
 起点课堂会员权益
起点课堂会员权益AI数据爆发“石油危机”,内容公司可以躺着赚钱了
随着AI大模型的普及,对高质量数据的需求也在不断增长,引发了一系列的版权和使用权问题。本文将深入探讨AI数据的版权纠纷、内容平台的变现机会,以及高质量数据的稀缺性,为读者揭示AI时代数据价值的多面性。

ChatGPT 的出现和 Midjourney 的爆发式采用让 AI 实现了第一次大规模应用,即大模型的普及。
所谓大模型,是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务。
一、AI数据版权纠纷
如果把当下的 AI 大模型比作汽车,原始数据就是原油。无论如何,首先 AI 模型需要足够的“原油”。
AI 公司的“原油”来源主要有以下几类:
- 网上公开免费的数据源,比如维基百科、博客、论坛、新闻资讯等;
- 老牌新闻媒体和出版社;
- 大学等研究机构;
- 使用模型的 C 端用户。
现实世界的石油归属权已经有成熟的法律规范,而在 AI 这个天地尚且混沌的领域,“原油”开采权还不明晰,由此造成的纠纷不胜枚举。
就在最近,多家大型音乐厂牌起诉AI音乐制作公司Suno和Udio,指控其侵犯版权。这起诉讼与《纽约时报》去年12月对OpenAI的诉讼类似。
2023年7月,一些作家对该公司提起诉讼,指控ChatGPT根据受版权保护的内容生成了作者作品的摘要。
同年12月,《纽约时报》也对微软和OpenAI提起类似版权侵权诉讼,指控这两家公司利用该报的内容训练人工智能聊天机器人。
此外,还有一起集体诉讼在加利福尼亚州提起,指控OpenAI未经用户同意,从互联网上获取用户私人信息来训练ChatGPT。
OpenAI 最终并没有为这份指控买单,他们表示不认同《纽约时报》的指控,也无法复现《纽约时报》提到的问题,更重要的是,所谓《纽约时报》提供的数据源,对于 OpenAI 来说并不重要。

来源:https://openai.com/index/openai-and-journalism/
对于 OpenAI 来说,这件事情带来的最大教训也许就是处理好与数据供应商的关系,明确双方权责。于是,我们在近一年的时间内看到 OpenAI 跟很多数据供应商达成合作伙伴关系,包括但不仅限于The Atlantic、Vox Media、News Corp、Reddit、Financial Times、Le Monde、Prisa Media、Axel Springer、American Journalism Project 等等。
未来,OpenAI 将名正言顺地使用这些媒体的数据,而这些媒体也会将 OpenAI 的技术融合到产品中。
二、AI 推动内容平台变现
不过,OpenAI 跟数据供应商达成合作关系最根本的原因不是恐惧被起诉,而是机器学习即将面临的数据枯竭。MIT等研究人员曾进行一项研究估计,机器学习数据集可能会在 2026 年之前耗尽所有「高质量语言数据」。
「高质量的数据」因此成为像 OpenAI 和 Google 这样的模型制造商的香饽饽。内容公司与AI模型厂商屡屡达成合作,开启躺平赚钱模式。
传统媒体平台Shutterstock陆续和Meta, Alphabet, Amazon, Apple, OpenAI, Reka等AI公司达成合作, 2023年通过内容授权给AI模型将年收入提高到 1.04 亿美元,预计 2027 年产生 2.5 亿美元收入;Reddit 授权给谷歌的内容版权收入每年高达 6000 万美元;苹果也在寻求与主流新闻媒体合作,开出一年至少5000万美元的版权费。内容公司从 AI 公司收到的版权费正在以 450% 的年增长率疯狂上涨着。
而在过去一些年里,流媒体之外的内容难以变现,这是内容行业的一大痛点。相比互联网创业时代,AI 的出现给内容行业带来了更大的想象力以及更强烈的收入预期。
三、高质量数据依然稀缺
当然不是什么样的内容都符合 AI 的需求。
关于前文提到的 OpenAI 和《纽约时报》的争论,另一个亮点是数据质量。从原油中提炼石油,一则是要油本身质量好,二则提纯技术要好。
OpenAI 特意强调《纽约时报》的内容并未对 OpenAI 的模型训练产生任何重大贡献,比起能够让 OpenAI 每年自掏腰包数千万美金的 Shutterstock,《纽约时报》这类靠时效性起家的文字媒体并不是 AI 时代的宠儿。AI 更需要深刻而独特的数据。
而高质量数据太稀缺,AI 公司也开始在“提纯技术”和“一站式应用”上下功夫。
6 月 25 日,OpenAI 收购实时分析数据库公司 Rockset。这家公司主要提供实时数据索引和查询功能,OpenAI将在其产品中集成 Rockset 的技术,提高数据的实时使用价值。
通过收购Rockset,OpenAI 计划使 AI 更好地利用和访问实时数据。这能使 OpenAI 的产品支持更复杂的应用,如实时推荐系统、动态数据驱动的聊天机器人、实时监控和报警系统等。
Rocket是 OpenAI 内置的“石化部门”,将普通数据直接转化为应用所需的高质量数据。
四、创作者数据确权是异想天开吗?
互联网媒体平台(Facebook、Reddit 等)的数据很大程度来自于UGC,即用户贡献内容。很多平台在向 AI 公司收取高额数据费的同时,也悄悄在用户条款上加上了一条“平台拥有使用用户数据训练 AI 模型的权力”。
虽然用户条款对 AI 模型训练权力有所标注,但创很多作者并不清楚自己生产的内容具体被哪些模型使用,也不知道是否是付费使用,更无从获得本该属于自己的相关权益。
在今年 2 月份的 Meta 季度业绩电话会议上,扎克伯格明确表示将使用 Facebook 和 Instagram 上的图片来训练他的 AI 生成工具。
据报道,Tumblr 也已经与 OpenAi 和 Midjourney 神秘达成内容授权协议,但并未公开具体协议的具体的内容。
图片库平台EyeEm的创作者们最近也收到一份通知,提示他们发布过的照片会用于 AI 模型训练。通知提到,用户可以选择因此不使用产品,但还未提及任何补偿政策。EyeEm 的母公司 Freepik 向路透社透露,该公司已与两家大型科技公司签署协议,以每张图片 3 美分左右的价格授权其 2 亿张图片中的大部分图片。首席执行官 Joaquin Cuenca Abela 表示,还有五笔类似的交易正在进行中,但拒绝透露买家的身份。
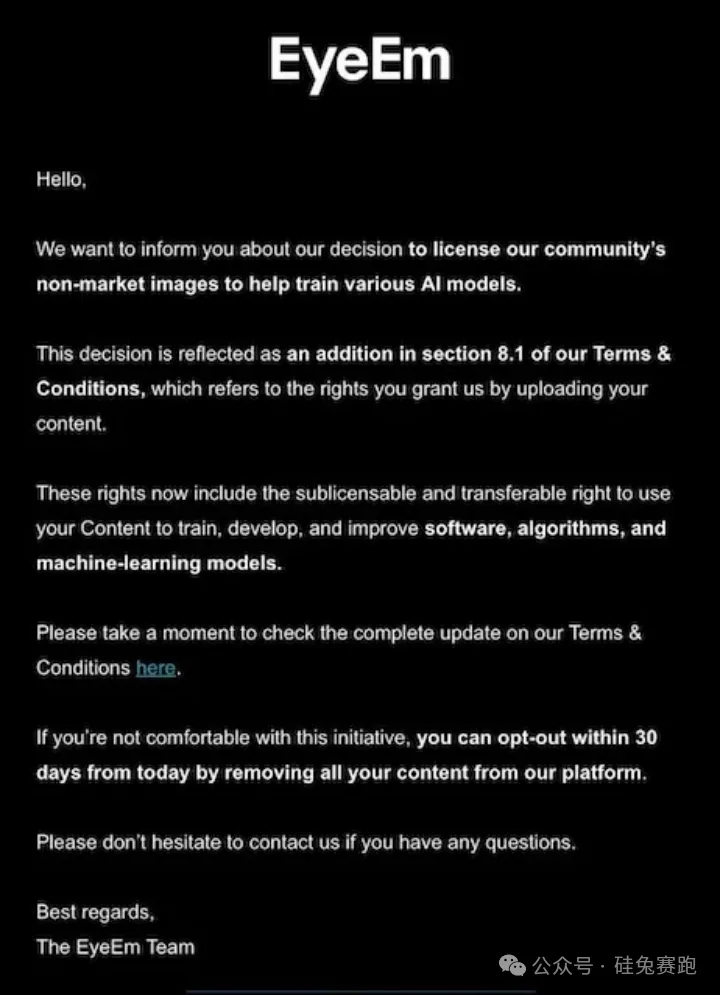
Getty Images、Adobe、Photobucket、Flickr、Reddit 等UGC 为主导的内容平台都面临类似的问题,在巨大的数据变现诱惑下,平台选择忽视用户的内容所有权,一把将数据打包卖给 AI 模型公司。
整个过程都在暗处进行,创作者并没有任何反抗的机会。甚至许多创作者,可能要在未来某一天,在某个模型中训练出与自己作品类似的内容时,才能有机会怀疑曾经的作品被某个平台拿去卖给 AI 公司做模型训练。
解决创作者的数据确权和收益难以保护的问题,Web3 可能是个好选择。当 AI 公司在美股屡创新高时,web3 的 AI 概念币也在同时一飞冲天。区块链以其去中心化和不可篡改的特性,在保护创作者权益上享有得天独厚的优势。
诸如图片和视频这样的媒体内容已经在 2021 年的牛市完成了上链的大规模采用,而社交平台的 UGC 内容上链也在悄然发生。同时,许多 web3 AI 模型平台已经在激励为模型训练做贡献的普通用户,无论是数据所有者,还是训练者,都被激励着。
AI 模型指数级的发展为数据确权提出了更大的需求,创作者应该思考:为什么我的作品在没有经过我同意的情况下被 5 美分一幅卖给了 AI 模型公司?为什么整个过程中我不知情,且无法得到任何收益?
媒体平台竭泽而渔也无法缓解 AI 模型公司的数据焦虑,实现高质量数据高产量的前提是数据确权,是创作者、平台和 AI 模型公司三者合理的利益分配。
参考来源:
Shutterstock Made $104 Million Licensing Assets to AI Devs Last Year(PetaPixel)
All The Photo Companies That Have Struck Licensing Deals With AI Firms(PetaPixel)
Reddit has a new AI training deal to sell user content(TheEverge)
GPT-4耗尽全宇宙数据!OpenAI接连吃官司,竟因数据太缺了,UC伯克利教授发出警告(新智元)
OpenAI acquires Rockset(OpenAI)
本文由人人都是产品经理作者【硅兔赛跑】,微信公众号:【硅兔赛跑】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


