
 起点课堂会员权益
起点课堂会员权益Open AI开卷小模型,价格战杀手锏来了
在人工智能领域,大模型的高昂训练成本一直是限制其广泛应用的主要障碍。然而,最近各大科技巨头纷纷转向小模型的开发,试图在成本和性能之间找到平衡点。OpenAI推出的GPT-4o mini模型,以其卓越的性价比和广泛的应用场景,成为这一趋势的代表。本文将探讨小模型如何成为AI领域的新宠,以及它们在价格战中扮演的关键角色。
过去一周,小模型战场悄然开“卷”。大模型训练成本如滚雪球般越滚越大,曾经坚信“大力出奇迹”的科技巨头们,如今纷纷转向小模型赛道,试图在这场技术与商业的角逐中寻找新的突破口。
OpenAI、谷歌、微软乃至苹果,各自带着小模型利器纷纷亮相,谁能在这场成本与性能较量中找到黄金分割点?
一、小模型更小、更好、更便宜
7月18日,Open AI推出了号称迄今为止最具成本效益的小模型GPT-4o mini。
据Open AI介绍,小模型产品是想通过显著降低AI使用成本,扩大AI使用范围。GPT-4o mini在MMLU上的得分为82%,并在LMSYS排行榜的聊天偏好测试中表现优于GPT-4。
GPT-4o mini适用于一系列任务,第一类是需要多次调用模型的应用,例如调用多个API;第二类是需要向模型传递大量上下文信息的应用,例如完整的代码库或对话历史;第三类是通过快速的实时文本响应与客户互动的应用,例如聊天机器人。
目前,GPT-4o mini在API中支持文本和视觉处理,未来将支持文本、图像、视频和音频的输入和输出。该模型的上下文窗口为128K tokens,每次请求支持多达16K输出tokens,并且具备截至2023年10月的知识。
GPT-4o mini成为主推产品,已在 ChatGPT 免费版上线。在学术基准测试中,GPT-4o mini在文本智能和多模态推理方面超越了GPT-3.5 Turbo和其他小型模型,支持与GPT-4o相同范围的语言。它还在函数调用方面表现出色,使开发人员能够构建与外部系统交互的应用,并在长上下文处理性能方面优于GPT-3.5 Turbo。
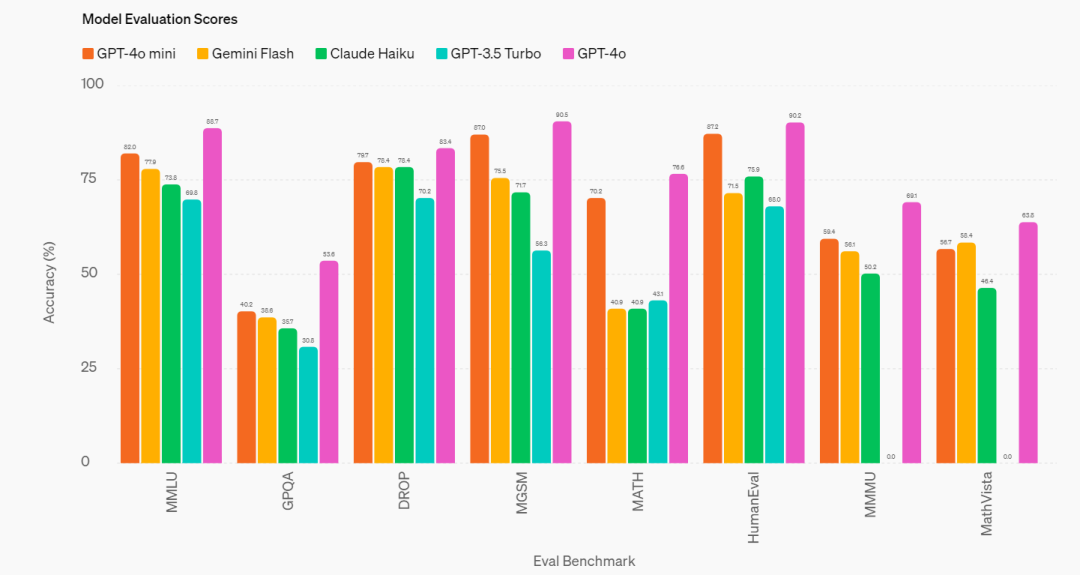
图源:Open AI
就在OpenAI推出GPT-4o mini模型不久后,英伟达和法国明星AI独角兽Mistral联合发布了名为Mistral NeMo的小模型,提供性能优越、部署便捷、安全性高的企业级AI功能。由于 Mistral NeMo 依赖于标准架构,因此易于使用,可以直接替换任何使用 Mistral 7B 的系统。
同样不走寻常路的还有最新杀入AI战场的苹果。近期,苹果公司作为 DataComp-LM(DCLM)项目的研究机构之一,在 Hugging Face 上发布了 DCLM-7B 开源模型,而且比其他公司更开放。据了解,该模型性能已经超越了 Mistral 7B,并且正在逼近其他领先的开源模型,包括 Llama 3 和 Gemma。
对此有科学家发出惊叹:“Apple发布了一个击败Mistral 7B的模型,但更棒的是他们完全开源了,包括预训练数据集!”
二、小模型或成价格战“利器”
有人将AI领域如此热闹的一周戏称为“小模型周”。事实上,今年以来,小模型的赛道早已开跑,今年5月,谷歌发布了轻量级模型Gemini 1.5 Flash。4月,微软推出SLM(小语言模型)Phi-3系列,微软强调Phi-3便宜得多,但响应能力接近比它大10倍的模型,号称能力对标GPT3.5。
小模型,顾名思义指的是参数规模远小于一些大型语言模型的模型,常见的参数规模有1.5b、3b、7b等。尽管参数较少,但通过特定的设计和优化,小模型依然能够在某些任务上实现与大型模型相近的性能,同时降低计算资源消耗,提高能耗比。
曾经信仰“大力出奇迹”的巨头们,如今前赴后继地入局小模型赛道,仍旧是出于那个绕不开的理由:“成本”。
今年以来,国内外大模型赛道的价格战愈演愈烈。自去年以来,OpenAI已经进行了4次降价,国内方面,5月,字节跳动把定价降低了一个数量级,从以分计价进入以厘计价时代。根据火山引擎公布的价格计算,1元就能买到豆包主力模型的125万Tokens,大约是200万个汉字。7月5日,2024世界人工智能大会(WAIC 2024)期间,百度宣布文心旗舰款模型ERNIE 4.0和ERNIE 3.5大幅降价,ERNIE Speed、ERNIE Lite两款主力模型持续免费。
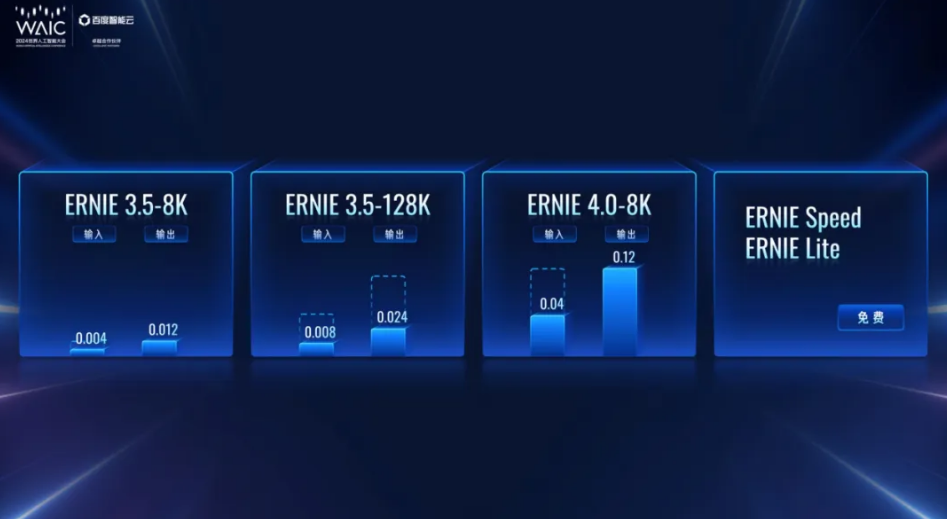
价格战打得火热的背后,尖端AI训练成本居高不下,甚至越来越高。
斯坦福HAI研究所发布的报告指出,当前尖端AI的训练成本正越来越高,报告显示,2017年训练最初的Transformer模型的成本仅为约900美元,而到了2019年,RoBERTa Large模型的训练成本已经升至约16万美元。到了2023年,OpenAI GPT-4和Google Gemini Ultra的训练成本更是分别达到约7800万美元和近2亿美元。
为此,小模型以更低的成本,极致的性价比,成为AI模型公司卷价格战的“利器”。
GPT-4o mini发布后,山姆·奥特曼在推特上发文指出,早在2022年,世界上最好的模型是text-davinci-003,它比GPT-4o mini差得多,但成本要贵上100多倍。
成本更低的小模型给成本敏感型企业多了一重选择。GPT-4o mini的每百万输入tokens 为15美分,每百万输出tokens 为60美分,相对的,此前入门款模型GPT-3.5 Turbo输入/输出定价是0.5美元/1.5美元,GPT-4o mini在此基础上便宜了超60%。
根据Artificial Analysis的统计,GPT-4o mini已经达到美国AI公司主流“小模型”里价格最低位置,比起Anthropic、谷歌的同类型竞品都要更具性价比。
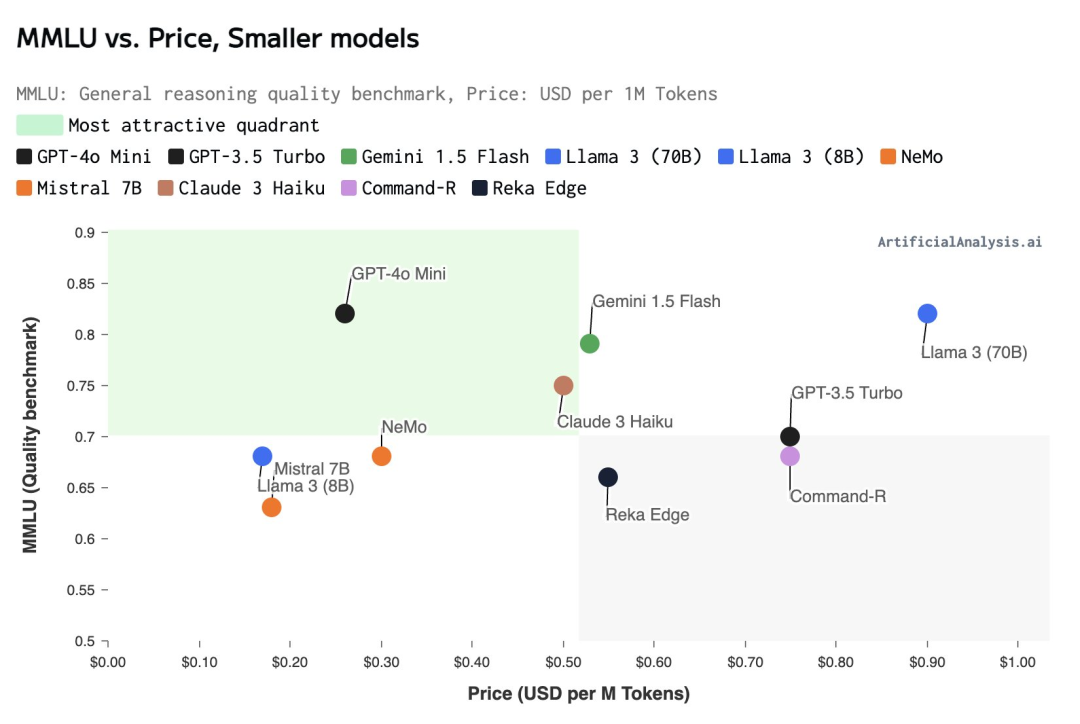
“在过去的几年里,我们见证了人工智能的显著进步,同时也见证了成本的大幅低,我们致力于提高模型性能的同时继续降低成本。”OpenAI方面表示,自2022年以来,模型每token的成本下降了99%。
三、小模型正成为新风口
真正落地后,性价比成为企业的重要考量,小模型或将越来越受青睐。
《华尔街日报》近日报道,企业正越来越多地部署中小型的AI模型,它们更青睐规模较小、更具成本效益的AI技术,而不是在AI热潮早期掀起波澜的大型昂贵模型。
对于一些最常见的AI用例来说,比如涉及文档分类等小范围、重复的任务,中小型模型更有意义。当前企业正在部署更多AI用例,它们也面临着管理这种昂贵技术的成本和回报的压力。
营销服务公司WPP集团正在使用谷歌Gemini的中型模型Flash,其首席技术官斯蒂芬·普雷托留斯提到,一年前,企业被少数几款大型模型吸引。当公司有限度地、试验性地使用它们的能力时,情况还好,但现在随着它们的规模扩大,大模型的成本可能很快就会失控。
“企业倾向于构建小模型来完成特定任务。”山海引擎COO彭璐在接受《IT时报》记者采访时曾表示,国内算力需求正从大规模模型训练转向推理需求,尤其是企业对于私有化部署的推理需求日益增长。随着开源模型能力的提升,企业发现通过微调开源模型即可满足特定任务需求,无须投入巨资训练超大规模模型。
在今年年初召开的2024百度AI开发者大会上,李彦宏也表示,基于百度文心4.0,用户可以结合效果、响应速度及推理成本等多维度因素,灵活剪裁出适用于不同场景的小尺寸模型。相较于直接使用开源模型调整得到的模型,这些定制的小模型在同等尺寸下展现出了更为显著的效果优势;而在同等效果下,其成本则更低廉。
“在一些特定场景中,经过精调后的小模型,其使用效果甚至可以媲美大模型。”李彦宏论断,未来大型的AI原生应用将主要采用大小模型混合使用的方式,根据不同场景选择适合的模型。
本文由人人都是产品经理作者【IT时报】,微信公众号:【IT时报】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


