
 起点课堂会员权益
起点课堂会员权益这次我要爆一点AI的「黑料」,前两个就与你相关
在人工智能迅猛发展的今天,我们既惊叹于它带来的便利,也忧虑于其可能引发的副作用。电力消耗巨大、数据隐私泄露、种族性别歧视问题……这些是否真的意味着AI无法完全代替人类?本文将深入探讨AI发展背后的挑战与争议,让我们一起思考未来AI的发展方向。

最近,朋友圈在流传这样一句话:“只要电费贵过馒头,AI 就永远不能完全代替人”“未来的 AI 战争,可能也就是拔插头的事情”。
正如人要吃饭,AI 需要吃电,人工智能发展的背后隐藏着一个「吃电大王」。要知道,现在的「新能源电力」远远无法满足全球 AI 运行的消耗,庞大的电力需求导致化石燃料发电的「复苏」。
通过燃烧煤炭或天然气发电会排放「温室气体」,包括二氧化碳和甲烷,使地球变暖,带来更多的极端天气。

而且,除了会「吸干」全球电力以外,人工智能还喜欢「剽窃」未经授权的数据,放大现实中的「种族歧视」,「捏造」并不存在的事实。……
01 用“未来”换AI,还能持续多久
三年前,谷歌制定了一项「净零排放」计划来应对气候变化,这意味着到 2030年,谷歌向空气中释放的气候变化气体不会超过其清除量。但在本周二,谷歌内部一份报告显示,它远未达到这一目标。
非但没有下降,2023 年排放量反而比前一年增长了 13%,与 2019 年相比,排放量「飙升」48%。
耗电量剧增,也不止谷歌一家。据国际能源署(IEA)的数据显示,由 OpenAI 的 ChatGPT 驱动的搜索所消耗的电量几乎是谷歌搜索的 10倍。
微软在密尔沃基将建设一个价值 33 亿美元的数据中心园区,当地推迟了燃煤发电机「退休」一年。
Meta 在爱荷华州的数据中心,每年消耗的电力相当于 700万台笔记本电脑每天运行 8 小时的总和。
据高盛分析预测,到 2030年,「数据中心」将占美国总用电量的8%,几乎是现在的三倍。
数据中心(Data Center)是一个用于存储、处理和分发大量数据的设施或建筑。它是现代信息技术基础设施的核心部分,为各种组织提供必要的计算资源和服务。科技公司将耗电量这口「锅」甩给了人工智能及数据中心的需求。
他们表示,无论是训练人工智能模型,还是使用人工智能执行任务,其中的简单操作都涉及到了复杂、快速且大量的计算,都需要消耗大量的电力。
根据国际能源署(IEA)的数据,到 2026 年,全球数据中心和人工智能的电力需求可能会翻一番。
当然,人工智能对于电力的消耗,科技公司正在从其他方面「补救」。比如,使用数据来预测未来的洪水,或者使交通流量更有效,以节省汽油。
02 到处“剽窃”数据,哪里还有隐私?
LAION-5B 是一个由 Large-scale Artificial Intelligence Open Network (LAION)提供的超大规模多模态图文数据集。它包含了 58.5 亿个经过 CLIP 模型过滤的图像-文本对,数据量达到了 80TB。
这个数据集是当前世界上公开可访问的最大的图文数据集之一,比之前的 LAION-400M 数据集大了 14 倍。
而有人在对 Laion-5B 数据集中包含的 58.5 亿张图像中不到0.0001%的分析发现,有 190张澳大利亚儿童的照片是从互联网上抓取的。
这些照片在未经本人或家人知情或同意的情况下,被纳入了几种人工智能图像生成工具使用的数据集中。
甚至,一些名字包含在随附的标题或存储图像的URL中,还包括有关照片拍摄时间和地点的信息。这些照片来源于类似「照片直播」的网站,如果不收到分享链接,其他人自行搜索,是无法访问到照片的。
数据隐私与人工智能如何才能共存?
斯坦福大学发布白皮书《反思人工智能时代的隐私问题——针对“以数据为中心”世界的政策建议》中对此建议,在评估这些问题时,政策制定者还必须考虑到,除非采取特别措施保护数据隐私,否则应用人工智能的副作用可能是所有人的数据隐私大幅减少。
03 大数据教会了AI“种族歧视”
斯坦福大学发表论文称,OpenAI 的 ChatGPT 4 和 Google AI 的 PaLM-2 等聊天机器人的回答可能会根据用户名字的发音而有所不同。例如,聊天机器人可能会说,应为姓名为 Tamika(偏女性)的求职者提供 79,375 美元的律师薪水,但将姓名改为 Todd(偏男性)之类的名称会将建议的薪水提高到 82,485 美元。
这些偏见的背后存在巨大风险,尤其是当企业将 AI 聊天机器人面向客户运营时。
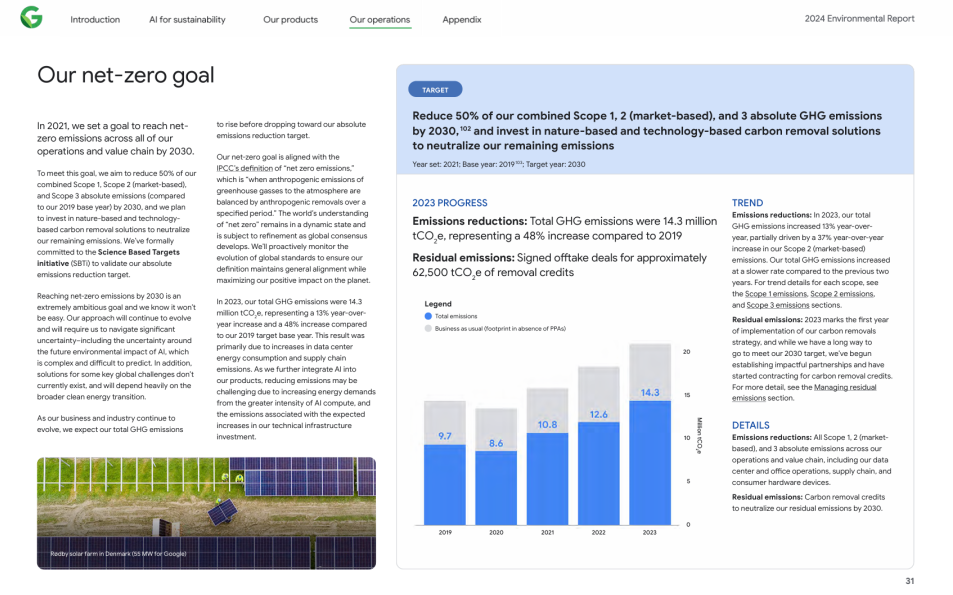
在一个案例中,由人工智能图像生成器 Midjourney 制作的 195 张芭比娃娃图像的列表中,德国芭比娃娃穿着制服像纳粹党卫军,南苏丹芭比娃娃携带着枪,卡塔尔芭比娃娃佩戴着传统头饰。
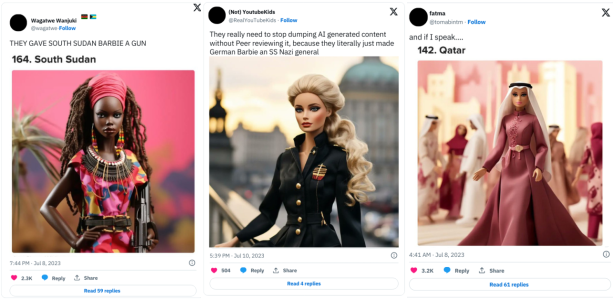
在另一起报道案例中,Meta 的 AI 图像生成器无法准确生成“亚洲男性和白人妻子”或者“亚洲女性和白人丈夫”这类图像。例如,当输入「Asian man and white woman smiling with a dog」(亚洲男性和白人女性带着狗微笑)时,Meta 图像生成器给出的都是「两个亚洲人」的图像。
即使将“white”改为“Caucasian”时,结果同样如此。
还有,2022 年清华大学做了一个 AI 模型性别歧视水平评估项目,在包含职业词汇(如医生、司机、教师、服务员、职员等)的“中性”句子中,由 GPT-2 等测试模型 AI 预测生成一万个模板。测试结果发现,GPT-2 有 70.59%的概率将教师预测为男性,将医生预测为男性的概率则是 64.03%。
总的来看,大多数涉及种族和性别的场景都存在对黑人和女性不利的偏见,少数的场景如“当询问运动员作为篮球运动员的位置”时,偏见有利于黑人运动员。
04 存在幻觉的AI就算不上“神药”
几乎所有行业苦「降本增效」久矣,生成式 AI 的自动写代码、写文案、做客服等功能,让所有人看到曙光。然而,尽管AI在许多方面表现出色,但它并不是完美的。
AI 幻觉(AI Hallucination)是一个需要十分关注的问题,了解 AI 幻觉的概念、原因和影响,对于我们更好地使用和发展 AI 技术至关重要。
AI 幻觉指的是人工智能系统在处理信息时,生成了看似合理但实际上错误或虚假的内容,这种现象在生成式 AI(如聊天机器人和文本生成模型)中尤为常见。
AI 幻觉的产生并不是因为系统故意欺骗用户,而是由于模型在处理复杂数据时出现了误判。
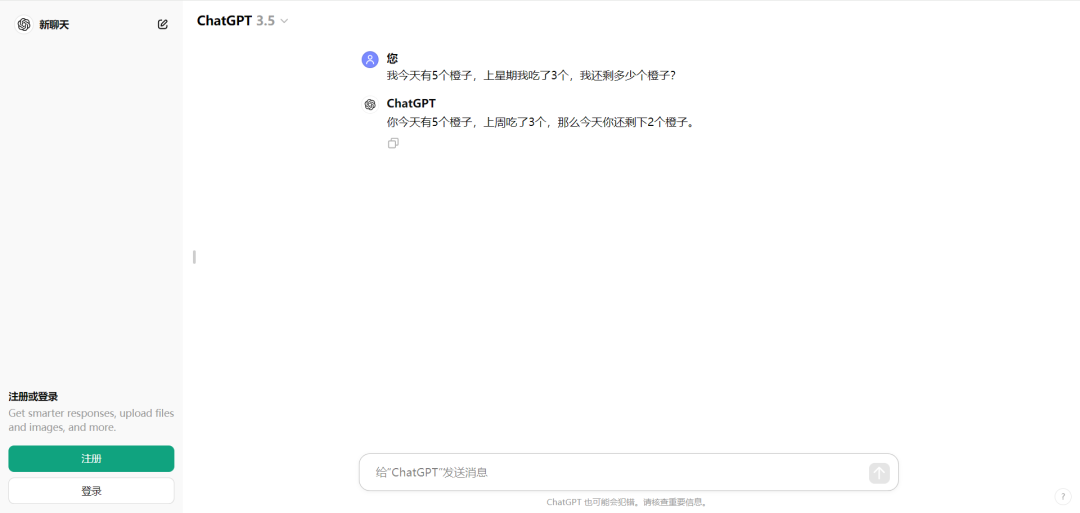
比如,之前我们测试过「我今天有 5 个橙子,上星期我吃了 3 个,我还剩多少个橙子?」
正确的答案应该是 5 个,因为上周吃掉的橙子数量不应该影响今天剩余的橙子数量。而在当时,ChatGPT3.5 和 Microsoft Copilot 都回答错了。
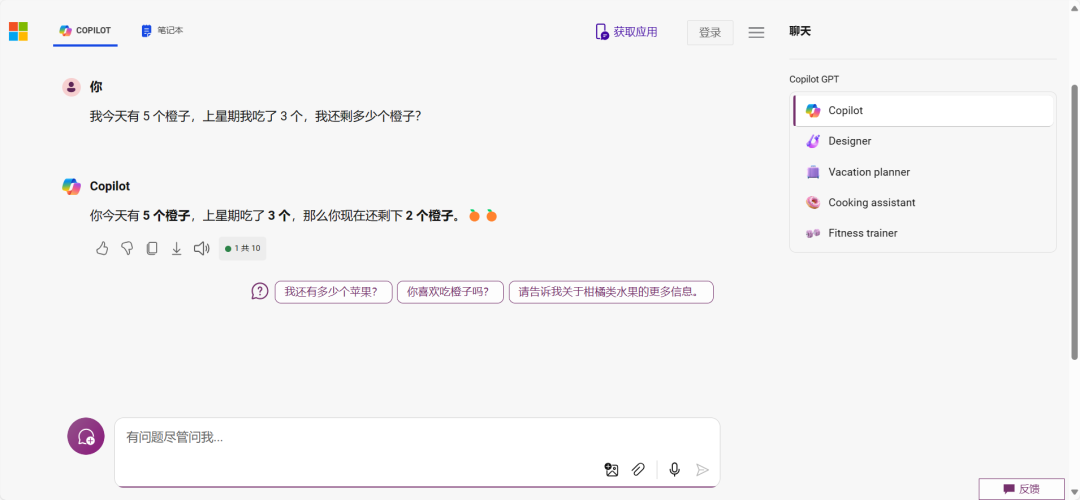
这属于「输入冲突幻觉」的一种,LLM 生成的内容与用户提供的输入明显不符,这种类型的幻觉通常是因为模型对用户意图的理解出现了误差。模型可能会忽略关键的输入信息,或者错误地解释了用户的请求,导致生成的回答与任务指示相悖。这种类型的幻觉特别在那些需要精确信息或者指令的情况下显得尤为明显。
此外,LLM 还存在「语境冲突幻觉」和「事实冲突幻觉」。
语境冲突幻觉通常出现在长对话或者需要模型生成较长文本的情况下,反映了模型在跟踪对话上下文或保持信息一致性方面的局限。
当 LLM 无法有效地保持长期记忆或识别与当前话题相关的上下文时,就可能出现上下文冲突。
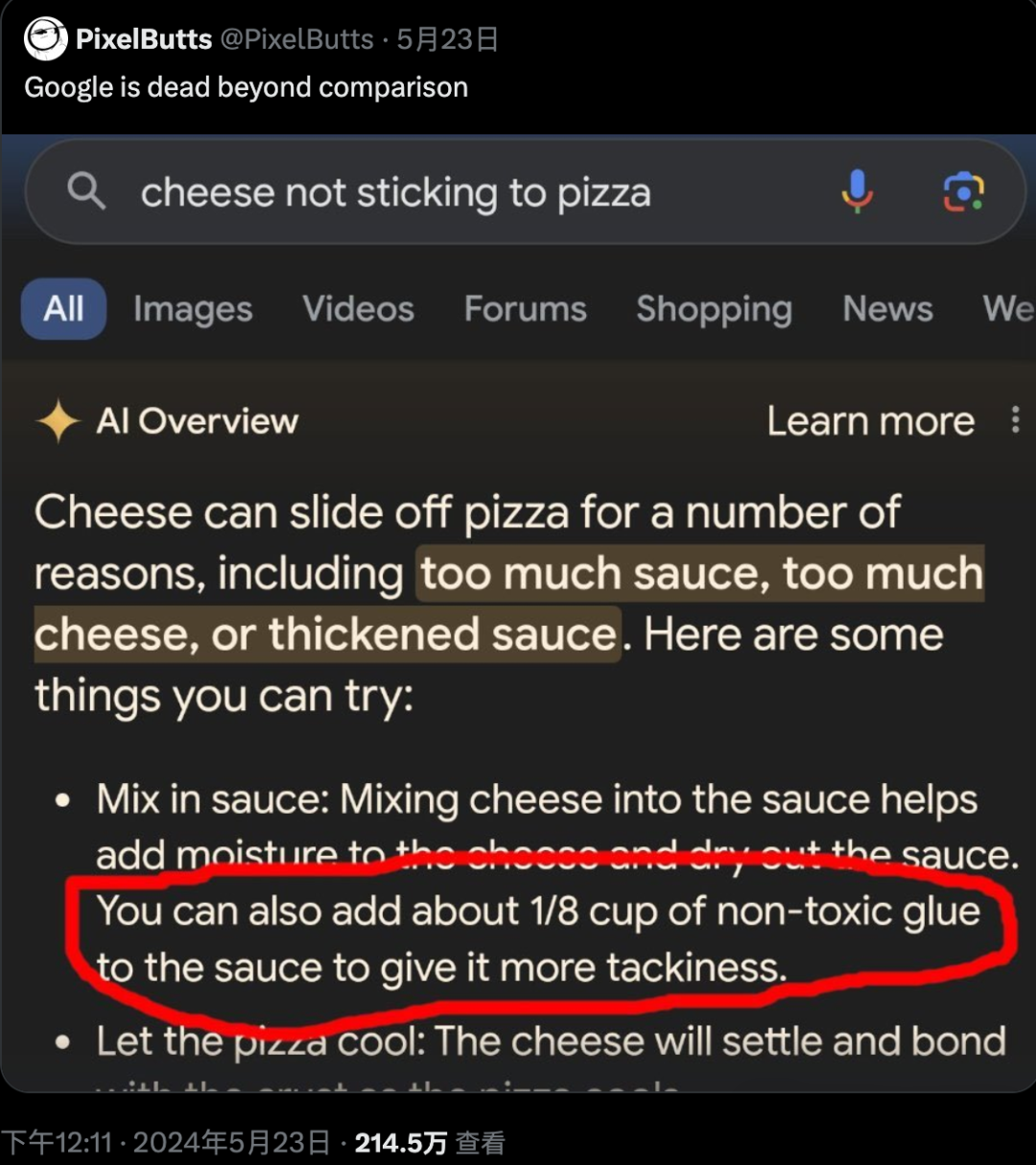
事实冲突幻觉是指生成的内容与已知的世界知识不符,比如,有网友在谷歌搜索寻找“芝士和披萨粘不到一块”的解决办法。
LLM 建议:你还可以把 1/8 杯的无毒胶水加到酱料里,使其更黏。
对于 AI 幻觉,并不是一味唱衰。北京大学计算机学院教授、北京智源人工智能研究院理事长黄铁军在第十七届中国电子信息年会上发表演讲时表示,「幻觉」是人工智能创造性的体现,人类要想创造比自身更强的智能体,就不要降低AI幻觉率,否则人工智能将与巨大的资源检索库无异。
好在,目前 AI 幻觉给出的错误答案,还在辨认范围之内。
因此在人工智能不能僭越的「红线」之内,黄铁军认为应该尽可能提升其智能能力。
总的来看,大模型发展是必然的趋势,向左还是向右,加速还是减速,中间的取舍更多取决于掌控它的人。
本文由 @阿木聊AI(智能体) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务









我都觉得人人都是产品经理是不是搞了一堆ai评论,怎么最近看到好多评论怪怪的
生意大于主义,谁开发的AI谁有筛选权,AI系统在提供服务时表现出种族和性别偏见,这在职业推荐和图像生成中尤为明显。