星公司Runway、新晋创企Luma AI,再到国内的短视频企业快手,都推出了产品或发布了更新。
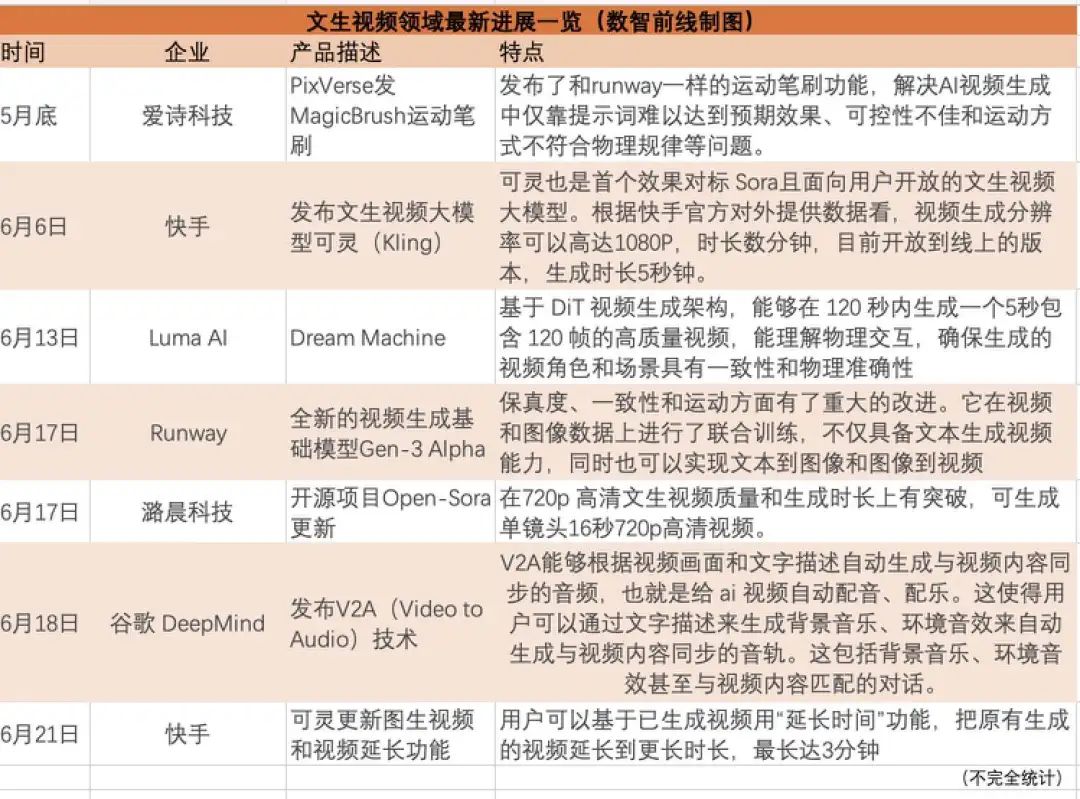
比如硅谷创业公司Luma AI推出的Dream Machine,可基于文字或图片输入,在120 秒内生成长度为5秒的高质量视频。推出后不少试用者就称在能力上吊打了老牌AI企业Runway的文生视频模型Gen-2。
几天后,Runway马上找回了场子,它宣布即将推出新模型Gen-3 Alpha,相比上一代的Gen-2在保真度、一致性和运动表现方面有重大改进。并且它支持多种创作方式,包括文本到视频(T2V)、图像到视频(I2V)和文本到图像(T2I) 等能力。虽然未开放试用,但Runway在官网释出了不少精彩的视频。
目前,厂商们都没有公布文生视频模型的参数量级,多是模型即产品模式,主要围绕生成视频的时长、视频的分辨率等指标展开。分钟级的内容生成能力,之前Sora是独苗,快手可灵推出后,一下子刷新了这个指标。已公布产品里,腾讯此前宣布过文生视频模型生成时长达到了16秒,三季度要到20秒。其他各家目前的产品看还停在10秒以内 。
另外,各家的产品化阶段和对公众可用的进度也不一。

这种你追我赶的架势,看起来与大语言模型领域的内卷游戏如出一辙。Sora的DiT路线验证了文生视频领域的Scaling law之后,文生视频赛道底层模型的未来走向也变得明了。
乐乘认为,Sora和它的追随者们,后续的竞争态势会跟现在大语言模型一样。大厂的闭源版产品+开源版,大家一起卷,能力逐渐拉平趋同。
目前行业里开源产品的能力也在提升。今年3月18日,潞晨科技旗下Colossal-AI团队开源了其Open-Sora 1.0视频生成模型,包括模型权重、训练源代码和详细的架构,目前在GitHub上获得超过19.6k的星标。
潞晨科技Open-Sora负责人申琛惠提到,Open-Sora开源项目,经过迭代更新,目前版本能单次生成大概20秒的视频,针对于最初版本只能生成2秒,有了显著的提升,基于之前视频生成的延续性生成可以长达数分钟。
她也提到了开源项目模型Demo和OpenAI没有办法去比。“OpenAI使用到大概2000-4000个H100的GPU,花费5000万美元到2亿美元的训练成本,我们用了大概1万美金这样的范围成本进行实验”。
值得一提的是,快手可灵推出后,已经有不少人士在关注能否“开源白嫖”。万鹏飞出席北京智源现场两次被提问模型的开源打算。他回应称,他们暂时不考虑开源,目前已经放出了一些关键的判断和设计,未来也会把一些硬核的东西逐步释放出来,大家一起交流学习。
当下业界普遍意识到,文生视频产品距离商用仍然有不小的鸿沟需要跨越。
一个突出的问题是效果不稳定,有人将之类比为“抽卡”。“在限定的语句和限定的训练样本内,可以获得很好的效果,但是一超过边界就会天马行空,甚至群魔乱舞,超越人类常识和认知。”一位人士使用后评价。
为了减少“抽卡”,企业也在想办法提升体验,比如爱诗科技用到了图生视频这种“垫图”的方法。王长虎提到,如果用文生视频,需要尝试 25 次才能生成一次可用的,文生图每生成 5 次就能有一次可用的,再用这张图通过技术把它动起来,抽卡成功概率就从 1/25 提升到了 1/10。
另外,如何对运动规律和物理世界实现更好的建模,如何生成更长的可用视频,以及如何能够表达镜头语言,生成多镜头内容,都是未来AI视频要解决的问题。业界已有共识,目前视频生成还没有到ChatGPT阶段。
“视频生成模型目前还处于一个相对早期的发展阶段,其情形有点类似于视频领域的GPT-2时期。市场上尚未出现一个完全成熟且广泛可用的视频生成应用。”潞晨科技创始人兼董事长尤洋今年4月指出。
文|徐鑫编|任晓渔
本文由人人都是产品经理作者【汪仔7974】,微信公众号:【数智前线】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


